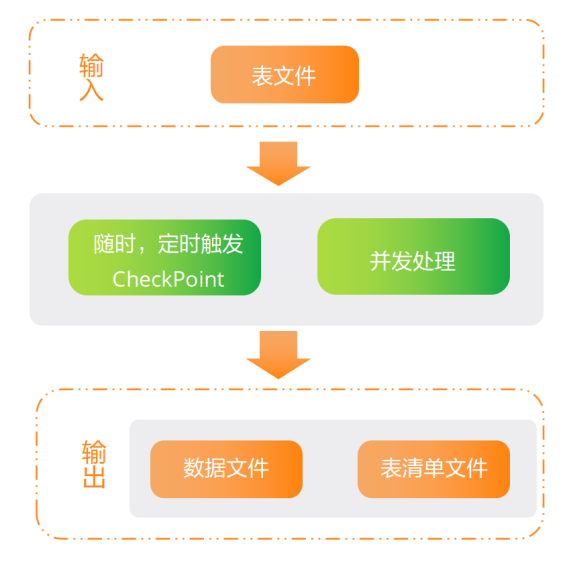
模式识别与机器学习-半监督学习
- 半监督学习
- 半监督学习的三个假设
- 半监督学习算法
- 自学习算法
- 自学习的步骤:
- 自学习的优缺点:
- 优点:
- 缺点:
- 协同训练
- 多视角学习
- 生成模型
- 半监督SVM
谨以此博客作为复习期间的记录
半监督学习
半监督学习(Semi-Supervised Learning)是机器学习的一种范式,它利用同时包含标记(有标签)和未标记(无标签)数据的数据集来进行模型训练。相比于监督学习和无监督学习,半监督学习尝试结合已标记数据和未标记数据来提高模型的性能和泛化能力。
在半监督学习中,通常只有少部分数据被手动标记了标签,而大部分数据没有标签。其主要思想是利用未标记数据的潜在分布和结构,辅助模型在训练过程中更好地捕获数据的特征和规律。
