持续更新中…
目录
- 性能
- 防抖、节流
- 防抖(debounce)
- 节流(throttle)
- 防抖节流的区别:
- 图片/视频/音频压缩
- 减少请求发送次数
- 减少重绘与回流
- 经常要切换消失与出现状态的节点用v-show而不用v-if
- 按需引入
- 路由懒加载
- 懒加载
- 图片懒加载
- 列表懒加载
- 精灵/雪碧图
- Webpack优化前端性能
- 提高Webpack的构建速度
- 安全性
- XSS攻击
- CSRF攻击
性能
防抖、节流
防抖(debounce)
防抖严格算起来应该属于性能优化的知识,但实际上遇到的频率相当高,处理不当或者放任不管就容易引起浏览器卡死。
从滚动条监听的例子说起
function showTop () {
var scrollTop = document.documentElement.scrollTop;
console.log('滚动条位置:' + scrollTop);
}
window.onscroll = showTop
在运行的时候会发现存在一个问题:这个函数的默认执行频率,太!高!了!。 高到什么程度呢?以chrome为例,我们可以点击选中一个页面的滚动条,然后点击一次键盘的【向下方向键】,会发现函数执行了8-9次!
然而实际上我们并不需要如此高频的反馈,毕竟浏览器的性能是有限的,不应该浪费在这里,所以接着讨论如何优化这种场景。
基于上述场景,首先提出第一种思路:在第一次触发事件时,不立即执行函数,而是给出一个期限值比如200ms,然后
- 如果在200ms内没有再次触发滚动事件,那么就执行函数
- 如果在200ms内再次触发滚动事件,那么当前的计时取消,重新开始计时
效果:如果同样的事件它们触发的时间间隔小于规定的间隔,那么只执行一次该事件的回调函数
实现:既然前面都提到了计时,那实现的关键就在于setTimeout这个函数,由于还需要一个变量来保存计时,考虑维护全局纯净,可以借助闭包来实现
function debounce(fn,delay){
let timer = null //借助闭包
return function() {
if(timer){
clearTimeout(timer) //清除之前的定时器
// timer=null // 测试过了,这一句没有也行
}
timer = setTimeout(fn,delay) //开启新的定时器
}
}
// 然后是旧代码
function showTop () {
var scrollTop = document.documentElement.scrollTop;
console.log('滚动条位置:' + scrollTop);
}
window.onscroll = debounce(showTop,300)//滚动的时候会触发多次debounce()
防抖通用模板
function debounce(fn,delay){
let timer = null //借助闭包
return function() {
let context=this, args=[...arguments] // 保存this对象及参数
if(timer){
clearTimeout(timer) //清除之前的定时器
// timer=null // 测试过了,这一句没有也行
}
timer = setTimeout(()=>{
fn.apply(context,args)
},delay) //开启新的定时器
}
}
// 原来事件的回调
function fn(<事件回调的一些参数>) {
// 回调函数的操作
}
事件绑定的对象.事件类型 = debounce(fn,<时间>,<事件回调的一些参数>)//滚动的时候会触发多次
到这里,已经把防抖实现了
防抖定义
对于短时间内连续触发的事件(上面的滚动事件),防抖的含义就是让某个时间期限(如上面的1000毫秒)内,事件处理函数只执行一次
实时效果反馈
1. 以下是关于定时器防抖代码,横线处填写代码是:
function debounce(fn,delay){
let timer = null
return function() {
if(timer){
_2_(timer)
}
timer = _1_(fn,delay)
}
}
function showTop () {
var scrollTop = document.documentElement.scrollTop;
console.log('滚动条位置:' + scrollTop);
}
window.onscroll = debounce(showTop,300)
A setTimeout clearInterval
B setTimeout clearTimeout
C setInterval clearTimeout
D setInterval clearInterval
答案
1=>B
节流(throttle)
节流严格算起来应该属于性能优化的知识,但实际上遇到的频率相当高,处理不当或者放任不管就容易引起浏览器卡死
继续思考,使用上面的防抖方案来处理问题的结果是
如果在限定时间段内,不断触发滚动事件(比如某个用户闲着无聊,按住滚动不断的拖来拖去),只要不停止触发,理论上就永远不会输出当前距离顶部的距离
但是如果产品同学的期望处理方案是:即使用户不断拖动滚动条,也能在某个时间间隔之后给出反馈呢?
