本实践教程将教你如何使用 Elasticsearch 构建完整的搜索解决方案。 在本教程中你将学习:
- 如何对数据集执行全文关键字搜索(可选使用过滤器)
- 如何使用机器学习模型生成、存储和搜索密集向量嵌入
- 如何使用 ELSER 模型生成和搜索稀疏向量
- 如何使用 Elastic 的倒数排名融合 (RRF) 算法组合上述方法的搜索结果
本教程最重要的方面是,它将向你展示如何在你将在自己的计算机上运行的项目上实现所有这些功能,所有这些功能都通过小的增量步骤完成。
你将学习的示例是用 Python 编写的,但概念是通用的,可以应用于你最喜欢的语言或技术堆栈。
为了充分利用本教程,我们建议你遵循并运行所有示例。在如下的展示中,我将使用最新的 Elastic Stack 8.11 来进行展示。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:
Python
你可以安装自己喜欢的 Python 版本。版本在 3.8 及以上。本教程假设你之前没有 Elasticsearch 或一般搜索主题的知识,但它希望你对以下技术有基本的熟悉,至少在初学者水平:
- Python开发
- Python 的 Flask Web 框架
- 操作系统中的命令提示符或终端应用程序
项目设置
在本教程中,你将使用一个基于 Flask Web 框架的小型 Python 应用程序。 以下部分提供了帮助你在计算机上设置和运行此应用程序的说明。 要完成本部分,你需要在操作系统的终端或命令提示符窗口上工作。
下载入门应用程序
单击下面的链接下载入门搜索应用程序。
- 下载教程入门应用程序
为你的项目找到合适的父目录,例如 Documents 目录,然后在其中提取 zip 文件的内容。 这应该添加一个搜索教程目录,其中包含多个子目录和文件。

安装 Python 依赖包
从你的终端,切换到上一节中创建的 search-tutorial 目录。遵循 Python 最佳实践,你现在将创建一个虚拟环境,一个专用于该项目的私有 Python 环境。 使用以下命令执行此操作:
python3 -m venv .venv$ pwd
/Users/liuxg/python/search-tutorial
$ python3 -m venv .venv
$ ls -al
total 144
drwx------ 11 liuxg staff 352 Jan 4 09:38 .
drwxr-xr-x 115 liuxg staff 3680 Jan 2 20:09 ..
-rw-r--r-- 1 liuxg staff 34 Oct 31 19:34 .flaskenv
drwxr-xr-x 6 liuxg staff 192 Jan 4 09:38 .venv
-rw-r--r--@ 1 liuxg staff 1085 Nov 1 15:23 LICENSE
-rw-r--r-- 1 liuxg staff 110 Nov 7 20:21 README.md
-rw-r--r-- 1 liuxg staff 409 Nov 7 19:46 app.py
-rw-r--r-- 1 liuxg staff 51647 Oct 31 15:54 data.json
-rw-r--r--@ 1 liuxg staff 745 Oct 31 19:05 requirements.txt
drwx------ 3 liuxg staff 96 Jan 2 20:09 static
drwx------ 5 liuxg staff 160 Jan 2 20:09 templates此命令在 .venv (dot-venv) 目录中创建 Python 虚拟环境。 你可以将此命令中的 .venv 替换为你喜欢的任何名称。 请注意,在某些 Python 安装中,你可能需要使用 python 而不是 python3 来调用 Python 解释器。
下一步是激活虚拟环境,这是使该虚拟环境成为你所在终端会话的活动 Python 环境的一种方法。如果你使用的是基于 UNIX 的操作系统(例如 Linux 或 macOS),请激活 虚拟环境如下:
source .venv/bin/activate$ source .venv/bin/activate
(.venv) $ pwd
/Users/liuxg/python/search-tutorial如果你在 Microsoft Windows 计算机上的 WSL 环境中工作,上述激活命令也适用。 但如果你使用的是 Windows 命令提示符或 PowerShell,激活命令会有所不同:
.venv\Scripts\activate激活虚拟环境后,命令行提示符将更改为显示环境名称:
(.venv) $ _注意:如果你以前没有使用过虚拟环境,则应记住激活命令不是永久性的,仅适用于输入命令的终端会话。 如果你打开第二个终端窗口,或者在前一天关闭计算机后返回继续学习本教程,则必须重复激活命令。
配置 Python 环境的最后一步是安装入门应用程序所需的一些包。 确保上一步中已激活虚拟环境,然后运行以下命令安装这些依赖项:
pip install -r requirements.txt
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
(.venv) $ ls http_ca.crt
http_ca.crt运行应用
此时,你应该能够使用以下命令启动应用程序:
flask run

要确认应用程序正在运行,请打开浏览器并导航到 http://localhost:5001。
注意:早期阶段的应用程序只是一个空壳。 如果你愿意,你可以在搜索框中输入内容并请求搜索,但响应始终是没有结果。 在以下部分中,你将了解如何在 Elasticsearch 索引中加载一些内容并执行搜索。