半监督学习的常见方法和技术包括:
-
自训练(Self-training): 通过使用已标记数据训练初始模型,然后使用该模型对未标记数据进行预测,并将置信度高的预测结果添加到已标记数据中,反复迭代训练。
-
半监督支持向量机(Semi-Supervised Support Vector Machines): 在支持向量机中,通过在优化目标函数中添加未标记数据的信息,以利用未标记数据的特征。
-
图半监督学习(Graph-based Semi-Supervised Learning): 基于图的方法,利用数据之间的关系构建图模型,并通过图的传播或标签传递等方法来利用未标记数据。
-
生成式模型: 一些生成模型,如生成对抗网络(GANs)和变分自编码器(VAEs),也可以结合有监督和无监督信号来进行半监督学习。
半监督学习的优点和适用场景包括:
-
利用未标记数据: 能够利用未标记数据提供的额外信息,提高模型性能和泛化能力。
-
节省人力成本: 减少手动标记数据的成本,尤其在某些领域标记数据可能很昂贵或耗时。
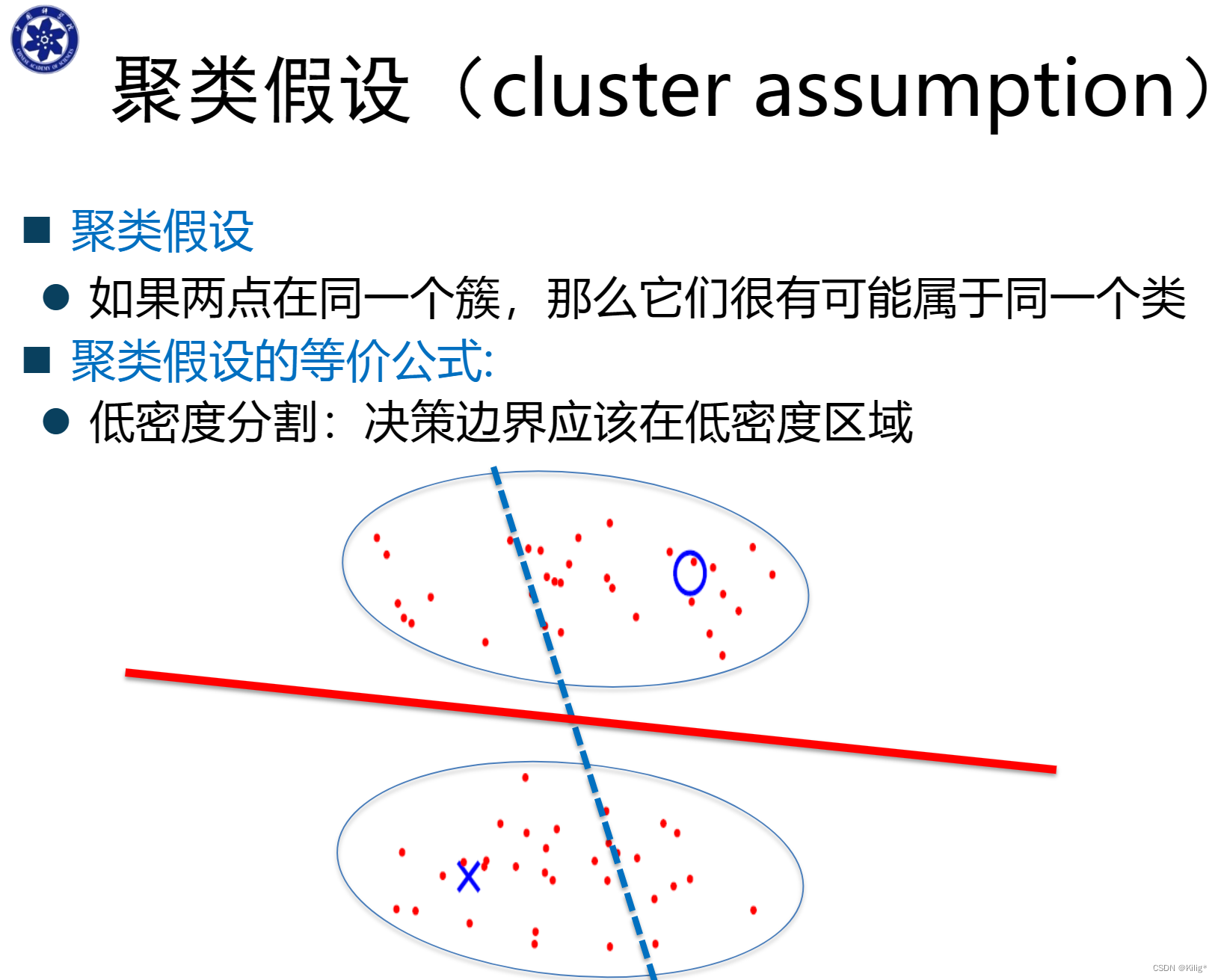
半监督学习的三个假设

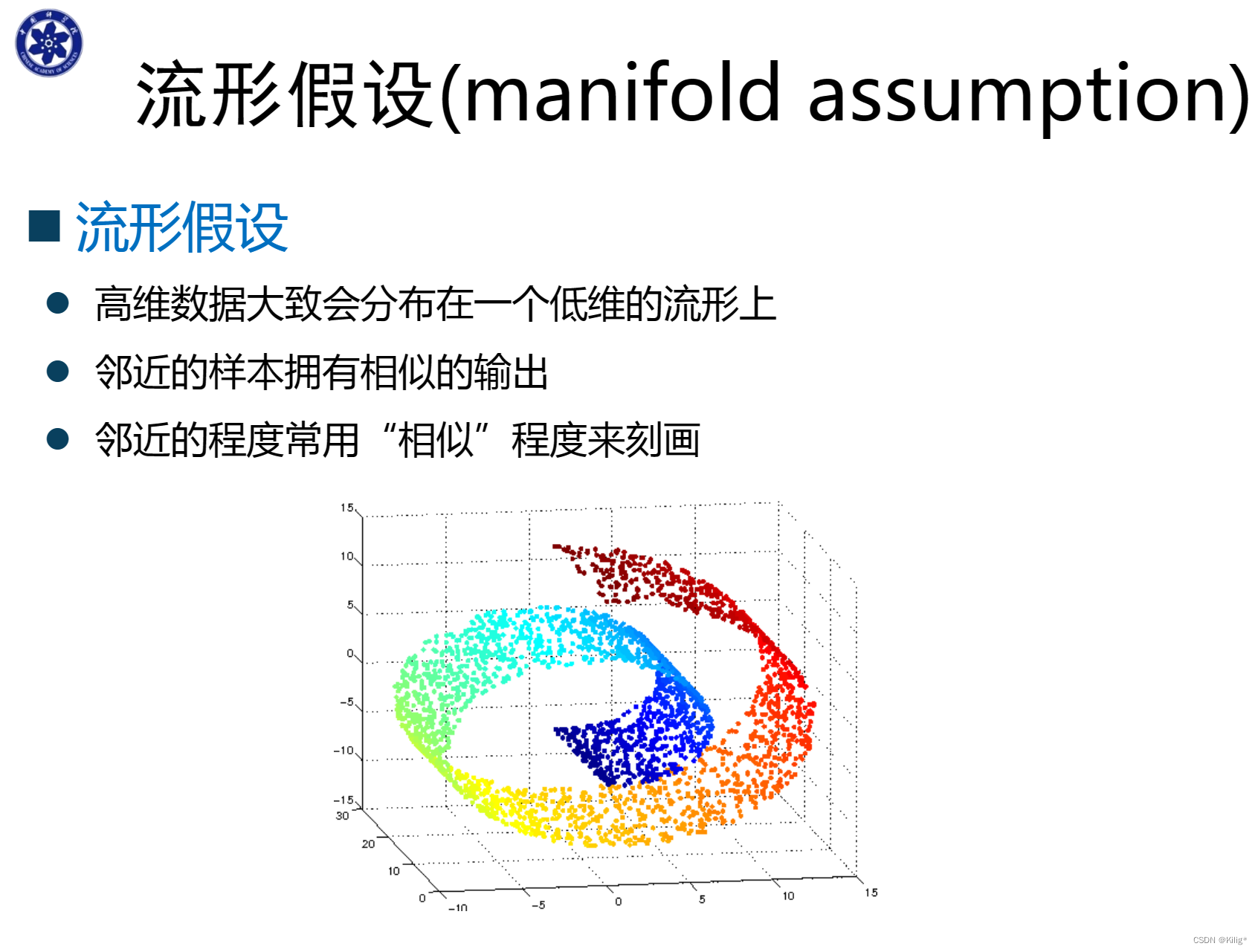
半监督学习算法
自学习算法
自学习(Self-training)是半监督学习中的一种常见方法,其核心思想是通过已标记数据训练一个初始模型,然后利用这个模型对未标记数据进行预测,并将高置信度的预测结果加入到已标记数据中,然后重新训练模型。这个过程会反复迭代进行,直至模型收敛或达到停止条件。
