1. 贝叶斯推断
统计推断这件事大家并不陌生,如果有一些采样数据,我们就可以去建立模型,建立模型之后,我们通过对这个模型的分析会得到一些结论,不管我们得到的结论是什么样的结论,我们都可以称之为是某种推断。

对于数据 和未知参数
,频率学派会建立起关于数据的模型
,模型当中会有我们的参数,如果我们把参数看成是确定的未知量。我们就可以用频率学派的观点来进行推断了。此时数据是随机量,参数是确定量,我们用数据来估计参数,也就是构成所谓的统计
,然后用这个统计去对参数进行估计。我们还会有各种各样的关于这个估计好坏的说法,也就是有各种各样的 Metric,这是我们熟悉的频率学派的套路。
贝叶斯推断自然是在贝叶斯框架下展开推断:
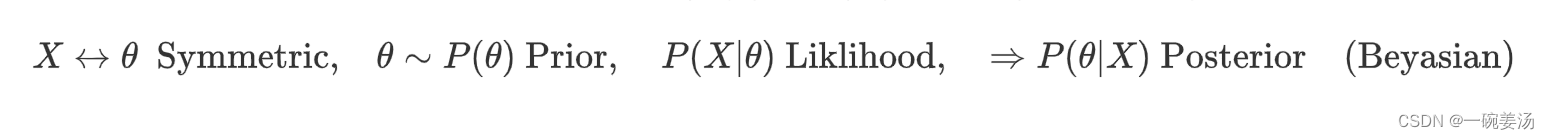
贝叶斯的想法是不一样的,数据和参数之间是对称(Symmetric)的,两者同为随机变量,当我们去考察参数的时候,这个参数会有一个先验分布 ,先验分布你可以说是拍脑袋的,也可以说是天上掉下来的,总之在我们没有获得数据之前,它就有一个先验分布了。然后我们确实也会建立模型
,这一点和频率学派当中所做的事情是完全对应的,而我们想要做的事情,并不是直接在模型上去动手,而是通过先验分布和模型,来做后验分布
。
后验分布如果能被我们掌握,那就意味着我们对于参数的认识就有一点变化:原来我们对参数有一个先验认识,但这个先验认识谈不上科学,因为这个先验认识与我们的实际的生产实践活动、与我们的观测、与我们的数据之间,它没有关系。而有了数据之后,我们必然要对先验认识进行某种更新和迭代,这种更新和迭代融汇了数据当中的信息,这才是科学,因为我们要相信观测、相信事实。而基于数据这一事实,我们所得到的关于参数的分布,那才是比较合理有效的对于参数的认知,这个认知是贝叶斯推断的核心。也就是说,当我们有了后验分布以后,我们就能够通过后验分布对我们的参数进行各种各样的推断与决策。
这里有一个有趣的事情:如果你从频率学派的观点看,参数是一个确定的未知量,你可以形成各种各样对参数的估计,就好像解方程,我们有未知数,我们通过数据建立了模型之后我们就来解这个未知数,这就显得很自然。贝叶斯呢,得出了后验分布,你说你对参数的认识究竟是进步了,还是退步了呢?这事很难说,原因在哪?原因在于,我们这里所拿到的是一个参数的分布。分布这件事情我们都不习惯,说实话,因为概率统计上的事情大家都认为是比较困难的,因此大家都是能绕就绕,能躲就躲。现在如果我们现在拿到的仅仅是个分布的话,似乎就有点老虎吃天,无从下爪,因此从分布这个角度入手,我们需要有新的观点, 乃至于新的方法。
