系列文章目录
机器学习(一) -- 概述
机器学习(二) -- 数据预处理(1-3)
机器学习(三) -- 特征工程(1-2)
未完待续……
目录
系列文章目录
前言
一、特征工程简介
1、特征工程定义:
2、特征工程包含内容:
二、特征提取
1、定义
2、字典特征提取
3、文本特征提取
3.1、 英文文本分词
3.1.1、停用词方法
3.2、中文文本分词
3.2.1、普通方法
3.2.2、jieba实现自动分词
3.2.3、Tf-idf文本特征提取
机器学习(三) -- 特征工程(2)
前言
tips:这里只是总结,不是教程哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
一、特征工程简介
其实数据预处理和特征工程,两者并无明显的界限,都是为了更好的探索数据集的结构,获得更多的信息,将数据送入模型中之前进行整理。可以说数据预处理是初级的特征处理,特征工程是高级的数据预处理,也可以说这里的预处理过程是广义的,包含所有的建模前的数据预处理过程。
(简单理解,就是数据预处理是数据本身的问题,如数据缺失;特征工程是为了更好的让数据进行机器学习,如进行降维)
为什么需要特征工程?
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
所以需要在特征上下功夫。
1、特征工程定义:
特征工程是使用一定技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。会直接影响机器学习的效果。
2、特征工程包含内容:
特征提取(特征抽取)、特征预处理、特征降维
(基本上==特征构建、特征变换(特征缩放)、特征选择)
二、特征提取
1、定义
将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
注:特征值是为了计算机更好的去理解数据。
主要分为字典特征提取(特征离散化)、文本特征提取、图像特征提取(深度学习再介绍)
特征提取API是
sklearn.feature_extraction2、字典特征提取
字典特征提取API
sklearn.feature_extraction.DictVectorizer
导入:
from sklearn.feature_extraction import DictVectorizer# 创建数据集
data = [{'name':'薰悟空', 'age':1160},
{'name':'朱八姐', 'age':235},
{'name':'傻无能', 'age':9000}]
# 提取特征值,转化为稀疏矩阵
# 1、实例化转换器类
transfer = DictVectorizer()
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('稀疏矩阵特征值\n', feature_data)
