一、k8s应用自动扩缩容概述
1)背景:
在实际的业务场景中,我们经常会遇到某个服务需要扩容的场景(例如:测试对服务压测、电商平台秒杀、大促活动、或由于资源紧张、工作负载降低等都需要对服务实例数进行扩缩容操作)。
2)扩缩容分类
对象分类
• node扩缩容
• 在使用 kubernetes 集群经常问到的一个问题是,我应该保持多大的节点规模来满足应用需求呢?cluster-autoscaler 的出现解决了这个问题, 可以通过 cluster-autoscaler 实现节点级别的动态添加与删除,动态调整容器资源池,应对峰值流量。
• pod层面
• 我们一般会使用 Deployment 中的 replicas 参数,设置多个副本集来保证服务的高可用,但是这是一个固定的值,比如我们设置 10 个副本,就会启 10 个 pod 同时 running 来提供服务。如果这个服务平时流量很少的时候,也是 10 个 pod 同时在 running,而流量突然暴增时,有可能出现 10 个 pod 不够用的情况。针对这种情况怎么办?就需要自动扩缩容。
按方式分类
• 手动模式
通过 kubectl scale 命令,这样需要每次去手工操作一次,而且不确定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。
• 自动模式
kubernetes HPA(Horizontal Pod Autoscaling):根据监控指标(cpu 使用率、磁盘、自定义的等)自动扩容或缩容服务中的pod数量,当业务需求增加时,系统将无缝地自动增加适量 pod 容器,提高系统稳定性。
kubernetes KPA(Knative Pod Autoscaler):基于请求数对 Pod 自动扩缩容,KPA 的主要限制在于它不支持基于 CPU 的自动扩缩容。
kubernetes VPA(Vertical Pod Autoscaler):基于 Pod 的资源使用情况自动设置 pod 的 CPU 和内存的 requests,从而让集群将 Pod 调度到有足够资源的最佳节点上。
二、如何实现自动扩缩容
HPA运作方式
• 整体逻辑:K8s 的 HPA controller 已经实现了一套简单的自动扩缩容逻辑,默认情况下,每 15s 检测一次指标,只要检测到了配置 HPA 的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在 5min 内没有重新扩缩容的情况下,才会触发扩缩容。
• 缺陷:HPA 本身的算法相对比较保守,可能并不适用于很多场景。例如,一个快速的流量突发场景,如果正处在 5min 内的 HPA 稳定期,这个时候根据 HPA 的策略,会导致无法扩容。
• pod数量计算方式:通过现有 pods 的 CPU 使用率的平均值(计算方式是最近的 pod 使用量(最近一分钟的平均值,从 metrics-server 中获得)除以设定的每个 Pod 的 CPU 使用率限额)跟目标使用率进行比较,并且在扩容时,还要遵循预先设定的副本数限制:MinReplicas <= Replicas <= MaxReplicas。计算扩容后 Pod 的个数:sum(最近一分钟内某个 Pod 的 CPU 使用率的平均值)/CPU 使用上限的整数+1
