LINUX 系统在多核下,以及NUMA架构技术下 如何管理物理内存?
经过初步了解 发现系统对内存有以下工作
1 映射
2 内存碎片
3 内存回收
4 内存池
5 冷热页
6 水位线和保留内存
7 支持内存条热插拔
8 大页管理
这些功能给人感觉,尤其是DBA感觉是重新实现了数据缓存池的功能!
听说 LINUX 之父 非常讨厌数据库 ORACLE和MYSQL 直接IO 绕过系统缓存. 而PG就没有绕过!
林纳斯·本纳第克特·托瓦兹(Linus Benedict Torvalds,1969年12月28日- ),芬兰赫尔辛基人,著名的电脑程序员,Linux内核的发明人及该计划的合作者,毕业于赫尔辛基大学计算机系
实际上 并发如此! 系统对内存各种骚操作,并发是针对应用来的. 通过前面两篇NUMA架构文章来说, 系统对内存的操作是针对CPU来的.
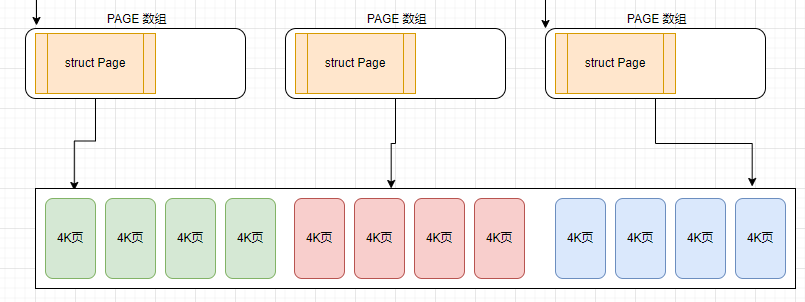
LINUX 系统把物理内存按4K大小来划分管理单元 4K 一页. 类似MYSQL 16K 一个页.ORACLE 8KB 一个块!
LINUX 系统核心是STRUCT PAGE 你认可为C++的类, JAVA的类 4K页对应一个实例,对象. PAGE数组则是存放该对象的数组.
物理内存区域中管理的就是物理内存页( Linux 内存管理的最小单位),前面我们介绍的内核对物理内存的换入,换出,回收,内存映射等操作的单位就是页。内核为每一个物理内存区域分配了一个伙伴系统,用于管理该物理内存区域下所有物理内存页面的分配和释放。
那么系统支持 4KB,8KB,2MB,4MB 等大小的物理页面,它们都是 2 的整数次幂,为啥偏偏要选 4KB 呢?
在内存紧张的时候,内核会将不经常使用到的物理页面进行换入换出等操作,还有在内存与文件映射的场景下,都会涉及到与磁盘的交互,数据在磁盘中组织形式也是根据一个磁盘块一个磁盘块来管理的,4kB 和 4MB 都是磁盘块大小的整数倍,但在大多数情况下,内存与磁盘之间传输小块数据时会更加的高效,所以综上所述内核会采用 4KB 作为默认物理内存页大小。
假设我们有 4G 大小的物理内存,每个物理内存页大小为 4K,那么这 4G 的物理内存会被内核划分为 1M 个物理内存页,内核使用一个 struct page 的结构体来描述物理内存页,而每个 struct page 结构体占用内存大小为 40 字节,那么内核就需要用额外的 40 * 1M = 40M 的内存大小来描述物理内存页。
对于 4G 物理内存而言,这额外的 40M
内存占比相对较小,这个代价勉强可以接受,但是对内存锱铢必较的内核来说,还是会尽最大努力想尽一切办法来控制 struct page 结构体的大小。
因为对于 4G 的物理内存来说,内核就需要使用 1M 个物理页面来管理,1M 个物理页的数量已经是非常庞大的了,因此在后续的内核迭代中,对于 struct page 结构的任何微小改动,都可能导致用于管理物理内存页的 struct page 实例所需要的内存暴涨。
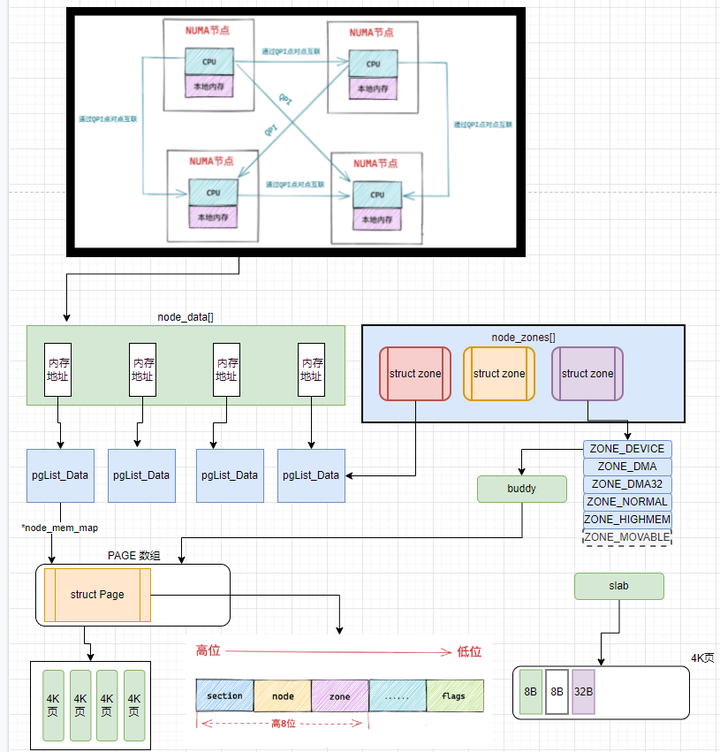
1 内核如何统一组织 NUMA 节点
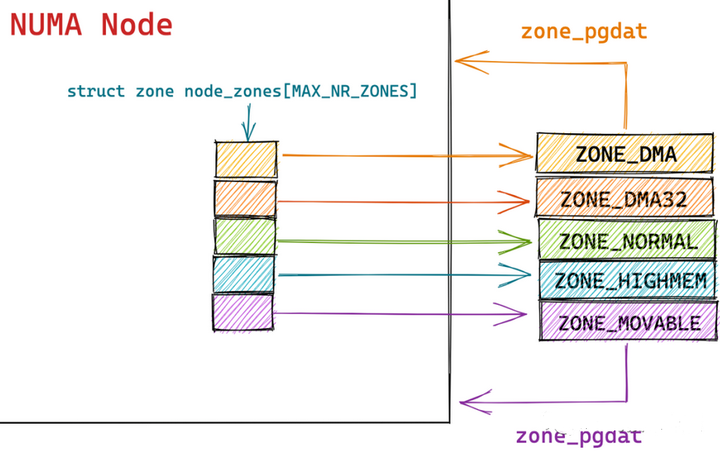
内核中使用了 struct pglist_data 这样的一个数据结构来描述 NUMA 节点,2.4 之后的版本中使用了一个大小为 MAX_NUMNODES ,类型为 struct pglist_data 的全局数组 node_data[] 来管理所有的 NUMA 节点。