于是我们有基于仿真(Simulation)的办法,仿真方法它的基本思路是很清晰的:就是要产生出一系列的伪随机样本,既然这个分布(后验分布)我们通过贝叶斯公式已经得到了,我们就产生出关于这个分布的一系列的伪随机样本,它在数量上没有任何的限制,想生成多少就生成多少。而基于这些伪随机样本,我们就可以做很多事情了,比如我们要想估计后验均值就很简单,只需要算一个算术平均值来估计它就可以了:
你甚至还可以做直方图来看一看这个后验分布到底长什么样子。不用担心因为数据量太小,导致直方图做出来很粗糙。所以仿真的方法真的是一个好方法。关于仿真(MCMC)我会在另一篇文章详细展开,这篇文章介绍另一种跟仿真并重的方法:基于近似(Approximate)的方法。
2. 变分贝叶斯(Variation Bayes)
变分方法跟仿真方法都是为了对付复杂的后验分布而产生的。因为后验分布的复杂程度往往很高,往往是多元的,这很难用简单的随机数发生器把他给产生出来,MCMC实际上是相当复杂的随机数发生器,因为你首先要构造这个马氏链,然后你得 run 这个马氏链,然后你还得确保这个马氏链 run 到了马氏链的稳态里面去,然后你的采样才能有效地获取。这样不仅消耗的算力巨大,而且 online 的计算很难,一般都是 offline,所以你不能对它的实时性有太高的期待。那么如果我们不愿意去面对这样的复杂性,我们就可以去尝试使用这种近似的手段去处理。当然,在面对这样的复杂性的时候,还有另外的一种处理手段,就是分析其中的分布结构,然后有效地利用这个分布结构来为我服务,这就是贝叶斯网络(Beyasian Network)干的事情:利用网络来刻画分布结构。
变分贝叶斯是这么一个思想:我先找到一个已知的分布 ,就跟找MCMC的那个Proposal矩阵的思想一样。这个已知分布
比较容易,各种性质都很好算。然后我们用这个
通过某种方式来近似后验分布。
其实大家可以设身处地地想一想,如果是你,你能不能产生出这样的想法,如果不能,究竟是思维上的哪一块受到了限制,还是哪一部分意识受到了限制,因为这个想法说出来大家都觉得很自然。但是近似这件事,是我们中国学生普遍的盲点,是因为我们长期应试,我们习惯于任何一个问题都有精确答案,太习惯了,只要那个答案不是2,我得出2.01、2.001都是Nonsense没有任何意义的,我的分就被扣光了。而实际上,在科学里,尤其是在工程上,如果这个值为2,你能得出2.001这多数情况就OK了。当然你说有误差限,没问题,你把误差限、工程里的要求说出来,然后我的目标并不在于说去找到2那么一个准确的值,只要我能通过某种方法,能够让我们的答案与2之间的那个差小于你的误差限,这个就已经是满分了。
