论文描述:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
论文作者:Deyao Zhu∗ Jun Chen∗ Xiaoqian Shen Xiang Li Mohamed Elhoseiny
作者单位:King Abdullah University of Science and Technology
论文原文:https://arxiv.org/abs/2304.10592
论文出处:–
论文被引:457(12/31/2023)
论文代码:https://github.com/Vision-CAIR/MiniGPT-4,21.4k star
项目主页:https://minigpt-4.github.io/
ABSTRACT
最近的 GPT-4 展示了非凡的多模态能力,例如直接从手写文本生成网站,以及识别图像中的幽默元素。这些功能在以往的视觉语言模型中很少见。然而,GPT-4 背后的技术细节仍未公开。我们认为,GPT-4 增强的多模态生成能力源于对复杂的大型语言模型(LLM)的利用。为了研究这一现象,我们提出了 MiniGPT-4,它使用一个投影层将冻结的视觉编码器与冻结的高级 LLM Vicuna 对齐。我们的研究首次发现,将视觉特征与先进的大型语言模型进行适当对齐,可以拥有 GPT-4 所展示的众多先进的多模态能力,例如生成详细的图像描述和根据手绘草稿创建网站。此外,我们还观察到 MiniGPT-4 的其他新兴/涌现能力(emerging capabilities),包括根据给定图像编写故事和诗歌,根据食物照片教用户如何烹饪等。在我们的实验中,我们发现在较短的图片描述对(image caption pair)上训练的模型可能会产生不自然的语言输出(e.g, repetition and fragmentation)。为了解决这个问题,我们在第二阶段策划了一个详细的图片描述数据集来对模型进行微调,从而提高了模型生成的可靠性和整体可用性。
1 INTRODUCTION
近年来,大型语言模型(LLMs)取得了突飞猛进的发展(Ouyang et al., 2022;OpenAI,2022;Brown et al., 2020;Scao et al., 2022a;Touvron et al., 2023;Chowdhery et al., 2022;Hoffmann et al., 2022)。这些模型具有超强的语言理解能力,能以零样本的方式完成各种复杂的语言任务。值得注意的是,最近推出的大规模多模态模型 GPT-4 展示了视觉语言理解和生成方面的多项令人印象深刻的能力(OpenAI,2023)。例如,GPT-4 可以生成详细而准确的图像描述,解释不寻常的视觉现象,甚至可以根据手写文本指令构建网站。
虽然 GPT-4 展示了非凡的视觉语言能力,但其卓越能力背后的方法仍是一个谜。我们认为,这些令人印象深刻的技能可能源于使用了更先进的大型语言模型(LLM)。LLM 已经展示了各种新兴/涌现能力(emergent abilities),GPT-3 的小样本提示设置(Brown et al., 2020)和(Wei et al., 2022)的研究结果都证明了这一点。在较小的模型中很难发现这种特性。据推测,这些新兴能力也适用于多模态模型,这可能是 GPT-4 令人印象深刻的视觉描述(visual description)能力的基础。
为了证实我们的假设,我们提出了一种名为 MiniGPT-4 的新型视觉语言模型。
- 它利用先进的大型语言模型(LLM)Vicuna(Chiang et al., 2023)作为语言解码器,该模型基于 LLaMA(Touvron et al., 2023)构建,据报道,根据 GPT-4 的评估,其质量达到 ChatGPT 的 90%。
- 在视觉感知方面,我们采用了与 BLIP-2(Li et al., 2023)相同的预训练视觉组件,其中包括来自 EVA-CLIP (Fang et al., 2022)的 ViT-G/14 和 Q-Former 网络。
- MiniGPT-4 增加了一个投影层,将编码的视觉特征与 Vicuna 语言模型对齐,并冻结了所有其他视觉和语言组件。