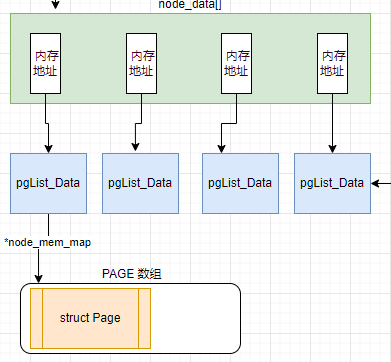
数组中每个下表存储PGLIST_DATA的变量的内存地址, 而该变量里面有存储了PAGE数组首地址; 下面是PgList_data结构体简化的内容
typedef struct pglist_data
{
// NUMA 节点id
int node_id;
// 指向 NUMA 节点内管理所有物理页 page 的数组
struct page *node_mem_map;
// NUMA 节点内第一个物理页的 pfn
unsigned long node_start_pfn;
// NUMA 节点内所有可用的物理页个数(不包含内存空洞)
unsigned long node_present_pages;
// NUMA 节点内所有的物理页个数(包含内存空洞)
unsigned long node_spanned_pages;
// 保证多进程可以并发安全的访问 NUMA 节点
spinlock_t node_size_lock;
.............
// NUMA 节点中的物理内存区域个数
int nr_zones;
// NUMA 节点中的物理内存区域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 节点的备用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
}pg_data_t;上面的NODE_MEM_MAP关联PAGE数组 4K物理内存页数组; NODE_ID 节点号, NODE_START_PFN是第一个物理页数组下标[1] 这类的 NR_ZONES: 映射区个数 NODE_ZONES 本地内存映射区数组 NODE_ZONELISTS 备用映射区数组,远端内存,其它节点的本地内存
NUMA 节点状态
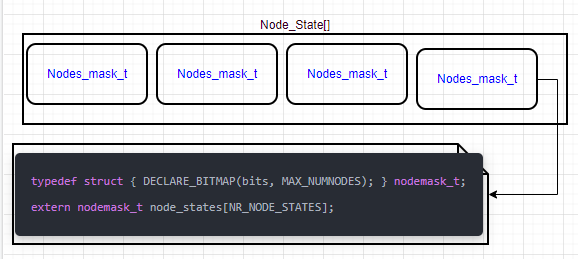
每个节点有个状态,也用数组存在,状态根据上面的位图MASK来表示
enum node_states
{
N_POSSIBLE, /* The node could become online at some point */
N_ONLINE, /* The node is online */
N_NORMAL_MEMORY, /* The node has regular memory */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};相关视频推荐
90分钟了解Linux内存架构,numa的优势,slab的实现,vmalloc的原理
庞杂的内存问题,如何理出自己的思路出来,让你开发与面试双丰收
面对内存再不发怵,手把手带你实现内存池(自行准备linux环境)
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
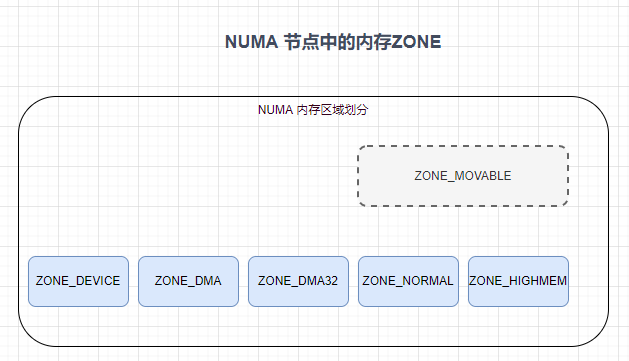
2 映射
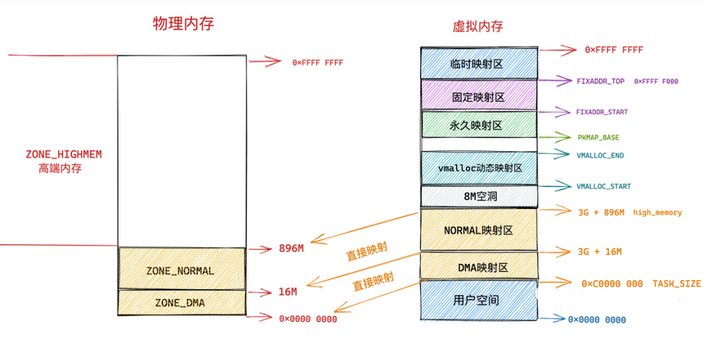
在 NUMA 架构下内存被划分成了一个一个的内存节点(NUMA Node),在每个 NUMA 节点中,内核又根据节点内物理内存的功能用途不同,将 NUMA 节点内的物理内存划分为四个物理内存区域分别是:ZONE_DMA, ZONE_DMA32, ZONE_NORMAL, ZONE_HIGHMEM。 其中 ZONE_MOVABLE 区域是逻辑上的划分,主要是为了防止内存碎片和支持内存的热插拔。
