集合
-
概念:是提供一种存储空间 可变 的存储模型,存储的数据容量可以发生改变。(也就是集合容量不固定)
-
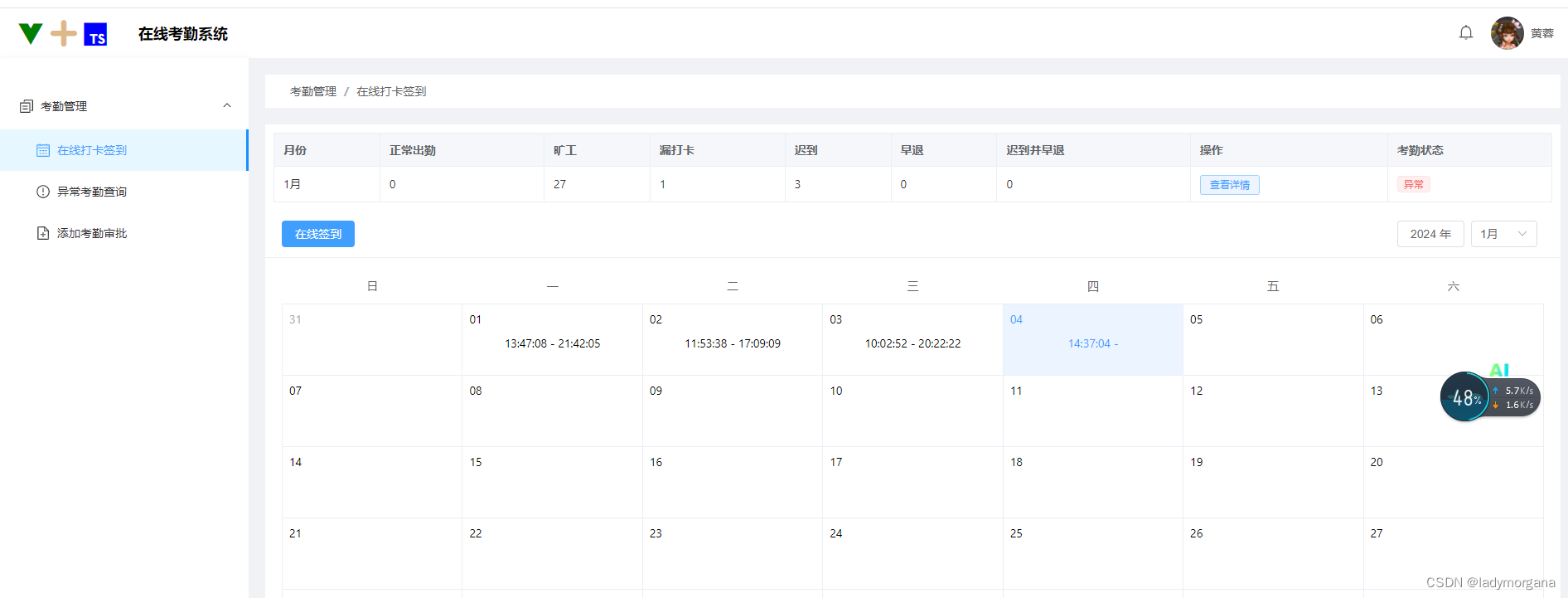
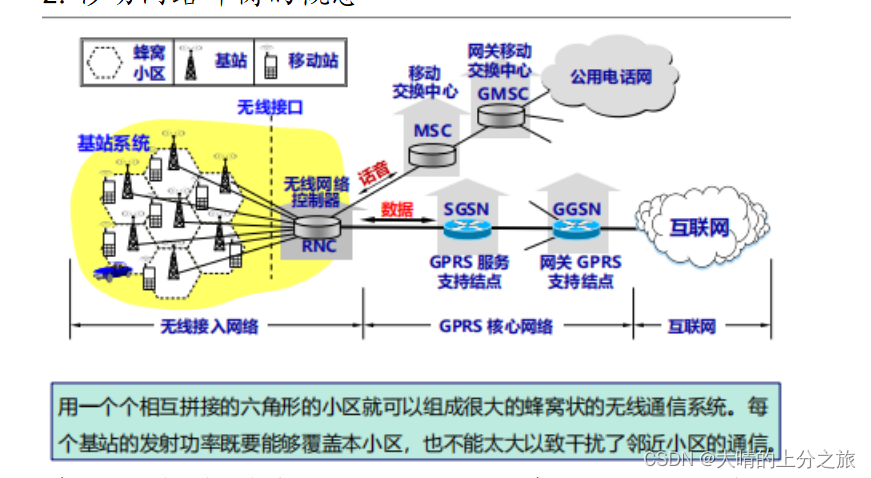
集合关系图

绿色的代表接口,蓝色的代表接口的实现类
单列集合
Collection(接口)
-
概述:单列集合的顶层接口,表示一组对象,这些对象也称为Collection的元素,不提供此接口的任何直接实现。
-
常用方法:
方法 作用 boolean add(E e) 添加元素 boolean remove(Object obj) 从集合中移除指定的元素 void clear() 清空集合中的元素 boolean contains(Object obj) 判断集合中是否存在指定的元素 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中元素的个数 -
使用方法
import java.util.ArrayList; import java.util.Collection; public class Test{ // 遍历集合 public static void show(Collection co){ for(Object c : co){ System.out.println(c); } } public static void main(String args[]){ // 1、创建集合对象,Collection 是接口,所以创建对象只能用其子类实现类 Collection c = new ArrayList(); // 2、添加元素 c.add(1); c.add("张三"); c.add(true); // 3、遍历集合 show(c); // 4、移除指定元素 c.remove(1); // 5、遍历集合 show(c); // 6、清空集合中元素 c.clear(); // 7、判断集合中是否存在指定元素 boolean flag; flag = c.contains("张三"); System.out.println(flag); // 8、判断集合是否为空 flag = c.isEmpty(); System.out.println(flag); // 9、得到集合元素个数 int num = c.size(); System.out.println(num); } }
注意:我们可以看到,我们向集合中 添加了 整型 1 字符串 张三 布尔型 true ,所以集合是可以存储不同数据类型的容器,而数组是存储相同数据类型的容器
注意:接下来的集合都用泛型进行限定,如果不理解泛型,可以去参考下这篇文章:泛型-限定存储数据类型
List
-
概述:List 集合是一个有序集合。用户可以精确控制列表中的每个元素的插入位置,用户也可以通过整数索引访问元素,并搜索列表中的元素。列表中通常允许重复的元素。List 接口是继承其父类Collection 接口的。
-
List 集合特点:
- 有序:存储和取出的元素顺序一致
- 可重复:存储的元素可以重复
-
List 的两个实现类
ArrayList 底层结构是数组 查询快,增删慢 LinkedList 底层结构是链表 查询慢,增删快 -
集合的遍历参考这篇文章:集合的三种遍历方式
ArrayList
-
特有方法(特指其父类 Collection 没有的那些):
方法 作用 void add(int index , E element) 在集合指定位置插入指定的元素 E remove(int index) 删除指定索引处的元素,返回被删除的元素 E set(int index , E element) 修改指定索引处的元素,返回被修改的元素 E get(int index) 返回指定索引处的元素 -
使用方法