自学习的步骤:
-
初始化模型: 使用少量的有标签数据训练一个初始模型。
-
预测未标记数据: 利用这个初始模型对未标记数据进行预测,得到它们的预测标签。
-
置信度筛选: 选取置信度较高的预测标签,并将这些样本标记为新的有标签数据。
-
模型更新: 将新标记的数据加入到已标记数据中,重新训练模型。
-
迭代训练: 重复以上步骤,直到满足停止条件(如达到最大迭代次数、模型收敛等)。
自学习的优缺点:
优点:
-
充分利用未标记数据: 利用了未标记数据的信息,可以增加模型的训练样本量,提高模型的性能和泛化能力。
-
简单易实现: 自学习算法相对简单,并且易于实现。
缺点:
-
标签传播风险: 自学习可能将预测错误的标签加入到已标记数据中,会带入噪声和错误信息,导致模型性能下降。
-
标签偏向性: 初始标签偏差会在迭代中逐步放大,可能导致模型偏向于初始标签。
-
忽略数据不确定性: 忽略了模型对于预测的不确定性,可能导致未标记数据预测的不准确性。
在实际应用中,自学习算法可以在数据标记成本较高或标记数据较少的情况下起到一定的作用,但需要小心处理预测置信度和不确定性,以及监督信息的传播风险。
协同训练
和最近大火的多模态有点相似。
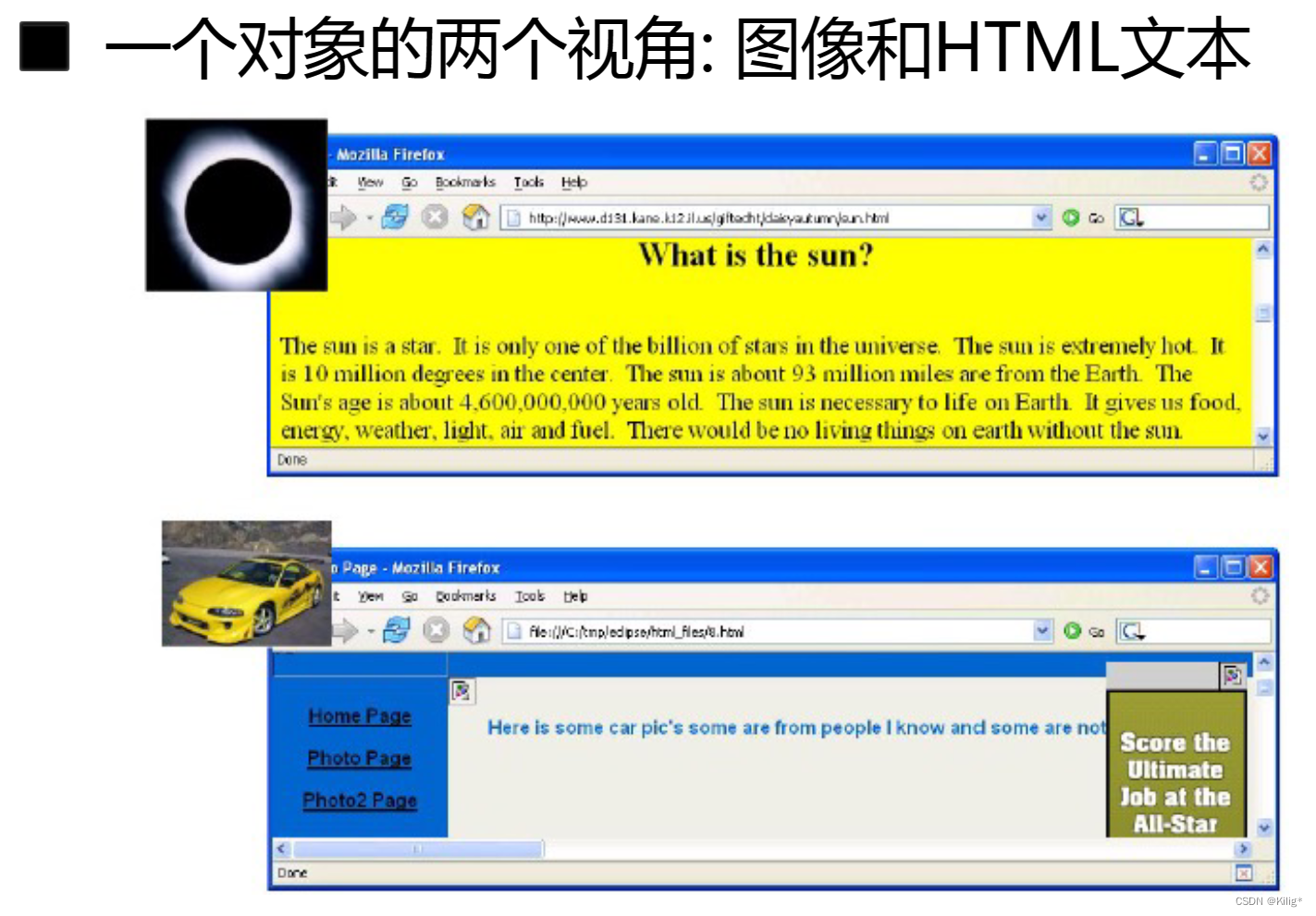


多视角学习
多视角学习(Multi-view Learning)是一种利用多个视角或多个数据来源进行学习的方法,旨在提高模型的鲁棒性和泛化能力。这些不同视角可以是来自不同传感器、不同特征提取方式或不同数据来源等。

生成模型