print('特征名字:', transfer.get_feature_names())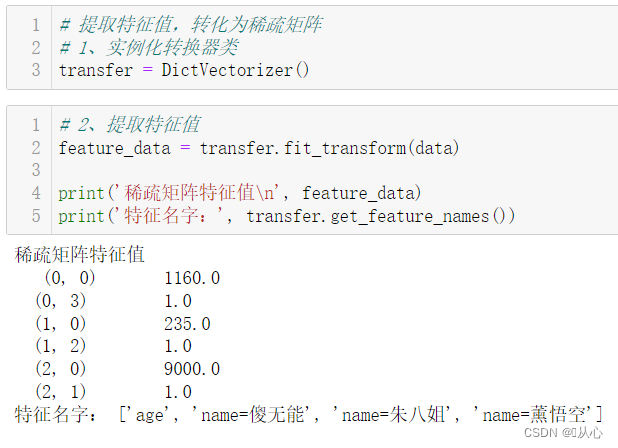
DictVectorizer()使用默认参数会返回一个稀疏矩阵(sparse矩阵)。其实就是一个和下面的操作出现的一样的矩阵,只是采用三元组的格式保存,能减少存储空间的开销。
三元组:(行号,列号,元素值)
上面稀疏矩阵特征值换为矩阵为:
| 0(age) | 1(name=傻无能) | 2(name=朱八姐) | 3(name=薰悟空) | |
|---|---|---|---|---|
| 0 | 1160 | 0 | 0 | 1 |
| 1 | 235 | 0 | 1 | 0 |
| 2 | 9000 | 1 | 0 | 0 |
然后特征名称对应的就是分别的列号,即0为‘age’,1为‘name=傻无能’,2为‘name=朱八姐’,3为‘name=薰悟空’。
DictVectorizer(sparse=False)返回一个One-hot编码矩阵。
# 提取特征值,转化为二维矩阵
# 1、实例化转换器类
transfer = DictVectorizer(sparse=False)
# 2、提取特征值
feature_data = transfer.fit_transform(data)
print('二维矩阵特征值:\n', feature_data)
print('特征名字:', transfer.get_feature_names())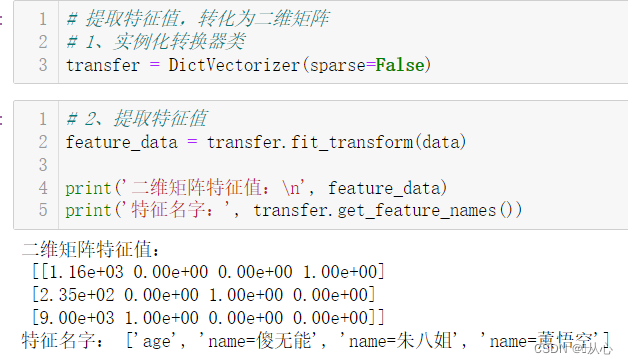
一般这样使用。
3、文本特征提取
文本特征提取API
sklearn.feature_extraction.text.CountVectorizer
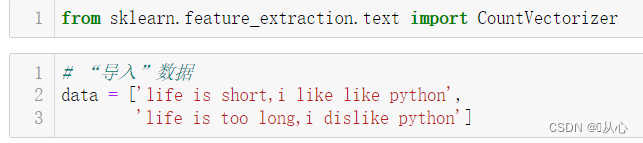
导入:
from sklearn.feature_extraction.text import CountVectorizer3.1、 英文文本分词
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray()) # toarray转换为二维数组
print("特征名字:\n", transfer.get_feature_names())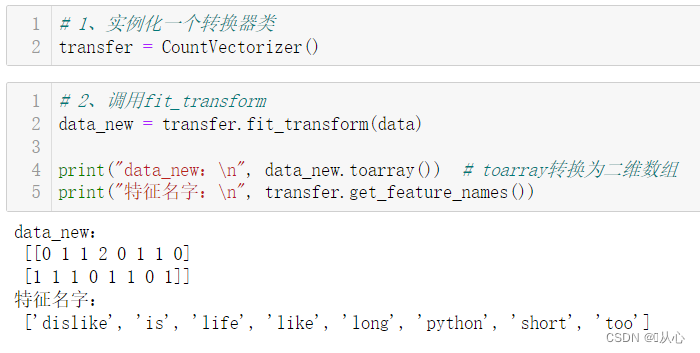
一样把特征名字和列名对应上去
| 0(dislike) | 1(is) | 2(life) | 3(like) | 4(long) | 5(python) | 6(short) | 7(too) | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 2 | 0 | 1 | 1 | 0 |
| 2 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
3.1.1、停用词方法