三、安装 Metrics Server
# 官方仓库地址:https://github.com/kubernetes-sigs/metrics-server
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.4.0/components.yaml
在部署之前,修改 components.yaml 的镜像地址为:
hostNetwork: true # 使用hostNetwork模式
containers:
- name: metrics-server
image: cnych/metrics-server:v0.4.0
kubectl apply -f components.yaml
kubectl get pods -n kube-system -l k8s-app=metrics-server
问题处理:
如果出现pod的状态一直在重启,要看下日志报错

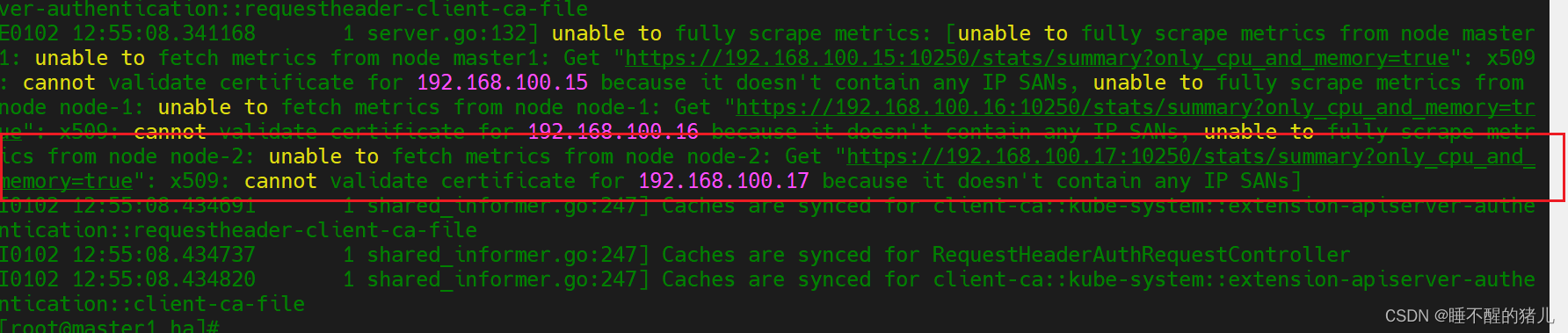
E0102 12:55:08.341168 1 server.go:132] unable to fully scrape metrics: [unable to fully scrape metrics from node master1: unable to fetch metrics from node master1: Get “https://192.168.100.15:10250/stats/summary?only_cpu_and_memory=true”: x509: cannot validate certificate for 192.168.100.15 because it doesn’t contain any IP SANs, unable to fully scrape metrics from node node-1: unable to fetch metrics from node node-1: Get “https://192.168.100.16:10250/stats/summary?only_cpu_and_memory=true”: x509: cannot validate certificate for 192.168.100.16 because it doesn’t contain any IP SANs, unable to fully scrape metrics from node node-2: unable to fetch metrics from node node-2: Get “https://192.168.100.17:10250/stats/summary?only_cpu_and_memory=true”: x509: cannot validate certificate for 192.168.100.17 because it doesn’t contain any IP SANs]