其实很简单:我们可以设计一种类似控制阀门一样定期开放的函数,也就是让函数执行一次后,在某个时间段内暂时失效,过了这段时间后再重新激活(类似于技能冷却时间)
效果:如果短时间内大量触发同一事件,那么在回调执行一次之后,该回调在指定的时间期限内不会再触发,过了这段时间才可以
实现
个人推荐时间戳版,因为定时器版第一次触发的回调会在delay时间后执行
时间戳版
function throttle(fn, delay) {
var preTime=Date.now() // 获取当前时间戳,这个变量必须在外层函数和内层函数之间定义。否则每次调用throttle函数preTime的值都是调用throttle函数时的时间,无法达到计算时间段的效果
return function(){
var context =this, args=[...arguments], nowTime=Date.now()
if(nowTime-preTime>delay){
fn.apply(context,args)
preTime=Date.now()
}
}
}
定时器版
这里借助setTimeout来做一个简单的实现,加上一个状态位valid来表示当前函数是否处于工作状态
function throttle(fn,delay){
let timer = null // 初始肯定是不被冻结的
return function() {
let context=this, args=[...arguments];
if(!timer){
timer=setTimeout(function(){
fn().apply(context,args)
timer = null // 记得执行完定时器中的操作后将timer置空,timer为null的时候表示在设定的时间外,没有被冻结
}, delay)
}
}
}
function showTop () {
var scrollTop = document.documentElement.scrollTop;
console.log('滚动条位置:' + scrollTop);
}
window.onscroll = throttle(showTop,300)
如果一直拖着滚动条进行滚动,那么会以300ms的时间间隔,持续输出当前位置和顶部的距离
讲完了这两个技巧,下面介绍一下平时开发中常遇到的场景:
- 搜索框input事件,例如要支持输入实时搜索可以使用节流方案(间隔一段时间就必须查询相关内容),或者实现输入间隔大于某个值(如500ms),就当做用户输入完成,然后开始搜索,具体使用哪种方案要看业务需求
- 页面resize事件,常见于需要做页面适配的时候。需要根据最终呈现的页面情况进行dom渲染(这种情形一般是使用防抖,因为只需要判断最后一次的变化情况)
