在网络抓取的领域,开发人员经常面临 reCAPTCHA 的障碍。为了区分人类和自动化机器人,reCAPTCHA 可能会成为那些试图从网站提取数据的人的沉痛阻碍。然而,借助 Python 和像 Capsolver 这样的工具,可以绕过 reCAPTCHA 并继续抓取有价值的信息。
理解 reCAPTCHA:
reCAPTCHA 是由 Google 开发的广泛使用的安全措施,被网站用来防止自动机器人访问其内容。它向用户提出各种挑战,如识别对象、解决谜题或选择特定图像,以验证人类交互。
不同类型的 reCAPTCHA:
reCAPTCHA 有不同的版本以满足各种需求和安全级别:
- reCAPTCHA v1:
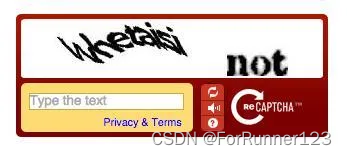
这是 reCAPTCHA 的原始版本。用户被呈现两个扭曲的单词,并需要将它们输入到文本框中。一个单词是已知单词,用于验证用户是否为人类,另一个单词是未知单词,用于帮助数字化书籍和其他来源的文本。如果在网站上看到这种风格的 CAPTCHA,这清楚地表明正在使用 reCAPTCHA v1。
- reCAPTCHA v2(标准版):
此版本引入了著名的“我不是机器人”复选框。一旦用户勾选此框,reCAPTCHA 将评估用户的行为以确定他们是否为人类。如果 reCAPTCHA 怀疑用户可能是机器人,它会呈现一个次要挑战,通常是基于图像的,以进一步验证用户是否为人类。
- reCAPTCHA v2(隐形版):
reCAPTCHA v2 的隐形变体提供与标准版本相同的安全级别,但用户体验更流畅。隐形 reCAPTCHA v2 不要求用户勾选框,而是仅在检测到可疑活动时触发验证码挑战。

- reCAPTCHA v2 企业版:
这是 reCAPTCHA v2 的更高级版本。它对抗机器人的防御更为复杂,并提供详细的风险分析。
- reCAPTCHA v3:
此版本在后台运行,评估用户与网站的交互,并分配一个分数,指示用户可能是机器人的可能性。reCAPTCHA v3 不会通过挑战打断用户的体验。

- reCAPTCHA v3 企业版:
reCAPTCHA v3 的企业版更详细地了解网站流量,并允许对可疑活动做出更细致入微的响应。
在网络抓取中的 reCAPTCHA:
网站通常使用 reCAPTCHA 作为防御机制,防止试图抓取其数据的机器人。对于网络抓取,它构成了一个重要的挑战,因为传统的抓取技术无法绕过 reCAPTCHA。
使用 Capsolver 解决 reCAPTCHA:
Capsolver,一个强大的 Python 库,通过利用机器学习算法来解决 reCAPTCHA 挑战,为用户提供了帮助。通过将 Capsolver 集成到您的网络抓取工作流中,您可以有效地自动化解决 reCAPTCHA 的过程。以下是操作步骤:
⚙️ 先决条件
有效的代理(可选,阅读两个示例,其中一个需要代理,另一个不需要代理)
已安装 Python
Capsolver API 密钥
步骤 1:安装必要的软件包
执行以下命令以安装所需的软件包:
bash
pip install capsolver 使用代理绕过 reCaptcha v2 的 Python 代码
以下是执行任务的 Python 示例脚本:
python
import capsolver
# 考虑使用环境变量存储敏感信息
PROXY = "http://username:password@host:port"
capsolver.api_key = "Your Capsolver API Key"
PAGE_URL = "PAGE_URL"
PAGE_KEY = "PAGE_SITE_KEY"
def solve_recaptcha_v2(url,key):
solution = capsolver.solve({
"type": "ReCaptchaV2Task",
"websiteURL": url,CapsolverCN官 方代理交流扣 群:497493756