我如果想用g来近似我的后验分布,我首先要解决一个什么问题?首先要解决一个 距离Metric 的问题。没有距离,也就根本谈不上近似。
我们在这里只选一种距离:Kullback-Leibler distance / divergence(KL距离 / 散度)
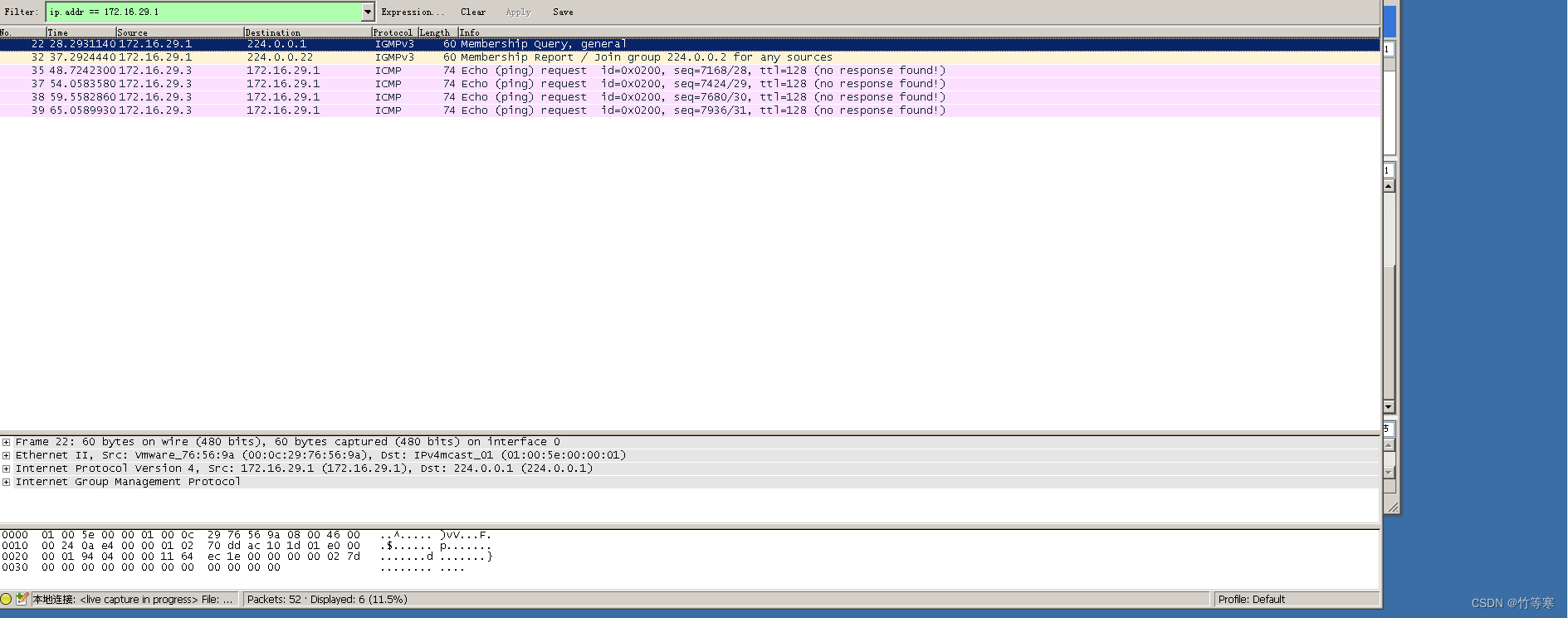
Kullback-Leibler理论上来讲只是一种伪距离,不是真正意义上的距离。因为距离的三个条件:
KL散度只有第一条是OK的,其余两条都不满足。不过即便如此,这个距离人们也用的最多,因为它比较容易算。
变分是一种以函数为自变量的优化
这里我们提供变分的两种路径,第一种方法叫做 均场(Mean Field Approch)
2.1. 均场假定(Mean Field Assumption)
我们对g有一种先验的结构添加。这种先验的结构反映了我们希望能够用尽可能简单的方法来完成我们的变分/近似。
假设θ能写成两个部分 ,g(θ)也能分拆成两个部分
。这其实是在做分离变量(Seperated Variable)。这对我们有什么好处呢?我们来看一下:
- 第一项:
使用分离参数的原因就在于: 维度太高,我们企图把它简单化,把它分离成更小的一部分一部分,然后在这些分离后的变量上进行轮转。把这个优化从高维简化成低维,我们在优化的时候其实经常这么做:我不想在高维空间里直接做搜索,所以我先固定住一些维度,转而优化某一维,优化完了这一维之后我再把这一维固定住,再去优化另外一维,如此反过来倒过去。这么干虽然不能够保证它一定可以找到最优的。但是我们反正已经开始近似了,就不用有啥心理压力(反正目标不是那100分,也许及格就够了)。
- 第二项:
里头那个积分 ,其中,
被认为是已经被我们掌握的结构,所以复杂的根源来自于
,但是我们发现它的前面有一个
,一般来讲(虽然算不上定律,但这是一般性的规律)分布加个log就简单多了。因为多数情况下,我们处理的分布都是指数族,就跟高斯一样,指数上方可能是一次项、二次项,总之指数族一旦一log就简单多了,所以这是在一个变简单的函数上来用已知分布进行期望。
于是乎,加上了分离参数的结构,KL散度就可以写成这么个模样
现在这个优化就很好做了,只需令 ,然后
