Apache Kafka Spring 集成
今天来学习Spring如何集成 Apache kafka,在Spring Boot中如何集成kafka客户端 生产、消费消息。首先介绍下各个组件的版本信息:
- Apache Kafka_2.13-3.3.1
- Spring Boot 3.0.0
- Apache-Maven-3.6.0
- JDK-17.0.5
启动Kafka
# 进入kafka安装主目录
# 启动Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# 启动kafka
bin/kafka-server-start.sh config/server.properties
Maven依赖
<modelVersion>4.0.0</modelVersion>
<groupId>org.kafka.spring.example</groupId>
<artifactId>kafka-spring-example</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
Spring Boot 之生产者
生产者代码
@SpringBootApplication
public class KafkaApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaApplication.class, args);
}
@Bean
public NewTopic topic() {
return TopicBuilder.name("topic100")
.partitions(2)
.replicas(1)
.build();
}
@KafkaListener(id = "myId", topics = "topic1")
public void listen(String in) {
System.out.println(in);
}
@Bean
public ApplicationRunner runner(KafkaTemplate<String, String> template) {
return args -> {
template.send("topic100", "test");
};
}
}
启动代码,系统自动创建topic 并发送消息至 Kafka Broker。
消费者代码
./bin/kafka-console-consumer.sh --topic topic100 --from-beginning --bootstrap-server localhost:9092

如上图,消费者程序已经成功地消费生产者发送的消息,至此已经实现了Spring Boot集成Kafka 生产者、消费者最简单的代码逻辑。
Kafka配置
细心的同学可能已经注意到了,上述生产者代码并没有指定kafka的配置,如连接地址 就能够正常的向 localhost:9092 的kafka 发送消息了。如果kafka安装在内网中的其他机器的话,就需要为生产者配置相关的属性,代码如下:
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(senderProps());
}
private Map<String, Object> senderProps() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
只需要在KafkaApplication增加如上两个方法代码,即可实现。如果再动态化一点,可以相关的配置放置到配置文件中,然后使用 @Value注解引用配置属性,再注入到构造kafka生产者/消费者实例中。
生产者监听
某些情况下,生产者需要监听数据是否发送成功,以便做特殊的业务处理。Spring 定义了核心接口 - ProducerListener用于实现数据发送的信息回调:
public interface ProducerListener<K, V> {
//消息发送成功回调函数
default void onSuccess(ProducerRecord<K, V> producerRecord, RecordMetadata recordMetadata);
//消息发送失败回调函数
default void onError(ProducerRecord<K, V> producerRecord, RecordMetadata recordMetadata,
Exception exception);
}
默认情况下,发送模板类 - KafkaTemplate 配置LoggingProducerListener,它记录错误,当发送成功时不做任何操作。如果需要监听消息发送成功的状态,需要开发者实现接口并配置到KafkaTemplate类中。
@Bean
public KafkaTemplate<String, String> kafkaTemplate(ProducerFactory<String, String> producerFactory) {
KafkaTemplate<String, String> template = new KafkaTemplate<>(producerFactory);
template.setProducerListener(new ProducerListener(){
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata metadata) {
System.out.println("============== onSuccess : " + metadata.offset());
}
@Override
public void onError(ProducerRecord producerRecord, RecordMetadata metadata, Exception exception) {
System.out.println("============== onError : " + metadata.offset() + " , " + exception.getMessage());
}
});
return template;
}
在KafkaApplication类中添加以上方法,然后重新启动程序,可以在控制台看到发送成功的日志信息。
发送结果
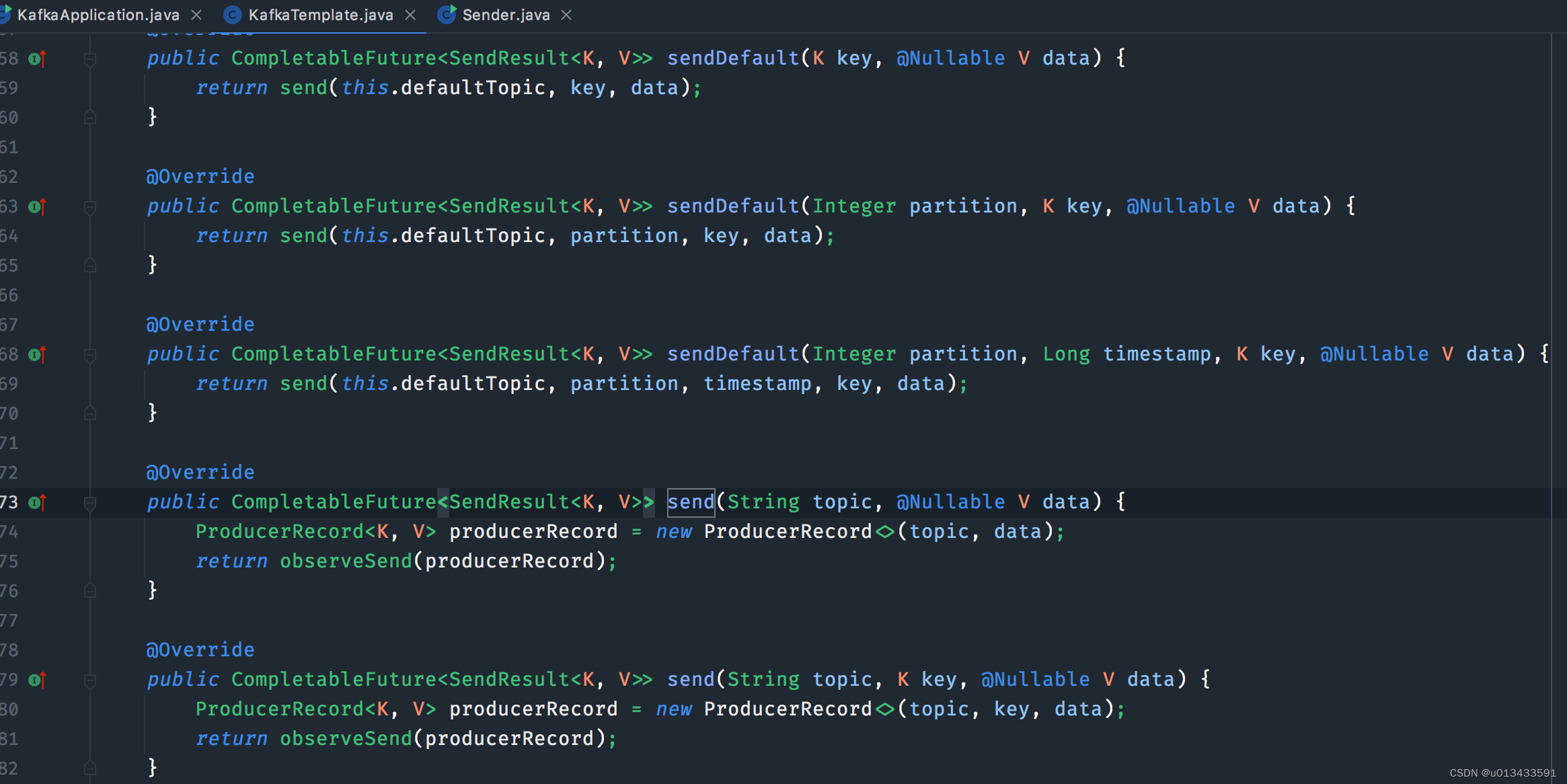
