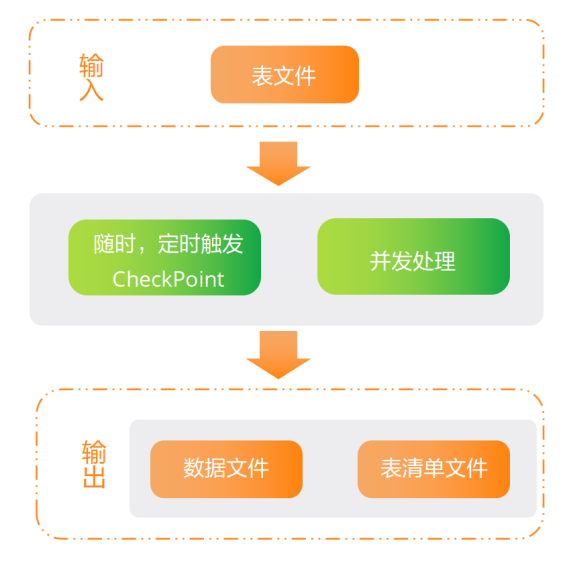
一、背景:
客户方提供过来一个开放平台的pdf文档,文档里有几十个接口,没有大纲和目录可以定位到具体内容,了解整体的API功能,观看体验极度差劲,所以想使用Python代码自动解析pdf文档,给文档增添大纲内容,便于观看和理解。
二、实现思路:
1、可行性调研
- pdf文档是文本格式的,而非扫描图像,所以可以拿到具体的文本内容。
- 内容格式整体比较整齐,标题有特定的格式可以识别。
2、技术细节
- 使用pyPDF2和pdfplumber类库来实现pdf的解析。
- 根据章节标题的格式,编写正则表达式进行匹配
- 记录识别结果到csv文件中,方便比对和删除多余的标题内容。
- 使用pyPDF2来添加书签,生成新的PDF大纲。
三、代码
1、详细python代码
import csv
import pdfplumber
import re
from PyPDF2 import PdfReader, PdfWriter
# TODO PDF文件路径
pdf_path = 'C:\\Users\\admin\\Desktop\\use_book.pdf' # 更改为您的PDF文件路径
output_pdf_path = '.\output_use_book_with_bookmarks.pdf' # 输出文件的路径
# 保存目录信息的CSV文件路径
csv_path = 'titles.csv'
# 检测是否为标题的函数
# 现在只匹配包含至少两个点的数字序列
def is_title(line):
# TODO 正则表达式匹配类似 "3.8.1.2.3 业务接口" 的格式
# 确保后面紧跟着的是文字而不是数字或符号
pattern = r'^\d+(\.\d+)+\s+[^\d\W]+.*'
return re.match(pattern, line) is not None
# 提取标题的函数
def extract_titles(pdf_path):
titles = []
with pdfplumber.open(pdf_path) as pdf:
for page_number, page in enumerate(pdf.pages):
text = page.extract_text()
if text:
for line in text.split('\n'):
if is_title(line):
titles.append((line.strip(), page_number)) # PDF页码从0开始
return titles
# 将标题保存到CSV文件
def save_titles_to_csv(titles, csv_path):
with open(csv_path, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Page Number'])
for title in titles:
writer.writerow(title)
# 从CSV文件读取标题
def read_titles_from_csv(csv_path):
titles = []
with open(csv_path, 'r', encoding='utf-8') as file:
reader = csv.reader(file)
next(reader) # 跳过标题行
for row in reader:
titles.append((row[0], int(row[1]) - 1)) # 将页码转换为从0开始的索引
return titles
# 检查是否已经有保存的目录信息
try:
titles = read_titles_from_csv(csv_path)
except FileNotFoundError:
# 如果没有找到文件,则提取并保存目录信息
titles = extract_titles(pdf_path)
save_titles_to_csv(titles, csv_path)
# 打印目录信息
for title in titles:
print(f"Title: {title[0]}, Page: {title[1]}")
# 添加大纲的函数
def add_bookmarks_to_pdf(input_pdf_path, output_pdf_path, titles):
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
for title, page_number in titles:
writer.add_outline_item(title, page_number)
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
if __name__ == '__main__':
# 调用函数
titles = read_titles_from_csv(csv_path)
add_bookmarks_to_pdf(pdf_path, output_pdf_path, titles)
2、涉及依赖版本库
python = 3.10 (anaconda3)
pdfplumber = 0.10.3
PyPDF2 = 3.0.1
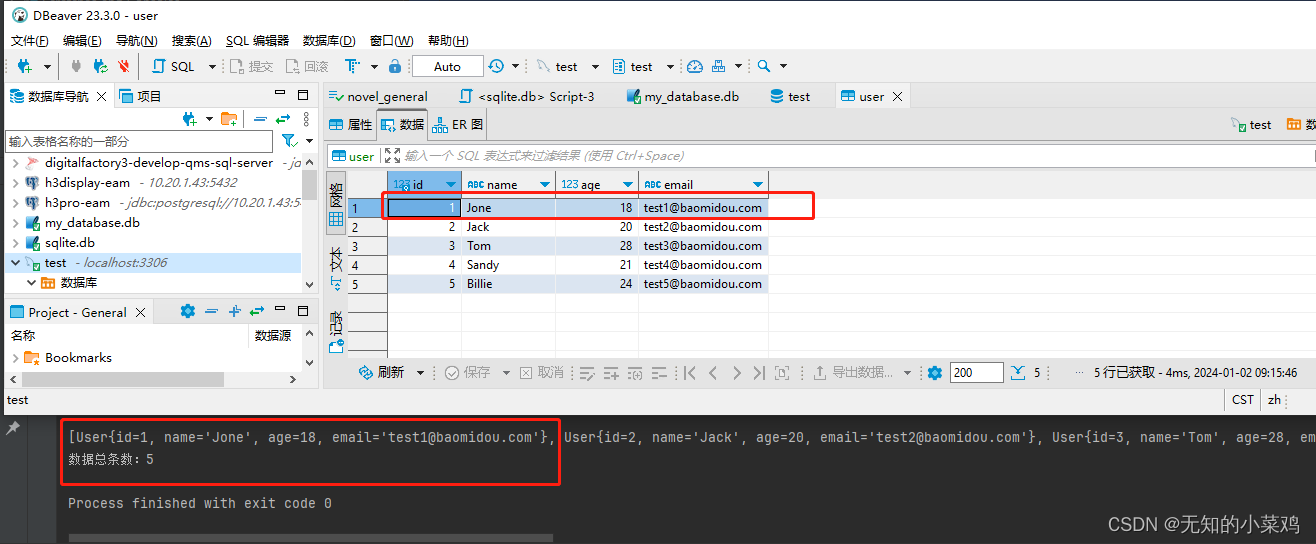
3、运行效果
- csv 文件示例 ( title.csv )
Title,Page Number
2.1 运行硬件环境,5
2.2 运行软件环境,5
3.1 门户应用,6
3.1.1 门户配置,6
3.1.2 常用应用,6
3.1.3 快捷导航,7
3.1.4 下载,9
3.1.4.1 插件助手,9
3.1.4.2 客户端,10
3.1.4.3 插件,10
3.1.5 用户登录管理,10
- pdf 示例

四、补充
理论上如果标题格式有层级关系,是可以在添加书签的时候,调整每个书签的层级,达到更好的阅读体验。
# 解析标题层级的函数
def parse_title_level(title):
# 假设标题格式为 "1.1.1 标题"
level = title.count('.') # 层级由点的数量决定
return level
# 添加大纲的函数 (修改版)
def add_bookmarks_to_pdf(input_pdf_path, output_pdf_path, titles):
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
bookmarks = [None] * 10 # 重点在这段,假设最大层级为10
for title, page_number, level in titles:
parent = bookmarks[level-1] if level > 0 else None # 确定父书签
bookmark = writer.add_outline_item(title, page_number, parent)
bookmarks[level] = bookmark # 更新当前层级的书签
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
以上代码未进行调试,仅做参考 (* ^ ▽ ^ *) 。