实时效果反馈
1. 以下是关于定时器节流代码,横线处填写代码是:
function throttle(fn,delay){
let valid = true
return function() {
if(_1_){
return false
}
valid = false
_2_(function(){
fn()
valid = true;
}, delay)
}
}
A valid setTimeout
B valid setInterval
C !valid setTimeout
D !valid setInterval
答案
1=>C
防抖节流的区别:
防抖:从字面上看是为了避免短时间内大量同样事件回调执行的次数,在规定时间间隔内触发的事件,会导致计时重新开始,以最后一次事件为准
节流:从字面上看是为了减少事件回调执行的次数,事件触发后一段时间内不可再次执行事件回调,有一段事件冻结的时间,但不会重新开始计时
图片/视频/音频压缩
减少请求发送次数
减少重绘与回流
经常要切换消失与出现状态的节点用v-show而不用v-if
按需引入
比如按需引入element-ui中的组件
路由懒加载
懒加载
使用场景:懒加载适用于图片或列表较多,页面列表较长(长列表)的场景中。由于很多图片和列表还没出现在视口中,所以没有必要去加载它们浪费性能。当用户滚动页面快要看到它们才发起请求,加载图片或列表
实现原理:当图片或列表出现或接近可视区时才加载图片。对于图片,将图片的真实地址赋值给图片src属性即可。
图片懒加载
方法一(推荐,简单,但兼容性不太好):设置<img src="图片地址" loading="lazy" />或<img src="图片地址" loading="lazy" decoding="async" />
详细参考https://segmentfault.com/a/1190000020109563
decoding:为浏览器提供图像解码方式上的提示。允许的值:
- sync:同步解码图像,实现与其他内容互斥的原子渲染。
- async:异步解码图像,以减少其他内容的渲染延迟。
- auto:默认值:不指定解码方式,由浏览器决定哪一种对用户来说是最合适的。
loading:指示浏览器应当如何加载该图像。允许的值:
- eager:立即加载图像,不管它是否在可视视口(visible viewport)之外(默认值)。
- lazy:延迟加载图像,直到它和视口接近到一个计算得到的距离(由浏览器定义)。目的是在需要图像之前,避免加载图像所需要的网络和存储带宽。这通常会提高大多数典型用场景中内容的性能。
这是新增的属性,注意需要考虑兼容性


方法二(兼容性较好,但性能差):监听scroll事件,比较图片距离视口顶部和窗口大小的关系