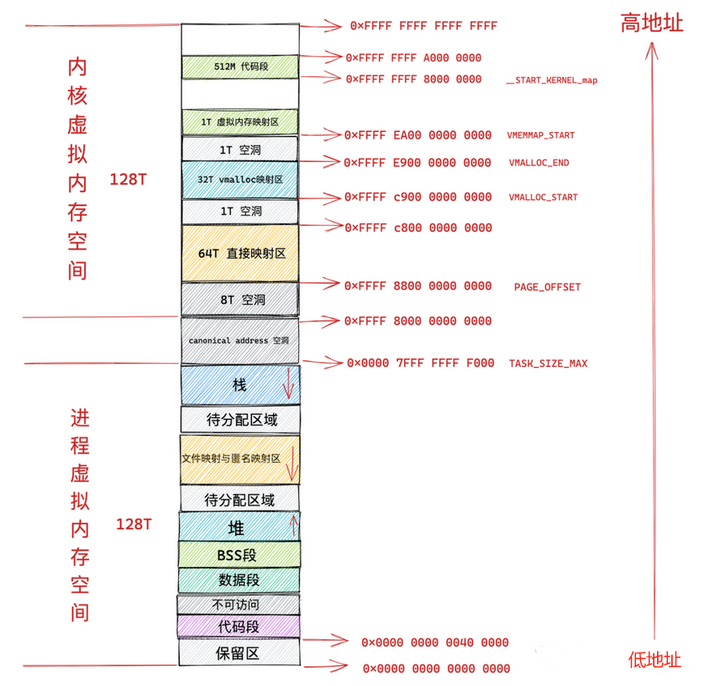
64位程序的虚拟地址空间需要映射到不同的区域里,图中的细节实际上是进程不同功能区域,这些区域需要映射到不同的内存里.就是上面的内存区域,分门别类后,方便后续的管理!
所以内核会根据各个物理内存区域的功能不同,将 NUMA 节点内的物理内存主要划分为以下四个物理内存区域:
ZONE_DMA:用于那些无法对全部物理内存进行寻址的硬件设备,进行 DMA 时的内存分配。例如前边介绍的 ISA 设备只能对物理内存的前 16M 进行寻址。该区域的长度依赖于具体的处理器类型。
ZONE_DMA32:与 ZONE_DMA 区域类似,该区域内的物理页面可用于执行 DMA 操作,不同之处在于该区域是提供给 32 位设备(只能寻址 4G 物理内存)执行 DMA 操作时使用的。该区域只在 64 位系统中起作用,因为只有在 64 位系统中才会专门为 32 位设备提供专门的 DMA 区域。
ZONE_NORMAL:这个区域的物理页都可以直接映射到内核中的虚拟内存,由于是线性映射,内核可以直接进行访问。
ZONE_HIGHMEM:这个区域包含的物理页就是我们说的高端内存,内核不能直接访问这些物理页,这些物理页需要动态映射进内核虚拟内存空间中(非线性映射)。该区域只在 32 位系统中才会存在,因为 64 位系统中的内核虚拟内存空间太大了(128T),都可以进行直接映射。
struct zone {
// 防止并发访问该内存区域
spinlock_t lock;
// 内存区域名称:Normal ,DMA,HighMem
const char *name;
// 指向该内存区域所属的 NUMA 节点
struct pglist_data *zone_pgdat;
// 属于该内存区域中的第一个物理页 PFN
unsigned long zone_start_pfn;
// 该内存区域中所有的物理页个数(包含内存空洞)
unsigned long spanned_pages;
// 该内存区域所有可用的物理页个数(不包含内存空洞)
unsigned long present_pages;
// 被伙伴系统所管理的物理页数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
// 该内存区域内存使用的统计信息
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;ZONE是管理区域的(类,对象,实例)结构体数据,
____cacheline_internodealigned_in_smp
这是一个 Linux 内核中的宏定义,用于指定在 SMP 系统中缓存行对齐。具体来说,它表示将变量或数据结构填充到缓存行中,以避免多个 CPU 核心同时访问同一缓存行时的冲突和性能损失。"cacheline" 表示缓存行,"internode" 表示非本地节点,"aligned" 表示对齐,"in_smp" 表示在 SMP 系统中使用。
在ZONE结构体里面有个内存地址变量 *zone_pgdat 类型是 struct pglist_data PgList_data 里面有Zone变量的数组, 而Zone变量又反射回PgList_Data的内存地址(指针),这样回来读取PgList_data里面的物理页的数组
3 文件页和匿名页
从系统角度来看,存放在磁盘上的都是文件,文件装入内存后占用的内存页叫文件页. 其中文件是包含程序的,也就是说文件是指程序+数据!
匿名页是由进程(程序)执行过程中申请的内存 比如全局变量,进栈出栈,以及动态内存分配.
