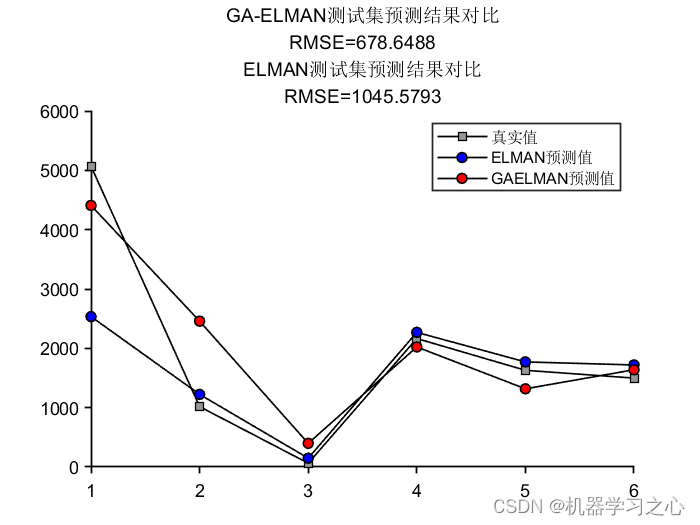
01 实现思路
首先,利用哔哩哔哩的弹幕接口,把数据保存到本地。接着,对数据进行分词。最后,做了评论的可视化。
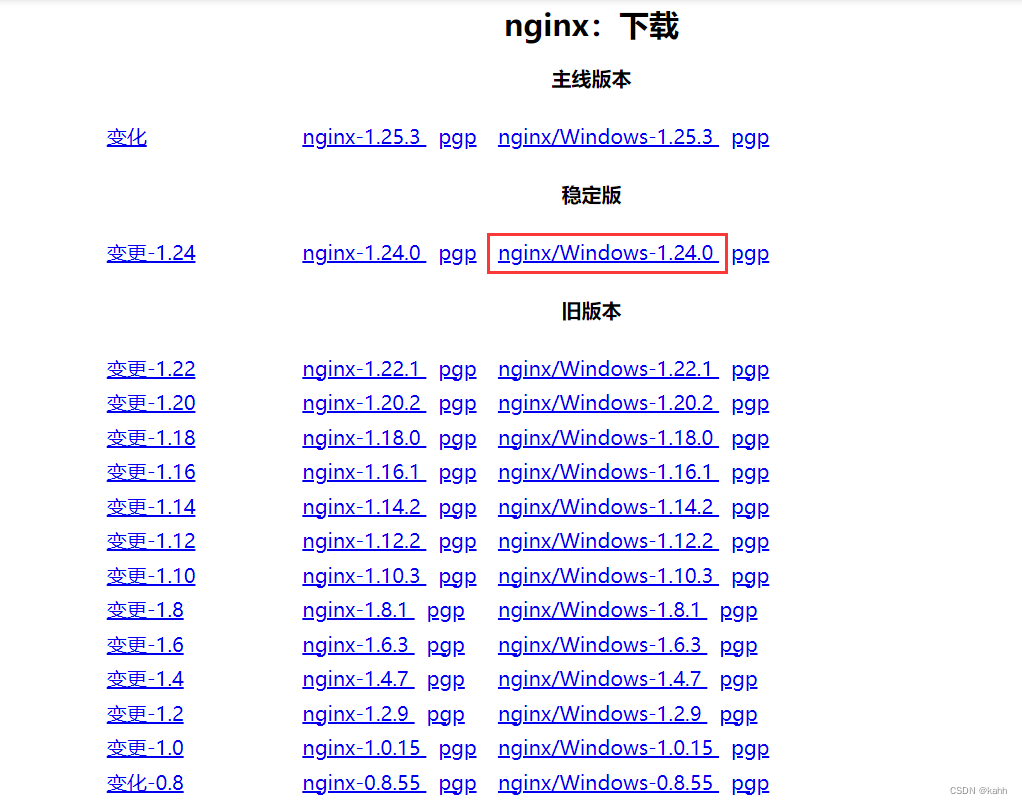
02 弹幕数据

平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的。
比如:
https://comment.bilibili.com/123072475.xml
一个固定的url地址 + 视频的cid + .xml
只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?
右键网页,打开网页源代码,搜索 "cid": 就能找到:

03 保存数据到本地
有了数据的接口链接,我们就可以利用request模块,获取数据了。
然后,再利用xpath简单的解析xml,就可以把所有的弹幕信息汇总到一个列表里了。最后,把列表转化成dataframe,保存到本地。
# 许嵩新歌《雨幕》
# bilibili视频弹幕文件
url = 'https://comment.bilibili.com/123072475.xml'
# 发送请求
response = requests.get(url)
xml = etree.fromstring(response.content)
# 解析数据
dm = xml.xpath("/i/d/text()")
print(dm) # list
# 把列表转换成 dataframe
dm_df = pd.DataFrame(dm, columns=['弹幕内容'])
print(dm_df)
# 存到本地
# 解决了中文乱码问题
dm_df.to_csv('雨幕-弹幕.csv', encoding='utf_8_sig')
保存的csv数据:
![]()

04 对数据进行分词
制作词云前,需要把弹幕数据进行分词。
关于jieba分词,可以参考:
https://blog.csdn.net/dnxbjyj/article/details/72854460
# jieba分词
dm_str = " ".join(dm)
words_list = jieba.lcut(dm_str) # 切分的是字符串,返回的是列表
words_str = " ".join(words_list)
05 词云可视化
通过创建词云对象、设置词云参数,最终生成图片,保存到本地。
# 读取本地文件
backgroud_Image = plt.imread('1.jpg')
# 创建词云
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='./SourceHanSerifCN-Medium.otf', # 设置本地字体
max_words=2000,
max_font_size=100,
min_font_size=10,
color_func=random_color_func,
random_state=50,
)
word_cloud = wc.generate(words_str) # 产生词云
word_cloud.to_file("yumu.jpg") #保存图片