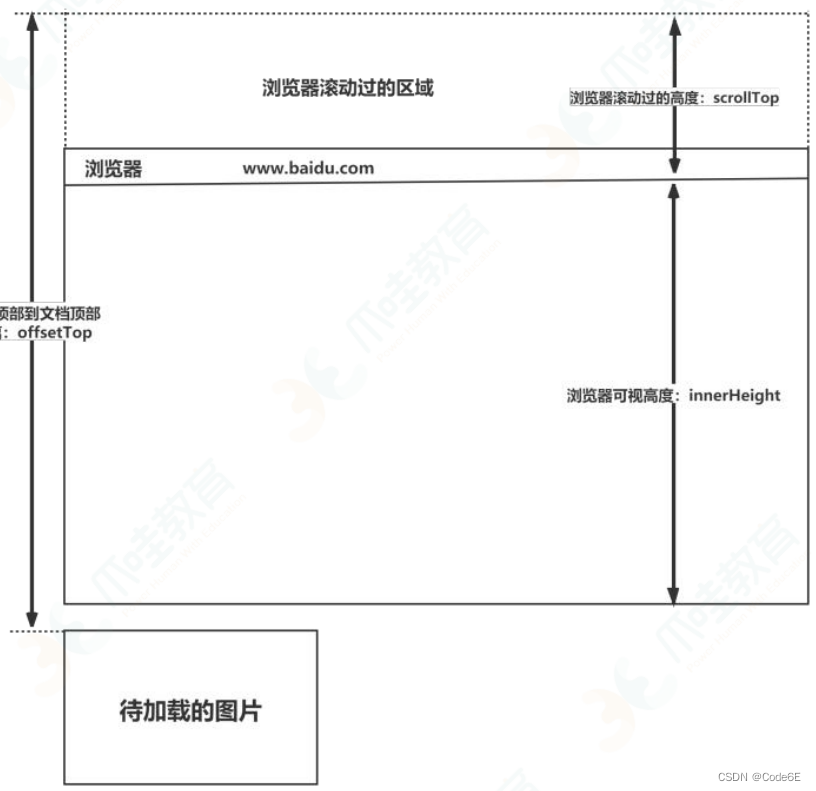
window.innerHeight:浏览器可视区的高度
document.body.scrollTop或document.documentElement.scrollTop:页面滚动的过的距离,document.documentElement是一个会返回文档对象(document)的根元素的只读属性(如 HTML 文档的 元素)。
imgs.offsetTop:是元素顶部距离文档顶部的高度(包括滚动条的距
离)
图 片 加 载 条 件 : img.offsetTop < window.innerHeight +document.body.scrollTop;
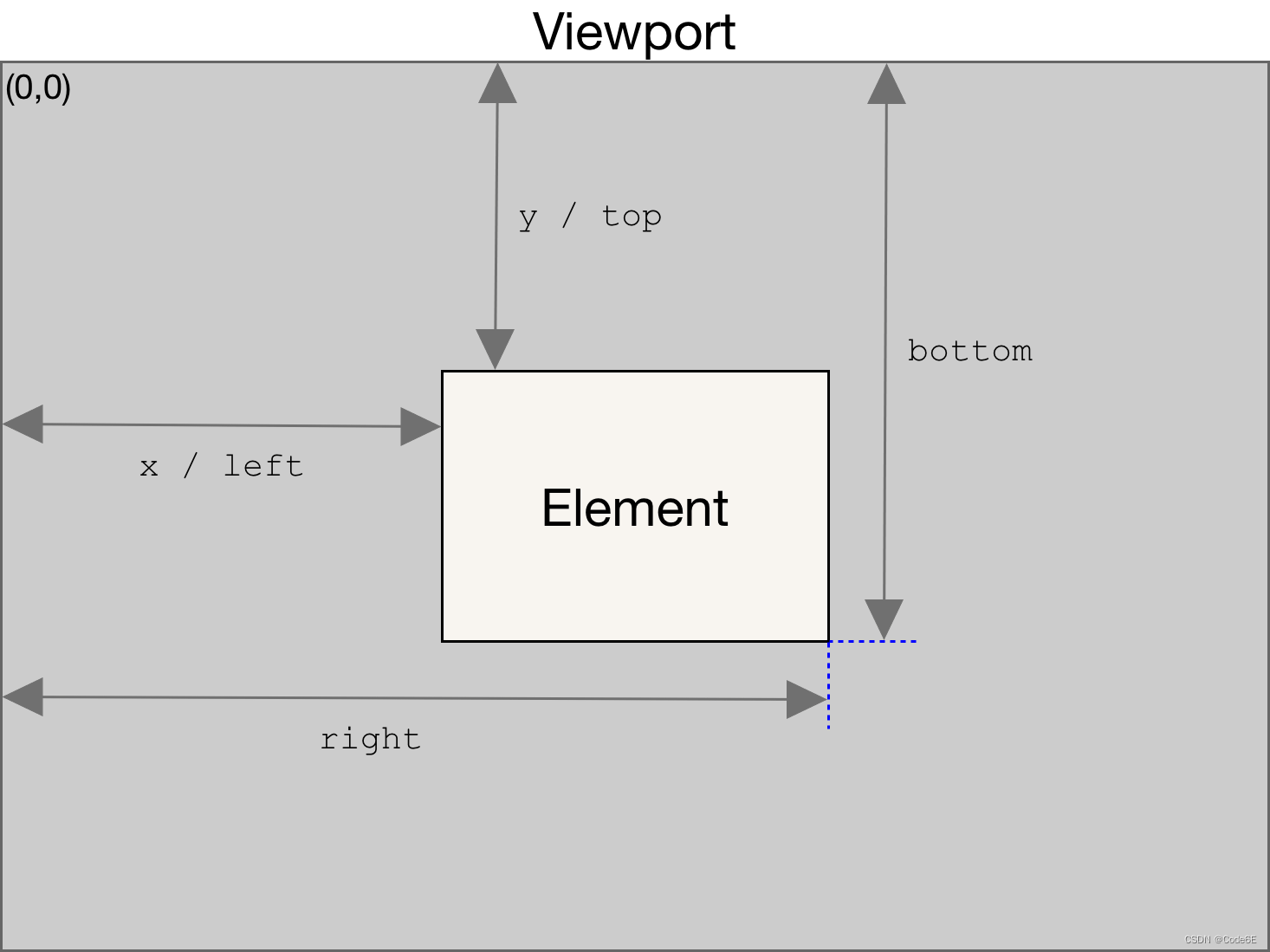
或img.getBoundingClientRect().top<window.innerHeight

Element.getBoundingClientRect() 方法返回一个 DOMRect 对象,其提供了元素的大小及其相对于视口的位置。
代码实现
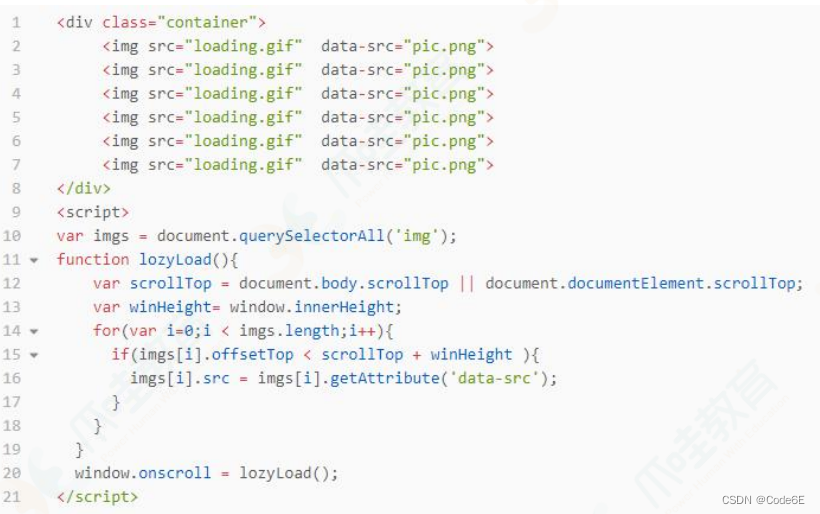
缺点:触发太多次了,每次触发滚动事件都会导致遍历所有图片,而且即使图片已经加载了还可以触发滚动事件,比较消耗性能,可以对滚动事件做节流处理
方法三:IntersectionObserver(性能好,但兼容性不太好)
参考:https://www.bilibili.com/video/BV1FU4y157Li
创建IntersectionObserver实例时,IntersectionObserver构造函数接受一个回调函数,这个回调函数在观察的目标元素与视口交叉或没有交叉时(出现在视口或从视口消失)都会触发。该回调函数有一个参数entries,entries是IntersectionObserver实例监听(observe)的对象组成的数组
IntersectionObserver.observe():使 IntersectionObserver 开始监听一个目标元素。
IntersectionObserver.unobserve():使 IntersectionObserver 停止监听特定目标元素。

entries的每个元素有isIntersecting属性,表示监听的元素是否与视口交叉(即是否出现在视口中),target属性表示监听的Element元素
<body>
<p>3. 验证Referer(不能完全保证避免CSRF攻击)
HTTP请求头有个Referer字段,用于记录请求的来源。可以添加个请求拦截器,若不是来自规定页面的请求,服务器则会拒绝(用户正常发起请求的源地址与黑客冒充用户身份发起请求的源地址是不一样的)。