struct page {
// 如果 page 为文件页的话,低位为0,指向 page 所在的 page cache
// 如果 page 为匿名页的话,低位为1,指向其对应虚拟地址空间的匿名映射区 anon_vma
struct address_space *mapping;
// 如果 page 为文件页的话,index 为 page 在 page cache 中的索引
// 如果 page 为匿名页的话,表示匿名页在对应进程虚拟内存区域 VMA 中的偏移
pgoff_t index;
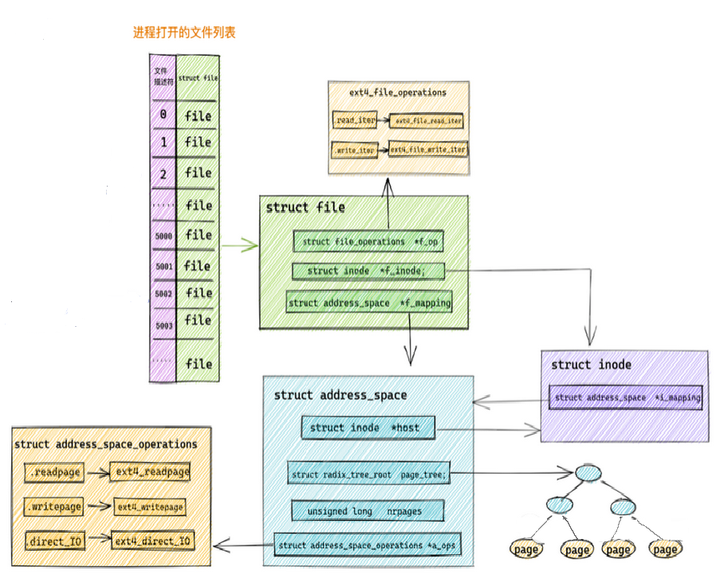
}区分文件页和匿名页由PAGE结构体里面的 *mapping低为0和1 在内核中每个文件都会有一个属于自己的 page cache(页高速缓存),页高速缓存在内核中的结构体就是这个 struct address_space。它被文件的 inode 所持有。如果当前物理内存页 struct page 是一个文件页的话,那么 mapping 指针的最低位会被设置为 0 ,指向该内存页关联文件的 struct address_space(页高速缓存),pgoff_t index 字段表示该内存页 page 在页高速缓存 page cache 中的 index 索引。内核会利用这个 index 字段从 page cache 中查找该物理内存页,同时该 pgoff_t index 字段也表示该内存页中的文件数据在文件内部的偏移 offset。偏移单位为 page size。
如果当前物理内存页 struct page 是一个匿名页的话,那么 mapping 指针的最低位会被设置为 1 , 指向该匿名页在进程虚拟内存空间中的匿名映射区域 struct anon_vma 结构(每个匿名页对应唯一的 anon_vma 结构),用于物理内存到虚拟内存的反向映射
4 页高速缓存 PAGE_CACHE
当用户进程发起 read 系统调用之后,内核首先会在 page cache 中检查请求数据所在页面是否已经缓存在 page cache 中。
-
如果缓存命中,内核直接会把 page cache 中缓存的磁盘文件数据拷贝到用户空间缓冲区中,从而避免了龟速的磁盘 IO。
-
如果缓存没有命中,内核会分配一个物理页面,将这个新分配的页面插入 page cache 中,然后调度磁盘块 IO 驱动从磁盘中读取数据,最后用从磁盘中读取的数据填充这个物里页面。page cache 中缓存的不仅有基于文件的缓存页,还会缓存内存映射文件,以及磁盘块设备文件。
page cache 在内核中的数据结构是一个叫做 address_space 的结构体:struct address_space。这个名字起的真是有点词不达意
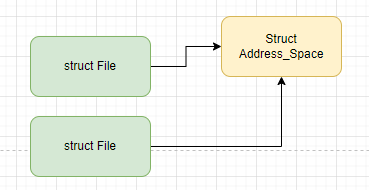
可以通过多个不同的进程打开一个相同的文件,进程每打开一个文件,内核就会为它创建 struct file 结构。这样在内核中就会有多个 struct file 结构来表示同一个文件,但是同一个文件的 page cache 也就是 struct address_space 在内核中只会有一个。
struct address_space
{
struct inode *host; // 关联 page cache 对应文件的 inode
struct radix_tree_root page_tree; // 这里就是 page cache。里边缓存了文件的所有缓存页面
spinlock_t tree_lock; // 访问 page_tree 时用到的自旋锁
unsigned long nrpages; // page cache 中缓存的页面总数
..........省略..........
const struct address_space_operations *a_ops; // 定义对 page cache 中缓存页的各种操作方法
..........省略..........
}struct inode *host :一个文件对应一个 page cache 结构 struct address_space ,文件的 inode 描述了一个文件的所有元信息。在 struct address_space 中通过 host 指针与文件的 inode 关联。而在 inode 结构体 struct inode 中又通过 i_mapping 指针与文件的 page cache 进行关联。 struct radix_tree_root page_tree : page cache 中缓存的所有文件页全部存储在 radix_tree 这样一个高效搜索树结构当中。在文件 IO 相关的操作中,内核需要频繁大量地在 page cache 中搜索请求页是否已经缓存在页高速缓存中,所以针对 page cache 的搜索操作必须是高效的,否则引入 page cache 所带来的性能提升将会被低效的搜索开销所抵消掉。
const struct address_space_operations *a_ops :a_ops 定义了 page cache 中所有针对缓存页的 IO 操作,提供了管理 page cache 的各种行为。比如:常用的页面读取操作 readPage() 以及页面写入操作 writePage() 等。保证了所有针对缓存页的 IO 操作必须是通过 page cache 进行的。page cache 中缓存的不仅仅是基于文件的页,它还会缓存内存映射页,以及磁盘块设备文件,况且基于文件的内存页背后也有不同的文件系统。所以内核只是通过 a_ops 定义了操作 page cache 缓存页 IO 的通用行为定义。而具体的实现需要各个具体的文件系统通过自己定义的 address_space_operations 来描述自己如何与 page cache 进行交互。
下面是自定义操作函数结构体.相当于类的方法
struct address_space_operations {
// 写入更新页面缓存
int (*writepage)(struct page *page, struct writeback_control *wbc);
// 读取页面缓存
int (*readpage)(struct file *, struct page *);
// 设置缓存页为脏页,等待后续内核回写磁盘
int (*set_page_dirty)(struct page *page);
// Direct IO 绕过 page cache 直接操作磁盘
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
........省略..........
