文章目录
- 大数据机器学习TF-IDF 算法+SnowNLP智慧旅游数据分析可视化推荐系统
- 一、项目概述
- 二、机器学习TF-IDF 算法
- 什么是TF-IDF?
- TF-IDF介绍
- 名词解释和数学算法
- 三、SnowNLP
- 四、数据爬虫分析
- 五、项目架构思维导图
- 六、项目UI
- 系统注册登录界面
- 各省份热门城市分析
- 城市热门景点分析
- 热门小吃分析
- 景点评论情感分析
- 城市景点路线的智能推荐
- 七、项目总结
大数据机器学习TF-IDF 算法+SnowNLP智慧旅游数据分析可视化推荐系统
一、项目概述
基于机器学习TF-IDF 算法SnowNLP大数据的智慧旅游数据分析可视化推荐系统通过数据采集、数据清洗、数据分析、数据可视化的技术,对景区数据进行爬取和收集。以旅游景点数据为基础分析景区热度,挖掘客流量、景区评价等信息,并对分析的结果进行统计。智慧旅游数据分析系统拟实现景区热度、景区展示、游客统计、景区评价、旅游路线等部分。拟定景区热度通过热力图展示,客流量、景区评价情感分析,景点路线推荐等数据通过折线图、饼图等形式呈现出来,推出各景区旅游路线,并将景区的特色场景展现给游客。
技术栈:Python+机器学习TF-IDF 算法+Requests爬虫+Echarts可视化+SnowNLP(情感分析/文本数据清洗/分词/关键词抽取)+Flask
二、机器学习TF-IDF 算法
什么是TF-IDF?
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序
TF-IDF介绍
TF-IDF实际上是:TF * IDF。主要思想是:如果某个词或短语在一篇文章中出现的频率高(即TF高),并且在其他文章中很少出现(即IDF高),则认为此词或者短语具有很好的类别区分能力,适合用来分类。通俗理解TF-IDF就是:TF刻画了词语t对某篇文档的重要性,IDF刻画了词语t对整个文档集的重要性。
名词解释和数学算法
TF是词频(Term Frequency)表示词条在文本中出现的频率公式

IDF是逆向文件频率(Inverse Document Frequency)某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力公式

解释分子|D|:语料库中的文件总数分母:包含词语的文件数目(即文件数目)如果该词语不在语料库中,就会导致分母为零