但这种方法不能完全保证避免CSRF攻击,因为有些浏览器的HTTP请求头中的字段是可以篡改的,黑客可能通过篡改Referer字段伪造成合法的请求源地址,从而避开请求拦截器的拦截。
</p>
<div style="height: 2000px;"></div>
<img data-src="https://img-blog.csdnimg.cn/a5b8a100c3624a87933fdae1527f0b24.png" >
<img data-src="https://img-blog.csdnimg.cn/f8f529805ae540dd8289a44bcb490afd.png" >
<img data-src="https://i0.hdslb.com/bfs/banner/d57e8c0786fd289fc0771efa92de3d227f85a227.png@976w_550h_1c_!web-home-carousel-cover.webp"
>
<script>
const imgs = document.querySelectorAll('img')
const observer = new IntersectionObserver((entries) => {
console.log(entries)
entries.forEach((entry) => {
const img = entry.target
console.log(img);
})
})
imgs.forEach((img)=>{
observer.observe(img)
})
</script>
</body>
初始控制台输出
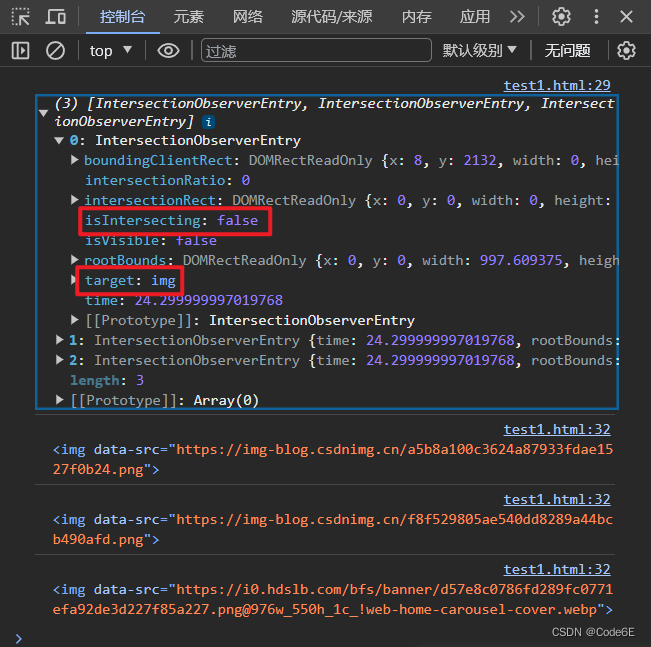
懒加载代码实现:
<body>
<p>3. 验证Referer(不能完全保证避免CSRF攻击)
HTTP请求头有个Referer字段,用于记录请求的来源。可以添加个请求拦截器,若不是来自规定页面的请求,服务器则会拒绝(用户正常发起请求的源地址与黑客冒充用户身份发起请求的源地址是不一样的)。
但这种方法不能完全保证避免CSRF攻击,因为有些浏览器的HTTP请求头中的字段是可以篡改的,黑客可能通过篡改Referer字段伪造成合法的请求源地址,从而避开请求拦截器的拦截。
</p>
<div style="height: 1000px;"></div>
<img data-src="https://img-blog.csdnimg.cn/a5b8a100c3624a87933fdae1527f0b24.png">