import java.util.ArrayList; import java.util.List; public class Test{ public static void main(String[] args) { // 1、创建集合,使用泛型限定集合存储数据类型 List<String> list = new ArrayList<String>(); // 2、指定位置添加元素 list.add(0,"王五"); list.add(1,"张三"); // 3、返回指定索引处的元素 String s; s = list.get(1); System.out.println("修改前:" + s); // 4、修改指定索引处元素 String s1 = list.set(1, "李四"); s = list.get(1); System.out.println("被修改的元素是:" + s1); System.out.println("修改后:" + s); // 5、删除指定索引元素,并返回被删除元素 String s2 = list.remove(1); System.out.println("被删除的元素是:" + s2); // 6、集合中元素个数 System.out.println("集合中元素个数:" + list.size()); } }
LinkedList
-
特有方法
方法 作用 void addFirst(E e) 在该列表开头插入指定的元素 void addLast(E e) 将指定元素追加到此列表的末尾 E getFirst() 返回此列表中的第一个元素 E getLast() 返回此列表中的最后一个元素 E removeFirst() 从此列表中删除并返回第一个元素 E removeLast() 从此列表中删除并返回最后一个元素 -
使用方法
import java.util.LinkedList; public class Test6 { public static void main(String[] args) { // 1、创建集合,使用泛型限定集合存储数据类型 LinkedList<String> list = new LinkedList<String>(); // 2、在列表开头插入元素 list.addFirst("张三"); list.add("李四"); list.add("王五"); // 4、在列表尾部插入元素 list.addLast("牛六"); // 5、返回列表第一个元素 System.out.println("集合第一个元素:" + list.getFirst()); // 6、返回列表最后一个元素 System.out.println("集合最后一个元素:" + list.getLast()); // 7、删除并返回列表第一个元素 System.out.println("被删除的元素是:" + list.removeFirst()); // 8、删除并返回列表最后一个元素 System.out.println("被删除的元素是:" + list.removeLast()); // 9、遍历集合 System.out.print("集合中还有的元素是:"); for (String s : list) { System.out.print(s + " "); } } }
Set
-
概述:不包含重复元素的集合,没有带索引的方法,所以不能使用普通 for 循环遍历
-
特点:
- 对集合的迭代顺序不做任何保证(无序)
-
Set 集合的三个实现类
HashSet 底层是哈希表 TreeSet 底层是树 LinkedHashSet 底层是 哈希表和链表
HashSet
-
概述:底层数据结构是 哈希表(数组 + 链表)
-
特点:
- HashSet 集合存储元素,要保证元素的唯一性【需要重写 hashCode() 和 equals() 方法】
import java.util.HashSet; import java.util.Objects; class Pig{ private int age; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Pig pig = (Pig) o; return age == pig.age; } @Override public int hashCode() { return Objects.hash(age); } } public class Test7 { public static void main(String[] args) { // 1、创建集合 HashSet<Pig> hs = new HashSet<Pig>(); // 2、添加元素(添加重复元素) Pig p1 = new Pig(); Pig p2 = new Pig(); hs.add(p1); hs.add(p1); hs.add(p2); // 3、遍历元素 for (Pig h : hs) { System.out.println(h.hashCode()); } } }可以,注销 hashCode() 和 equals() 方法,看下!