即可。这样g1就被优化过了。然后下一步把g1固定住,然后再去优化g2,如此循环往复。这种方法虽然不是 Universal 的,但是有很多实际情况很好算,这就给我们的工具箱里增加了一项工具。
解释一下什么是均场假定。物理学当中,如果我们有一个多元复杂函数,假如我能把它写成分离变量的形式
我们就把这玩意叫做均场假定(Mean Field Assumption)。什么叫均?就是各个变量之间是对等的,事实上这么一写,对称性就出来了。所以均场意义下的变分就是:固定住,先优化
,优化完了再来做
的优化,并且固定住除了
以外的
,以此类推。
文献里头用这么一个符号“” 来表示除了
以外的
:
2.2. 梯度方法(Gradient Approach)
均场假定的方法其实并没有对 的具体分布做出界定,也就是非参数化的结构。
而梯度方法则希望 是参数化的这么一种结构,即分布的具体类型已知,不知道的仅仅是参数本身。
从非参数到参数,这是一个重大的变化。对于参数化结构,我们去优化g的范围,是用另一种方式去缩小的,即变分实际上是变成了一个普通的优化
于是我们重新回到了梯度这个感觉上来,基于 λ 来做KL散度的求导
因为此时 g 的形式已经给定了,所以我们只需要考虑 λ 就行了。
下面我们就可以来做求导
人们有一个理念:就是你一log,这件事情就会变得简单。做到这里,大概就差不多了,形式上也都变简单了,这个就是梯度的一个Approach。
这就是我们的变分推断。summary一下,变分推断是一种近似推断,因为我们并不是直接用后验分布去推断,后验分布是我们的目标,但是这个目标往往难以达成,因此我们才使用近似,这个近似应该有两个条件:第一,他应该比较容易算、比较容易对付、比较容易分析、比较容易处理。第二,他应该在第一个条件满足的前提下,尽可能地去靠近我的后验分布。这个靠近的过程,我们叫作变分。
3. 贝叶斯网络
从推断这个角度来讲,贝叶斯的含义还远不止于此。应当说远不止我们所 focus 的后验分布那一点东西,其实贝叶斯包含有我们整个的逻辑推断的全部知识。比方说我们都熟悉三段论:
证明:
可以看到,我们是可以通过概率语言来算这个逻辑三段论的。这其中起着关键性作用的就是这个贝叶斯的思想。
下面再举一个例子:我们知道原命题和逆否命题是同对错的:
证明:
所以可以这么说,逻辑推断是概率推断的一个子集。逻辑推断非1即0,而概率推断要比它做的更精美,因为概率推断未必非1即0,中间如果有那种似是而非、如果有那种不确定性,我们同样是可以推断的。
下面我们来说用概率推断可以来解决什么问题?
