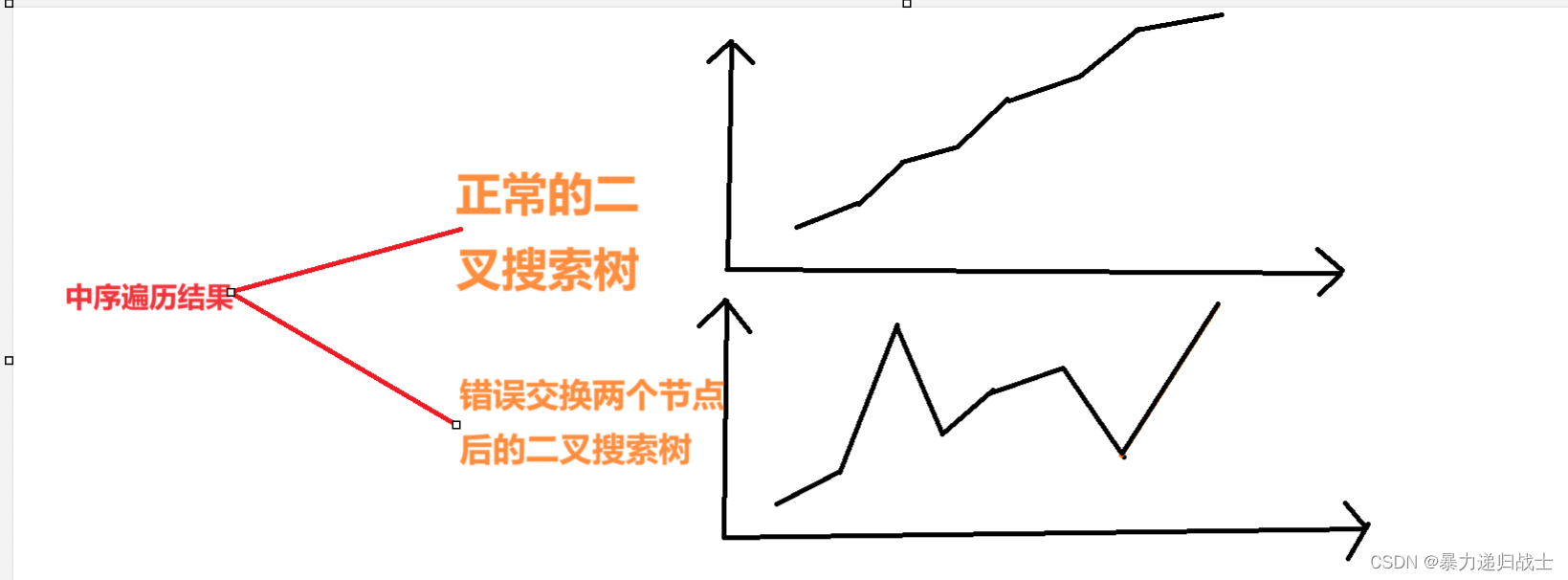
k近邻算法是一个很容易理解的算法,构建模型只需要保存训练数据集。要对一个新的数据点做出预测,算法会在训练集中寻找与这个新数据点距离最近的数据点,然后将找到的数据点的标签赋值给这个新数据点。
l近邻算法中k的含义是:我们可以考虑训练集中与新数据点最近的任意k个邻居,而不是只考虑最近的一个。
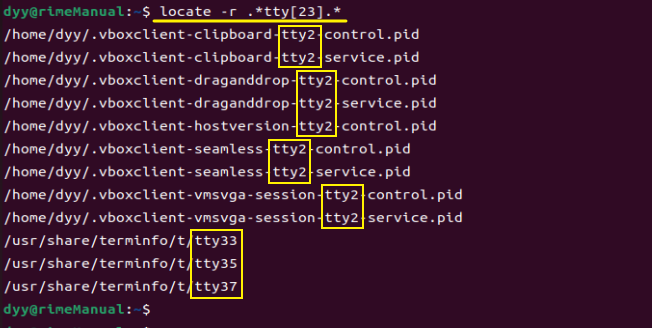
scikit-learn中算有的机器学习模型都在各自的类中实现,被称为Estimator类。k近邻算法就是在neighbors模块中的KNeighborsClassifier类,使用它需要设置模型的参数,KNeighborsClassifier最重要的参数就是邻居的数据,先设置1看下结果。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_dataset=load_iris()
X_train,X_test,y_train,y_test=train_test_split(
iris_dataset['data'],iris_dataset['target'],random_state=0
)
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto',leaf_size=30,metric='minkowski',metric_params=None,n_jobs=1,n_neighbors=1,p=2,weights='uniform')
X_new=np.array([[5,2.9,1,0.2]])
print('X_new:{}'.format(X_new.shape))
prediction=knn.predict(X_new)
print('prediction:{}'.format(prediction))
print('prediction 种类:{}'.format(iris_dataset['target_names'][prediction]))
输出:

根据输出结果可以看到,模型根据输入的结果判断,类别为0,也就是‘setosa’品种