给转换器传入停用词的列表,stop_words=['is', 'too'],其中的词不会被提取。
transfer = CountVectorizer(stop_words=['is', 'too'])
3.2、中文文本分词
3.2.1、普通方法
这种实现只能通过给中文加空格才行。

# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray()) # toarray转换为二维数组
print("特征名字:\n", transfer.get_feature_names())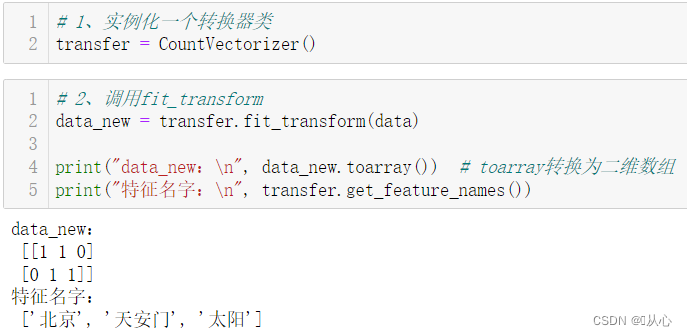
3.2.2、jieba实现自动分词
需要先下载jieba哟
pip install jieba

def cut_word(text):
return ' '.join(jieba.cut(text))
def count_chinese_demo2():
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
count_chinese_demo2()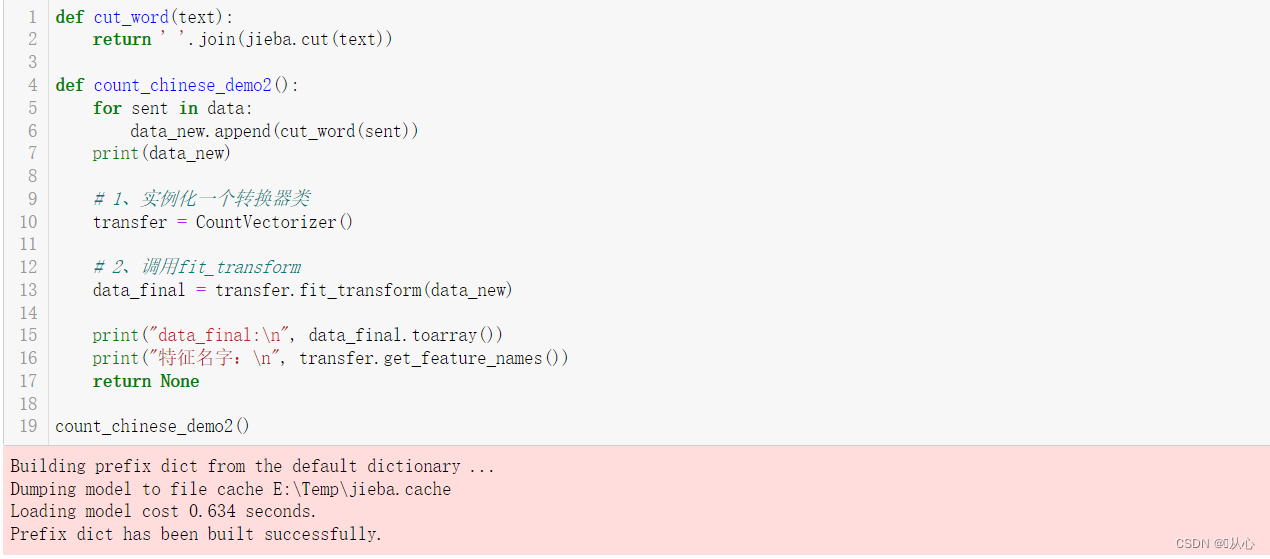

3.2.3、Tf-idf文本特征提取
Tf-idf文本特征提取API:
sklearn.feature_extraction.text.TfidfVectorizer
导入:
from sklearn.feature_extraction.text import TfidfVectorizer
Tf-idf的主要思想:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF:词频(term frequency,tf),指的是某一个给定的词语在该文件中出现的频率。
IDF:逆向文档频率(inverse document frequency,idf),是一个词语普遍重要性的度量,某一特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
 ,其得出结果可以理解为重要程度
,其得出结果可以理解为重要程度
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
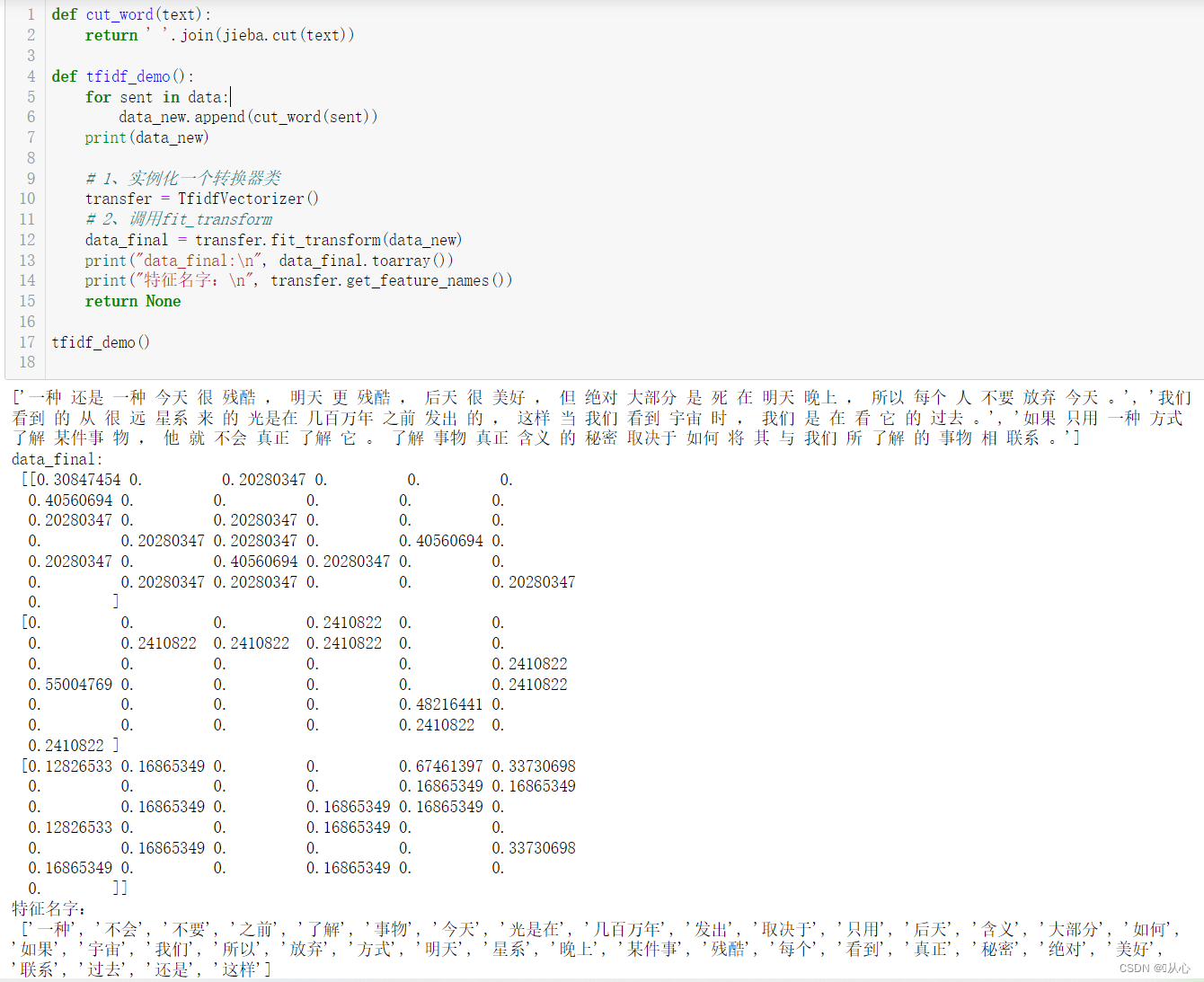
def cut_word(text):
return ' '.join(jieba.cut(text))
def tfidf_demo():
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 1、实例化一个转换器类
transfer = TfidfVectorizer()
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
tfidf_demo()