目录
- (1)why deep learning is game changing?
- (2)it all started with a neuron
- (3)Perceptron
- (4)Perceptron for Binary Classification
- (5)put it all together
- (6)multilayer Perceptron
- (7)backpropagation
- (8)实战演练-使用感知机用于感情识别
- 1. 数据集划分
- 2. 将文本转成vector
- 3.对数据集进行预处理fit/transform/fit_transform
- 4.创建模型并训练
- 5、评估模型
- (9)使用MLP来提升性能
link:https://towardsdatascience.com/multilayer-perceptron-explained-with-a-real-life-example-and-python-code-sentiment-analysis-cb408ee93141
(1)why deep learning is game changing?
传统的机器学习太依赖于模型,一般都需要有很多经验的专家来构建模型,而且机器学习的质量也很大程度上取决于数据集的质量和how well features encode the patterns in the data
深度学习算法使用人工神经网络作为主要的模型,好处就是不再需要专家来设计特征,神经网络自己学习数据中的characteristics
深度学习算法读入数据后,学习数据的patterns,学习如何用自己提取的特征来代表数据。之后组合数据集的特征,形成一个更加具体、更加高级的数据集表达形式。
深度学习侧重于使系统能够学习multiple levels of partern composition(组合)
(2)it all started with a neuron
1940 Warren McCulloch teamd up with Walter Pitts created neuron model
a piece of cake:
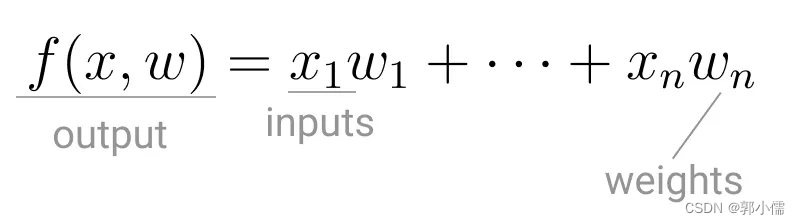
神经网络的首次应用是复制(replicated)了一个logic gate:
但是此时的神经网络没有办法像大脑一样学习,因为获得期望输出的前提是,魔性的参数要提前设置好
only a decade later, Frank Rosenblatt 创建了一个可以学习权重的模型:💥Perceptron💥
(3)Perceptron
Perception 最初是为了图像识别创造的,为了让模型具有人类的perception(感知),seeing and recognizing 图片的能力。
Perception模型核心就是neuron,主要不同就是输入被组合成一个加权和,如果这个加权和超过一个预设的阈值(threshold),神经网络就会被触发,得到一个输出。
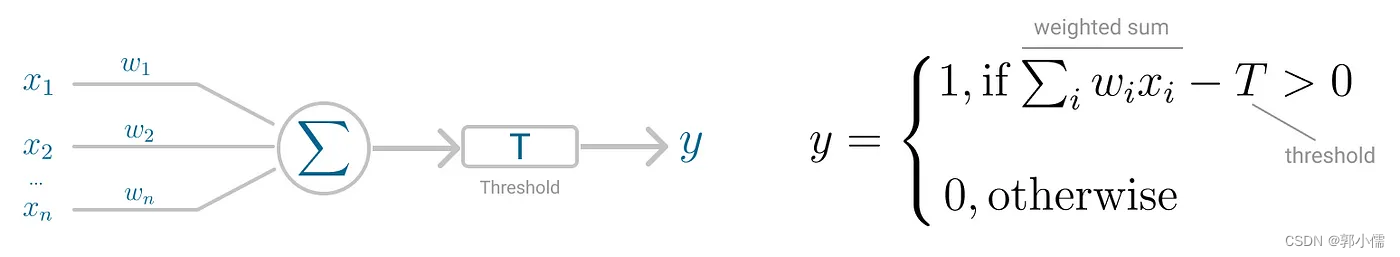
(4)Perceptron for Binary Classification
Perceptron 用于二元分类问题的主要假设是数据是:linearly separable(线性可分):