假如有两个人,一个叫A,一个叫B。这是一个非常经典的例子,举这个例子的人得了图灵奖了。这个人叫Pearl。这个人因为发明了贝叶斯网络方法而得了2011年的图灵奖。2012年深度学习就横空出世了。所以说在深度学习之前,机器学习的最高成就就是这个贝叶斯网络。贝叶斯网络相比于深度学习还是有一些优势的,当然劣势也很多。深度学习最大的问题是可解释性不强,贝叶斯网络是可以完美地用现有知识做出解释的。而且他还具备某种智能。
我们现在看看Pearl的例子,了解贝叶斯网络在干什么。
A,B这两个人各有一个花园,一大早A发现花园湿了,A的花园有喷水装置S,所以有可能是喷水装置喷过水导致花园湿了,也有可能是昨天晚上下过雨R,导致今天地上湿了。而B这个人的花园没有喷水装置,如果昨天下雨了,也会导致B的花园湿了。假如花园湿了,我们现在要反过来推断,看这个花园究竟是喷水装置自己莫名其妙喷水,还是下雨了。
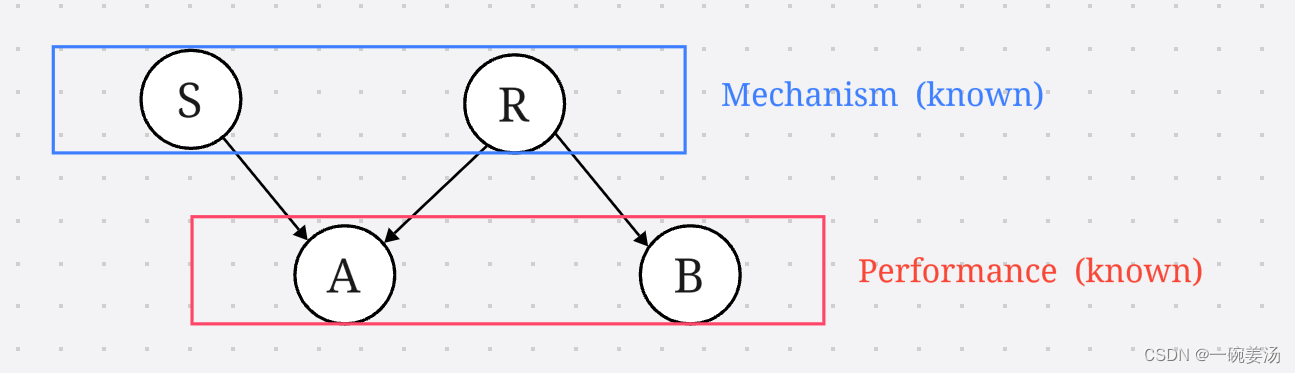
这是一个有向无环图(Directed Acycle Graph - DAG)。这个图一旦做出来了,从机理(Mechanism)到表象(Performance)这个推理过程就是透明的。我们现在想要反过去。你一想这个东西就是贝叶斯的特点:因为从参数(Machanism)到数据(Performance)这个就是似然,你现在要推这个后验,到底是由哪个参数转化而来的。
当然这个图想要纳入概率计算的范畴,还需要做一个概率上的转化。
为什么能这样写,是因为如果两个事件不独立,一定能找到一个有向路径,从一个到另一个。
把网络图转化成概率计算来表征我们机理与表象之间的链接关系,这一点是Pearl核心的一个创造。这样的好处就在于我们可以在非常之观的网络层面更方便地构建模型,再通过Pearl给出的转化方法转化到非常严密的概率分布层面上来计算。
这就是在寻求分布的内部结构。因为我们觉得这个分布一定是有结构的,因为它一定是有先验知识的。先验知识怎么能够融汇到你的结构里来。这一步做的太漂亮了。直到今天人们认为深度学习纯端到端的这样的做法在这一点上都是比不了pearl的。深度学习是没法用先验知识的。最典型的,你没法给神经网络提示。你输入一只猫的图片,它给你输出结果是猫,中间你没法给任何提示,比如你要注意它的胡子,因为猫跟狗的一大区别就是胡子。这样的 Hint 你给不进去。而在 Pearl 的体系里你就给进去了,因为猫的特殊性会反映在这个条件概率结构里。所以直到今天,对于贝叶斯网络还是非常尊崇的。这玩意真的是好东西。
我们现在来做这件事:
再来算这个:
我们发现如果B的地湿了,那么一定是下雨了。

如果B家里有个熊孩子,爱往地上洒水,那么B又多了一个不确定因素,如果导致
则根据上面的式子计算一定得出:
即B湿了,并不能给A湿了的原因给出任何帮助。
这就是我们的贝叶斯网络。贝叶斯网络不是一个近似推断,他是直接对后验分布进行推断。或者说直接对多元分布进行推断。但是贝叶斯网络仍然有先验的结构进来,这个先验的结构来源于我们的知识,而且他把知识可以用非常直观的方式 encoding 进来,再通过一个转换,转换成概率结构,然后剩下的我们就是反复地在积分/求和。积分的时候你还可以有效地利用这个先验结构。