}缓存页的树型结构体
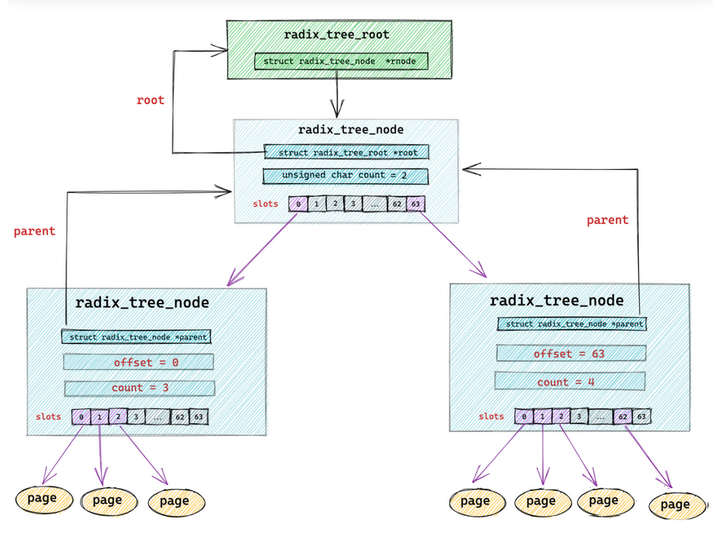
struct radix_tree_root
{
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode; // radix_tree 根节点
};
struct address_space
{
// 这里就是 page cache。里边缓存了文件的所有缓存页面
struct radix_tree_root page_tree;
..........省略..........
}
struct radix_tree_node
{
void __rcu *slots[RADIX_TREE_MAP_SIZE]; //包含 64 个指针的数组。用于指向下一层节点或者缓存页
unsigned char offset; //父节点中指向该节点的指针在父节点 slots 数组中的偏移
unsigned char count;//记录当前节点的 slots 数组指向了多少个节点
struct radix_tree_node *parent; // 父节点指针
struct radix_tree_root *root; // 根节点
..........省略.........
// radix_tree 中的二维标记数组,用于标记子节点的状态。
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};最后跟MYSQL B树差不多样
radix_tree 深度可以缓存多大的文件内容:
| radix_tree 深度 | page 最大索引值 | 缓存文件大小 |
|---|---|---|
| 1 | 2^6 - 1 = 63 | 256K |
| 2 | 2^12 - 1 = 4095 | 16M |
| 3 | 2^18 - 1 = 262143 | 1G |
| 4 | 2^24 -1 =16777215 | 64G |
| 5 | 2^30 - 1 | 4T |
| 6 | 2^36 - 1 | 64T |
在 radix_tree 是根据缓存页的 index (索引)来组织管理缓存页的,
内核会根据这个 index 迅速找到对应的缓存页。
在缓存页描述符 struct page 结构中保存了其在 page cache 中的索引 index。
struct page
{
unsigned long flags; //缓存页标记
struct address_space *mapping; // 缓存页所在的 page cache
unsigned long index; // 页索引
...
} 如果一颗 radix_tree 的深度为 2(不包括叶子节点),那么它就可以缓存 64 * 64 = 4096 个文件页,表示的索引范围为 0 - 4095,在这种情况下,缓存页索引 offset 的低 12 位可以分成 两个 6 位的字段,高位的字段用来表示第一层节点的 slots 数组的下标,低位字段用于表示第二层节点的 slots 数组下标。
这段话大意就是索引表达,通过位来实现 下面是两个函数的查找算法,大概瞄一眼就行
static inline struct page *find_get_page(struct address_space *mapping, pgoff_t offset)
{ //offset 是page cache 中的索引 index
return pagecache_get_page(mapping, offset, 0, 0);
}
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset, int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
// 在 radix_tree 中根据 缓存页 offset 查找缓存页
page = find_get_entry(mapping, offset);
// 缓存页不存在的话,跳转到 no_page 处理逻辑
if (!page)
goto no_page;
.......省略.......
no_page:
if (!page && (fgp_flags & FGP_CREAT))
{
// 分配新页
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (fgp_flags & FGP_ACCESSED)
//增加页的引用计数
__SetPageReferenced(page);
// 将新分配的内存页加入到页高速缓存 page cache 中
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
.......省略.......
}
return page;
}-
内核首先调用 find_get_entry 方法根据缓存页的 offset 到 page cache 中去查找看请求的文件页是否已经在页高速缓存中。如果存在直接返回。
-
如果请求的文件页不在 page cache 中,内核则会首先会在物理内存中分配一个内存页,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
-
随后会通过 address_space_operations 重定义的 readpage 激活块设备驱动从磁盘中读取请求数据,然后用读取到的数据填充新分配的内存页。
下面这个是结构体变量,同时赋值操作,不过这里是赋的是函数. 类似与C++构造函数, C语言中函数类型内存地址变量(指针)绑定函数名,就可以通过内存地址变量调用函数了
static const struct address_space_operations ext4_aops =
{
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};4.2 缓存中的脏页标记
快速查找 page cache 中的所有脏页。但是如果此时 page cache 中的大部分缓存页都不是脏页,那么顺序遍历 radix_tree 的方式就实在是太慢了,所以为了快速搜索到脏页,就需要在 radix_tree 中的每个节点radix_tree_node中加入一个针对其所有子节点的脏页标记,如果其中一个子节点被标记被脏时,那么这个子节点对应的父节点 radix_tree_node 结构中的对应脏页标记位就会被置 1 。
struct radix_tree_node
// radix_tree 中的二维标记数组,用于标记子节点的状态。
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];tags 二维数组。其中第一维 tags[] 用来表示标记类型,有多少标记类型,数组大小就为多少,比如 tags[0] 表示 PG_dirty 标记数组,tags[1] 表示 PG_writeback 标记数组。
最后 这样的结构体关系图:
5 NUMA 节点中的文件页和匿名页回收 LRU
系统使用4条LRU链条管理
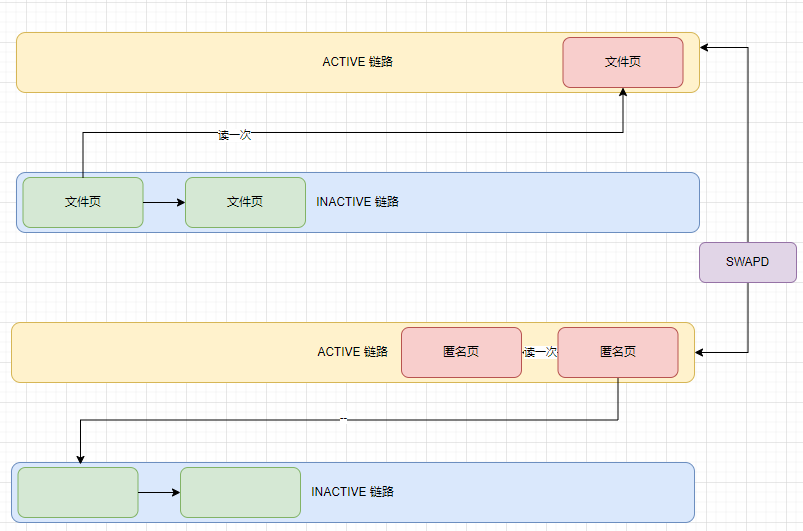
文件页第一次读取的时候存放在INACTIVE 冷链条头部,如果再被读取一次就提升到ACTIVE 热链尾部.