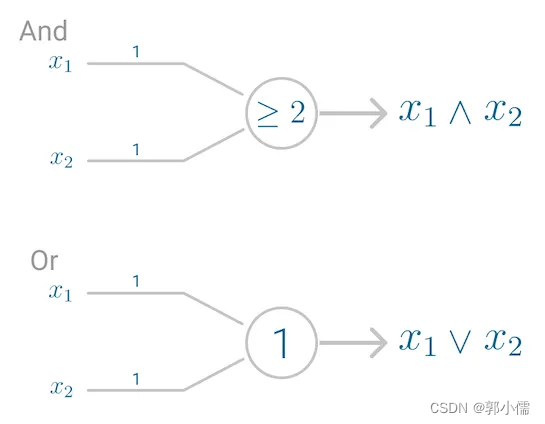
神经网络的预测值:
f
(
x
;
w
)
=
s
i
g
n
(
∑
i
w
i
x
i
−
T
)
∀
i
=
1
,
.
.
.
,
n
f(x;w)=sign(\sum_i w_ix_i-T) \forall i=1,...,n
f(x;w)=sign(i∑wixi−T)∀i=1,...,n
神经网络的真实值(label):
y
i
y_i
yi
如果预测正确率的话:
y
i
⋅
f
(
x
;
w
)
>
0
y_i \cdot f(x;w)>0
yi⋅f(x;w)>0
所以目标函数被设计为:
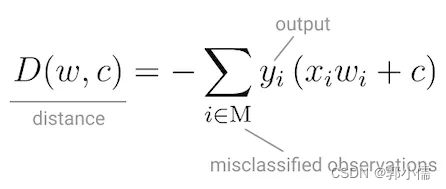
优化目标就是
min
D
(
w
,
c
)
\min D(w,c)
minD(w,c)
和其他算法不同,这个目标函数不能求导,所以Perceptron使用 Stochastic Gradient Descent(随机梯度下降法)来最小化目标函数(如果数据集是线性可分的,就可以使用这个方法,并且在有限的steps内converge收敛)

对于足够小的正数
r
r
r,我们就能保证
L
(
w
1
)
<
L
(
w
)
L(w_1)<L(w)
L(w1)<L(w)
Perceptron使用的激活函数是sigmoid function,这个函数把数值映射成一个0~1值:

之前总结过的sigmoid图:

- 非线性函数
- 值在0到1之间
- 它有助于网络更新或忘记数据。如果相乘结果为0,则认为该信息已被遗忘。类似地,如果值为1,则信息保持不变。
但是用的更多的是 Rectified Linear Unit (ReLU):

为什么更多使用ReLU?因为它可以使用随机梯度下降进行更好的优化,并且是尺度不变的,这意味着它的特征不受输入规模的影响。(没大搞懂)
(5)put it all together
神经网络输入数据,最初先随机设置权重,然后计算加权和,在通过激活函数ReLU,得到输出:

之后Perceptron使用随机梯度下降法,learn 权重,来最小化错误分类的点和决策边界(decision boundary)的距离,一旦收敛,数据集就会被线性超平面(linear hyperplane)分成两个区域
❌感知机不能表示XOR门(只有输入不同,返回1)
Minsky and Papert, in 1969 证明了这种只有一个神经元的Proceptron不能处理非线性数据,只能处理线性可分的数据
(6)multilayer Perceptron
多层感知器就是为了处理非线性可分问题的
多层感知器含有输入层、输出层、一个或者多个隐藏层

多层感知器和单层的一样将输入由最初随机的权重进行加权和再经过激活函数得到输出,但是不同的是,每个线性组合会传递给下一层:前向传播
但是只有秦香传播,就不能学习到能使得目标函数最小的权重,所以之后引入反向传播
(7)backpropagation
反向传播以最小化目标函数为goal,是的MLP能够迭代的调整神经网络的权重
⚡️反向传播的必要条件: 神经网络输入的加权和(
∑
i
w
i
⋅
x
i
\sum_i w_i \cdot x_i
∑iwi⋅xi)、激活函数(ReLU)必须是可微分的