修复方式:
在如下位置添加:- --kubelet-insecure-tls
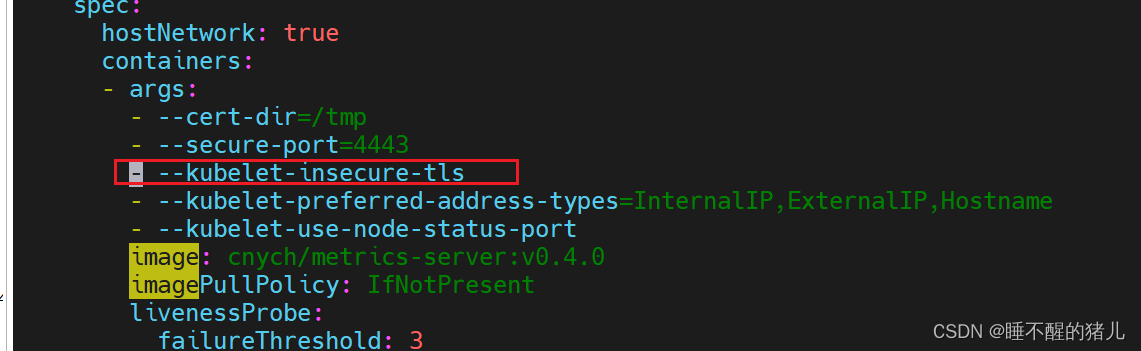
检查:
 指标获取
指标获取
K8S 从 1.8 版本开始,各节点CPU、内存等资源的 metrics 信息可以通过 Metrics API 来获取,用户可以直接获取这些 metrics 信息(例如通过执行 kubect top 命令),HPA 使用这些 metics 信息来实现动态伸缩。
[root@master1 ha]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 419m 20% 1465Mi 39%
node-1 251m 12% 811Mi 22%
node-2 235m 11% 813Mi 22%
四、实践
1)使用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:(hpa-demo.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
#执行yaml启动
kubectl apply -f hpa-demo.yaml
#查看pod
kubectl get pods -l app=nginx
2)创建一个 HPA 资源对象
#此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量。
kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
#查看hpa状态
[root@master1 ha]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 0 10s
[root@master1 ha]#
[root@master1 ha]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 20s
五、测试验证
#使用busybox进行压测
[root@master1 ha]# kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.137.87; done
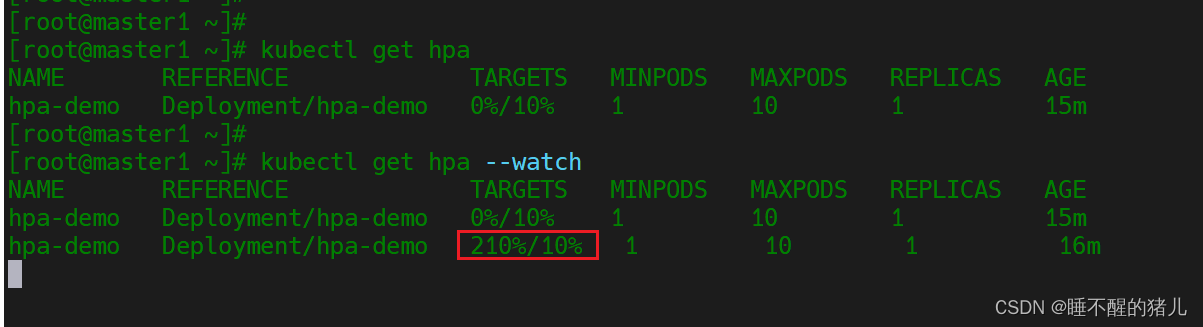
#观察hpa值变化:
kubectl get hpa --watch
#观察pod的变化
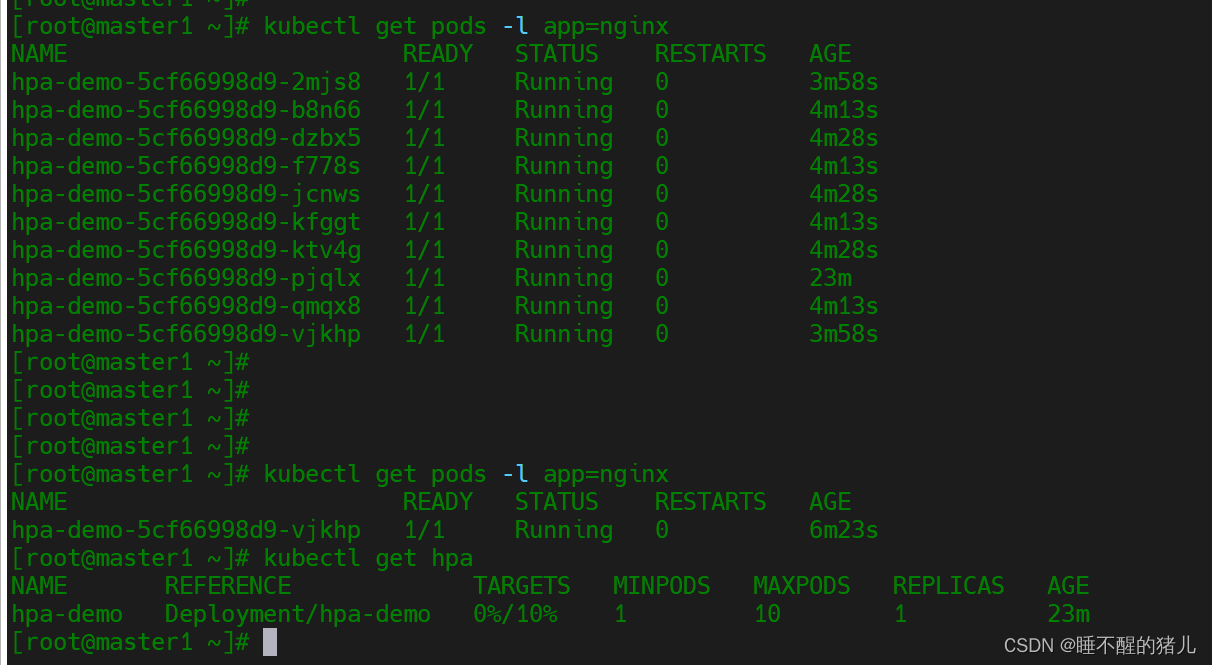
kubectl get pods -l app=nginx --watch
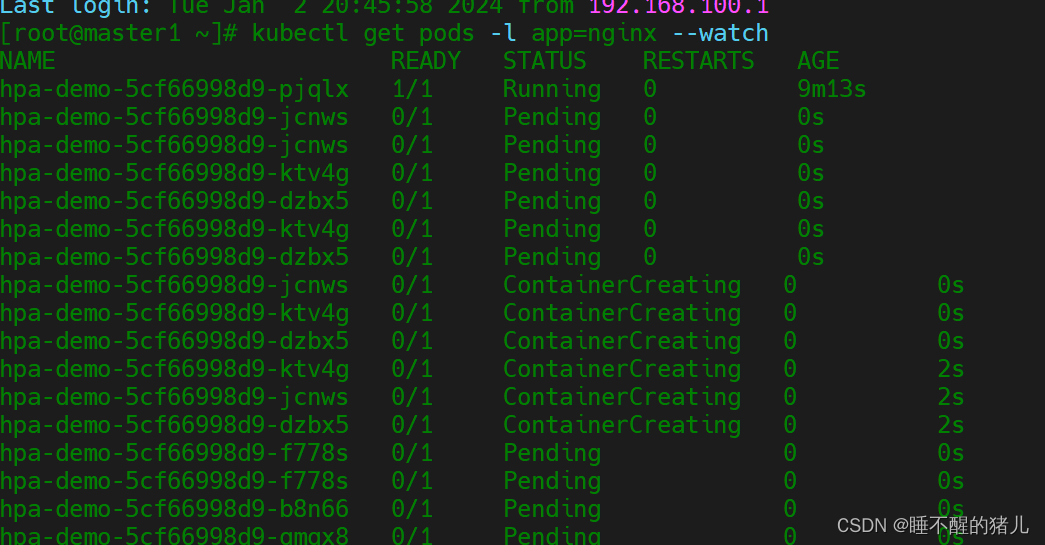
流量太大时候就会出现不能及时扩容的场景,这也就是缺点的地方
当cpu恢复后pod的数量也自动缩容,实现了自动扩缩容