MiniGPT-4 最初在 4 个 A100 GPU 上以 256 的批量大小训练了 20k 步,利用了一个综合图像描述(image captioning)数据集,其中包括来自 LAION(Schuhmann et al., 2021),Conceptual Captions(Changpinyo et al., 2021;Sharma et al., 2018)和 SBU(Ordonez et al., 2011)的图像,以便将视觉特征与 Vicuna 语言模型对齐。然而,仅仅将视觉特征与语言模型(LLM)进行对齐还不足以确保强大的视觉对话能力,与聊天机器人的能力相仿。原始图像-文本对中存在的潜在噪声会导致不合格的语言输出。因此,我们又收集了 3500 对详细的图像描述,利用设计好的对话模板进一步微调模型,以提高生成语言的自然度和可用性。
我们在实验中发现,MiniGPT-4 拥有许多与 GPT-4 类似的功能。例如,MiniGPT-4 可以生成复杂的图像描述,根据手写文本指令创建网站,以及解释不寻常的视觉现象。此外,我们的研究结果表明,MiniGPT-4 还具有 GPT-4 演示中没有展示的其他各种有趣的能力。例如,MiniGPT-4 可以根据食物照片直接生成详细的烹饪食谱,根据图像灵感编写故事或诗歌,根据图像编写产品广告,识别照片中显示的问题并提供相应的解决方案,以及直接从图像中检索有关人物,电影或艺术的丰富事实,等等。以前的视觉语言模型,如 Kosmos-1(Huang et al., 2023)和 BLIP-2(Li et al., 2023),都不具备这些能力。这进一步验证了将视觉特征与先进的语言模型相结合是增强视觉语言模型的关键之一。
我们总结了我们的主要发现:
- 我们的研究以令人信服的证据表明,通过将视觉特征与先进的大型语言模型(如 Vicuna)对齐,MiniGPT-4 可以实现与 GPT-4 演示相媲美的先进视觉语言能力。
- 我们的研究结果表明,只需训练一个投影层,就能有效地将预先训练好的视觉编码器与大型语言模型对齐。我们的 MiniGPT-4 只需要在 4 个 A100 GPU 上训练大约 10 个小时。
- 我们发现,仅仅使用简短的图像描述对(image caption pairs)将视觉特征与大型语言模型对齐,不足以开发出性能良好的模型,还会导致语言生成不自然。使用小而详细的图像描述对进行进一步微调可以解决这一局限性,并显著提高其可用性。
2 RELATED WORKS
Large language models
近年来,由于训练数据的扩大和参数数量的增加,大型语言模型取得了巨大成功。早期的模型,如 BERT(Devlin et al., 2018),GPT-2(Radford et al., 2019)和 T5(Raffel et al., 2020),为这一进展奠定了基础。随后,GPT-3(Brown et al., 2020)以 1,750 亿个参数的庞大规模问世,在众多语言基准方面取得了重大突破。这一发展激励了其他各种大型语言模型的创建,包括:
- MegatronTuring NLG(Smith et al., 2022)
- Chinchilla(Hoffmann et al., 2022)
- PaLM(Chowdhery et al., 2022)
- OPT(Zhang et al., 2022)
- BLOOM(Scao et al., 2022b)
- LLaMA(Touvron et al., 2023)
(Wei et al., 2022)进一步发现了几种新出现的能力,它们只出现在大型模型中。这些能力的出现强调了在开发大型语言模型过程中扩大规模的重要性。此外,通过将预先训练好的大型语言模型GPT-3与人类意图,指令和人类反馈对齐,InstructGPT(Ouyang et al., 2022)和ChatGPT(OpenAI,2022)实现了与人类的对话式交互,并能回答各种不同的复杂问题。最近,基于 LLaMA(Touvron et al., 2023)开发的几个开源模型,如 Alpaca(Taori et al., 2023)和 Vicuna(Chiang et al., 2023),也表现出类似的性能。
Leveraging Pre-trained LLMs in Vision-Language Tasks.