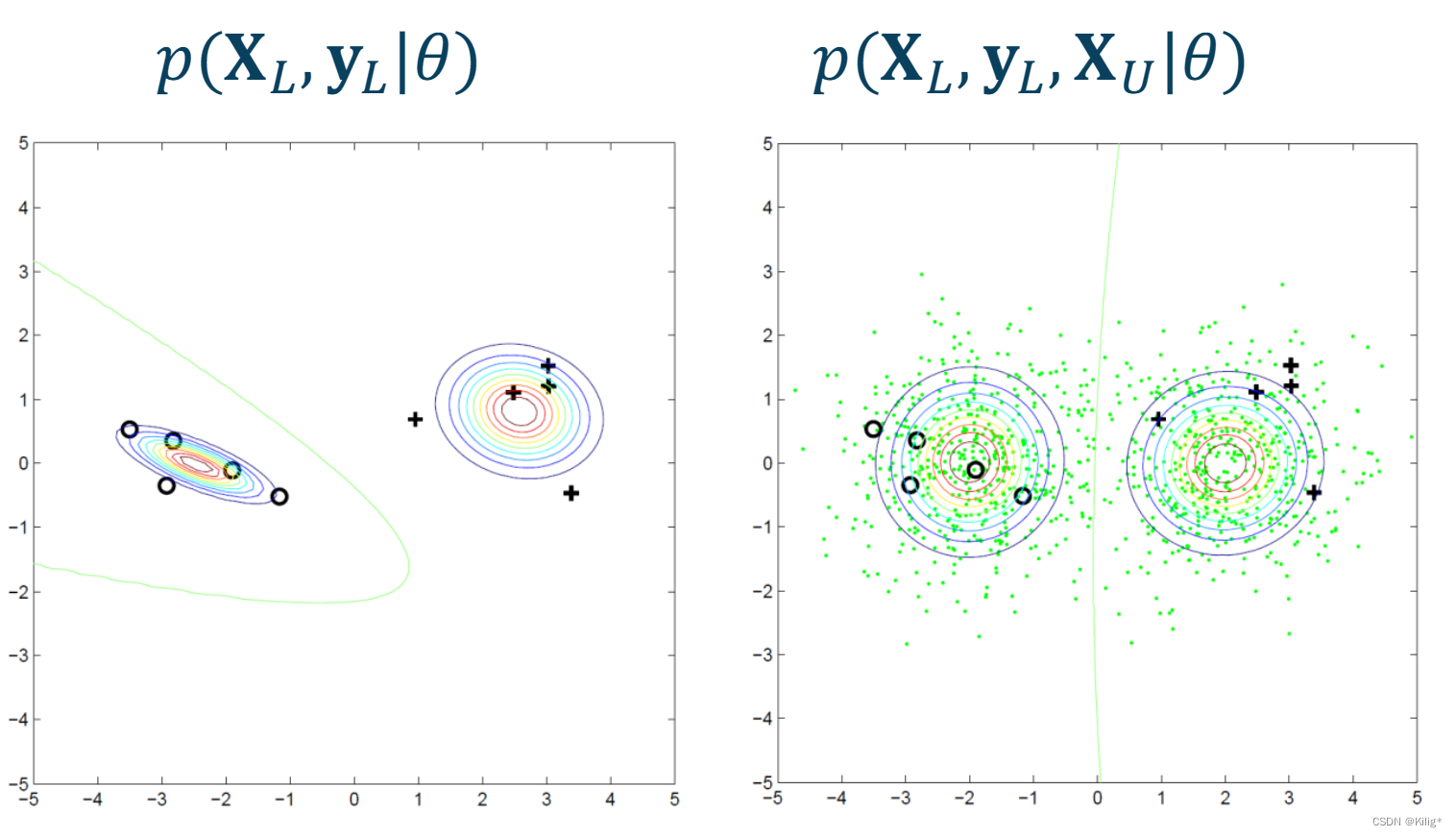
在传统机器学习任务中,生成模型(如高斯混合模型 GMM)通常只利用有标签的样本数据,通过对有标签样本的联合概率进行建模和估计。其目标是最大化有标签样本的似然概率或联合概率,以学习数据的分布和模式。
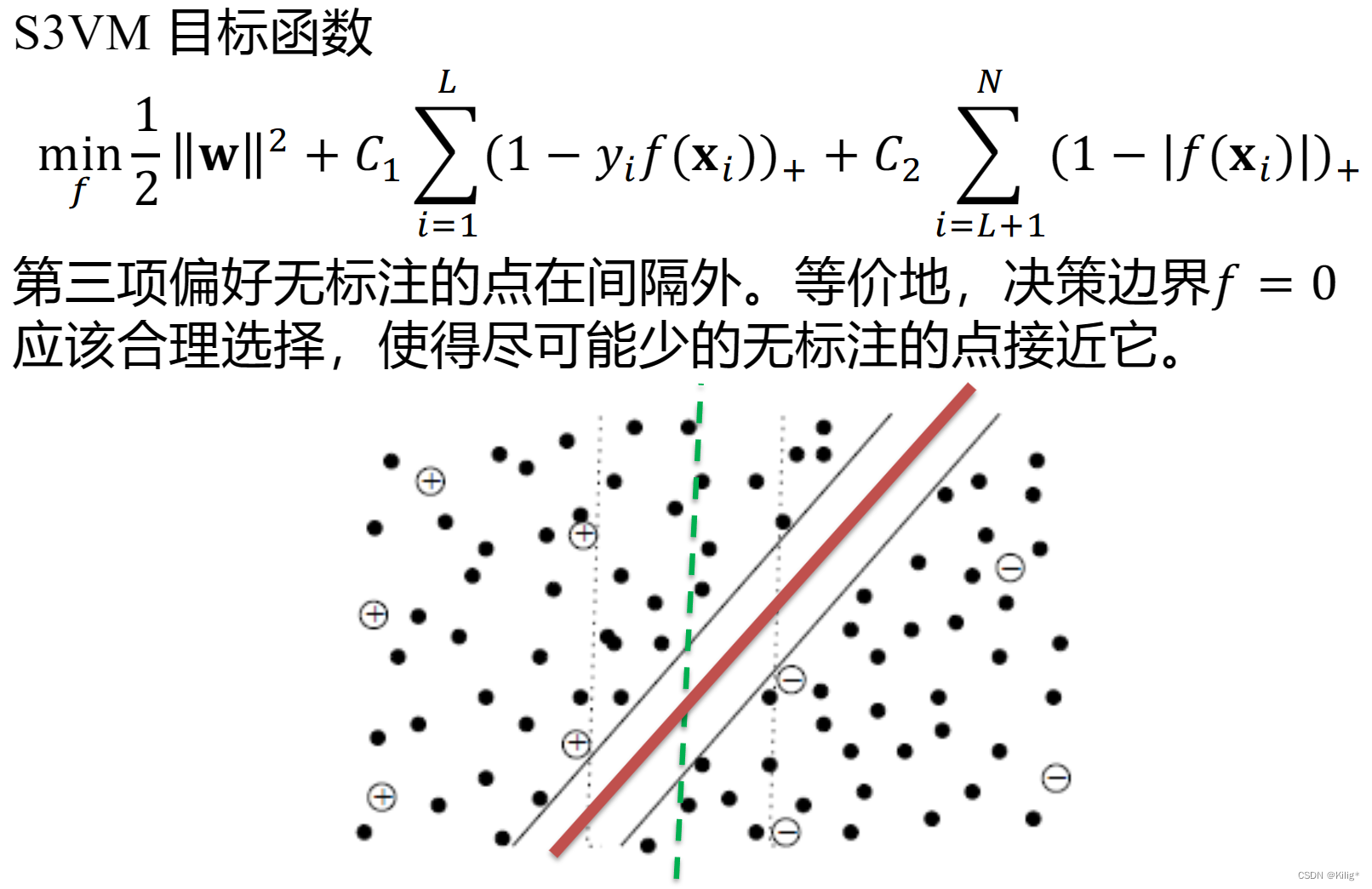
然而,在半监督学习中,除了利用有标签样本的信息,还可以充分利用未标记数据的信息来提高模型的性能和泛化能力。半监督学习中的生成模型通常通过结合有标签数据和未标记数据来进行建模。学习目标可以最大化有标签样本和无标签样本的似然概率或联合概率,如下图所示。
由于学习目标的不同,生成的决策边界也有所不同,黑色的点是有标注样本,蓝色的点是无标注训练数据。结合了无标注训练数据生成的概率分布要更加贴合数据情况。