<img data-src="https://img-blog.csdnimg.cn/f8f529805ae540dd8289a44bcb490afd.png">
<img
data-src="https://i0.hdslb.com/bfs/banner/d57e8c0786fd289fc0771efa92de3d227f85a227.png@976w_550h_1c_!web-home-carousel-cover.webp">
<script>
const imgs = document.querySelectorAll('img')
// 创建IntersectionObserver实例,并定义目标元素与视口交叉或失去交叉时触发的回调函数
const callback = (entries) => {
// console.log(entries)
entries.forEach((entry) => {
if (entry.isIntersecting) { // 图片出现在视口(与视口交叉)中才加载图片
const img = entry.target
const data_src = img.getAttribute('data-src')
img.setAttribute('src', data_src) // 给图片的src属性赋值,使图片加载
observer.unobserve(img) // 加载图片后,记得取消对已加载图片的监听,否则图片加载后与视口交叉或失去交叉时仍会触发回调函数
console.log('触发');
}
})
}
const observer = new IntersectionObserver(callback)
// 给IntersectionObserver实例设置监听的目标
imgs.forEach((img) => {
observer.observe(img)
})
</script>
</body>
疑惑:我这边实际执行改段代码,第一个图片出现时就加载了全部图片
列表懒加载
精灵/雪碧图
Webpack优化前端性能
提高Webpack的构建速度
安全性
XSS攻击
CSRF攻击
参见
- CSRF 攻击和防御 ——bilibili
- 为什么Cookie 无法防止CSRF攻击,而token可以?——bilibili
- 史上最详细的CSRF攻击与防御,看完必有收获!——掘金
- MDN官方参考
CSRF(Cross Site Request Forgery)。黑客冒充合法用户的身份做非用户本意的请求。
防御CSRF的方法
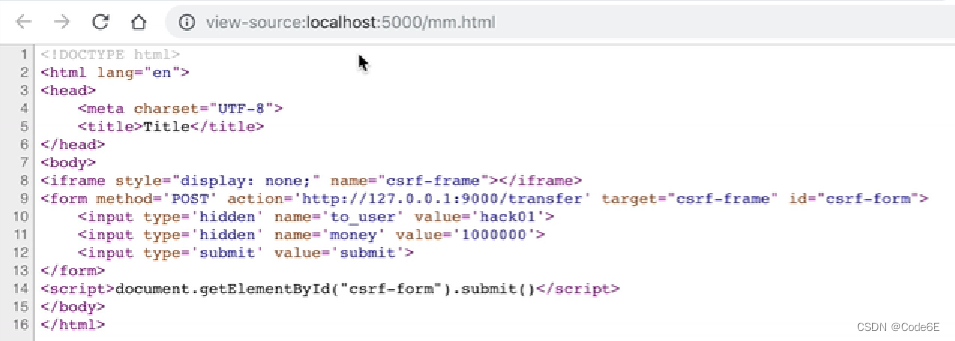
- 尽量用POST请求代替GET请求。但这种方法不能完全避免CSRF攻击
如下所示,攻击者可以通过这样的代码(iframe+form+script标签)进行攻击。