近年来,在视觉语言任务中使用自回归语言模型作为解码器的趋势得到了极大的发展(Chen et al., 2022;Huang et al., 2023;Yang et al., 2022;Tiong et al., 2022;Alayrac et al., 2022;Li et al., 2023;2022;Driess et al., 2023)。这种方法利用了跨模态迁移的优势,允许在语言和多模态领域之间共享知识。
- VisualGPT(Chen et al., 2022)和 Frozen(Tsimpoukelli et al., 2021)等开创性研究证明了采用预先训练的语言模型作为视觉语言模型解码器的好处。
- Flamingo(Alayrac et al., 2022)利用门控交叉注意技术将预先训练好的视觉编码器和语言模型对齐,并在数十亿图像-文本对上进行了训练,展示了令人印象深刻的上下文少量学习能力。
- BLIP-2(Li et al., 2023)采用了带有 Q-Former 的 Flan-T5(Chung et al., 2022),将视觉特征与语言模型有效地对齐。
- 5620 亿参数的 PaLM-E(Driess et al., 2023)用于将真实世界的连续传感器模态集成到 LLM 中,从而在真实世界的感知和人类语言之间建立联系。
- GPT-4(OpenAI,2023)在对大量对齐图像文本数据进行预训练后,展示了更强大的视觉理解和推理能力。
事实证明,像 ChatGPT 这样的 LLM 可以通过与其他专业模型合作,成为提高视觉语言任务性能的强大工具。例如,
- Visual ChatGPT(Wu et al., 2023)和 MM-REACT(Yang* et al., 2023)展示了 ChatGPT 如何充当协调者的角色,与不同的视觉基础模型整合,促进它们的协作,以应对更复杂的挑战。
- ChatCaptioner (Zhu et al., 2023)将 ChatGPT 视为提问者,提出各种问题让 BLIP-2 回答。通过多轮对话,ChatGPT 从 BLIP-2 中提取视觉信息,并有效总结图像内容。
- Video ChatCaptioner(Chen et al., 2023)扩展了这一方法,将其应用于视频时空理解。
- ViperGPT (Sur ́ıs et al., 2023)展示了将 LLM 与不同视觉模型相结合,以编程方式处理复杂视觉查询的潜力。
- 相比之下,MiniGPT-4 直接将视觉信息与语言模型对齐,无需使用外部视觉模型即可完成各种视觉语言任务。
3 METHOD
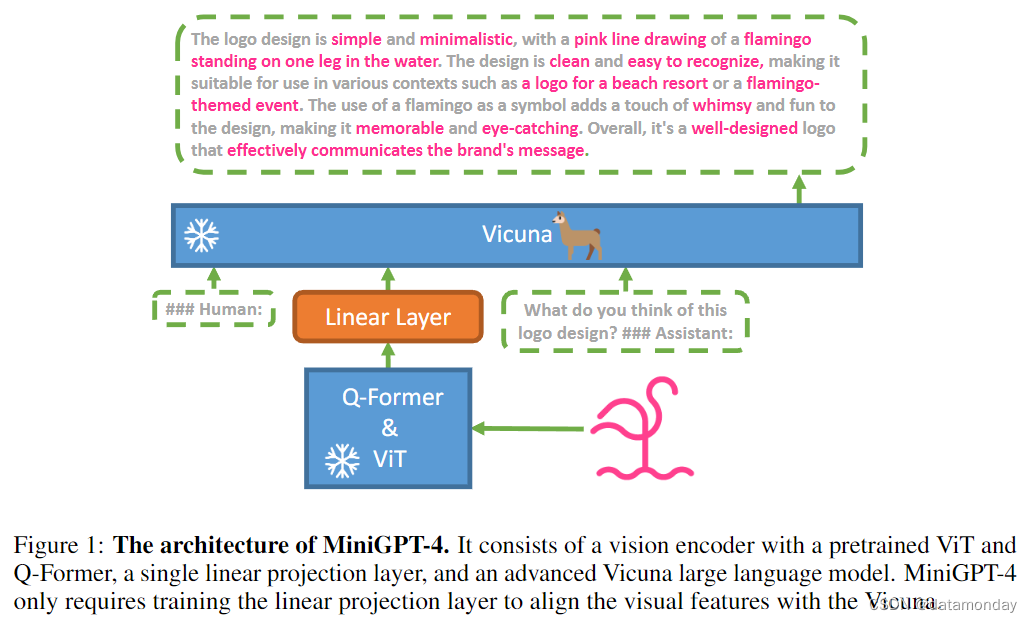