TF-IDF实际上是:TF * IDF某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。公式:TF-IDF=TF*IDF****TF-IDF应用举例
有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“中国”出现了8次,那么“中国””一词在该文件中的词频就是8/100=0.08。一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“中国””一词。所以,如果“中国””一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.08 * 4=0.32
在这个项目中我们定义了一个名为WordSegmentPOSKeywordExtractor的类,它继承了jieba.analyse.tfidf模块中的TFIDF类。该类用于基于TF-IDF算法从给定的句子中提取关键词。
from jieba.analyse.tfidf import TFIDF
class WordSegmentPOSKeywordExtractor(TFIDF):
def extract_sentence(self, sentence, keyword_ratios=None):
"""
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- keyword_ratios: return how many top keywords. `None` for all possible words.
"""
words = self.postokenizer.cut(sentence)
freq = {}
seg_words = []
pos_words = []
for w in words:
wc = w.word
seg_words.append(wc)
pos_words.append(w.flag)
if len(wc.strip()) < 2 or wc.lower() in self.stop_words:
continue
freq[wc] = freq.get(wc, 0.0) + 1.0
if keyword_ratios is not None and keyword_ratios > 0:
total = sum(freq.values())
for k in freq:
freq[k] *= self.idf_freq.get(k, self.median_idf) / total
tags = sorted(freq, key=freq.__getitem__, reverse=True)
top_k = int(keyword_ratios * len(seg_words))
tags = tags[:top_k]
key_words = [int(word in tags) for word in seg_words]
return seg_words, pos_words, key_words
else:
return seg_words
- 关键词提取过程:
- 使用
postokenizer(词性标注分词器)将输入句子划分为单词。 - 遍历单词,过滤掉长度较短的单词和常见的停用词。
- 构建一个频率字典(
freq)以计算每个单词的出现次数。 - 如果指定了
keyword_ratios且大于0,则计算每个单词的TF-IDF分数。 - 根据TF-IDF分数降序排序单词。
- 获取前
keyword_ratios百分比的单词,如果keyword_ratios为None,则获取所有单词。 - 构建二进制表示(
key_words),表示每个单词是否在顶部关键词中。
- 使用
- 返回值:
- 该方法返回三个列表:
seg_words:输入句子中分段的单词列表。pos_words:与每个单词相对应的词性标签列表。key_words:二进制值列表,指示每个单词是否在顶部关键词中。
- 该方法返回三个列表:
三、SnowNLP
SnowNLP是一个基于Python的中文自然语言处理(NLP)库。它可以用于中文文本的分词、词性标注、情感分析、文本分类等任务。SnowNLP基于概率模型和机器学习算法,使用了一些常见的NLP技术,如隐马尔可夫模型、朴素贝叶斯分类器、最大熵模型等。它可以处理简体中文和繁体中文,支持Python 2和Python 3。 SnowNLP在中文文本处理方面表现良好,是一个非常实用的NLP工具。
def search_and_get_comments(keywords):
search_url = 'https://m.ctrip.com/restapi/h5api/globalsearch/search?action=gsonline&source=globalonline&keyword={}&t=1641209789046'