匿名页 第一次读取存在 热链的尾巴, 当匿名页再次被访问的时候就会被被提升到 active 链表的头部。
当遇到内存紧张的情况需要换页时,内核会从 active 链表的尾部开始扫描,将一定量的页面降级到 inactive 链表头部,这样一来原来位于 inactive 链表尾部的页面就会被置换出去。
当内存紧张的时候,内核就会优先将 inactive 链表中的内存页置换出去。
内核在回收内存的时候,这两个列表中的回收优先级为:
inactive 链表尾部 > inactive 链表头部 > active 链表尾部 > active 链表头部。
swappiness 用于表示 Swap 机制的积极程度,数值越大,Swap 的积极程度,越高越倾向于回收匿名页。数值越小,Swap 的积极程度越低,越倾向于回收文件页
struct page
{
struct list_head lru; //属性就是用来指向物理页被放置在了哪个链表上。
atomic_t _refcount; //该物理页的次数
unsigned long flags; //物理内存页属性和状态的标志位 flag物理内存页属性和状态的标志位 flag}FLAGS 高八位,低位FLAGS
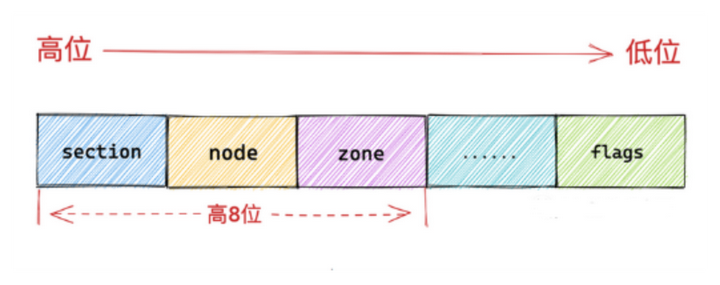
下面是页的FLAGS 在CAT/PROC/MEMINFO 也见到一二
enum pageflags
{
PG_locked, /* Page is locked. Don't touch. */
PG_referenced,
PG_uptodate,
PG_dirty,
PG_lru,
PG_active,
PG_slab,
PG_reserved,
PG_compound,
PG_private,
PG_writeback,
PG_reclaim,
#ifdef CONFIG_MMU
PG_mlocked, /* Page is vma mlocked */
PG_swapcache = PG_owner_priv_1,
................
}6 NUMA 节点中的内存回收
一般达到了内存压力大的时候系统会触发KSWAPD进程起来工作,把匿名页SWAP到磁盘上,继续紧张下去就触发更重要的内存进行 回收
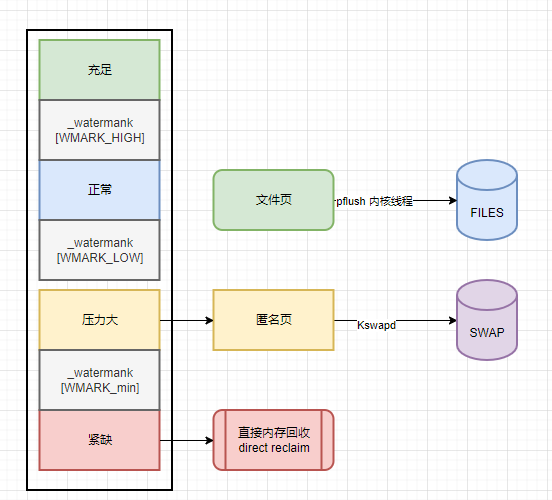
涉及以下几个相关数据结构
typedef struct pglist_data
{
.........
// 页面回收进程
struct task_struct *kswapd;
wait_queue_head_t kswapd_wait;
// 内存规整进程
struct task_struct *kcompactd;
wait_queue_head_t kcompactd_wait;
..........