MiniGPT-4 的目标是将来自预训练视觉编码器的视觉信息与先进的大型语言模型(LLM)对齐(Alignment)。具体来说,
- 使用 Vicuna(Chiang et al., 2023)作为语言解码器,该解码器基于 LLaMA(Touvron et al., 2023)构建,可以执行各种复杂的语言任务。
- 视觉感知方:采用与 BLIP-2 (Li et al., 2023)相同的视觉编码器,ViT Backbone(Fang et al., 2022)及其预先训练好的 Q-Former。
语言和视觉模型都是开源的。我们的目标是利用线性投影层弥合视觉编码器与 LLM 之间的差距,图 1 显示了模型概览。
为了实现有效的 MiniGPT-4,我们提出了一种两阶段训练方法。
- 第一阶段:在大量对齐的图像-文本对上对模型进行预训练,以获取视觉语言知识。
- 第二阶段:使用一个较小但高质量的图像-文本数据集对预训练模型进行微调,并设计了对话模板,以提高生成的可靠性和可用性。
3.1 FIRST PRETRAINING STAGE
在初始预训练阶段,该模型旨在从大量对齐图像-文本对中获取视觉-语言知识。我们将注入投影层的输出视为对 LLM 的软提示,促使它生成相应的地面实况文本。
在整个预训练过程中,预训练的视觉编码器和线性投影层都保持冻结状态,只有线性投影层进行了预训练。使用 Conceptual Caption(Changpinyo et al., 2021;Sharma et al., 2018),SBU(Ordonez et al., 2011)和 LAION(Schuhmann et al., 2021)的组合数据集来训练模型。经过 20,000 个训练步骤,批量大小为 256,约 500 万个图像-文本对。整个过程耗时约 10 个小时,使用了 4 个 A100 (80GB) GPU。
Issues of the first pretraining stage
第一个预训练阶段之后,MiniGPT-4 显示出拥有丰富知识的能力,并能对人类的询问做出合理的回答。不过,我们也观察到它产生不连贯语言输出的情况,如重复的单词或句子,支离破碎的句子或无关内容。这些问题阻碍了 MiniGPT-4 与人类进行流畅视觉对话的能力。
我们在 GPT-3 中也观察到了类似的挑战。尽管在大量语言数据集上进行了预训练,GPT-3 仍然难以生成与用户意图准确一致的语言输出。通过指令微调和从人类反馈中强化学习,GPT-3 演化成了 GPT-3.5(Ouyang et al., 2022;OpenAI,2022),并能够产生更多对人类友好的输出。这一现象与 MiniGPT-4 在初始预训练阶段后的现状相似。因此,我们的模型在这一阶段可能难以生成流畅自然的人类语言输出也就不足为奇了。