Flask 应用程序配置为在开发模式下运行。 当它检测到源文件已更改时,它将自动重新启动以合并更改。 当你继续学习本教程时,你可以让该终端会话保持应用程序运行,并且当你进行更改时,应用程序将重新启动以进行更新。
全文搜索
在本教程的这一部分中,你将学习如何使用 Elasticsearch 的全文搜索功能。 这将向你介绍几个核心主题,例如使用 Python 客户端库、创建和更新索引、进行查询以及使用搜索结果,所有这些也适用于你稍后将学习的更高级的搜索方法。
设置 Elasticsearch Python 客户端
在本部分中,你将安装适用于 Python 的 Elasticsearch 客户端库并使用它连接到 Elasticsearch 服务。
安装
Elasticsearch 客户端库是一个与 pip 一起安装的 Python 包。 确保之前创建的虚拟环境已激活,然后运行以下命令安装客户端:
pip install elasticsearch$ pip3 install elasticsearch
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Requirement already satisfied: elasticsearch in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (8.11.1)
Requirement already satisfied: elastic-transport<9,>=8 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elasticsearch) (8.10.0)
Requirement already satisfied: urllib3<3,>=1.26.2 in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2.1.0)
Requirement already satisfied: certifi in /Library/Frameworks/Python.framework/Versions/3.11/lib/python3.11/site-packages (from elastic-transport<9,>=8->elasticsearch) (2023.11.17)
$ pip3 list | grep elasticsearch
elasticsearch 8.11.1
rag-elasticsearch 0.0.1 /Users/liuxg/python/rag-elasticsearch/my-app/packages/rag-elasticsearch始终建议使用所有依赖项更新 requirements.txt 文件,因此这是更新此文件以包含新安装的软件包的好时机。 从终端运行以下命令:
pip3 freeze > requirements.txt我们可以看到最终的 requirements.txt 文件中的 elasticsearch 版本被修正了:

连接到 Elasticsearch
要创建与 Elasticsearch 服务的连接,必须使用适当的连接选项创建 Elasticsearch 对象。
在代码编辑器中创建一个新的 search.py 文件,该文件位于 search-tutorial 目录中。 search.py 文件将定义所有搜索函数。 为搜索功能创建一个单独的文件的想法是,这将使你可以轻松地提取该文件并稍后将其添加到你自己的项目中。
在 search.py中输入以下代码添加 Search 类:
import json
from pprint import pprint
import os
import time
from dotenv import load_dotenv
from elasticsearch import Elasticsearch
load_dotenv()
class Search:
def __init__(self):
self.es = Elasticsearch() # <-- connection options need to be added here
client_info = self.es.info()
print('Connected to Elasticsearch!')
pprint(client_info.body)这里有很多东西需要解释。 导入后立即调用的 load_dotenv() 函数来自 python-dotenv包。 该包知道如何使用 .env 文件,这些文件用于存储配置变量,例如密码和密钥。 load_dotenv() 函数读取存储在 .env 文件中的变量,并将它们作为环境变量导入到 Python 进程中。
Search 类有一个构造函数,用于创建 Elasticsearch 客户端类的实例。 这是与 Elasticsearch 服务通信的所有客户端逻辑所在的位置。 请注意,此行当前不完整,因为需要包含适合你的服务的连接选项。你将在下面了解哪些选项适用于你的案例。 创建后,Elasticsearch 对象将存储在名为 self.es 的实例变量中。
为了确保客户端对象可以与你的 Elasticsearch 部署进行通信,将调用 info() 方法。 此方法调用请求基本信息的服务。 如果此调用成功,则你可以假设你已与该服务建立了有效连接。
然后,该方法打印一条状态消息,指示连接已建立,然后使用 Python 中的 pprint 函数以易于阅读的格式显示服务返回的信息。
注意:你可能已经注意到,Python 标准库中的 json 包已导入到此文件中,但并未使用。 不要删除此导入,因为稍后将使用此包。