} pg_data_t;
struct zone
{
// 物理内存区域中的水位线
unsigned long _watermark[NR_WMARK];
// 优化内存碎片对内存分配的影响,可以动态改变内存区域的基准水位线。
unsigned long watermark_boost;
} ____cacheline_internodealigned_in_smp;
enum zone_watermarks
{
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)也就是我们老三样其中的 zone 类和pglist_data类 (结构体)类型
7 NUMA 节点中的ZONE的水位线和保留内存
7.1 物理内存区域中的水位线
内核会为每个 NUMA 节点中的每个物理内存区域定制三条用于指示内存容量的水位线,分别是:WMARK_MIN(页最小阈值), WMARK_LOW (页低阈值),WMARK_HIGH(页高阈值)。这三条水位线定义在 /include/linux/mmzone.h 文件中:
enum zone_watermarks
{
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
struct zone
{
// 物理内存区域中的水位线
unsigned long _watermark[NR_WMARK];
// 优化内存碎片对内存分配的影响,可以动态改变内存区域的基准水位线。
unsigned long watermark_boost;
} ____cacheline_internodealigned_in_smp;这三条水位线对应的 watermark 数值存储在每个物理内存区域 struct zone 结构中的 _watermark[NR_WMARK] 数组中。
cat /proc/zoneinfo
水位线:
-
free 就是该物理内存区域内剩余的内存页数,它的值和后面的 nr_free_pages 相同。
-
min、low、high 就是上面提到的三条内存水位线:_watermark[WMARK_MIN],_watermark[WMARK_LOW] ,_watermark[WMARK_HIGH]。
-
nr_zone_active_anon 和 nr_zone_inactive_anon 分别是该内存区域内活跃和非活跃的匿名页数量。
-
nr_zone_active_file 和 nr_zone_inactive_file 分别是该内存区域内活跃和非活跃的文件页数量。
WMARK_MIN,WMARK_LOW ,WMARK_HIGH 这三个水位线的数值是通过内核参数 /proc/sys/vm/min_free_kbytes 为基准分别计算出来的
通常情况下 WMARK_LOW 的值是 WMARK_MIN 的 1.25 倍,WMARK_HIGH 的值是 WMARK_LOW 的 1.5 倍。
而 WMARK_MIN 的数值就是由这个内核参数 min_free_kbytes 来决定的。
7.2 预留内存
每个物理内存区域 struct zone 还为操作系统预留了一部分内存,这部分预留的物理内存用于内核的一些核心操作,这些操作无论如何是不允许内存分配失败的。内核中关于内存分配的场景无外乎有两种方式:
-
当进程请求内核分配内存时,如果此时内存比较充裕,那么进程的请求会被立刻满足,如果此时内存已经比较紧张,内核就需要将一部分不经常使用的内存进行回收,从而腾出一部分内存满足进程的内存分配的请求,在这个回收内存的过程中,进程会一直阻塞等待。
-
另一种内存分配场景,进程是不允许阻塞的,内存分配的请求必须马上得到满足,比如执行中断处理程序或者执行持有自旋锁等临界区内的代码时,进程就不允许睡眠,因为中断程序无法被重新调度。这时就需要内核提前为这些核心操作预留一部分内存,当内存紧张时,可以使用这部分预留的内存给这些操作分配。
struct zone
{
//表示的是该内存区域内预留内存的大小,范围为 128 到 65536 KB 之间。
unsigned long nr_reserved_highatomic;
long lowmem_reserve[MAX_NR_ZONES];
//数组则是用于规定每个内存区域必须为自己保留的物理页数量
}一些用于特定功能的物理内存必须从特定的内存区域中进行分配,比如外设的 DMA 控制器就必须从 ZONE_DMA 或者 ZONE_DMA32 中分配内存。
但是一些用于常规用途的物理内存则可以从多个物理内存区域中进行分配,当 ZONE_HIGHMEM 区域中的内存不足时,内核可以从 ZONE_NORMAL 进行内存分配,ZONE_NORMAL 区域内存不足时可以进一步降级到 ZONE_DMA 区域进行分配。
而低位内存区域中的内存总是宝贵的,内核肯定希望这些用于常规用途的物理内存从常规内存区域中进行分配,这样能够节省 ZONE_DMA 区域中的物理内存保证 DMA 操作的内存使用需求,但是如果内存很紧张了,高位内存区域中的物理内存不够用了,那么内核就会去占用挤压其他内存区域中的物理内存从而满足内存分配的需求。
但是内核又不会允许高位内存区域对低位内存区域的无限制挤压占用,因为毕竟低位内存区域有它特定的用途,所以每个内存区域会给自己预留一定的内存,防止被高位内存区域挤压占用。而每个内存区域为自己预留的这部分内存就存储在 lowmem_reserve 数组中。每个内存区域是按照一定的比例来计算自己的预留内存的,这个比例我们可以通过 cat /proc/sys/vm/lowmem_reserve_ratio 命令查看从左到右分别代表了 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_MOVABLE,ZONE_DEVICE 物理内存区域的预留内存比例。服务器是 64 位,所以没有 ZONE_HIGHMEM 区域。
以 ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM 这三个物理内存区域举例,它们的 lowmem_reserve_ratio 分别为 256,32,0。它们的大小分别是:8M,64M,256M,按照每页大小 4K 计算它们区域里包含的物理页个数分别为:2048, 16384, 65536。
| lowmem_reserve_ratio | 内存区域大小 | 物理内存页个数 | |
|---|---|---|---|
| ZONE_DMA | 256 | 8M | 2048 |
| ZONE_NORMAL | 32 | 64M | 16384 |
| ZONE_HIGHMEM | 0 | 256M | 65536 |
ZONE_DMA 为防止被 ZONE_NORMAL 挤压侵占,而为自己预留的物理内存页为:16384 / 256 = 64。
ZONE_NORMAL 为防止被 ZONE_HIGHMEM 挤压侵占而为自己预留的物理内存页为:65536 / 32 = 2048。
上面两个算法有点绕, 我也没有研究清楚
各个内存区域为防止被高位内存区域过度挤压占用,而为自己预留的内存大小,
我们可以通过前边 cat /proc/zoneinfo 命令来查看,输出信息的
protection:则表示各个内存区域预留内存大小。
8 NUMA 节点中的内存冷热页
在 NUMA 内存架构下,这些 NUMA 节点中的物理内存区域 zone 管理的这些物理内存页,哪些是在 CPU 的高速缓存中?哪些又不在 CPU 的高速缓存中呢?内核如何来管理这些加载进 CPU 高速缓存中的物理内存页呢?