在每次迭代iteration,当所有层的加权和都被前向传播之后,计算所有输入和输出对的Mean Squared Error(均方差) 的梯度,之后让第一个隐藏层的权重更新为这个梯度,这个过程将抑制持续,直到所有的输入输出对都收敛,意味着新的梯度不能改变收敛阈值。
其实还是有点没搞懂这个过程,我记得陈木头?这个博主讲的害挺清晰的,之后再看看
(8)实战演练-使用感知机用于感情识别
识别一句话到底是“好话”还是“坏话”

1. 数据集划分
使用train_test_split 函数
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
- X和y:表示输入数据和对应的标签
- test_size:表示测试集所占的比例,这里设置为 0.1,表示测试集占原始数据集的 10%。
- random_state:表示随机数种子
- 数据集划分为什么要用到随机数:数据集的划分方式可能会影响到算法的性能和稳定性。如果数据集的划分方式不够随机,那么算法可能会偏向于某些特定的数据集,从而影响算法的准确性和泛化能力。
- 设置固定的随机数的好处:设置了随机数种子后,每次运行程序时都能得到相同的数据集划分,是因为函数使用了指定的随机数种子来生成随机数。这样,每次运行程序时生成的随机数都是相同的,从而保证了数据集的划分结果相同。如果我们将 random_state 设置为 None,那么每次运行程序时都会得到不同的数据集划分。
2. 将文本转成vector
使用Term Frequency — Inverse Document Frequency (TF-IDF):该方法将任何类型的文本编码为每个单词或术语在每个句子和整个文档中出现频率的统计数据。
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer(stop_words='english', lowercase=True, norm='l1')
# 删除英语停顿词,应用L1规范化
sklearn 是 Python 中一个流行的机器学习库,全名 scikit-learn。它提供了大量的分类、回归、聚类、降维和数据处理等算法,可以用于处理和分析数据,以帮助用户进行数据建模、预测和分类等任务。sklearn 基于 NumPy、SciPy 和 matplotlib,使用这些库的功能来提供高效的算法实现。
3.对数据集进行预处理fit/transform/fit_transform
参考链接:fit_transform,fit,transform区别和作用详解!!!!!!
TfidfTransformer举例
在较低的文本语料库中,一些词非常常见(例如,英文中的“the”,“a”,“is”),因此很少带有文档实际内容的有用信息。如果我们将单纯的计数数据直接喂给分类器,那些频繁出现的词会掩盖那些很少出现但是更有意义的词的频率。
- fit:求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
- fit(raw_documents, y=None):根据训练集生成词典和逆文档词频 由fit方法计算的每个特征的权重存储在model的idf_属性中。
- transform:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
- transform(raw_documents, copy=True):使用fit(或fit_transform)学习的词汇和文档频率(df),将文档转换为文档 - 词矩阵。返回稀疏矩阵,[n_samples, n_features],即,Tf-idf加权文档矩阵(Tf-idf-weighted document-term matrix)。
- fit_transform:fit_transform是fit和transform的组合,既包括了训练又包含了转换。fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
- 必须先用fit_transform(trainData),之后再transform(testData)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit_tranform(X_train)
sc.tranform(X_test)
# 根据对之前部分trainData进行fit的整体指标,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。
4.创建模型并训练
from sklearn.linear_model import Perceptron
classifier = Perceptron(random_state=457)
classifier.fit(train_features, train_targets)
-
sklearn.linear_model.Perceptron:感知机模型
- class sklearn.linear_model.Perceptron(*, penalty=None, alpha=0.0001, l1_ratio=0.15, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, eta0=1.0, n_jobs=None, random_state=0, early_stopping=False, validation_fraction=0.1, n_iter_no_change=5, class_weight=None, warm_start=False
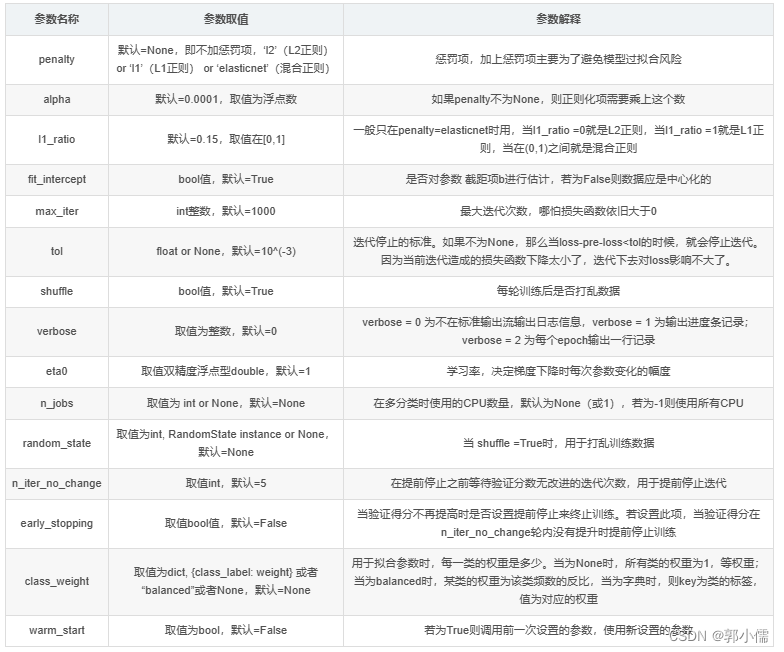
-
model.fit函数:训练模型,返回loss和测量指标(history)
- model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)