为了完成 Search 类的构造函数,需要为 Elasticsearch 对象提供适当的连接选项。 以下小节将告诉你安装方法需要哪些选项。
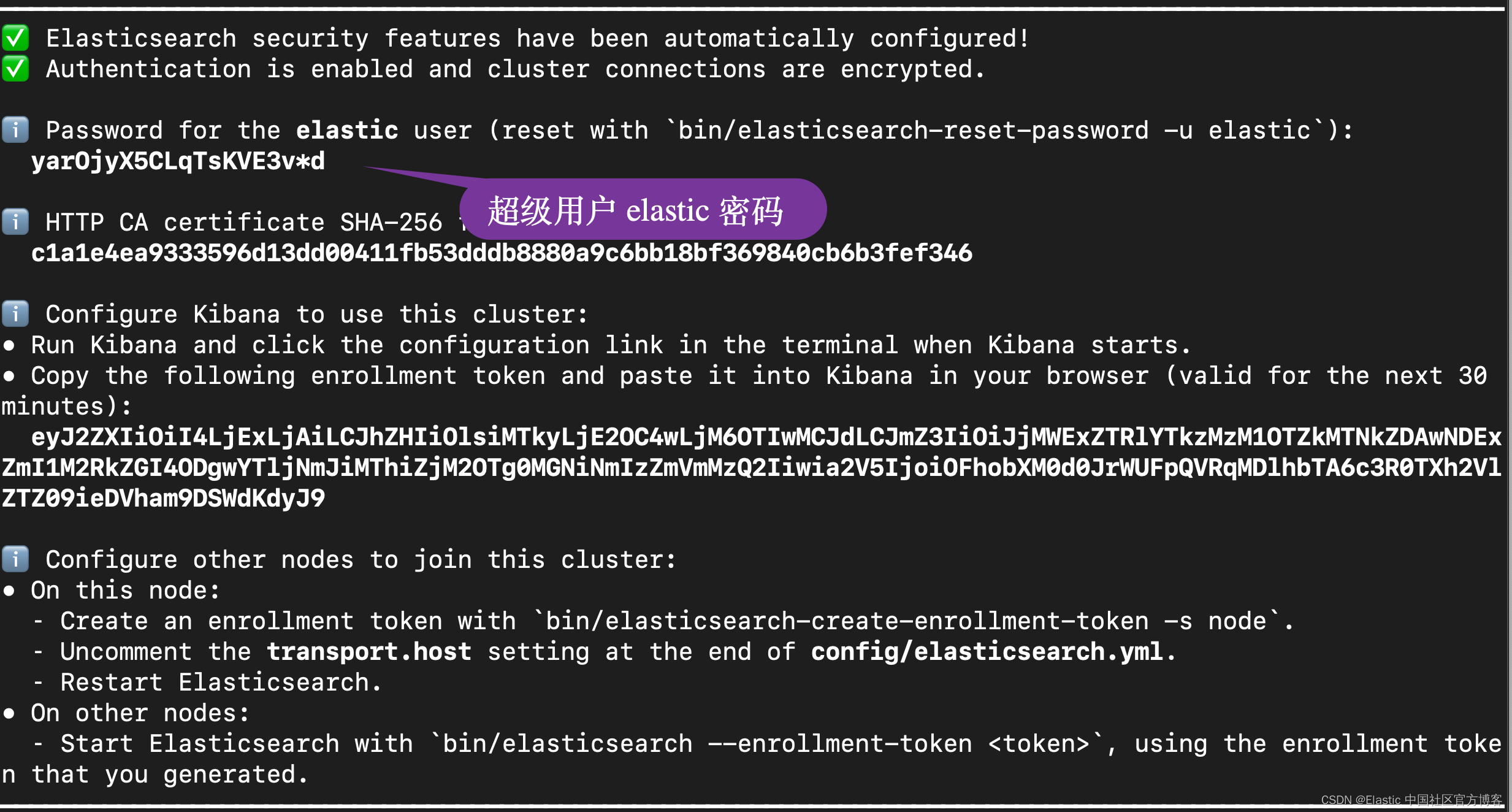
创建 .env 文件
我们接着在当前项目的根目录下创建如下的一个文件 .env:
.env
ES_USER="elastic"
ES_PASSWORD="yarOjyX5CLqTsKVE3v*d"
ES_ENDPOINT="localhost"(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ cat .env
ES_USER="elastic"
ES_PASSWORD="yarOjyX5CLqTsKVE3v*d"
ES_ENDPOINT="localhost"如上所示:
- ES_USER 定义了访问 Elasticsearch 的用户名。在我们的配置中,我们使用超级用户 elastic
- ES_PASSWORD 定义了 ES_USER 用户的密码
- ES_ENDPOINT 定义了访问 Elasticsearch 的地址
你们需要根据自己的配置二进行相应的改变。接下来,我们需要针对 search.py 来进行修改:
search.py
import json
from pprint import pprint
import os
import time
from dotenv import load_dotenv
from elasticsearch import Elasticsearch
load_dotenv()
class Search:
def __init__(self):
url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
self.es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
client_info = self.es.info()
print('Connected to Elasticsearch!')
pprint(client_info.body)测试连接
此时,你已准备好连接到 Elasticsearch 服务。 为此,请确保已激活 Python 虚拟环境,然后键入 python 以启动 Python 交互式会话。 你应该看到熟悉的 >>> 提示符,你可以在其中输入 Python 语句。
导入 Search 类如下:
from search import Search接下来,实例化新类:
es = Search()你应该看到一条已连接的消息,后面是客户端的 info() 方法返回的信息。 除了标识符和版本号的差异之外,输出应如下所示:
(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ python
Python 3.11.6 (v3.11.6:8b6ee5ba3b, Oct 2 2023, 11:18:21) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from search import Search
>>> es = Search()
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch',
'cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg',
'name': 'liuxgm.local',
'tagline': 'You Know, for Search',
'version': {'build_date': '2023-11-04T10:04:57.184859352Z',
'build_flavor': 'default',
'build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20',
'build_snapshot': False,
'build_type': 'tar',
'lucene_version': '9.8.0',
'minimum_index_compatibility_version': '7.0.0',
'minimum_wire_compatibility_version': '7.17.0',
'number': '8.11.0'}}如果收到错误,请确保在 .env 文件中输入正确的凭据。更多关于如何连接到 Elasticsearch 的知识,请参阅文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
将 Elasticsearch 与 Flask 应用程序集成
本节的最后一步是将迄今为止完成的工作集成到你之前安装的小 Flask 应用程序中。 目标是应用程序在启动时自动创建与 Elasticsearch 的连接。
为此,请在代码编辑器中打开 app.py。 在现有导入下方添加 search.py 模块的导入语句:
from search import Search然后找到创建 app 变量的行,然后创建新 Search 类的实例:
es = Search()就是这样! 现在应用程序有一个 es 对象可以在需要时使用。 如果你仍在终端中运行 Flask 应用程序,则保存文件后你应该会看到应用程序重新加载。 重新加载的结果是,由 Search 类构造函数打印的连接信息应该出现,并且从现在起每次应用程序重新启动时都会继续出现。
如果你没有运行 Flask 应用程序,现在是启动它的好时机。 更改到终端窗口中的项目目录,激活 Python 虚拟环境,然后使用以下命令启动应用程序:
flask run为了帮助你在收到错误时进行故障排除,以下是带有集成 Elasticsearch 客户端的 app.py 的完整代码:
app.py
import re
from flask import Flask, render_template, request
from search import Search
app = Flask(__name__)
es = Search()
@app.get('/')
def index():
return render_template('index.html')
@app.post('/')
def handle_search():
query = request.form.get('query', '')
return render_template(
'index.html', query=query, results=[], from_=0, total=0)
@app.get('/document/<id>')
def get_document(id):
return 'Document not found'当我们修改完这个文件后,我们可以在运行 flask 的 terminal 中看到如下的输出:

创建一个 Elasticsearch 索引
Elasticsearch 中两个非常重要的概念是文档和索引。你如果对这个还是很糊涂的话,那么请详细阅读我之前的文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
文档是字段及其关联值的集合。 要使用 Elasticsearch,你必须将数据组织到文档中,然后将所有文档添加到索引中。 你可以将索引视为以高度优化的格式存储的文档集合,旨在执行高效的搜索。
如果你使用过其他数据库,你可能知道许多数据库需要模式定义,它本质上是对你要存储的所有字段及其类型的描述。 如果需要,Elasticsearch 索引可以配置模式,但它也可以自动从数据本身派生模式(Elasticsearch 根据数据的类型进行推测)。 在本节中,你将让 Elasticsearch 自行计算模式,这对于文本、数字和日期等简单数据类型非常有效。 稍后,在了解更复杂的数据类型后,你将学习如何提供显式模式定义。
创建索引
这是使用 Python 客户端库创建 Elasticsearch 索引的方法:
self.es.indices.create(index='my_documents')在此示例中,self.es 是 Elasticsearch 类的实例,在本教程中它存储在 search.py 的 Search 类中。 Elasticsearch 部署可用于存储多个索引,每个索引都由名称标识,例如上例中的 my_documents。
也可以删除索引:
self.es.indices.delete(index='my_documents')如果你尝试使用已分配给现有索引的名称创建索引,则会收到错误消息。 有时,创建一个索引并自动删除该索引的先前实例(如果存在)会很有用。 这在开发应用程序时特别有用,因为你可能需要多次重新生成索引。
让我们在 search.py 中添加一个 create_index() 辅助方法。 在代码编辑器中打开此文件,然后在底部添加以下代码,保留现有内容不变:
class Search:
# ...
def create_index(self):
self.es.indices.delete(index='my_documents', ignore_unavailable=True)
self.es.indices.create(index='my_documents')create_index() 方法首先删除名为 my_documents 的索引。 ignore_unavailable=True 选项可防止在找不到索引名称时此调用失败。 该方法中的以下行创建一个具有相同名称的全新索引。
提示:本教程中的示例应用程序需要一个 Elasticsearch 索引,因此它将索引名称硬编码为 my_documents。 对于使用多个索引的更复杂的应用程序,你可以考虑接受索引名称作为参数。
将文档添加到索引
在 Python 的 Elasticsearch 客户端库中,文档表示为键/值字段的字典。 具有字符串值的字段会自动建立索引以进行全文和关键字搜索,但除了字符串之外,你还可以使用其他字段类型,例如数字、日期和布尔值,这些字段类型也会建立索引以进行过滤等高效操作。 你还可以构建复杂的数据结构,其中字段设置为列表或带有子项的字典。了解有关 Elasticsearch 类型的更多信息。
要将文档插入索引,请使用 Elasticsearch 客户端的 index() 方法。 例如:
document = {
'title': 'Work From Home Policy',
'contents': 'The purpose of this full-time work-from-home policy is...',
'created_on': '2023-11-02',
}
response = es.index(index='my_documents', body=document)
print(response['_id'])index() 方法的返回值是 Elasticsearch 服务返回的响应。 此响应中返回的最重要的信息是一个键名为 _id 的项目,表示在将文档插入索引时分配给该文档的唯一标识符。 该标识符可用于检索、删除或更新文档。
现在你已经知道如何插入文档了,让我们继续在 search.py 中构建一个有用的 helpers 库,并为 Search 类添加一个新的 insert_document() 方法。 在 search.py 底部添加此方法:
class Search:
# ...
def insert_document(self, document):
return self.es.index(index='my_documents', body=document)该方法接受 Elasticsearch 客户端和来自调用者的文档,并将文档插入到 my_documents 索引中,返回服务的响应。
注意:本教程不涉及这些操作(修改及删除),但 Elasticsearch 客户端也可以修改和删除文档。 请参阅 Python 库文档中的 Elasticsearch 类参考,了解所有可用的操作。更多内容,请阅读文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
从 JSON 文件提取文档
设置新的 Elasticsearch 索引时,你可能需要导入大量文档。 对于本教程,入门项目包括一个 data.json 文件,其中包含一些 JSON 格式的数据。 在本节中,你将学习如何将该文件中包含的所有文档导入到索引中。
data.json 中包含的文档结构如下:
- name:文档标题
- url:外部站点上托管的文档的 URL
- summary:文档内容的简短摘要
- content:文档正文
- created_on:创建日期
- updated_at:更新日期(如果文档从未更新过,则可能会没有这个项)
- category:文档的类别,可以是 github、sharepoint 或 teams
- rolePermissions:角色权限列表
此时,建议你在编辑器中打开 data.json 以熟悉要使用的数据。
本质上,导入大量文档与在 for 循环中导入一个文档没有什么不同。 要导入 data.json 文件的全部内容,你可以执行以下操作:
import json
from search import Search
es = Search()
with open('data.json', 'rt') as f:
documents = json.loads(f.read())
for document in documents:
es.insert_document(document)虽然这种方法有效,但扩展性不佳。 如果你必须插入大量文档,则需要对 Elasticsearch 服务进行尽可能多的调用。 遗憾的是,每个 API 调用都会产生性能成本,而且该服务还设有速率限制,无法快速进行大量调用。 由于这些原因,最好使用 Elasticsearch 服务的批量插入功能,该功能允许在单个 API 调用中将多个操作传递给服务。
下面显示的 insert_documents() 方法(你应该将其添加到 search.py 的底部)使用 bulk() 方法在一次调用中插入所有文档:
def insert_documents(self, documents):
operations = []
for document in documents:
operations.append({'index': {'_index': 'my_documents'}})
operations.append(document)
return self.es.bulk(operations=operations)该方法接受文档列表。 它不是单独添加每个文档,而是组装一个称为操作的列表,然后将该列表传递给 bulk() 方法。 对于每个文档,两个条目会添加到操作列表中:
- 对要执行的操作的描述,设置为索引,并以索引名称作为参数给出。
- 文档的实际数据
处理批量请求时,Elasticsearch 服务从头开始遍历操作列表并执行请求的操作。
- 在文档中了解有关 bulk() 方法的更多信息
我们在当前的目录下运行如下的脚步来写入文档:
ingest.py
重新生成索引
当你学习本教程时,你将需要重新生成索引几次。 要简化此操作,请向 search.py 添加 reindex() 方法:
class Search:
# ...
def reindex(self):
self.create_index()
with open('data.json', 'rt') as f:
documents = json.loads(f.read())
return self.insert_documents(documents)此方法结合了之前创建的 create_index() 和 insert_documents() 方法,因此只需一次调用即可销毁旧索引(如果存在)并构建并重新填充新索引。
注意:对大量文档建立索引时,最好将文档列表分成较小的集合,并分别导入每个集合。
为了使这个方法更容易调用,让我们通过 flask 命令公开它。 在代码编辑器中打开 app.py 并在底部添加以下函数:
@app.cli.command()
def reindex():
"""Regenerate the Elasticsearch index."""
response = es.reindex()
print(f'Index with {len(response["items"])} documents created '
f'in {response["took"]} milliseconds.')@app.cli.command() decorator 告诉 Flask 框架将此函数注册为自定义命令,该命令将作为 Flask reindex 提供。 命令的名称取自函数的名称,并且文档字符串包含在此处,因为 Flask 在 --help 文档中使用它。
reindex() 函数的响应,也就是 Elasticsearch 客户端的 bulk() 方法的响应,包含一些有用的项目,可用于构造良好的状态消息。 特别是,response['took'] 是调用的持续时间(以毫秒为单位),response['items'] 是每个操作的各个结果的列表,实际上并没有直接用处,但列表的长度提供了插入文档的计数。
通过从终端会话运行 Flask --help 来查看效果,确保 Python 虚拟环境已激活(如果您的终端会话仍在运行 Flask 应用程序,则可以打开第二个终端窗口)。 在帮助屏幕的末尾,您应该会看到作为可用命令包含的 reindex 选项以及 Flask 框架提供的其他选项:
flash --help(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ flask --help
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch',
'cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg',
'name': 'liuxgm.local',
'tagline': 'You Know, for Search',
'version': {'build_date': '2023-11-04T10:04:57.184859352Z',
'build_flavor': 'default',
'build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20',
'build_snapshot': False,
'build_type': 'tar',
'lucene_version': '9.8.0',
'minimum_index_compatibility_version': '7.0.0',
'minimum_wire_compatibility_version': '7.17.0',
'number': '8.11.0'}}
Usage: flask [OPTIONS] COMMAND [ARGS]...
A general utility script for Flask applications.
An application to load must be given with the '--app' option, 'FLASK_APP'
environment variable, or with a 'wsgi.py' or 'app.py' file in the current
directory.
Options:
-e, --env-file FILE Load environment variables from this file. python-
dotenv must be installed.
-A, --app IMPORT The Flask application or factory function to load, in
the form 'module:name'. Module can be a dotted import
or file path. Name is not required if it is 'app',
'application', 'create_app', or 'make_app', and can be
'name(args)' to pass arguments.
--debug / --no-debug Set debug mode.
--version Show the Flask version.
--help Show this message and exit.
Commands:
reindex Regenerate the Elasticsearch index.
routes Show the routes for the app.
run Run a development server.