3.2 CURATING A HIGH-QUALITY ALIGNMENT DATASET FOR VISION-LANGUAGE DOMAIN.
为了使生成的语言更加自然,提高模型的可用性,第二阶段的对齐过程必不可少。虽然在 NLP 领域,指令微调数据集(Taori et al., 2023)和对话(sha,2023)很容易获得,但在视觉语言领域却没有相应的数据集。为了弥补这一不足,我们制作了一个详细的图像描述数据集,专门用于视觉语言对齐。在第二阶段对齐过程中,利用该数据集对 MiniGPT-4 进行微调。
Initial aligned image-text generation
在初始阶段,我们使用从第一个预训练阶段得到的模型来生成输入图像的描述。为了使模型能够生成更详细的图像描述,我们设计了一个符合 Vicuna(Chiang et al., 2023)语言模型对话格式的提示(Prompt),如下所示。在该提示中, 表示线性投影层生成的视觉特征。
###Human: <Img><ImageFeature></Img>Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
为了识别不完整的句子,我们会检查生成的句子是否超过 80 个词组。如果没有,则加入一个额外的提示:###Human: Continue ###Assistant: ,提示MiniGPT-4 延长生成过程。通过串联这两个步骤的输出,我们可以创建一个更全面的图像描述。通过这种方法,我们可以生成具有详细图像描述的图像-文本对。我们从Conceptual Caption dataset(Changpinyo et al., 2021;Sharma et al., 2018)中随机选取 5000 张图片,使用预训练模型为每张图片生成相应的语言描述。
Data post-processing
上述自动生成的图片说明包含噪音或不连贯的描述,例如单词或句子重复,句子支离破碎或内容不相关。为了解决这些问题,我们采用了 ChatGPT,通过以下提示对描述进行修补:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
完成后处理阶段后,我们会手动验证每张图片说明的正确性,以保证其高质量。具体来说,我们首先找出了几个经常出现的错误(“I’m sorry I made a mistake…”, or “I apologize for that …”),然后用硬编码规则自动过滤掉这些错误。我们还通过人工方式完善生成的描述,剔除 ChatGPT 未能检测到的多余单词或句子。最后,在 5000 个图片-文本对中,只有约 3500 个符合我们的要求,这些图片-文本对随后被用于第二阶段的对齐过程。
3.3 SECOND-STAGE FINETUNING
在第二阶段,我们利用准备好的高质量图像-文本对微调预训练模型。在微调过程中,使用以下模板中的预定义提示:
###Human: <Img><ImageFeature></Img><Instruction>###Assistant:
在此提示中, 表示从我们预定义的指令集中随机抽取的指令,其中包含 “Describe this image in detail” 或 “Could you describe the contents of this image for me” 等不同形式的指令。我们并不计算这一特定文本图像提示的回归损失。
因此,MiniGPT-4 现在能够生成更自然,更可靠的语言输出。此外,我们还发现,这种微调过程的效率非常高,在批量为 12 的情况下,只需要 400 个训练步骤,而使用单个 A100 GPU 则需要 7 分钟左右。
4 EXPERIMENTS
在实验中,我们旨在通过各种定性实例展示 MiniGPT-4 模型的各种新兴能力。这些能力包括生成详细的图像描述,识别备忘录中有趣的方面,从照片中提供食物食谱,为图像写诗等。此外,我们还展示了图像描述任务的定量结果。
4.1 UNCOVERING EMERGENT ABILITIES WITH MINIGPT-4 THROUGH QUALITATIVE EXAMPLES
与传统的视觉语言模型相比,MiniGPT-4 展示了许多先进的能力。例如,它能详细描述图像,并能解释给定备忘录的幽默方面。在这里,我们将我们的模型与领先的视觉语言模型之一 BLIP-2(Li et al., 2023)进行了定性比较,并列举了八个不同的例子,每个例子都突出了一种不同的能力。

