1. 分布式ID生成器的使用场景
在分布式系统中,分布式ID生成器的使用场景非常之多:
- 大量的数据记录,需要分布式ID。
- 大量的系统消息,需要分布式ID。
- 大量的请求日志,如restful的操作记录,需要唯一标识,以便进行后续的用户行为分析和调用链路分析。
- 分布式节点的命名服务,往往也需要分布式ID。
- ......
传统的数据库自增主键已经不能满足需求。在分布式系统环境中,需要一种全新的唯一ID系统,这种系统需要满足以下需求:
(1)全局唯一:不能出现重复ID。
(2)高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响。
2. 分布式的ID生成器方案
生成分布式ID的方案有哪些呢? 大概有以下几种方案
- Java的UUID。
- 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
- Twitter的SnowFlake算法。
- ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID。
- MongoDb的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
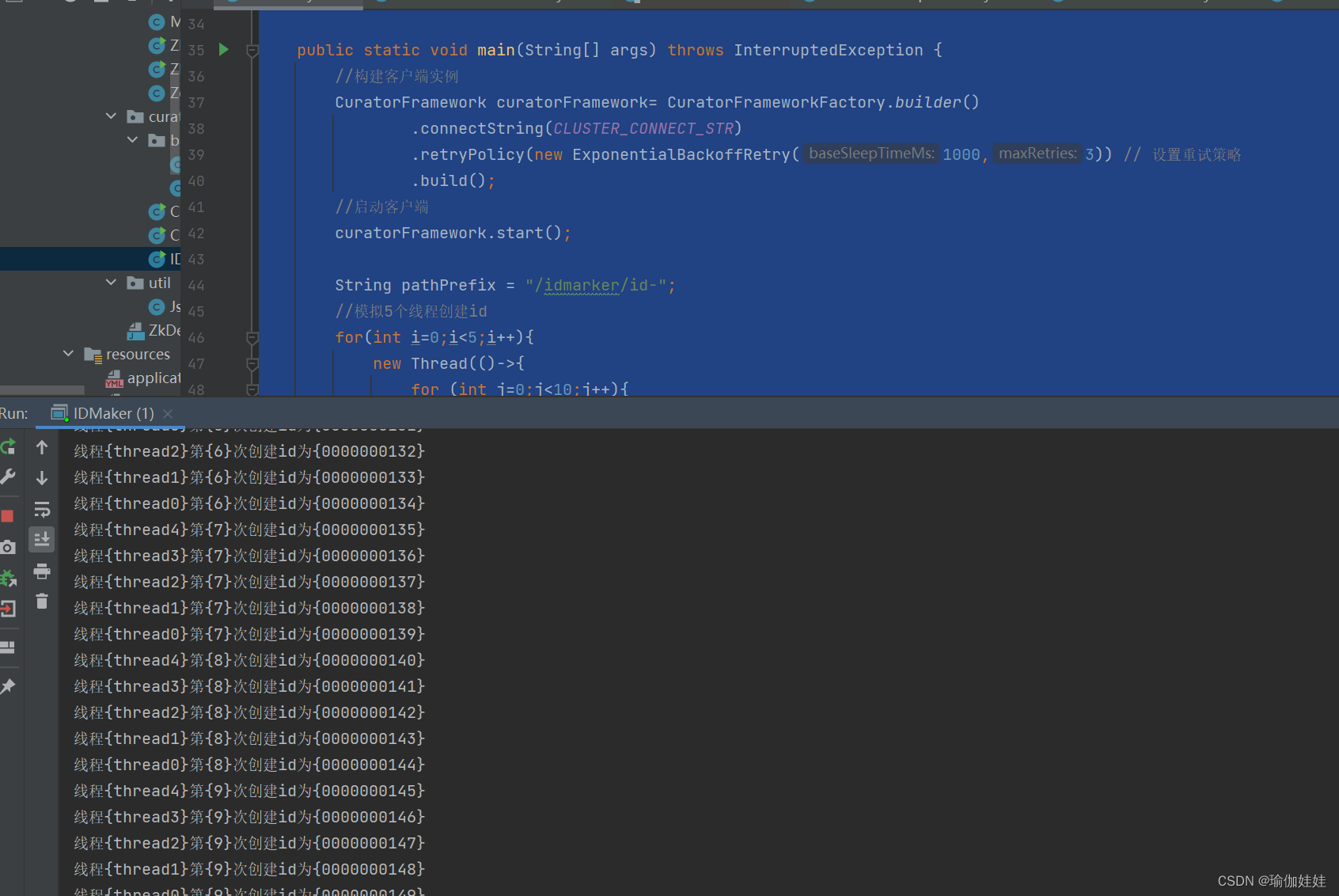
3. Zookeeper实现分布式ID生成器
接下来,我们可以通过创建ZooKeeper的临时顺序节点的方法,生成全局唯一的ID。
代码:
public class IDMaker { private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181"; private static String createSeqNode(String pathPefix,CuratorFramework curatorFramework) throws Exception { //创建一个临时顺序节点 String destPath = curatorFramework.create() .creatingParentsIfNeeded() .withMode(CreateMode.EPHEMERAL_SEQUENTIAL) .forPath(pathPefix); return destPath; } public static String makeId(String path,CuratorFramework curatorFramework) throws Exception { String str = createSeqNode(path,curatorFramework); if(null != str){ //获取末尾的序号 int index = str.lastIndexOf(path); if(index>=0){ index+=path.length(); return index<=str.length() ? str.substring(index):""; } } return str; } public static void main(String[] args) throws InterruptedException { //构建客户端实例 CuratorFramework curatorFramework= CuratorFrameworkFactory.builder() .connectString(CLUSTER_CONNECT_STR) .retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略 .build(); //启动客户端 curatorFramework.start(); String pathPrefix = "/idmarker/id-"; //模拟5个线程创建id for(int i=0;i<5;i++){ new Thread(()->{ for (int j=0;j<10;j++){ String id = null; try { id = makeId(pathPrefix,curatorFramework); System.out.println("线程{"+Thread.currentThread().getName()+"}第{"+j+"}次创建id为{"+id+"}"); } catch (Exception e) { e.printStackTrace(); } } },"thread"+i).start(); } Thread.sleep(Integer.MAX_VALUE); } }运行main方法:运行结果