半监督SVM
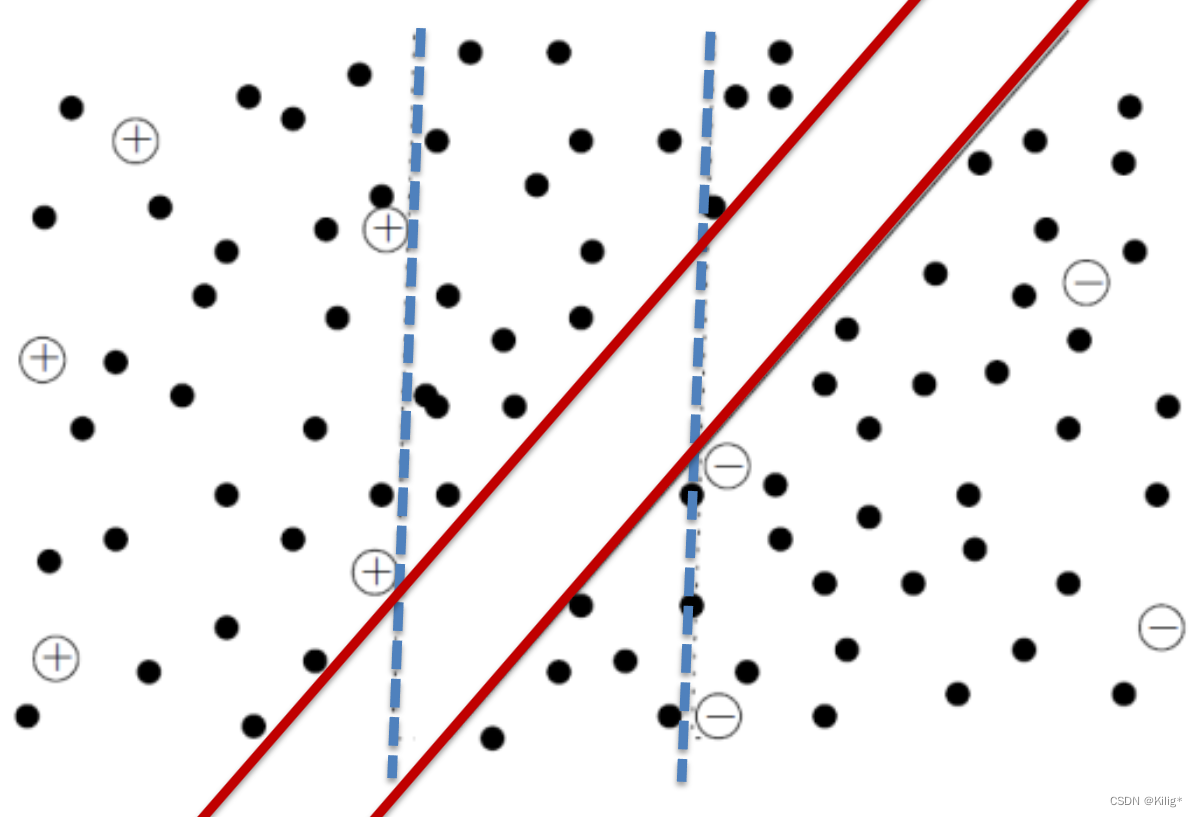
半监督支持向量机(Semi-Supervised Support Vector Machines,S3VM)是支持向量机(SVM)的一种扩展形式,用于半监督学习问题。S3VM结合了有标签数据和未标签数据,旨在提高模型的泛化能力和性能。
通常,标准的支持向量机(SVM)只使用有标签的数据进行训练,但在半监督学习中,S3VM允许利用未标记数据来辅助训练模型,以改善模型的泛化能力。S3VM尝试找到一个最优的超平面或决策边界,同时考虑有标签数据和未标记数据。其核心思想是最大化所有数据的间隔,而不仅仅是有标注数据的间隔。下图蓝色虚线是只使用有标注数据训练得出的分割间隔,红色实线是结合无标注数据得到的间隔。