LinkedHashSet
-
概述:哈希表和链表实现的 Set 接口,具有可预测的迭代次序
-
特点:
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素的唯一性
public class Test{ public static void main(String[] args) { // 1、创建集合对象 LinkedHashSet<String> lhs = new LinkedHashSet<String>(); // 2、添加元素 lhs.add("张三"); lhs.add("王五"); lhs.add("张三"); lhs.add("李四"); // 3、遍历集合 for (String lh : lhs) { System.out.print(lh + " "); } } }最终运行结果:张三 王五 李四
可以看到,元素有序,并且元素唯一
TreeSet
-
概述:底层是树的Set集合,按照一定的规则进行排序,具体排序取决于构造方法
-
特点:
- 元素有序:这里的顺序不是存储和取出的顺序
- 元素唯一:Set集合重写 hashCode() 和 equals() 保持元素唯一
-
两种排序规则:
- 自然排序
- 比较器排序
-
构造方法:
方法 作用 TreeSet() 根据元素的自然排序进行排序 TreeSet(Comparator comparator) 根据指定的比较器进行排序
自然排序
-
比较对象时候,该对象类要实现 Comparable 接口
-
该对象类重写 compareTo(E e)方法(规则如下)
- 返回 0 ,不比较
- 返回 1(正数),升序输出
- 返回 -1(负数),降序输出
-
例子1:逆序向集合存储元素,遍历集合?

注意:String 已经实现了 Comparable 接口,重写了 compareTo() 方法

-
例子2:按照年龄输出,年龄相同,按照姓名字母排序(升序)?
- this 代表当前类,s 代表的是已经在集合中的类
import java.util.TreeSet; // 自然排序 class Student implements Comparable<Student>{ private int age; private String name; public Student(int age , String name){ this.age = age; this.name = name; } @Override public String toString() { return "Student{" + "age=" + age + ", name='" + name + '\'' + '}'; } @Override public int compareTo(Student s) { int num1 = this.age - s.age; // 年龄相同,按照姓名排序 int num2 = (num1 == 0) ? this.name.compareTo(s.name) : num1; return num2; } } public class Test { public static void main(String[] args) { // 1、创建集合对象 TreeSet<Student> ts = new TreeSet<Student>(); // 2、添加元素 ts.add(new Student(7,"xiaoHeng")); ts.add(new Student(6,"xiaoBai")); ts.add(new Student(8,"xiaoLi")); ts.add(new Student(7,"abc")); // 3、遍历元素 for (Student t : ts) { System.out.println(t); } } }
比较器排序
-
概述:带参构造方法,使用的是比较器排序对元素进行排序
-
比较器排序,就是让集合构造方法接收 Comparator 的实现类对象。重写compareTo(T s1, T s2)(匿名内部类的方式实现)
-
注意:
- 重写方法时,一定要注意排序规则,按照要求的主要次要条件来写(否则有的不能实现)
- 次要条件一定要满足所有要求
-
例子1:按照字符串的长度进行排序,从小到大?
