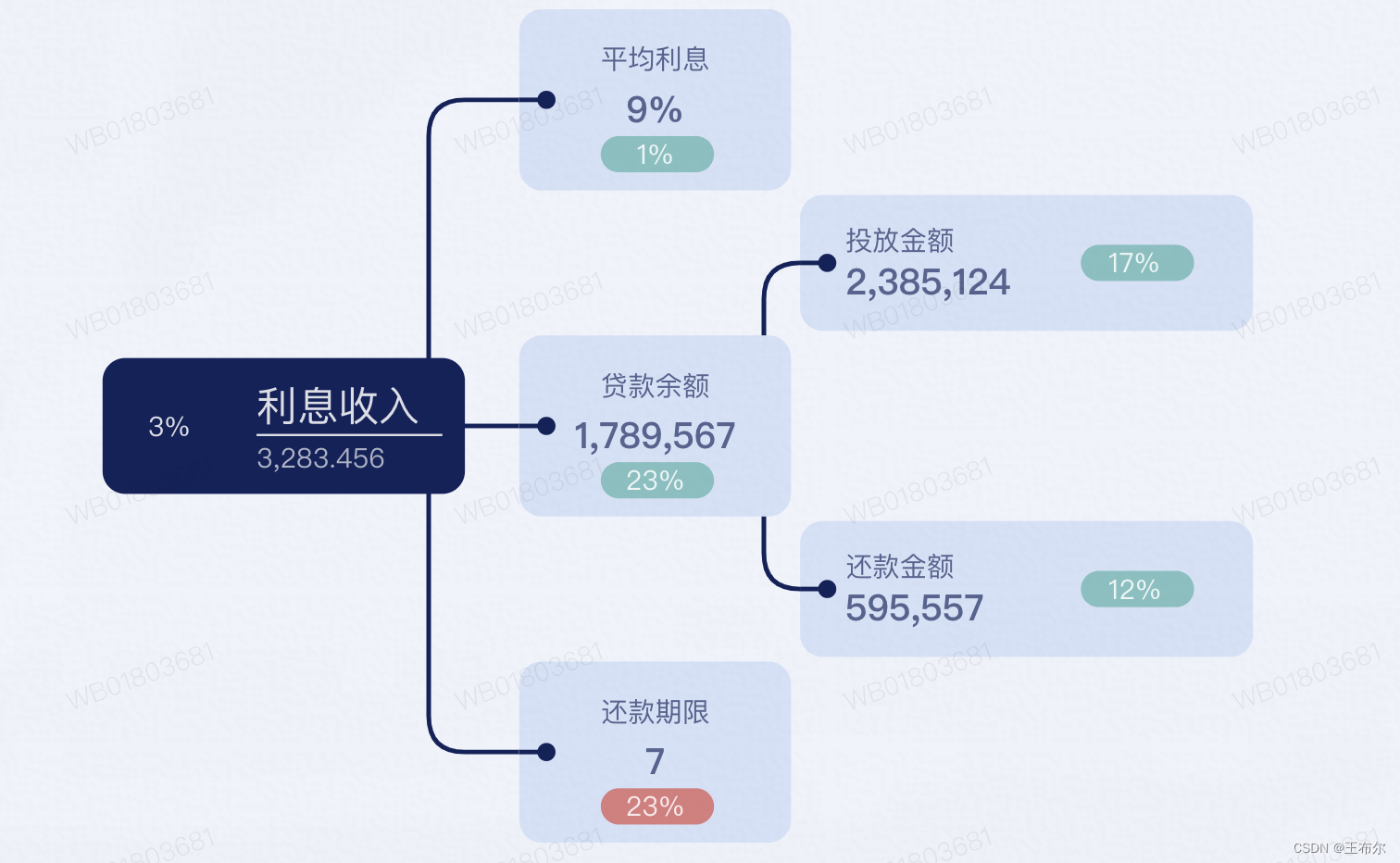
1、介绍
GELU (Gaussian Error Linear Units) 是一种基于高斯误差函数的激活函数,相较于 ReLU 等激活函数,GELU 更加平滑,有助于提高训练过程的收敛速度和性能。
# GELU激活函数的定义
def gelu(x):
return 0.5 * x * (1 + torch.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))2、公式
其中 和 0.044715 是 GELU 函数的两个调整系数。
3、图像

4、特点
-
非线性: GELU引入了非线性变换,使得神经网络能够学习更复杂的映射,有助于提高模型的表达能力。
-
平滑性: GELU是一个平滑的函数,具有连续的导数,没有梯度截断的问题,有助于梯度的稳定传播。并且GELU 在 0 附近比 ReLU 更加平滑,因此在训练过程中更容易收敛。
-
防止神经元“死亡”: 不同于ReLU在负数范围内完全置零,GELU在负数范围内引入了一个平滑的非线性,有助于防止神经元“死亡”问题。
-
高斯分布: GELU激活函数的输出在输入接近于 0 时接近于高斯分布,这有助于提高神经网络的泛化能力,使得模型更容易适应不同的数据分布。
-
计算资源效率: GELU激活函数的计算相对复杂,涉及到指数、平方根和双曲正切等运算,因此在计算资源有限的情况下可能会带来较大的计算开销。
- 趋向于线性:对于较大的输入值,GELU函数的输出趋向于线性,可能会导致一些非线性特征的丢失。
GELU 激活函数普遍应用于 Transformer 模型中。
相对于 Sigmoid 和 Tanh 激活函数,ReLU 和 GeLU 更为准确和高效,因为它们在神经网络中的梯度消失问题上表现更好。梯度消失通常发生在深层神经网络中,意味着梯度的值在反向传播过程中逐渐变小,导致网络梯度无法更新,从而影响网络的训练效果。而 ReLU 和 GeLU 几乎没有梯度消失的现象,可以更好地支持深层神经网络的训练和优化。
而 ReLU 和 GeLU 的区别在于形状和计算效率。ReLU 是一个非常简单的函数,仅仅是输入为负数时返回0,而输入为正数时返回自身,从而仅包含了一次分段线性变换。但是,ReLU 函数存在一个问题,就是在输入为负数时,输出恒为0,这个问题可能会导致神经元死亡,从而降低模型的表达能力。GeLU 函数则是一个连续的 S 形曲线,介于 Sigmoid 和 ReLU 之间,形状比 ReLU 更为平滑,可以在一定程度上缓解神经元死亡的问题。不过,由于 GeLU 函数中包含了指数运算等复杂计算,所以在实际应用中通常比 ReLU 慢。
总之,ReLU 和 GeLU 都是常用的激活函数,它们各有优缺点,并适用于不同类型的神经网络和机器学习问题。一般来说,ReLU 更适合使用在卷积神经网络(CNN)中,而 GeLU 更适用于全连接网络(FNN)。
论文链接:
[1606.08415] Gaussian Error Linear Units (GELUs) (arxiv.org)
更多深度学习内容请翻阅本人主页,下列是快速链接:
【激活函数】深度学习中你必须了解的几种激活函数 Sigmoid、Tanh、ReLU、LeakyReLU 和 ELU 激活函数(2024最新整理)-CSDN博客