search_url = search_url.format(keywords)
resp = requests.get(search_url, headers=headers)
resp = resp.json()
search_result = resp['data'][0]
spot_name = search_result['word']
poiId = search_result['poiId']
print('poiId:', poiId)
comments = []
for page_i in range(1, 10):
url = "http://you.ctrip.com/destinationsite/TTDSecond/SharedView/AsynCommentView?poiID={}&districtId=702&districtEName=Yangshuo&pagenow={}&order=3.0&star=0.0&tourist=0.0&resourceId=22079&resourcetype=2".format(
poiId, page_i)
html = requests.get(url, headers=headers)
html.encoding = "utf-8"
soup = BeautifulSoup(html.text)
block = soup.find_all(class_="comment_single")
if len(block) == 0:
break
print('page:', page_i, ', current page comments:', len(block))
for j in block:
comment = j.find(class_="heightbox").text.strip()
comment_date = j.find(class_="time_line").text.strip()
# 文本数据清洗
comment = remove_unicode_space(comment)
# 评论关键词抽取
words, _, keywords = extractor.extract_sentence(comment, keyword_ratios=0.4)
comment_keywords = ' '.join([words[i] for i in range(len(keywords)) if keywords[i]])
# 景点评论的情感分析
postive_score = SnowNLP(comment).sentiments
spot_comment_info = [comment, comment_keywords, comment_date, postive_score]
comments.append(spot_comment_info)
return spot_name, comments
上面的代码解析:
- 搜索URL构建:
search_url变量:构建一个搜索URL,其中keywords是传入的参数,用于搜索相关景点信息。这个URL包含了一些参数,如搜索动作、源、关键词等。
- 发起搜索请求:
- 使用
requests.get函数向构建好的搜索URL发送GET请求,并使用headers作为请求头。返回的响应以JSON格式解析。
- 使用
- 解析搜索结果:
- 从JSON响应中提取出搜索结果的相关信息,主要从
resp['data'][0]中获取景点名称(spot_name)和景点ID(poiId)。
- 从JSON响应中提取出搜索结果的相关信息,主要从
- 获取景点评论:
- 通过循环遍历页数,构建不同页数的评论获取URL,发送请求,解析HTML,提取评论信息。
- 评论获取URL包含了参数如
poiID(景点ID)、pagenow(当前页数)等。 - 通过BeautifulSoup解析HTML,提取出评论的块(
block)。
- 处理评论块:
- 循环遍历每个评论块,提取评论内容(
comment)、评论日期(comment_date)等信息。 - 对评论进行文本数据清洗,去除多余的空格。
- 循环遍历每个评论块,提取评论内容(
- 评论关键词抽取:
- 使用提供的
extractor对象中的extract_sentence方法,抽取评论中的关键词。 - 抽取的关键词根据TF-IDF算法得出,通过设定
keyword_ratios参数控制关键词的数量。
- 使用提供的
- 情感分析:
- 使用SnowNLP库对评论进行情感分析,计算评论的积极情感得分(
postive_score),并输出最终训练结果。
- 使用SnowNLP库对评论进行情感分析,计算评论的积极情感得分(
- 保存评论信息:
- 将每条评论的相关信息组织成列表(
