为什么htmlunit与HttpClient两者都可以爬虫、网页采集、通过网页自动写入数据,我们会推荐使用htmlunit呢?
一、网页的模拟化
首先说说HtmlUnit相对于HttpClient的最明显的一个好处,HtmlUnit更好的将一个网页封装成了一个对象,如果你非要说HttpClient返回的接口HttpResponse实际上也是存储了一个对象那也可以,但是HtmlUnit不仅保存了这个网页对象,更难能可贵的是它还存有这个网页的所有基本操作甚至事件。这就是说,我们对于操作这个网页可以像在jsp中写js一样,这是非常方便的,比如:你想某个节点的上一个节点,查找所有的按钮,查找样式为“bt-style”的所有元素,对于某些元素先进行一些改造,然后再转成String,或者我直接得到这个网页之后操作这个网页,完成一次提交都是非常方便的。这意味着你如果想分析一个网页会来的非常的容易
二、网络响应的自动化处理
HtmlUnit拥有强大的响应处理机制,我们知道:常见的404是找不到资源,100等是继续,300等是跳转...我们在使用HttpClient的时候它会把响应结果告诉我们,当然,你可以自己来判断,比如说,你发现响应码是302的时候,你就在响应头去找到新的地址并自动再跳过去,发现是100的时候就再发一次请求,你如果使用HttpClient,你可以这么去做,也可以写的比较完善,但是,HtmlUnit已经较为完整的实现了这一功能,甚至说,他还包括了页面JS的自动跳转(响应码是200,但是响应的页面就是一个JS)
三、并行控制 和串行控制
既然HtmlUnit封装了那么多的底层api和hHttpClient操作,那么它有没有给我们提供自定义各种响应策略和监听整个执行过程的方法呢?,答案是肯定的。由于HtmlUnit提供的监听和控制方法比较多,我说几个大家可能接触比较少,但很有用的方法。其他的类似于:设置CSS有效,设置不抛出JS异常,设置使用SSL安全链接,诸如此类,大家通过webClient.getOptions().set***,就可以设置了,这种大家都比较熟了。
四、强大的缓存机制
为什么第一次获取一个网页可能会比较慢,但是第二次来拿就特别快呢?在HtmlUnit源码webClient类中的loadWebResponseFromWebConnection方法中我们可以看到。
以下简单介绍下如何去分析网页及涉及的代码:
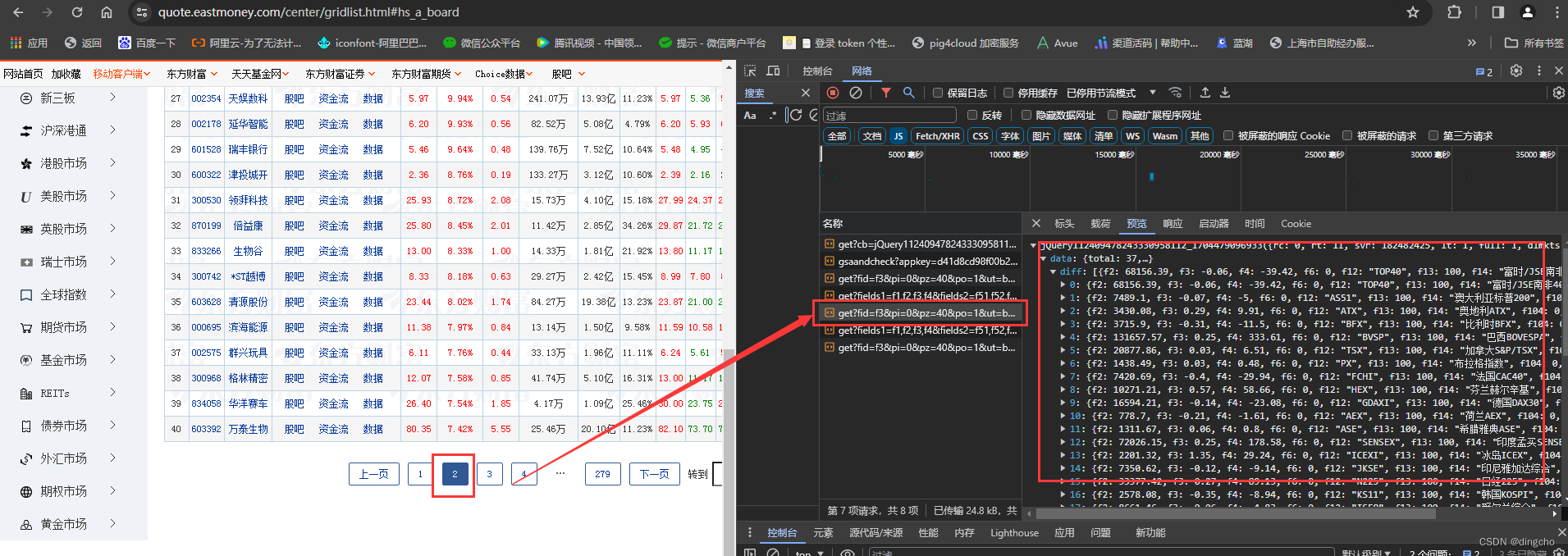
其中url可以直接浏览器访问地址直接解析页面,也可以通过分析页面请求接口(开启google浏览器F12开发者模式,刷新对应页面即可查看请求数据地址 -- >> 具体数据需要通过分享查看)
 引入maven包:
引入maven包:
<htmlunit.version>2.70.0</htmlunit.version>
<junit.version>4.13.2</junit.version>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>${htmlunit.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>@Slf4j
public class SpiderUtils {
/**
* 获取http请求
*
* @param url
* @return
* @throws Exception
*/
public static String crawlPageApi(String url) throws Exception {
// WebClient webClient = PooledClientFactory.getInstance().getClient();
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageApi();
//抓取网页
Page page = webClient.getPage(url);
//打印当前线程名称及网页标题
log.info(Thread.currentThread().getName() + " [ " + url + " ] : " + page.toString());
WebResponse response = page.getWebResponse();
String json = response.getContentAsString();
log.info(Thread.currentThread().getName() + " [ " + json + " ] : ");
return json;
}
/**
* 功能描述:抓取页面时并解析页面的js
*
* @param url
* @throws Exception
*/
public static HtmlPage crawlPageWithAnalyseJs(String url) throws Exception {
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageWithAnalyseJs();
//抓取网页
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(1000);
//打印当前线程名称及网页标题
System.out.println(Thread.currentThread().getName() + " [ " + url + " ] : " + page.getTitleText());
return page;
}
/**
* 功能描述:抓取页面时不解析页面的js
*
* @param url
* @throws Exception
*/
public static HtmlPage crawlPageWithoutAnalyseJs(String url) throws Exception {
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageWithAnalyseJs();
//抓取网页
HtmlPage page = webClient.getPage(url);
//打印当前线程名称及网页标题
System.out.println(Thread.currentThread().getName() + " [ " + url + " ] : " + page.getTitleText());
return page;
}
}
目前来说,只是简单运用爬虫爬取抓取对应数据进行分析,具体的爬取规则需要根据实际情况来制定,数据量过大的时候还需要考虑通过读写分离,分库分表来解决效率问题