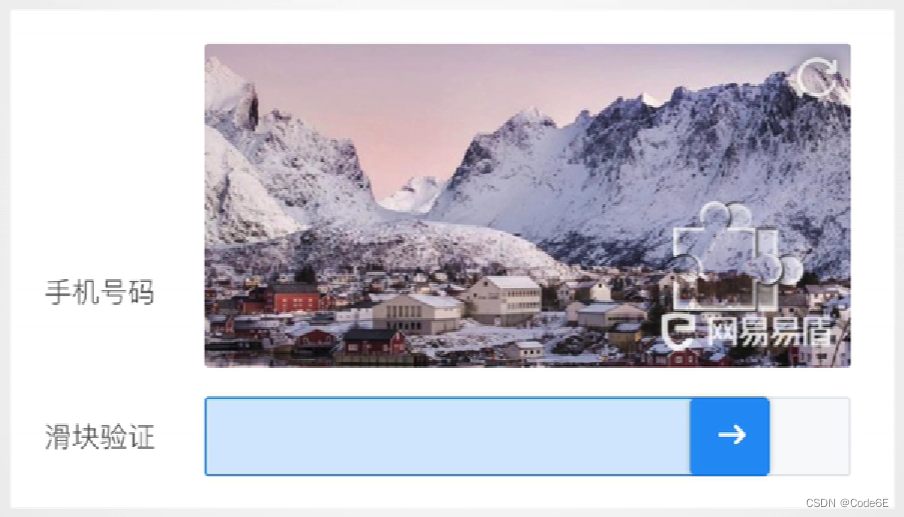
- 加入验证流程
比如验证码,滑动滑块等验证行为,以确保该操作是用户发起的,而不是黑客发起的。
- 验证Referer(不能完全保证避免CSRF攻击)
HTTP请求头有个Referer字段,用于记录请求的来源。可以添加个请求拦截器,若不是来自规定页面的请求,服务器则会拒绝(用户正常发起请求的源地址与黑客冒充用户身份发起请求的源地址是不一样的)。
但这种方法不能完全保证避免CSRF攻击,因为有些浏览器的HTTP请求头中的字段是可以篡改的,黑客可能通过篡改Referer字段伪造成合法的请求源地址,从而避开请求拦截器的拦截。

- Anti CSRF Token(大多数人的选择)
以前用户的信息存在Cookie中,黑客可以利用Cookie存储的用户信通过安全验证。为避免这种情况,可以用token代替Cookie中存储的用户信息,token在用户登入时由服务器下发,这个token是服务器随机生成的,并设定了有效期。客户端发送的请求都会携带在HTTP的头信息的token字段中,token用于验证用户。服务端接收到请求时,其请求拦截器会验证token是否正确,错误则拦截这次请求

- 自定义Header中的字段
- Cookie的sameSite属性设置
SameSite 是一个 cookie 属性(类似于 HTTPOnly、Secure 等),旨在缓解 CSRF 攻击。它在 RFC6265bis 中定义。此属性可帮助浏览器决定是否将 Cookie 与跨站点请求一起发送。此属性的可能值为Lax | Strict | None
Strict 值将阻止浏览器在所有跨站点浏览上下文中将 cookie 发送到目标站点,即使遵循常规链接也是如此。例如,对于类似 GitHub 的网站,这意味着如果登录用户点击了在公司论坛或电子邮件上发布的私有 GitHub 项目的链接,GitHub 将不会收到会话 cookie,并且用户将无法访问该项目。但是,银行网站不希望允许从外部网站链接任何交易页面,因此 Strict 标志是最合适的。
默认的 Lax 值为希望在用户从外部链接到达后维护用户登录会话的网站在安全性和可用性之间提供了合理的平衡。在上面的 GitHub 场景中,当跟踪来自外部网站的常规链接时,将允许会话 cookie,同时在 CSRF 倾向性请求方法(如 POST)中阻止它。只有在宽松模式下允许的跨站点请求才是具有顶级导航的请求,并且也是安全的 HTTP 方法。
Set-Cookie: JSESSIONID=xxxxx; SameSite=Strict
Set-Cookie: JSESSIONID=xxxxx; SameSite=Lax