spot_comment_info),包括评论内容、评论关键词、评论日期、情感得分。 - 将每条评论信息添加到
comments列表中。
- 将每条评论的相关信息组织成列表(
- 返回结果:
- 返回景点名称(
spot_name)和所有评论信息(comments)的元组。
- 返回景点名称(
四、数据爬虫分析
核心代码:
sheng_list = hot_list.select('dl')
sheng_info = {}
for sheng in sheng_list:
sheng_name = sheng.dt.text.strip() # 省
sheng_name = sheng_name.replace('\n', '')
shi = sheng.dd.select('a') # 市
shi_list = []
for a in shi:
shi_list.append((a.text.strip(), 'http://www.mafengwo.cn' + a['href']))
sheng_info[sheng_name] = shi_list
insert_sql = "INSERT INTO trip(sheng_name, city_name, city_code, url, gaikuang, top_jds, top_xiaochi) VALUES (?,?,?,?,?,?,?);"
city_lvyou_info = []
for sheng in sheng_info:
sheng = sheng.replace('\n', '')
print('--> 抓取 {} 省的城市信息...'.format(sheng))
city_info = sheng_info[sheng]
print(city_info)
for city in city_info:
print('抓取 {} 市信息...'.format(city[0]))
print(city[1])
# Top 景点 http://www.mafengwo.cn/jd/10065/gonglve.html
city_code = city[1].split('/')[-1].split('.')[0]
try:
gaikuang, top_jds = get_top_jd(city_code)
except:
gaikuang, top_jds = '', '{}'
print('空数据')
time.sleep(1)