shell Run a shell in the app context.现在,当你想要生成一个干净的索引时,你所需要做的就是运行 flask reindex。
搜素基础
现在你已经构建了 Elasticsearch 索引并向其中加载了一些文档,你已经准备好实现全文搜索了。
搜索将如何进行
让我们快速回顾一下搜索解决方案在教程应用程序中的工作原理。 Flask 应用程序运行后,你可以访问 http://localhost:5001 访问主页面,如下所示:

呈现此页面的代码在 app.py 文件中实现:
@app.get('/')
def index():
return render_template('index.html')这是一个非常简单的端点,用于呈现 HTML 模板。 在 Flask 应用程序中,模板位于 templates 子目录中,因此你会在其中找到应用程序中包含的此模板和其他模板。
让我们看看文件 templates/index.html 中搜索字段的实现。 这是该模板的相关部分:
<form method="POST" action="{{ url_for('handle_search') }}">
<div class="mb-3">
<input type="text" class="form-control" name="query" id="query" placeholder="Enter your search query" autofocus>
</div>
</form>在这里您可以看到这是一个 HTML 表单,其中包含一个名为 “query” 的文本类型字段。 表单的 method 属性设置为 POST,它告诉浏览器在 POST 请求中提交此表单。 action 属性设置为与 Flask 应用程序的 handle_search 端点对应的 URL。 提交表单后,handle_search() 函数将执行。
当前 handle_search() 的实现如下所示:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
return render_template('index.html', query=query, results=[], from_=0,
total=0)该函数从 Flask 的 request.form 字典中获取用户在文本字段中输入的文本,并将其存储在查询局部变量中。 然后该函数呈现 index.html 模板,但这种类型它传递一些额外的参数,以便页面可以显示搜索结果。 模板接收的四个参数是:
- query:用户在表单中输入的查询文本。
- results:搜索结果列表
- from_:第一个结果的从零开始的索引
- total:结果总数
由于搜索功能尚未实现,目前传递给 render_template() 函数的参数表明未找到任何结果。
现在的任务是实现一个全文查询并传递实际结果以便 index.html 页面可以显示它们。
Elasticsearch 查询
Elasticsearch 服务使用基于 JSON 格式的查询 DSL(域特定语言)来定义查询。
Python 的 Elasticsearch 客户端有一个 search() 方法,用于提交搜索查询。 让我们在 search.py 中添加一个使用此方法的 search() 辅助方法:
search.py
class Search:
# ...
def search(self, **query_args):
return self.es.search(index='my_documents', **query_args)此方法使用索引名称调用 Elasticsearch 客户端的 search() 方法。 query_args 参数捕获提供给该方法的所有关键字参数,然后将它们传递给 es.search() 方法。 这些参数将决定调用者如何指定要搜索的内容。
匹配查询
Elasticsearch Query DSL 提供了许多不同的方法来查询索引。 浏览文档中的其中的一个小的章节,你将熟悉可能的不同类型的查询。 全文查询部分介绍了非常常见的文本搜索任务。
对于第一个搜索实现,我们使用匹配查询。 你可以在下面看到使用此查询的示例:
GET /_search
{
"query": {
"match": {
"name": {
"query": "search text here"
}
}
}
}上面的示例以类似于原始 HTTP 请求的格式给出。 熟悉这种格式很有用,因为它在 Elasticsearch 文档和 Elasticsearch API 控制台中广泛使用。 幸运的是,这种格式很容易转换为使用 Python 客户端库的调用。 下面你可以看到上述示例的等效 Python 代码:
es.search(
query={
'match': {
'name': {
'query': 'search text here'
}
}
}
)将 API 控制台示例转换为 Python 时,请记住查询正文中的顶级键必须转换为 Python 调用中的关键字参数。 这些示例也没有指定进行 Python 调用时需要的索引。