图 2 中的一个例子表明,MiniGPT-4 能有效识别图像中的各种元素,如繁忙的城市街道,钟楼,商店,餐馆,摩托车,人,路灯和云。相比之下,BLIP-2 在生成图像描述时只能涵盖城市街道,人和摩托车。图 4a 中的另一个例子表明,MiniGPT-4 成功地解释了该备忘录幽默的原因。它解释了躺着的狗和许多人在星期一的感受是一样的,星期一通常被认为是一周中最可怕的一天。相比之下,BLIP-2 只简单描述了图片内容,未能理解图片的有趣之处。

我们还展示了 MiniGPT-4 的其他独特能力。这些能力包括:
- 根据给定图像创建广告促销文案(图 3)
- 从电影照片中检索事实信息(图 8)
- 从食物图像生成食物食谱(图 11)
- 诊断植物疾病并提出治疗方案(图 12)
- 根据手写草稿创建网站(图 4b)
- 根据图像灵感写诗(图 10)
传统的视觉语言模型,如 BLIP-2(使用 Flan-T5 XXL(Chung et al., 2022)作为语言模型),使用功能较弱的语言模型,则不具备这些能力。这种对比表明,只有当视觉特征与 Vicuna(Chiang et al., 2023)等先进的 LLM 适当对齐时,才会出现这些先进的视觉语言能力。
4.2 QUANTITATIVE ANALYSIS
Advanced Abilities
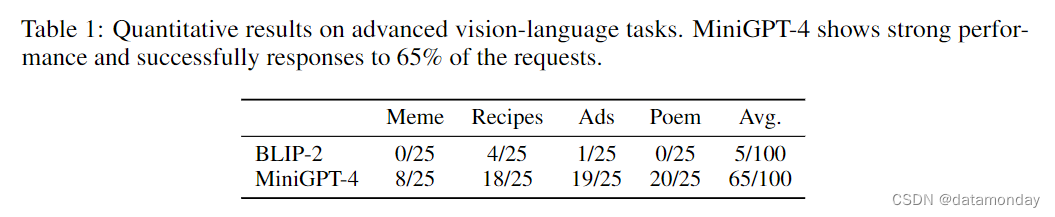
为了量化高级视觉语言任务的性能,我们编制了一个由 4 个任务组成的小型评估数据集:
- Explain why this meme is funny
- How should I make something like this?
- Help me draft a professional advertisement for this.
- Can you craft a beautiful poem about this image?
我们总共收集了 100 张不同的图片,每项任务分配 25 张图片。我们请人类评估员确定模型生成是否满足要求。我们将结果与 BLIP-2(Li et al., 2023)进行了比较,结果见表 1。在备忘录解释,诗歌创作和广告创作方面,BLIP-2 在很大程度上难以满足任何要求。在食谱生成方面,BLIP-2 在 25 个案例中成功了 4 个。相比之下,MiniGPT-4 能在近 80% 的情况下满足食谱,广告和诗歌创作的请求。此外,在 25 个案例中,MiniGPT-4 在 8 个案例中正确理解了备忘录中具有挑战性的幽默理解。
Image Captioning
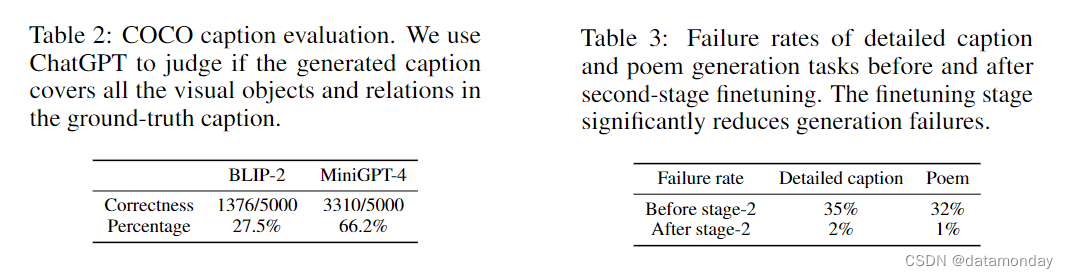
我们在 COCO 描述基准上评估了 MiniGPT-4 的性能,并将其与 BLIP-2 进行了比较(Li et al., 2023)。我们的模型生成的描述通常包含丰富的视觉细节。传统的基于相似性的图像描述评估指标很难对我们的模型进行准确评估。为此,我们借助 ChatGPT 来检查生成的描述是否涵盖了所有真实描述的信息,以此来评估模型的性能,详情见附录 A.3。表 2 中的结果表明,MiniGPT-4 在生成与真实视觉物体和关系更接近的描述方面优于 BLIP-2。MiniGPT-4 的成功率为 66.2%,比 BLIP-2 高出许多,后者的成功率仅为 27.5%。对传统 VQA 任务的进一步评估见附录 A.2。
4.3 ANALYSIS ON THE SECOND-STAGE FINETUNING
Effectiveness of the second-state finetuning

仅使用第一阶段预训练后的预训练模型可能会导致失败,例如出现重复的单词或句子,支离破碎的句子或不相关的内容。不过,通过第二阶段的微调过程,这些问题在很大程度上得到了缓解。从图 5 中可以看出,在第二阶段微调之前,MiniGPT-4 生成的描述并不完整。然而,经过第二阶段微调后,MiniGPT-4 能够生成完整流畅的描述。在本节中,我们将探讨第二阶段微调方法的重要性和有效性。
为了量化第二阶段微调的影响,我们从 COCO 测试集中随机抽取了 100 幅图像,并考察了模型在详细描述生成和诗歌创作这两项任务中的表现。使用的提示分别是:
- Describe the image in detail.