print(gaikuang)
print(top_jds)
# 城市的热门小吃 http://www.mafengwo.cn/cy/10065/tese.html
try:
top_xiaochi = get_top_xiaochi(city_code)
except:
top_xiaochi = '{}'
print('空数据')
city_lvyou_info.append([
sheng,
city[0], city_code, city[1], gaikuang,
json.dumps(top_jds, ensure_ascii=False),
json.dumps(top_xiaochi, ensure_ascii=False)
])
if len(city_lvyou_info) % 10 == 0:
cursor.executemany(insert_sql, city_lvyou_info)
conn.commit()
time.sleep(1)
代码解析:
- 数据抓取:
- 使用BeautifulSoup库的
select方法选取所有<dl>标签,这些标签包含省份信息。 - 遍历每个省份标签,提取省份名称(
sheng_name)和该省份下的城市信息链接(shi_list)。 shi_list是一个包含元组的列表,每个元组包含城市名称和城市链接。
- 使用BeautifulSoup库的
- 数据库插入操作:
- 使用SQLite语句定义了一个插入数据的SQL语句
insert_sql。 - 创建一个空列表
city_lvyou_info,用于存储待插入数据库的数据。
- 使用SQLite语句定义了一个插入数据的SQL语句
- 城市信息抓取循环:
- 遍历每个省份,对应省份的城市信息存储在
city_info中。 - 对每个城市信息,提取城市名称、城市代码(从链接中提取)、城市链接。
- 调用
get_top_jd函数获取城市概况和热门景点信息,将结果存储在gaikuang和top_jds变量中。如果获取失败,则设置为空字符串和空字典,并打印"空数据"。 - 调用
get_top_xiaochi函数获取城市的热门小吃信息,将结果存储在top_xiaochi变量中。如果获取失败,则设置为空字典,并打印"空数据"。
- 遍历每个省份,对应省份的城市信息存储在
- 数据存储:
- 将获取到的信息以列表形式添加到
city_lvyou_info中。 - 如果