通过查看查询结构,你可能可以推断出它请求的搜索类型。 该调用请求对名为 name 的字段进行 match 查询,要搜索的文本是 search text here。
这种查询方式相当容易合并到教程应用程序中。 打开 app.py 并找到 handle_search() 方法。 将当前版本替换为新版本:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
results = es.search(
query={
'match': {
'name': {
'query': query
}
}
}
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=0,
total=results['hits']['total']['value'])新版本端点第二行中对 es.search() 的调用会调用上面在 search.py 中添加的 search() 方法,该方法又调用 Elasticsearch 客户端的 search() 方法。
你能弄清楚查询要做什么吗? 这是与上面示例类似的 match 查询。 将要搜索的字段是 name,它包含你在上一节中构建的 my_documents 索引中文档的标题。 要搜索的文本是用户在网页搜索字段中键入的内容,该文本存储在 query 局部变量中。
搜索响应中包含结果的部分是 response['hits']。 这是一个具有几个键的对象,其中两个键对此实现感兴趣:
- response['hits']['hits']:搜索结果列表。
- response['hits']['total']:可用结果的总数。 结果数在 value 子键中给出,因此在实践中,获取结果总数的表达式为 results['hits']['total']['value']。 请注意,当结果数量较多时,结果总数可能是近似值。 有关详细信息,请参阅响应正文文档。
在这个新版本的端点中对 render_template() 的调用会传递 results 模板参数中的结果列表以及结果总数。 query 参数像以前一样接收查询字符串,from_ 仍然硬编码为 0,因为稍后添加分页时会实现它。
至此,该应用程序首次实现了全文搜索。 返回 Web 浏览器并导航至 http://localhost:5001 以打开应用程序。 如果由于任何原因你没有运行 Flask 应用程序,请在执行此操作之前重新启动该应用程序。 输入搜索文本(例如 polict 或 work from home),你将看到相关结果。 你可以在下面看到在家搜索工作时的结果:
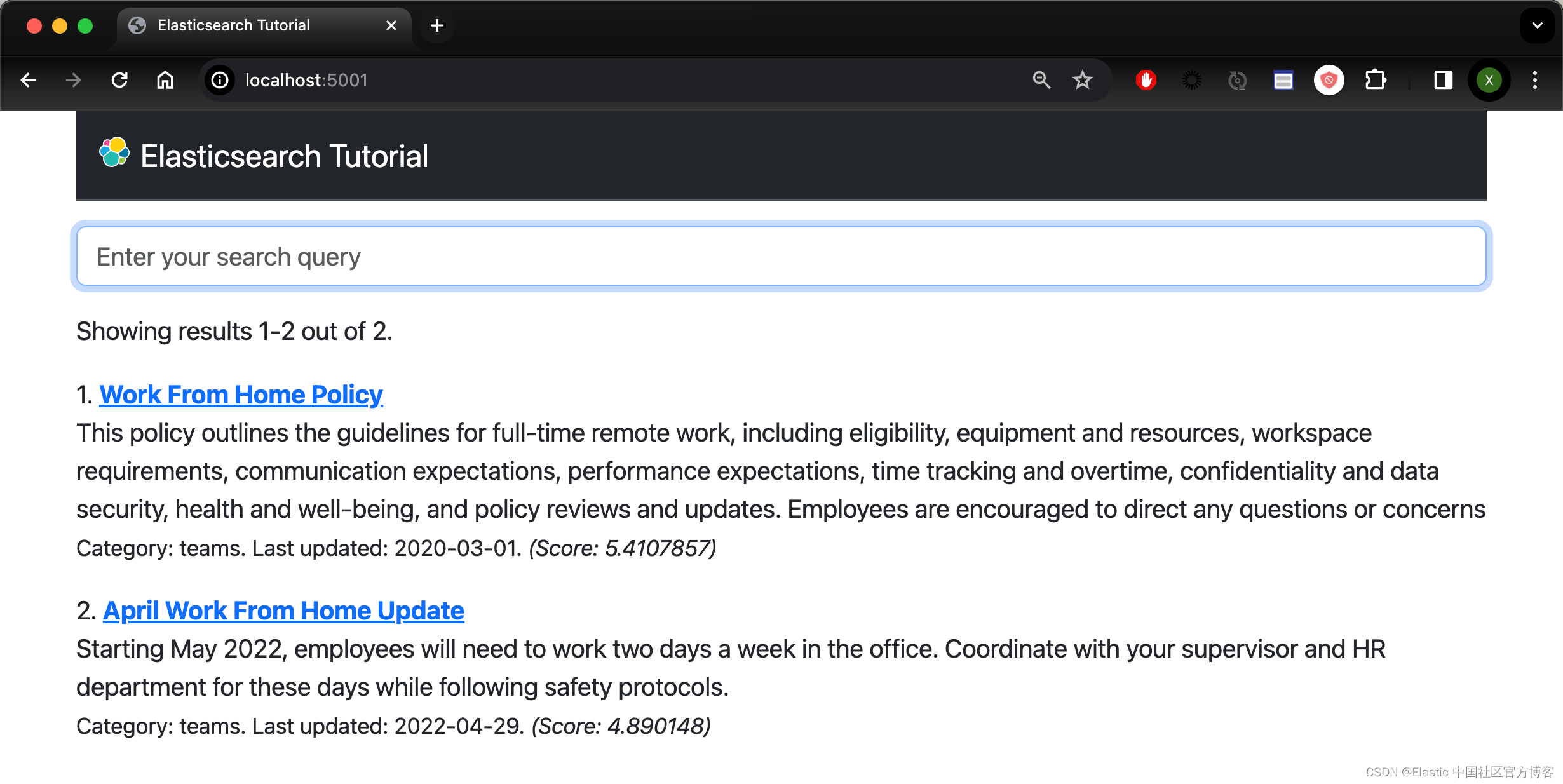
你随入门应用程序下载的 index.html 模板包含呈现搜索结果的所有逻辑。 如果你对此感到好奇,以下是此模板中呈现结果列表的部分:
{% for result in results %}
<p>
{{ from_ + loop.index }}. <b><a href="{{ url_for('get_document', id=result._id) }}">{{ result._source.name }}</a></b>
<br>
{{ result._source.summary }}
<br>
<small>
Category: {{ result._source.category }}.
Last updated: {{ result._source.updated_at | default(result._source.created_on) }}.
{% if result._score %}<i>(Score: {{ result._score }})</i>{% endif %}
</small>
</p>
{% endfor %}从这段代码中值得注意的是,与返回结果关联的数据在 _source 键下可用。 还有一个 _id 字段,其中包含分配给结果的唯一标识符。
与每个结果相关的分数可以从 _score 获得。 分数提供了相关性的分数,分数越高表示与查询文本的匹配越接近。 默认情况下,结果按分数从最高到最低的顺序返回。 Elasticsearch 中的分数是使用 Okapi BM25 算法计算的。
如果你有兴趣更详细地探索本节中涵盖的主题,请使用以下链接:
- Match query
- Search API Request body
- Search API Response Body
- Practical BM25 article series
检索单个结果
你可能已经注意到,index.html 模板将每个搜索结果的标题呈现为链接。 该链接指向在起始 Flask 应用程序中实现的第三个也是最后一个端点,称为 get_document。 提供的实现返回 “Document not found” 硬编码文本,因此如果你在使用应用程序时单击任何结果,你将看到以下内容。
为了正确渲染单个文档,让我们使用 Elasticsearch 客户端的 get() 方法在 search.py 中添加一个 retrieve_document() 辅助方法:
class Search:
# ...
def retrieve_document(self, id):
return self.es.get(index='my_documents', id=id)在这里,你可以看到分配给每个文档的这些唯一标识符如何有用,因为应用程序可以使用它来引用各个文档。
以下是 get_document() 端点的当前实现:
@app.get('/document/<id>')
def get_document(id):
return 'Document not found'你可以看到与此端点关联的 URL 包含文档 id,并且为每个搜索结果呈现的链接也将 id 合并到各自的 URL 中,因此所缺少的就是将这一简单的实现替换为检索的文档并呈现它。 将端点替换为此更新版本:
@app.get('/document/<id>')
def get_document(id):
document = es.retrieve_document(id)
title = document['_source']['name']
paragraphs = document['_source']['content'].split('\n')
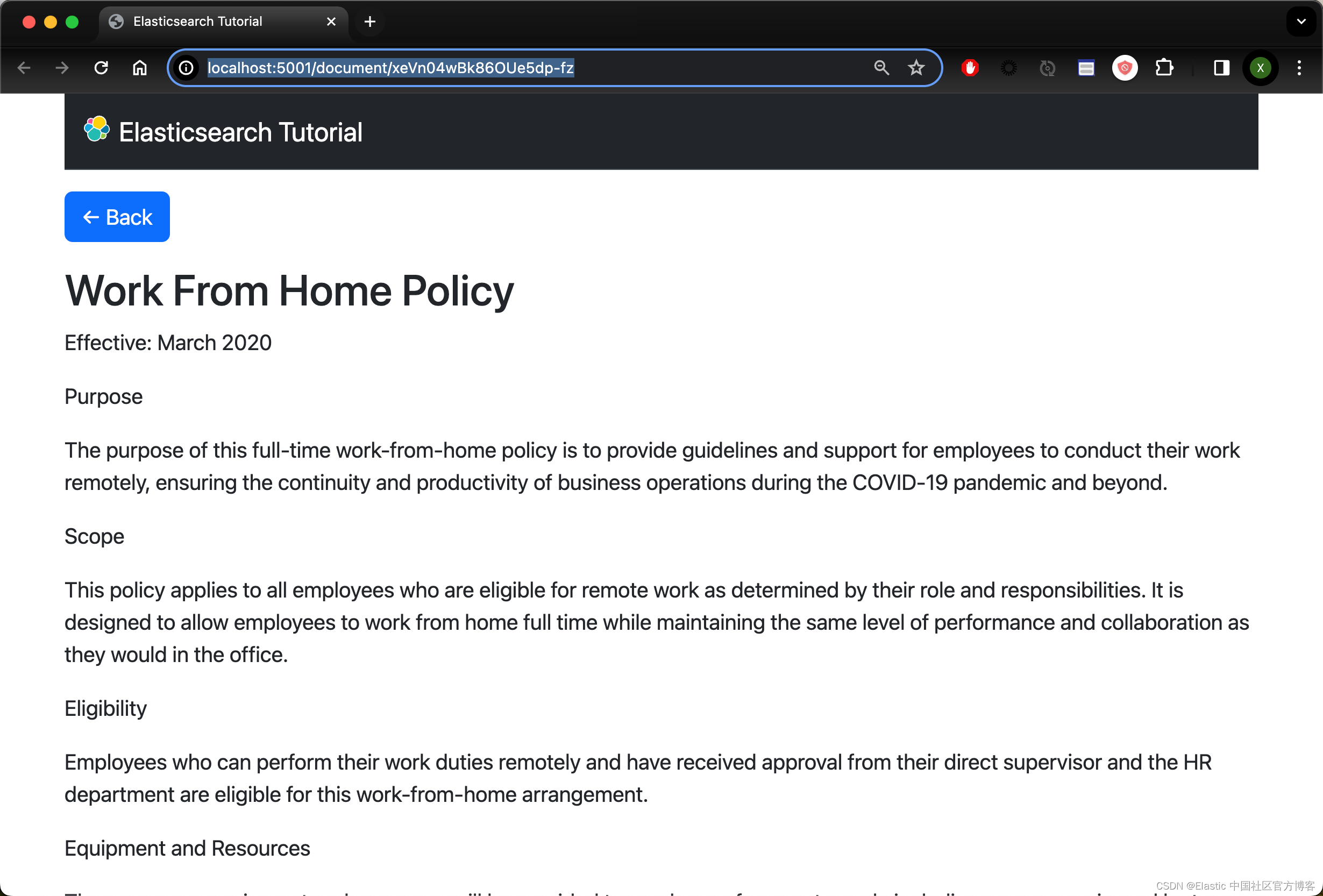
return render_template('document.html', title=title, paragraphs=paragraphs)这里使用 search.py 中的 retrieve_document() 方法来获取所请求的文档。 然后,将呈现 document.html,其中包含来自 name 字段的标题和来自 content 的段落列表。
尝试运行更多查询,然后单击结果,现在你应该可以看到完整的内容。
搜索多个字段
使用该应用程序一段时间后,你可能会注意到许多查询没有返回结果。 你还记得,当前搜索是在每个文档的 name 字段上实现的,这是存储文档标题的地方。 文档还具有 summary 和 content 字段,其中包含较长的文本,也很容易被搜索,但现在这些都被忽略。
在本节中,你将了解另一种常见的全文搜索查询,即 multi-match,它要求在索引的多个字段中执行搜索。
以下是文档中的多重匹配查询示例:
GET /_search
{
"query": {
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ]
}
}
}让我们以此示例为基础来扩展 handle_search() 端点,以对组合的 name、summary 和 content 字段运行多重匹配查询。 这是更新后的端点代码:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
results = es.search(
query={
'multi_match': {
'query': query,
'fields': ['name', 'summary', 'content'],
}
}
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=0,
total=results['hits']['total']['value'])进行此更改后,需要搜索的文本会多得多,以至于某些查询的默认返回结果数可能超过 10 个。 在下一章中,你将学习如何通过分页处理长结果列表。请详细阅读文章 “Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (二)”。