本文将按照transformer的结构图依次对各个模块进行讲解:
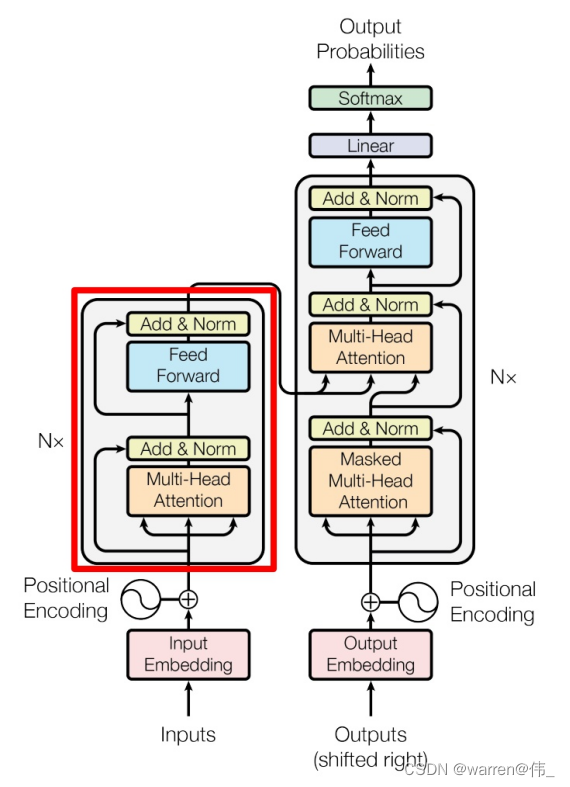
可以看一下模型的大致结构:主要有encode和decode两大部分组成,数据经过词embedding以及位置embedding得到encode的时输入数据
- embedding就是从原始数据中提取出单词或位置;
输入矩阵:

位置编码采用如下公式

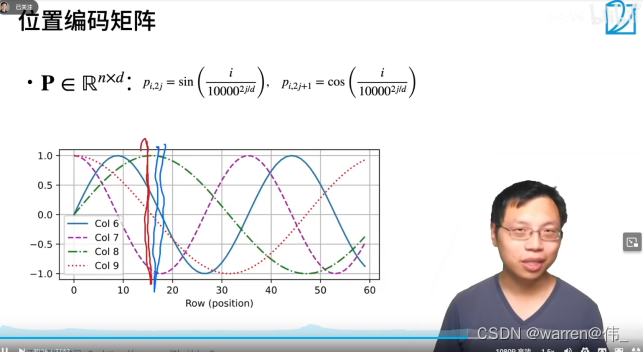
- 好处有使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
encode里有6个encode块,每一个块里包含了一个自注意层、残差以及归一化、前向传播层、残差及归一化构成

attention结构

计算公式

我们可以理解为搜索引擎:q就是你要搜索的关键字,k就是各个词条的标题,而v就是词条的全文,最后得到attention的就是与你想要搜索的关键字的相关程度,注意力分数是query和key的相似度,注意力权重是分数的softmax结果。
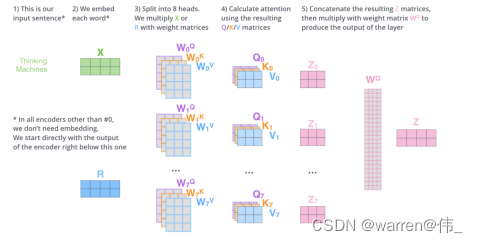
多头机制
并行堆叠attention,主要目的是为了增强模型对输入序列的表示能力和建模能力。多头自注意力允许模型同时关注输入序列中的不同位置和不同关系,从而提高了模型对序列中的长距离依赖关系和语义关系的建模能力。
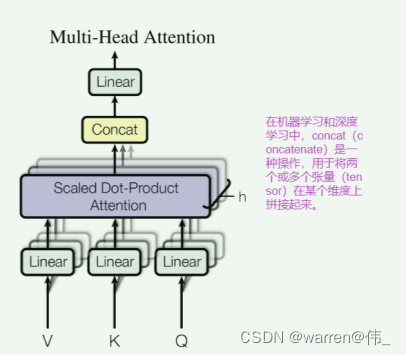

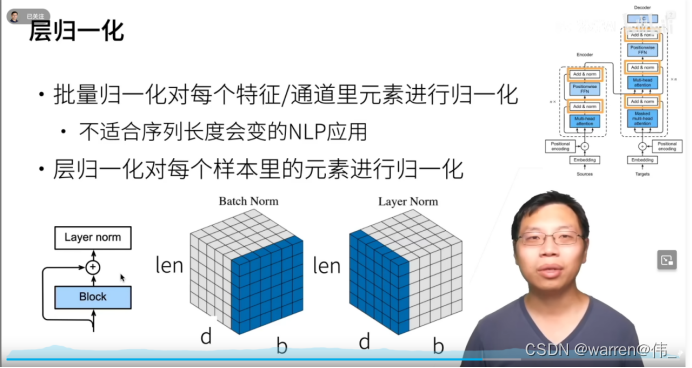
Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成。Add 类似ResNet提出的残差连接,以解决深层网络训练不稳定的问题。Norm为归一化层,即Layer Normalization,通常用于 RNN 结构。
Feed Forward
Feed Forward 层比较简单,由两个全连接层构成,第一层的激活函数为 ReLu,第二层不使用激活函数,对应的公式如下。
(max(0,XW1+b1))W2+b2
对于输入X,Feed Forward 最终得到的输出矩阵的维度与输入X一致

解码模块
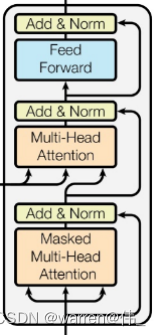

与encode最主要的区别就是多了一个带mask的多头注意力,在训练的过程中采用了teacher forcing(即将正确的序列也送入),但是为了不让模型提前知道将要预测的句子,采用了掩码
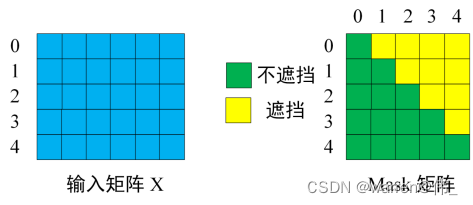

三种attention
文章一开始解释了Self-Attention和Multi-Head Attention。通过对Transformer模型的深入解读,可以看到,模型一共使用了三种Multi-Head Attention:
1)Encoder Block中使用的Attention。第一个Encoder Block的Query、Key和Value来自训练数据经过两层Embedding转化,之后的Encoder Block的Query、Key和Value来自上一个Encoder Block的输出。
2)Decoder Block中的第一个Attention。与Encoder Block中的Attention类似,只不过增加了Mask,在预测第 ii个输出时,要将第i+1i+1 之后的单词掩盖住。第一个Decoder Block的Query、Key和Value来自训练数据经过两层Embedding转化,之后的Decoder Block的Query、Key和Value来自上一个Decoder Block的输出。
- Decoder Block中的第二个Attention。这是一个 Encoder-Decoder Attention,它建立起了 Encoder 和 Decoder 之间的联系,Query来自第2种 Decoder Attention的输出,Key和Value 来自 Encoder 的输出。
1)通常情况下,embedding嵌入向量被训练为捕捉单词之间的语义和语法关系;
2)tokenize操作就是把句子切分成单词和标点符号即可,同时对其进行序列转化;
参考博文:
自注意力:
Attention 注意力机制 | 鲁老师
transformer:
Transformer | 鲁老师gggT