city_lvyou_info中的数据达到10个城市(len(city_lvyou_info) % 10 == 0),则执行批量插入数据库的操作,然后清空city_lvyou_info。 - 在每次插入之后,通过
conn.commit()提交事务,避免数据丢失。 - 使用
time.sleep(1)来防止爬取过快被网站封IP。
- 将获取到的信息以列表形式添加到
通过上面爬取马蜂窝网站上各省市的旅游信息,包括省市名称、城市代码、城市链接、城市概况、热门景点和热门小吃,并将这些信息存储到SQL数据库中。
五、项目架构思维导图
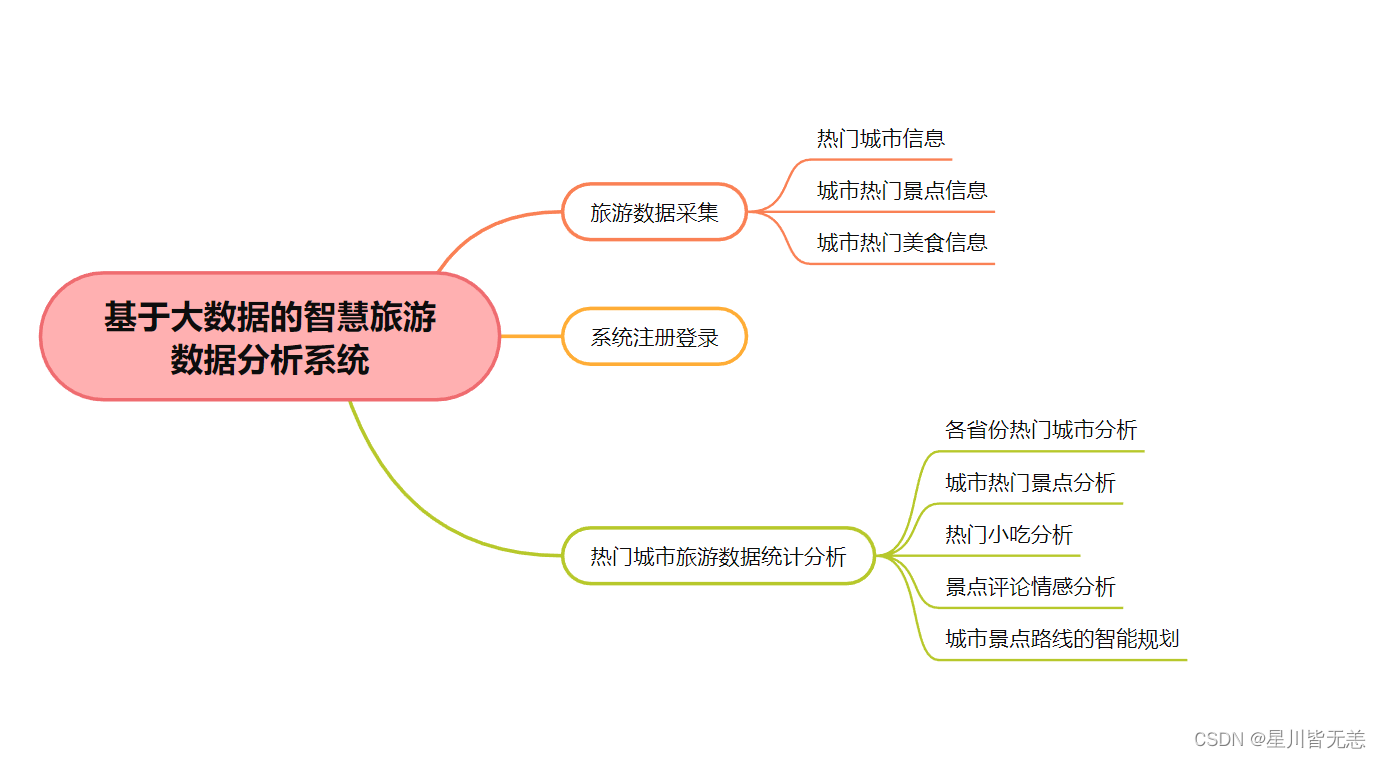
六、项目UI
直接启动我们的Flask框架 端口5000
系统注册登录界面
登陆页面图片选择的是布达拉宫,(我也挺想去的,有机会一定去。)
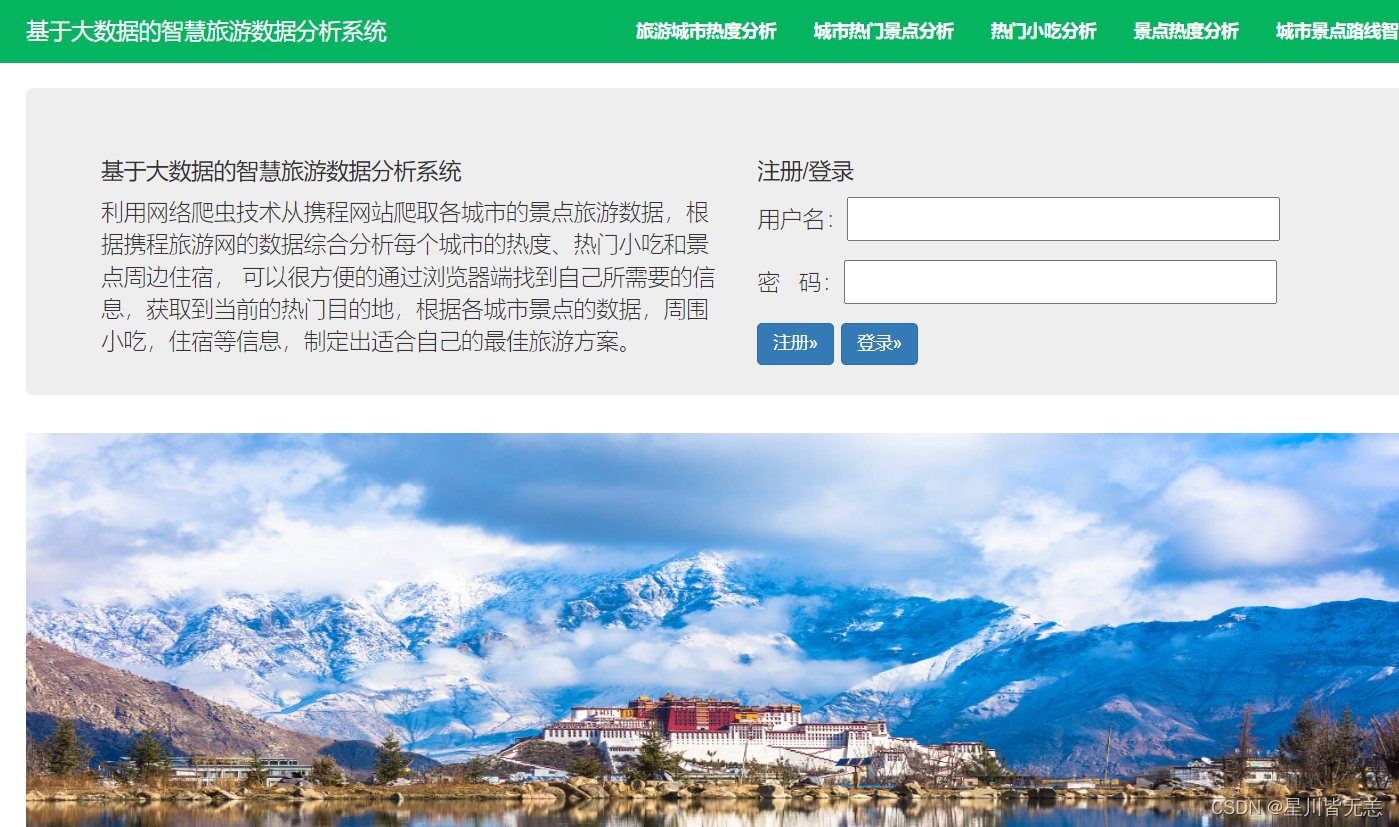
各省份热门城市分析
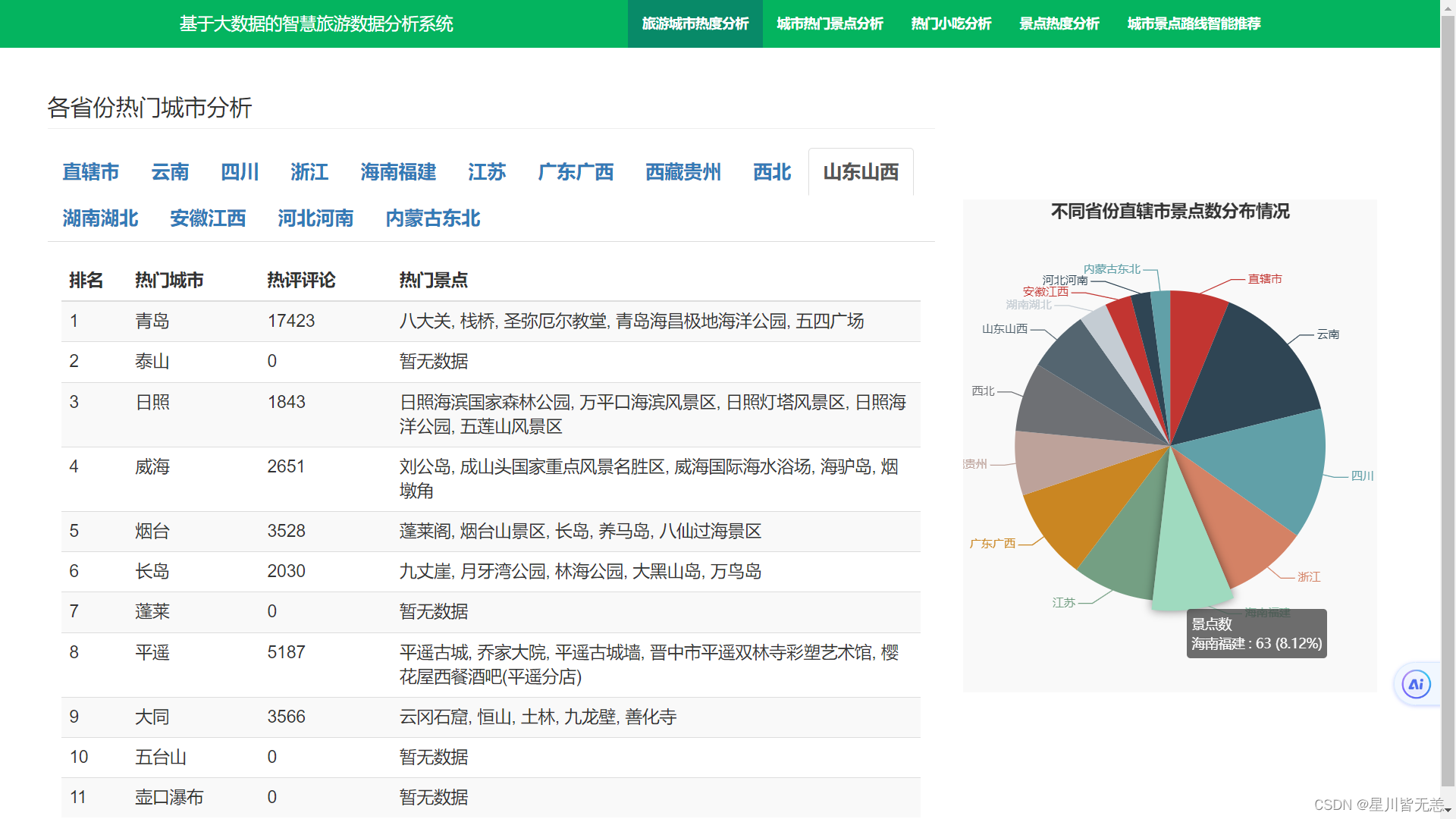
城市热门景点分析
热门小吃分析
控制台信息
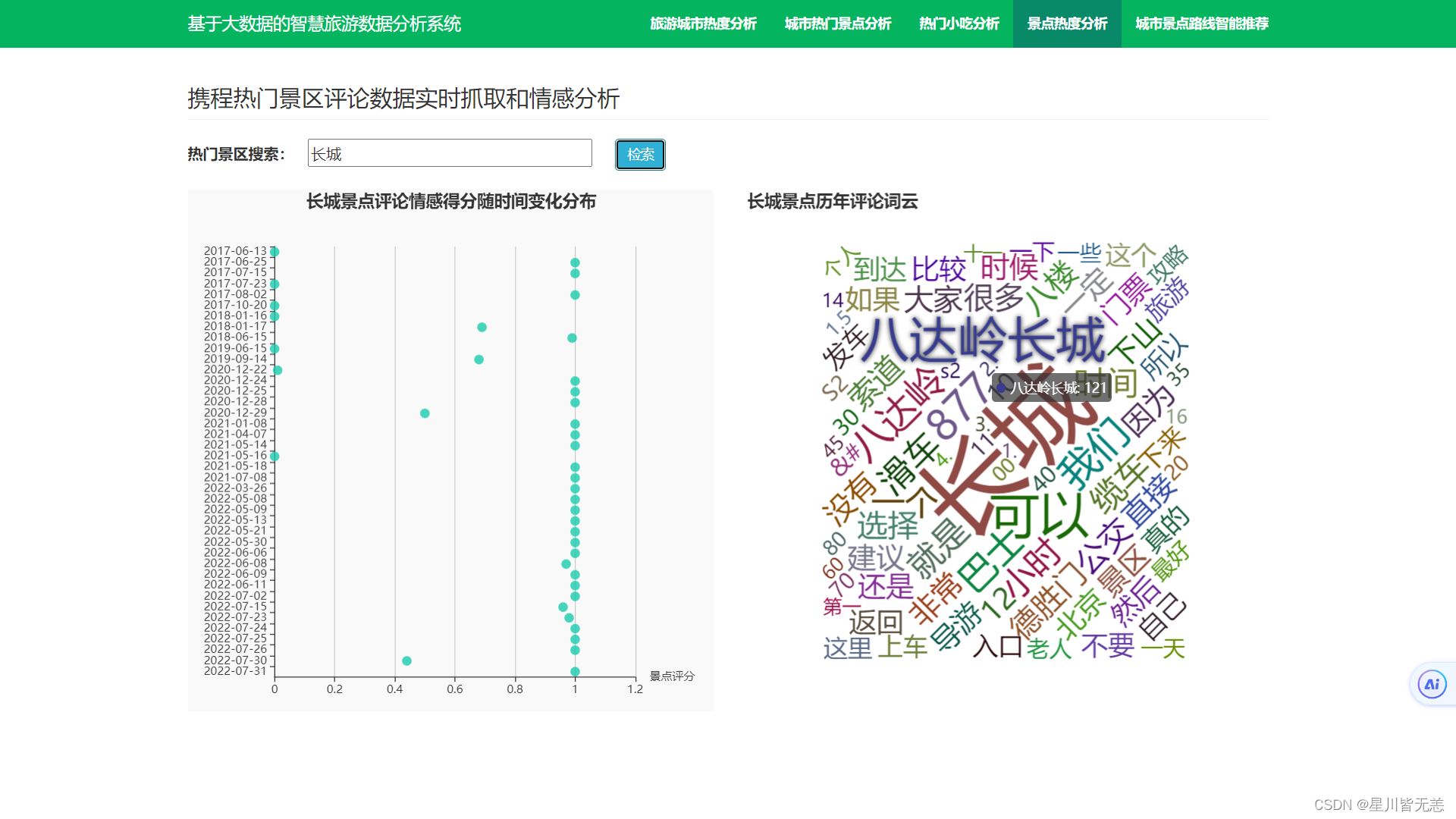
景点评论情感分析
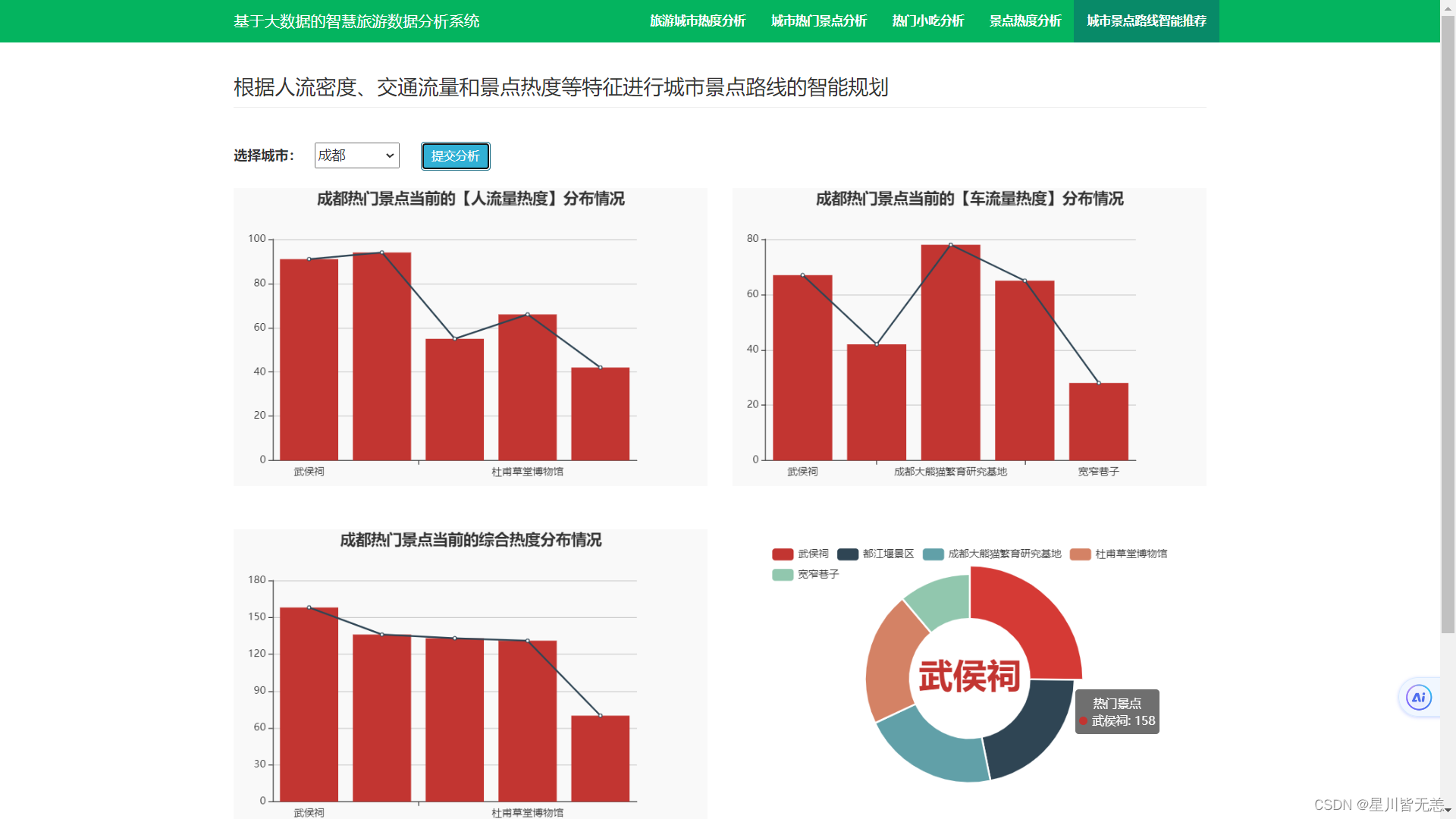
城市景点路线的智能推荐
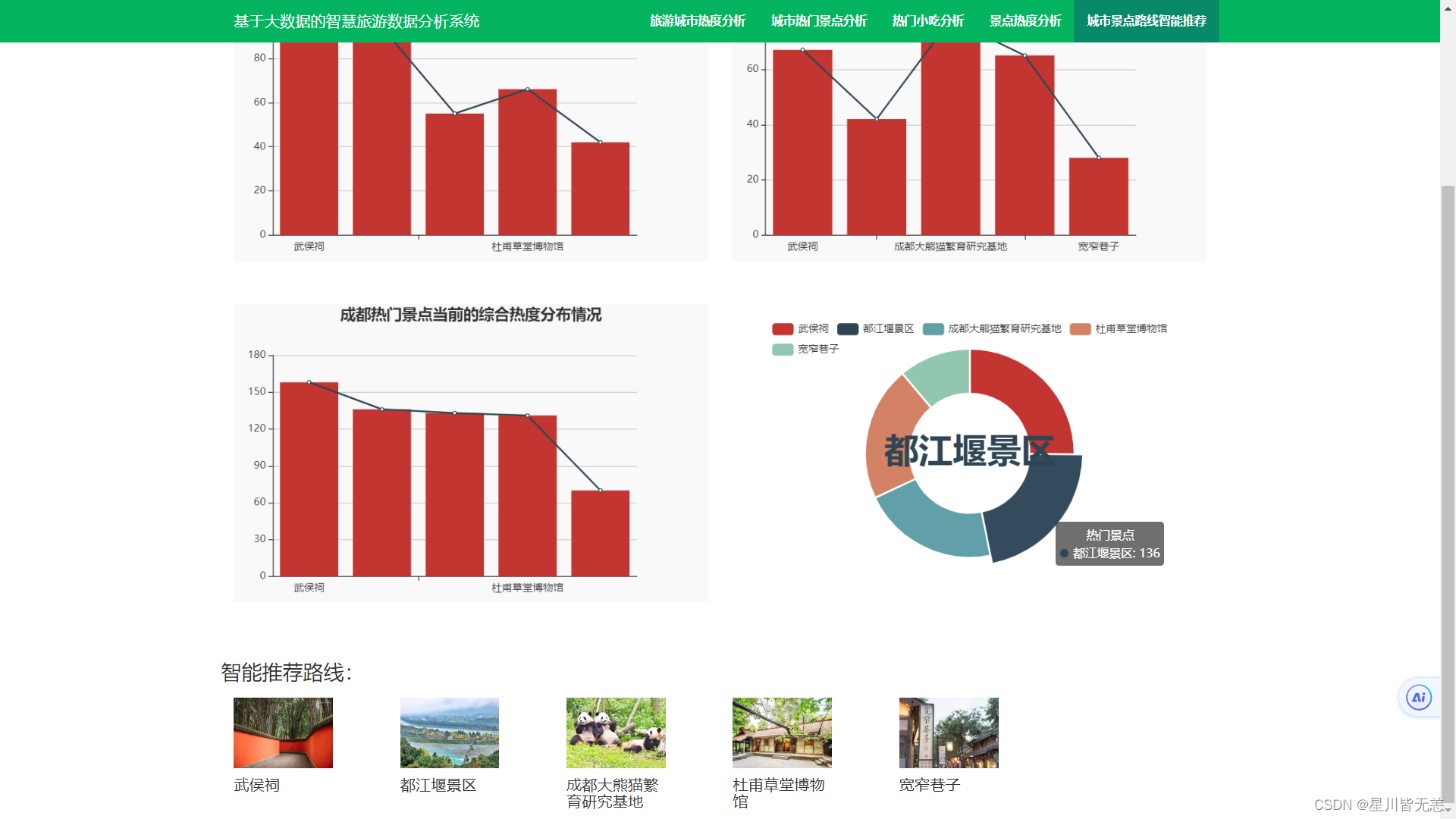
七、项目总结
本项目利用网络爬虫技术从某旅游网站爬取各城市的景点旅游数据,根据旅游网的数据综合分析每个城市的热度、热门小吃和景点周边住宿, 可以很方便的通过浏览器端找到自己所需要的信息,获取到当前的热门目的地,根据各城市景点的数据,周围小吃,住宿等信息,制定出适合自己的最佳旅游方案。通过TF-IDF算法,系统可以分析用户搜索和浏览的行为,从而理解用户的兴趣和偏好。结合SnowNLP进行情感分析,可以更好地了解用户对于景点、餐馆等的喜好。这使得系统能够提供个性化的推荐,增加用户体验,提高用户满意度。SnowNLP的情感分析能够帮助系统理解用户对于景点、餐馆等的感受,从而更好地为用户提供符合其心理期望的旅游建议。这有助于提高用户对于推荐系统的信任度,并增强用户体验。
总的来说,基于TF-IDF算法和SnowNLP大数据的智慧旅游数据分析可视化推荐系统有助于提升用户体验、优化业务流程、推动行业创新,对于旅游业的数字化和智能化转型具有重要意义。