如上图,消息发送模板类 - KafkaTemplate 中定义的所有发送消息方法的返回对象都是 CompletableFuture<SendResult<K, V>>,CompletableFuture 类是 Future接口的实现类,因此可以调用该类的方法实现
-
同步等待返回结果
@Bean public ApplicationRunner runner(KafkaTemplate<String, String> template) { return args -> { CompletableFuture<SendResult<String, String>> future = template.send("topic100", "test"); // 同步等待 发送结果 SendResult<String, String> result = future.get(10, TimeUnit.SECONDS); RecordMetadata metadata = result.getRecordMetadata(); System.out.println("offset : " + metadata.offset()); }; } -
异步执行发送结果
@Bean public ApplicationRunner runner(KafkaTemplate<String, String> template) { return args -> { CompletableFuture<SendResult<String, String>> future = template.send("topic100", "test"); future.whenComplete((result, ex) -> { if (ex == null) { System.out.println("数据发送成功"); return; } System.out.println("数据发送失败: " + ex.getMessage()); }); }; }
RoutingKafkaTemplate
从spring-kafka 2.5 开始,开发者可以使用RoutingKafkaTemplate在运行时根据目标主题名称选择生产者。但是需要注意:路由模板不支持事务、执行、刷新或metrics操作,因为此类操作时的主题未知
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public RoutingKafkaTemplate routingTemplate(GenericApplicationContext context,
ProducerFactory<Object, Object> pf) {
// 复制生产者默认的属性
Map<String, Object> configs = new HashMap<>(pf.getConfigurationProperties());
// 覆盖属性
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
// 新注册一个生产者
DefaultKafkaProducerFactory<Object, Object> bytesPF = new DefaultKafkaProducerFactory<>(configs);
context.registerBean(DefaultKafkaProducerFactory.class, "bytesPF", bytesPF);
Map<Pattern, ProducerFactory<Object, Object>> map = new LinkedHashMap<>();
map.put(Pattern.compile("two"), bytesPF);
map.put(Pattern.compile(".+"), pf); // Default PF with StringSerializer
return new RoutingKafkaTemplate(map);
}
@Bean
public ApplicationRunner runner(RoutingKafkaTemplate routingTemplate) {
return args -> {
routingTemplate.send("one", "thing1");
routingTemplate.send("two", "thing2".getBytes());
};
}
}
DefaultKafkaProducerFactory
框架内部使用ProducerFactory工厂类创建KafkaTemplate模板发送类。默认情况下,当不使用Transactions时,DefaultKafkaProducerFactory会创建一个供所有客户端使用的单例生产者,正如KafkaProduction javadocs中所建议的那样。但是,如果在模板上调用flush(),这可能会导致使用同一生成器的其他线程延迟。从2.3版开始,DefaultKafkaProducerFactory有一个新的属性producerPerThread。当设置为true时,工厂将为每个线程创建(并缓存)一个单独的生产者,以避免此问题。
注意:当producerPerThread为true时,当不再需要生产者时,用户代码必须在工厂上调用closeThreadBoundProducer()。这将实际关闭生成器并将其从ThreadLocal中删除。调用reset()或destroy()不会清除这些生产者。
ReplyingKafkaTemplate
2.1.3版引入了KafkaTemplate的子类,以提供请求/应答语义。该类名为ReplyingKafkaTemplate,有两个额外的方法;下面显示了方法签名:
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record);
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record,
Duration replyTimeout);
如果使用了第一个方法,或者replyTimeout参数为空,则使用模板的defaultReplyTimeout属性(默认为5秒)。相关代码如下
@SpringBootApplication
public class KRequestingApplication {