- callback=callbacks.EarlyStopping(monitor=‘loss’,min_delta=0.002,patience=0,mode=‘auto’,restore_best_weights=False)
- monitor:监视量,一般是loss。
- min_delta:监视量改变的最小值,如果监视量的改变绝对值比min_delta小,这次就不算监视量改善,具体是增大还是减小看mode
- patience:如发现监视量loss相比上一个epoch训练没有下降,则经过patience个epoch后停止训
- mode:在min模式训练,如果监视量停止下降则终止训练;在max模式下,如果监视量停止上升则停止训练。监视量使用acc时就要用max,使用loss时就要用min。
- restore_best_weights:是否把模型权重设为训练效果最好的epoch。如果为False,最终模型权重是最后一次训练的权重
- model.fit( )函数返回一个History的对象,即记录了loss和其他指标的数值随epoch变化的情况。
- model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)
5、评估模型
predictions = classifier.predict(test_features)
score = np.round(metrics.accuarry_score(test_labels, predictions), 2)
- model.predict(X_test, batch_size=32,verbose=1)
- X_test:为即将要预测的测试集
- batch_size:为一次性输入多少张图片给网络进行训练,最后输入图片的总数为测试集的个数
- verbose:1代表显示进度条,0不显示进度条,默认为0
- 返回值:每个测试集的所预测的各个类别的概率
- 例子:
# 各个类别评估(X_test为10000个数据集) print("[INFO] evaluating network...") predictions = model.predict(X_test, batch_size=32) #显示每一个测试集各个类别的概率,这个值的shape为(10000,10) print(predictions) print(predictions.shape) 
- model.predict(X_test, batch_size=32)的返回值为每个测试集预测的10个类别的概率
- metrics.accuarry_score:计算分类的准确率
- sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
- normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数
- true:

- false:TP+TN
>>>import numpy as np >>>from sklearn.metrics import accuracy_score >>>y_pred = [0, 2, 1, 3] >>>y_true = [0, 1, 2, 3] >>>accuracy_score(y_true, y_pred) 0.5 >>>accuracy_score(y_true, y_pred, normalize=False) 2

完整代码:

(9)使用MLP来提升性能
- 激活函数:参数activation=’relu’
- 使用随机梯度下降算法:solver=’sgd’
- 学习率:learning_rate=’invscaling’这是啥啊
- 迭代次数:max_iter=20
代码:

使用的MLP是有3个隐藏层,每个隐藏层有两个节点
此时的性能并不好
当把num_neurons=5之后,性能就变好了
这就是调参!








![[GKCTF 2020]cve版签到](https://img-blog.csdnimg.cn/direct/c37e5f8168004f26a7382d6afce917e0.png#pic_center)