import java.util.Comparator; import java.util.TreeSet; public class Test { public static void main(String[] args) { // 1、创建集合对象,使用比较器排序 TreeSet<String> ts = new TreeSet<>(new Comparator<String>() { @Override public int compare(String s1, String s2) { int num = s1.length() - s2.length(); return num; } }); // 2、添加元素 ts.add("abc"); ts.add("abcd"); ts.add("ab"); ts.add("a"); // 3、遍历集合 for (String t : ts) { System.out.print(t + " "); } } }运行结果:a ab abc abcd
-
例子2:首先按照年龄进行降序排序,再按姓名升序排序,再按照姓名长度进行升序排序?
import java.util.Comparator; import java.util.TreeSet; class Pig{ private int age; private String name; public Pig(int age, String name) { this.age = age; this.name = name; } public int getAge() { return age; } public String getName() { return name; } @Override public String toString() { return "Pig{" + "age=" + age + ", name='" + name + '\'' + '}'; } } public class Test2 { public static void main(String[] args) { // 1、创建集合对象,使用比较器排序 TreeSet<Pig> ts = new TreeSet<>(new Comparator<Pig>() { @Override public int compare(Pig s1, Pig s2) { int num1 = s2.getAge() - s1.getAge(); int num2 = (num1 == 0) ? s1.getName().compareTo(s2.getName()) : num1; int num3 = (num2 == 0) ? s1.getName().length() - s2.getName().length() : num2; return num3; } }); // 2、添加元素 ts.add(new Pig(5,"abc")); ts.add(new Pig(6,"efg")); ts.add(new Pig(7,"hij")); ts.add(new Pig(5,"bcde")); ts.add(new Pig(5,"bcd")); // 3、遍历集合 for (Pig t : ts) { System.out.println(t); } } }运行结果:
Pig{age=7, name=‘hij’}
Pig{age=6, name=‘efg’}
Pig{age=5, name=‘abc’}
Pig{age=5, name=‘bcd’}
Pig{age=5, name=‘bcde’}
Map
-
概述:Map 集合是一个 键值对 集合,将键映射到值的对象,不能包含重复的键,每个键可以映射到最多一个值
- Map<K,V> K:键的类型,V:值的类型
-
特点:
- 键唯一,值可重复
- 键对应唯一的值,一个值可对应多个键
