目录
- 前言
- 1 Word2Vec概述
- 2 CBOW模型
- 2.1 CBOW模型简介
- 2.2 基于词袋(bag of word)的假设
- 2.3 One-hot向量编码
- 2.4 分类问题
- 3 Skip-gram模型
- 3.1 Skip-gram模型简介
- 3.2 目标词预测上下文
- 3.3 词语关联性的捕捉
- 4 优化Word2Vec模型的方法
- 4.1 负采样和分层softmax
- 4.2 动态调整滑动窗口大小
- 5 结语
前言
在自然语言处理领域,词嵌入(Word Embeddings)是一种强大的技术,它将词语映射到连续的低维向量空间中,捕捉了词语之间的语义关系。其中,Word2Vec是一种常用的词嵌入模型,其主要包括CBOW和skip-gram两种架构。本文将深入探讨Word2Vec的原理、应用以及优化方法,帮助读者更好地理解这一领域的关键概念和技术。
1 Word2Vec概述
Word2Vec是一种基于神经网络的模型,其旨在将单词转换为低维度、密集的向量表示,从而帮助计算机更好地理解和处理自然语言。其主要特点在于利用语言学规律捕捉单词之间的关联性,提供了一种高效的表征方式。

Word2Vec的核心在于能够在紧凑的向量空间中包含单词的语义和句法属性。通过利用语言学的规律和模式,该模型提取单词之间的有意义关系,使计算机能够更有效地编码语义相似性和句法结构。
通过利用神经网络和语言学原理,Word2Vec生成向量表示,有助于更全面地理解上下文中的单词。这些表示编码了语义含义和句法关系,使计算机能够更准确地识别相似之处、推断语境,并提高在语言相关任务中的表现。将语言的复杂性编码到紧凑的向量空间中,Word2Vec成为推动自然语言理解和处理系统能力的重要工具。

2 CBOW模型
2.1 CBOW模型简介
CBOW模型是Word2Vec的一种形式,它以一种简单而有效的方式将词语表示为向量。它的核心思想是通过上下文中的词语来预测目标词语。这种模型忽略了词语在文本中的顺序,而是专注于整个文本的统计信息。

2.2 基于词袋(bag of word)的假设
CBOW采用了词袋的假设,即假设一个词的出现仅依赖于它周围的词语,并忽略了它们的顺序。这种假设将文本视为一组词的集合,而不考虑它们在句子中的顺序。
2.3 One-hot向量编码
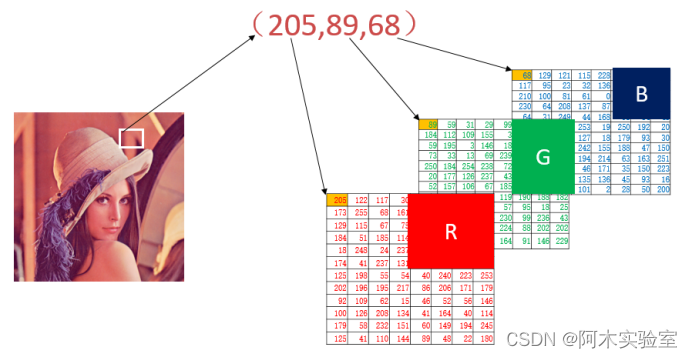
为了将词语转换为模型可接受的输入,CBOW使用了One-hot向量编码。这种编码将每个词映射为一个在词汇表大小范围内的高维向量,其中只有一个元素为1,其他元素为0。这样的表示方式有利于模型的计算。
2.4 分类问题
CBOW将词语预测的问题转化为一个分类问题。它以上下文词语作为输入,并尝试预测可能出现的目标词语。这种模型的训练过程旨在最大程度地减小预测误差,从而使模型能够根据给定的上下文推断出目标词语。
CBOW模型提供了一种基于上下文推断目标词语的有效方法。它捕捉了词语之间的语义关联,为自然语言处理任务提供了重要的语境信息。虽然它简化了语言的复杂性,但在词嵌入和语义推断方面发挥了关键作用。
3 Skip-gram模型
3.1 Skip-gram模型简介
Skip-gram模型是Word2Vec的另一种变体,它以不同的方式处理文本信息。与CBOW相反,skip-gram是基于目标词来预测其周围上下文词的模型。其关注点在于如何从单个词开始预测其上下文,从而更好地捕捉词语之间的关联性。

3.2 目标词预测上下文
通过给定一个特定的词语作为输入,skip-gram模型试图预测在其周围上下文中可能出现的其他词语。这种方法旨在通过目标词预测其上下文,以揭示词语之间的联系和语义关联。这种反向的预测方式有助于捕捉更广泛的语境信息。
相较于CBOW,skip-gram模型在处理大规模语料库时表现更为出色。它能够更好地捕捉每个单词的上下文信息,尤其在大规模文本数据中,这种能力对于构建准确的词向量至关重要。
3.3 词语关联性的捕捉
通过skip-gram模型,词语之间的关联性可以更为全面地被捕捉。模型试图理解词语在不同上下文环境下的语义表示,进而生成更具信息量的词向量表示。这有助于在自然语言处理任务中更准确地表达单词之间的语义和关系。
Skip-gram模型以目标词预测上下文的方式,在处理大规模语料库时展现出优越性。它有助于理解词语之间的关联性,提供了更丰富的语境信息,为自然语言处理领域的词嵌入和语义分析提供了有力支持。
4 优化Word2Vec模型的方法
4.1 负采样和分层softmax
Word2Vec模型在处理大规模词汇表时面临着巨大的计算成本。为了提高计算效率,出现了负采样和分层softmax这两种主要的优化方法。负采样通过随机选取少量负样本来近似全局softmax,从而减少了计算量,加快了模型训练速度。而分层softmax则将词汇表分解为不同层级,降低了计算复杂度,使得计算过程更高效。
4.2 动态调整滑动窗口大小
CBOW和skip-gram模型中的滑动窗口大小并非固定不变的,而是根据上下文与目标词的远近进行动态调整。这种智能化的策略能够更加精准地捕捉词语之间的相关性。当目标词与上下文词距离较近时,窗口大小会相应缩小,反之则会扩大。这种动态调整能更好地适应文本中词语的分布特点,提高了模型的表现力。
这些优化方法不仅仅是为了提高Word2Vec模型的计算效率,更是为了使其能够更好地捕捉词语之间的语义关联。通过负采样和分层softmax,以及动态调整滑动窗口大小,模型能够更快速、准确地学习到文本中词语之间的关系,生成更加具有表现力的词向量表示。
优化Word2Vec模型的方法不仅改善了计算效率,还提升了模型的表达能力,使其在自然语言处理任务中更加有效和可靠。这些方法为词嵌入技术的发展带来了重要的进步,为处理大规模文本数据提供了可行的解决方案。
5 结语
Word2Vec作为词嵌入的关键技术之一,对自然语言处理领域产生了深远的影响。CBOW和skip-gram模型以及相关的优化方法为我们提供了理解语言结构和语义关系的有效工具。随着对Word2Vec技术的深入研究,我们可以期待它在文本处理、信息检索和自然语言理解等领域的广泛应用。





![[C#]使用OpenCvSharp实现二维码图像增强超分辨率](https://img-blog.csdnimg.cn/direct/465153b8367243ba91dda6c49d8faaef.jpeg)