大型语言模型 (LLM) 已展现出理解自然语言提示并生成连贯响应的卓越能力。 这为将自然语言翻译成 SQL 等结构化查询语言开辟了新的可能性。 过去,编写 SQL 查询需要技术专业知识,而LLM允许任何人用简单的英语描述他们想要的内容,并自动生成相应的 SQL 代码。
当利用LLM将自然语言转换为 SQL 查询时,提示词至关重要。 使用 Anthropic 的两个模型(Claude instant 1.1、Claude 2),并使用不同的提示工程技术评估了spider数据集上的 SQL 查询准确性(执行准确性)。 从较高的层面来看,在进行自然语言到 SQL 的转换时,提示工程有几个重要的考虑因素:
-
使用清晰的说明–简单明了的自然语言提示更容易让LLM理解和翻译。
-
提供足够的上下文 --LLM 需要了解用户的请求查询语义以及有关数据库模式的详细信息,例如表和列名称。
-
包括示例 --提供一些自然语言和对应SQ的示例,可以帮助指导 LLM 以正确的语法生成查询。
-
利用 RAG(检索增强生成)–检索与用户查询相关的自然语言和 SQL 示例,可以提高准确性。
在这篇博客中,我将使用我的基准测试结果来帮助您了解上述每种提示策略如何影响自然语言到 SQL 转换的准确性。
操作说明
当使用 LLM 从自然语言生成 SQL 时,在提示中提供清晰的说明对于控制模型的输出至关重要。 在我对 Claude 模型的实验中,一种有效的策略是在提示中使用 XML 标签来注释不同的组件。 XML 标签就像指令一样,准确地告诉模型如何格式化 SQL。 例如,指示模型在 之间编写查询可以减少详细输出。 如果没有这条指令,Claude模型可能会非常健谈。 它倾向于解释 SQL 结构,这会增加后处理的复杂性并不必要地消耗更多的输出标记。 在 <table_schema> </table_schema> 之间添加表标记告诉模型上下文开始和结束的位置。
"""
Given an input question, use sqlite syntax to generate a sql query by choosing
one or multiple of the following tables. Write query in between <SQL></SQL>.
For this Problem you can use the following table Schema:
<table_schema>
{table_info}
</table_schema>
Please provide the SQL query for this question:
Question:{input}
Query:
"""
Database Schema
您需要包含数据库模式作为 LLM 生成 SQL 查询的上下文。 通常,数据库模式包括表名、列名、列类型、指示表关系的主键和外键。 在实验中,我尝试了仅列名、列名+外键和列名+外键+列类型。 结果表明列名+外键有最好的性能。 当查询需要连接表时,外键特别有用。 添加列类型没有帮助,甚至会产生更糟糕的结果。 这有点令人惊讶,但我相信这种行为可能不适用于所有模型。

Few-Shot Example
小样本学习涉及在提示中包含少量示例以演示所需的映射。 例如,提示可以包含 2-3 对自然语言查询和相应的 SQL 语句。 添加少量示例时,您还应该利用 XML 标签来获得清晰的说明。
"""Given an input question, use sqlite syntax to generate a sql query by choosing
one or multiple of the following tables. Write query in between <SQL></SQL>.
For this Problem you can use the following table Schema:
<table_schema>
{table_info}
</table_schema>
Below are three example Questions and the corresponding Queries.
<example>
Question:{question_1}
Query:<SQL>{query_1}</SQL>
</example>
<example>
Question:{question_2}
Query:<SQL>{query_2}</SQL>
</example>
<example>
Question:{question_3}
Query:<SQL>{query_2}</SQL>
</example>
Please provide the SQL query for this question:
Question:{input}
Query: """
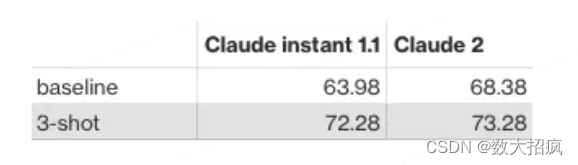
我的基准测试结果表明,通过在同一数据库模式上下文中包含 3 个示例,我们取得了显着的改进。 我鼓励您尝试更多示例以进一步改进结果。
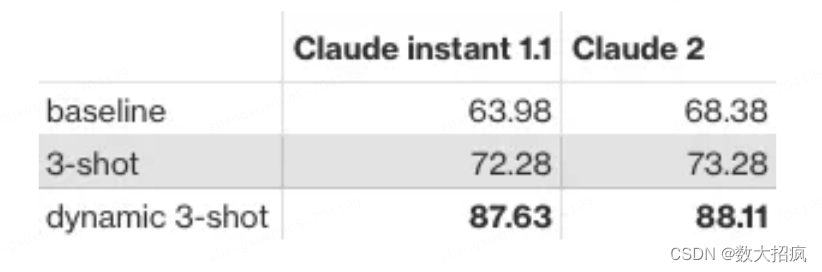
RAG for Dynamic Few-Shot Examples
虽然少数示例可以提高模型性能,但选择最相关的示例包含在提示中可以进一步提高模型性能。 使用 RAG,您可以动态选择少数示例并注入到提示中。 例如,对于给定的自然语言问题“显示出现次数最少的交易类型代码”,检索算法可以包括最相关的示例,例如“如果份额计数小于 10,则显示交易类型描述和日期”或“显示…的描述” 交易类型代码为“PUR”。 我的结果表明动态少样本方法可以显着提高模型性能。 值得注意的是,few-shot 学习可以缩小 Claude instant 1.1 与其更强大的同类 Claude 2 之间的差距。
结论
最后,提示工程对于优LLM以将自然语言转换为准确的 SQL 查询至关重要。 我在spider数据集上使用 Claude 进行的基准测试结果表明,通过包含schema详细信息、清晰的说明和添加少量示例等技术获得了切实的改进。 此外,检索增强提示动态地选择理想的少样本示例以最大化相关性。 通过深思熟虑的提示设计,我们可以引导LLM更好地理解我们的自然语言意图,并为每个人释放 SQL 的力量。