冷热页使用2个结构体数据表达
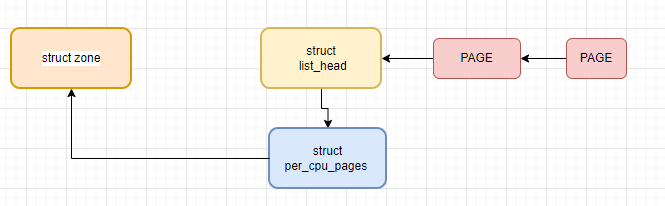
因为每个 CPU 都有自己独立的高速缓存,所以每个 CPU 对应一个 per_cpu_pages 结构,在内核版本 2.6.25 之后,将冷页和热页的管理合并在了一个列表中,热页放在列表的头部,冷页放在列表的尾部。
struct per_cpu_pages
{
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
.............省略............
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[NR_PCP_LISTS];
};struct zone
{
struct per_cpu_pages __percpu *per_cpu_pageset;
int pageset_high;
int pageset_batch;
} ____cacheline_internodealigned_in_smp;9 大页 compound_page
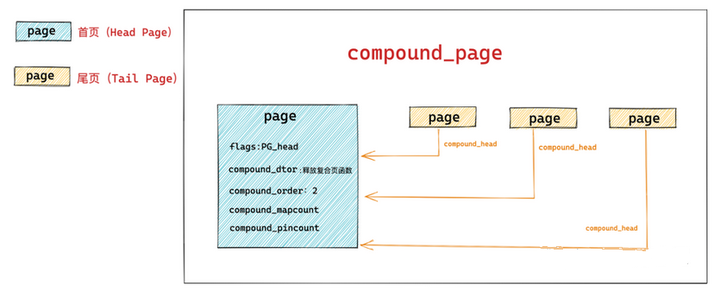
Linux 内存管理架构中都是统一通过 struct page 来管理内存,而巨型大页却是通过两个或者多个物理上连续的内存页 page 组装成的一个比普通内存页 page 更大的页,那么巨型页的管理与普通页的管理如何统一?
struct page
{
// 首页 page 中的 flags 会被设置为 PG_head 表示复合页的第一页
unsigned long flags;
// 其余尾页会通过该字段指向首页
unsigned long compound_head;
// 用于释放复合页的析构函数,保存在首页中
unsigned char compound_dtor;
// 该复合页有多少个 page 组成,order 还是分配阶的概念,首页中保存
// 本例中的 order = 2 表示由 4 个普通页组成
unsigned char compound_order;
// 该复合页被多少个进程使用,内存页反向映射的概念,首页中保存
atomic_t compound_mapcount;
// 复合页使用计数,首页中保存
atomic_t compound_pincount;
}首页中还保存关于复合页的一些额外信息,比如用于释放复合页的析构函数会保存在首页 struct page 结构里的 compound_dtor 字段中,复合页的分配阶 order 会保存在首页中的 compound_order 中,以及用于指示复合页的引用计数 compound_pincount,以及复合页的反向映射个数(该复合页被多少个进程的页表所映射)compound_mapcount 均在首页中保存。
复合页中的所有尾页都会通过其对应的 struct page 结构中的 compound_head 指向首页,这样通过首页和尾页就组装成了一个完整的复合页 compound_page 。
10 内存分配器
linux用两个内存分配器分配内存 分别是伙伴系统 buddy和SLAB.
BUDDY 在每个ZONE里面分配4K页内存,而SLAB是在4KB页里面分配更小的内存!
slab 就好比一个对象池,内核中的数据结构对象都对应于一个 slab 对象池,用于分配这些固定类型对象所需要的内存。
它的基本原理是从伙伴系统中申请一整页内存,然后划分成多个大小相等的小块内存被 slab 所管理。这样一来 slab 就和物理内存页 page 发生了关联,由于 slab 管理的单元是物理内存页 page 内进一步划分出来的小块内存,所以当 page 被分配给相应 slab 结构之后,struct page 里也会存放 slab 相关的一些管理数据。下面PAGE有些复杂了
struct page {
struct { /* slab, slob and slub */
union {
struct list_head slab_list;
struct { /* Partial pages */
struct page *next;
#ifdef CONFIG_64BIT
int pages; /* Nr of pages left */
int pobjects; /* Approximate count */
#else
short int pages;
short int pobjects;
#endif
};
};
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
union {
void *s_mem; /* slab: first object */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
}-
struct list_head slab_list :slab 的管理结构中有众多用于管理 page 的链表,比如:完全空闲的 page 链表,完全分配的 page 链表,部分分配的 page 链表,slab_list 用于指定当前 page 位于 slab 中的哪个具体链表上。
-
struct page *next : 当 page 位于 slab 结构中的某个管理链表上时,next 指针用于指向链表中的下一个 page。
-
int pages : 表示 slab 中总共拥有的 page 个数。
-
int pobjects : 表示 slab 中拥有的特定类型的对象个数。
-
struct kmem_cache *slab_cache : 用于指向当前 page 所属的 slab 管理结构,通过 slab_cache 将 page 和 slab 关联起来。
-
void *freelist : 指向 page 中的第一个未分配出去的空闲对象,前面介绍过,slab 向伙伴系统申请一个或者多个 page,并将一整页 page 划分出多个大小相等的内存块,用于存储特定类型的对象。
-
void *s_mem : 指向 page 中的第一个对象。
-
unsigned inuse : 表示 slab 中已经被分配出去的对象个数,当该值为 0 时,表示 slab 中所管理的对象全都是空闲的,当所有的空闲对象达到一定数目,该 slab 就会被伙伴系统回收掉。
-
unsigned objects : slab 中所有的对象个数。
-
unsigned frozen : 当前内存页 page 被 slab 放置在 CPU 本地缓存列表中,frozen = 1,否则 frozen = 0 。
最后每个NODE 管理每个ZONE ,
每个ZONE管理PAGES或者SECTION,
每个SECTION管理连续的PAGES
其中三大数据结构 STRUCT PAGE, STRUCT ZONE,STRUCT PGLIST_DATA