- Can you write a beautiful poem about this image?
模型在第二阶段微调之前和之后都执行了这些任务。我们人工统计了模型在每个阶段的失败的生成。结果如表 3 所示:在第二阶段微调之前,大约有 1/3 的生成输出与真实描述或诗歌不匹配。相比之下,经过第二阶段微调后的模型在这两项任务的 100 张测试图像中只有不到 2 个失败案例。这些实验结果表明,第二阶段微调能显著提高生成输出的质量。图 5 显示了第二阶段微调前后模型生成的定性示例。
Can the original BLIP-2 benefit from the second-stage data?
在本研究中,我们采用与 MiniGPT-4 相同的方法,利用我们的第二阶段数据对 BLIP-2(Li et al., 2023)进行了微调,并检验它是否能获得与 MiniGPT-4 类似的高级能力。经过微调的 BLIP-2 被称为 BLIP-2 FT。请注意,MiniGPT-4 使用与 BLIP-2 相同的视觉模块;而 BLIP-2 使用 FlanT5 XXL(Chung et al., 2022)作为语言模型,其强度不及 MiniGPT-4 模型中使用的 Vicuna(Chiang et al., 2023)模型。我们依靠相同的提示来评估我们模型的高级能力。定性结果如图 4,13 和 14 所示。我们发现,BLIP-2 FT 生成的反应仍然很短,而且无法推广到备忘录解释和网站编码等高级任务中(图 4)。我们的发现表明,BLIP-2 相对较弱的语言模型 FlanT5 XXL 从如此小的数据集中获益较少,并凸显了在 VLM 系统中更先进的 LLM 的有效性。
Second stage with Localized Narratives
Localized Narratives Dataset(Pont-Tuset et al., 2020)是一个详细的图像描述数据集,其中注释者在描述图像的同时对相应区域进行定位。在这里,我们用 Localized Narratives dataset 取代第二阶段的自收集数据集,以此测试我们模型的性能。该模型命名为 MiniGPT-4 LocNa。图 4,13 和 14 中的定性结果表明,MiniGPT-4 LocNa 可以生成较长的图像描述(图 14)。然而,生成的输出质量较低,表达单调。此外,MiniGPT-4 LocNa 在其他复杂任务中的泛化能力不如原始的 MiniGPT-4,如解释 meme 为何有趣(图 4a)。造成这种性能差距的原因可能是 Localized Narratives dataset 中单调重复的图像描述。
4.4 ABLATION ON THE ARCHITECTURE DESIGNS
为了进一步证明使用单个线性层将视觉特征与 LLM 对齐的有效性,我们进行了不同架构设计的实验,包括:
- a)移除 QFormer 并将 VIT 的输出直接映射到 Vicuna 的嵌入空间(不使用 Q-former)
- b)使用三个线性层而不是一个层
- c)在视觉模块中对 Q-Former 进行额外的微调
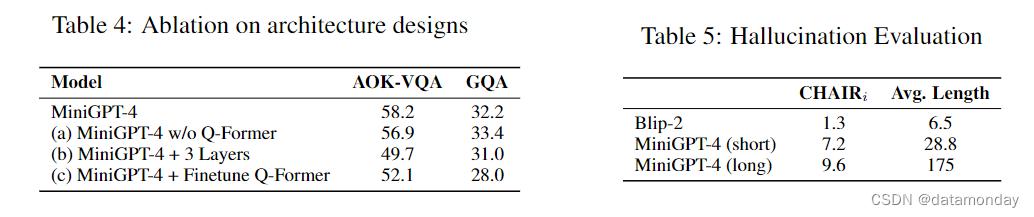
所有变体的训练方法与原始设计相同。表 4 中 AOK-VQA 数据集(Schwenk et al., 2022)和 GQA 数据集(Hudson & Manning, 2019)的结果表明,