- 当键第二次出现时,会将之前的值覆盖掉
-
常用方法
方法 作用 V put(K key , V value) 添加元素 V remove(Object key) 根据键删除键值对元素(当集合中没有此键的时候返回 null) void clear() 移除所有的键值对元素(慎用) boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,集合中键值对的个数 V get(Object key) 根据键获取值(当集合中没有此键的时候返回 null) Set keySet() 获取所有键的集合(set无法使用普通 for 循环) Collection values() 获取所有值的集合 Set<Map.Entry<K,V>> entrySet() 获取所有键值对对象的集合 -
使用方法
import java.util.HashMap; import java.util.Map; import java.util.Set; public class Test3 { // 遍历方法一 public static void show(Map<Integer,String> map){ // 1、获取所有键的集合 Set<Integer> keySet = map.keySet(); // 2、根据键获取值 for (Integer key : keySet) { // 根据键获取值 String s = map.get(key); System.out.println(key + " --- " + s); } } // 遍历方法二 public static void print(Map<Integer,String> map){ // 1、获取所有键值对的集合 Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); // 2、遍历 for (Map.Entry<Integer, String> es : entrySet) { System.out.println(es.getKey() + " --- " + es.getValue()); } } public static void main(String[] args) { // 1、创建集合对象 Map<Integer,String> m = new HashMap<Integer, String>(); // 2、添加元素 m.put(1,"张三"); m.put(2,"李四"); m.put(3,"王五"); show(m); // 3、根据键 删除 键值对,没有此键 返回 null m.remove(1); print(m); // 4、判断集合是否包含指定的键、值 System.out.println(m.containsKey(1)); System.out.println(m.containsValue("李四")); } }运行结果:
1 — 张三
2 — 李四
3 — 王五
2 — 李四
3 — 王五
false
true
HashMap 和 TreeMap
- TreeMap<K,V> : 对应 TreeSet 两种排序,可参考 自然排序 和 无参排序
哈希值
-
概述:是 JDK 根据对象的地址 或者 字符串 或者 数字 算出来的 int 类型的数值。
-
Object 类中有一个方法可以获取对象的哈希值
方法 作用 public int hashCode() 返回对象的哈希值 -
特点:
-
默认情况下,不同对象的哈希值是不相同的(Object)

-
通过方法重写,可以实现不同对象的哈希值是相同的(重写 hashCode() 方法)
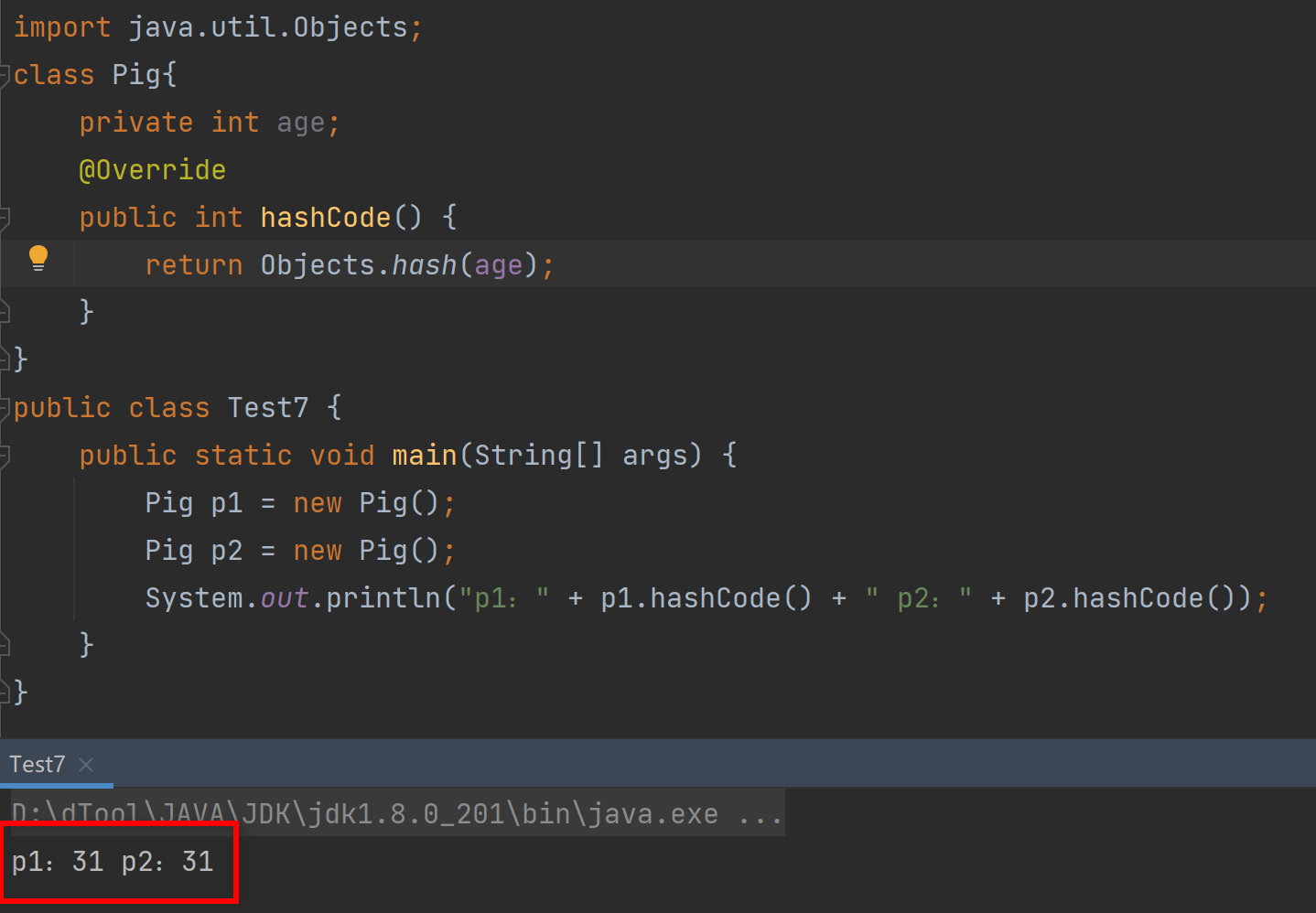
-
String 字符串重写了 hashCode 方法,所以不同内容的哈希值相同
-