public static void main(String[] args) {
SpringApplication.run(KRequestingApplication.class, args).close();
}
@Bean
public ApplicationRunner runner(ReplyingKafkaTemplate<String, String, String> template) {
return args -> {
if (!template.waitForAssignment(Duration.ofSeconds(10))) {
throw new IllegalStateException("Reply container did not initialize");
}
ProducerRecord<String, String> record = new ProducerRecord<>("kRequests", "foo");
RequestReplyFuture<String, String, String> replyFuture = template.sendAndReceive(record);
SendResult<String, String> sendResult = replyFuture.getSendFuture().get(10, TimeUnit.SECONDS);
System.out.println("Sent ok: " + sendResult.getRecordMetadata());
ConsumerRecord<String, String> consumerRecord = replyFuture.get(10, TimeUnit.SECONDS);
System.out.println("Return value: " + consumerRecord.value());
};
}
@Bean
public ReplyingKafkaTemplate<String, String, String> replyingTemplate(
ProducerFactory<String, String> pf,
ConcurrentMessageListenerContainer<String, String> repliesContainer) {
return new ReplyingKafkaTemplate<>(pf, repliesContainer);
}
@Bean
public ConcurrentMessageListenerContainer<String, String> repliesContainer(
ConcurrentKafkaListenerContainerFactory<String, String> containerFactory) {
ConcurrentMessageListenerContainer<String, String> repliesContainer =
containerFactory.createContainer("kReplies");
repliesContainer.getContainerProperties().setGroupId("repliesGroup");
repliesContainer.setAutoStartup(false);
return repliesContainer;
}
@Bean
public NewTopic kRequests() {
return TopicBuilder.name("kRequests")
.partitions(10)
.replicas(2)
.build();
}
@Bean
public NewTopic kReplies() {
return TopicBuilder.name("kReplies")
.partitions(10)
.replicas(2)
.build();
}
}
Spring Boot 之消费者
开发者可以通过配置MessageListenerContainer并提供消息监听器或使用@KafkaListener注释来接收消息。
初始化Factory
@Configuration
@EnableKafka
public class ConsumerConfiguration {
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
}
消费监听类
@Component
public class KafkaConsumerExample {
// concurrency : 覆盖工厂生产类的默认线程数量,表示使用多少个线程进行消费
@KafkaListener(id = "myListener", topics = "topic100",
autoStartup = "${listen.auto.start:true}", concurrency = "${listen.concurrency:3}")
public void listen(String data) {
System.out.println(" ----------------------------- consumer data : " + data);
}
}
从控制台可以看出,kafka消费者已经成功消费消息了。
指定分区消费
@KafkaListener(id = "thing2", topicPartitions =
{ @TopicPartition(topic = "topic1", partitions = { "0", "1" }),
@TopicPartition(topic = "topic2", partitions = "0",
partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
})
public void listen(ConsumerRecord<?, ?> record) {
//
}
此外, 还可以使用逗号分隔 指定多个分区,如下:
@KafkaListener(id = "pp", autoStartup = "false",
topicPartitions = @TopicPartition(topic = "topic1",
partitions = "0-5, 7, 10-15"))
public void process(String in) {
...