- 变体 (a) MiniGPT-4 w/o Q-Former 的性能与原始设计相似。图 4,13 和 14 中该变体的定性结果也显示出类似的高级技能。这表明,BLIP-2 中的 Q-Former 对高级技能并没有起到关键作用。
- (b) MiniGPT-4+ 3 层和 © MiniGPT-4 + 微调 Q-Former 这两个变体的表现都略逊于原始的 MiniGPT-4。这表明,在我们有限的训练数据设置中,单个投影层足以使视觉编码器和大型语言模型保持一致。
4.5 LIMITATION ANALYSIS
Hallucination
由于 MiniGPT-4 建立在 LLM 的基础上,因此它也继承了 LLM 的局限性,如产生不存在知识的幻觉。图 6 中的一个例子表明,尽管图像中没有白色桌布,但 MiniGPT-4 却错误地识别出了桌布的存在。在这里,我们使用指标 CHAIRi(Rohrbach et al., 2018)来衡量生成的幻觉率,并用两种不同的提示来控制模型生成的长度:
- MiniGPT-4 (long): Please describe this image as detailed as possible.
- MiniGPT-4 (short): Please describe the image shortly and precisely, in less than 20 words.
表 5 中的结果显示,较长的描述往往会产生较高的幻觉率。例如,MiniGPT-4 (long) 生成的描述平均单词数为 175 个,幻觉率较高;而 MiniGPT-4 (short) 生成的描述平均单词数为 28.8 个,幻觉率较低。如表 2 所示,BLIP-2(平均 6.5 个单词)产生的幻觉较少,但涵盖的对象较少。 在详细的图像描述中产生幻觉仍是一个尚未解决的问题。利用带有幻觉检测模块的强化学习和人工智能反馈可能是一个潜在的解决方案。
Spatial Information Understanding
MiniGPT-4 的视觉感知能力仍然有限。它可能难以区分空间定位。例如,图 6 中的 MiniGPT-4 无法识别窗户的位置。这种局限性可能是由于缺乏专为空间信息理解而设计的对齐图像-文本数据。在 RefCOCO(Kazemzadeh et al., 2014)或 Visual Genome(Krishna et al., 2017)等数据集上进行训练可能会缓解这一问题。
5 DISCUSSION
MiniGPT-4 是如何获得这些高级能力的?GPT-4 展示的许多高级视觉语言能力可以理解为植根于两项基础技能的合成技能:图像理解和语言生成。以基于图像的诗歌创作任务为例。像 ChatGPT 和 Vicuna 这样的高级 LLM 已经可以根据用户的指令创作诗歌。如果它们掌握了理解图像的能力,那么即使在训练数据中没有图像-诗歌对,也可以将构图能力推广到基于图像的诗歌创作任务中。
在第一个预训练阶段,MiniGPT-4 通过对图像和来自图像描述数据集的简短图像描述之间的相关性建模来学习理解图像。然而,这些图像描述数据集的语言风格与现代 LLM 生成的语言风格不同,导致语言生成失真,阻碍了成功的构图泛化。因此,我们引入了第二阶段微调来恢复语言生成能力。经过两阶段训练后,MiniGPT-4 成功地泛化了许多高级的视觉语言合成能力,如根据草稿进行网站编码或进行 meme 解释,验证了我们的假设。未来的研究可能会深入探讨构 compositional generalization 的机制,并寻求提高该能力的方法。我们希望我们的工作,作为对这些基于视觉的 LLM 能力的早期探索,能推动这一领域的进一步研究。