}
消费元数据
开发者可以从消息头中获得有关记录的元数据。您可以使用以下标头名称来检索消费者元数据:
KafkaHeaders.OFFSETKafkaHeaders.RECEIVED_KEYKafkaHeaders.RECEIVED_TOPICKafkaHeaders.RECEIVED_PARTITIONKafkaHeaders.RECEIVED_TIMESTAMPKafkaHeaders.TIMESTAMP_TYPE
@KafkaListener(id = "qux", topicPattern = "myTopic1")
public void listen(@Payload String foo,
@Header(name = KafkaHeaders.RECEIVED_KEY, required = false) Integer key,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts
) {
}
批量消费
从1.1版开始,开发可以配置@KafkaListener方法来接收从消费者投票中接收的整批消费者记录。要配置侦听器容器工厂以创建批处理侦听器,可以设置batchListener属性。以下示例显示了如何执行此操作:
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true); // <<<<<<<<<<<<<<<<<<<<<<<<<
return factory;
}
@KafkaListener(id = "list", topics = "myTopic", containerFactory = "batchFactory")
public void listen(List<String> list) {
//
}
此外 还可以实现多种接口,以满足特殊场景的需要,如手动管理消费者位移等等。
@KafkaListener(id = "listMsg", topics = "myTopic", containerFactory = "batchFactory")
public void listen14(List<Message<?>> list) {
//...
}
@KafkaListener(id = "listMsgAck", topics = "myTopic", containerFactory = "batchFactory")
public void listen15(List<Message<?>> list, Acknowledgment ack) {
//...
}
@KafkaListener(id = "listMsgAckConsumer", topics = "myTopic", containerFactory = "batchFactory")
public void listen16(List<Message<?>> list, Acknowledgment ack, Consumer<?, ?> consumer) {
// ...
}
指定参数
开发者可以在@KafkaListener注解上 单独的设置消费参数,以覆盖通用的设置:
@KafkaListener(topics = "myTopic", groupId = "group", properties = {
"max.poll.interval.ms:60000",
ConsumerConfig.MAX_POLL_RECORDS_CONFIG + "=100"
})
类级别 @KafkaListener
在类级别使用@KafkaListener时,必须在方法级别指定@KafkaHandler。传递消息时,转换后的消息负载类型用于确定要调用的方法。以下示例显示了如何执行此操作:
@KafkaListener(id = "multi", topics = "myTopic")
static class MultiListenerBean {
@KafkaHandler
public void listen(String foo) {
...
}
@KafkaHandler
public void listen(Integer bar) {
...
}
@KafkaHandler(isDefault = true)
public void listenDefault(Object object) {
...
}
}
消息过滤
在某些情况下,例如重平衡,可能会重新传递已经处理的消息,因此需要一种手段对此类重复的消息进行过滤。
@KafkaListener(id = "filtered", topics = "topic", filter = "differentFilter")
public void listen(Thing thing) {
//
}
如上述代码,开发者只需要在监听器注解上指定过滤器名称即可。同时开发者还需要实现核心接口 - RecordFilterStrategy
public interface RecordFilterStrategy<K, V> {
/**
* 返回true 则表示该消息被过滤掉
* @param consumerRecord the record.
* @return true to discard.
*/
boolean filter(ConsumerRecord<K, V> consumerRecord);
//...
}