
读算法霸权笔记09_信用数据的陷阱
news2026/2/11 20:01:01
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1349683.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
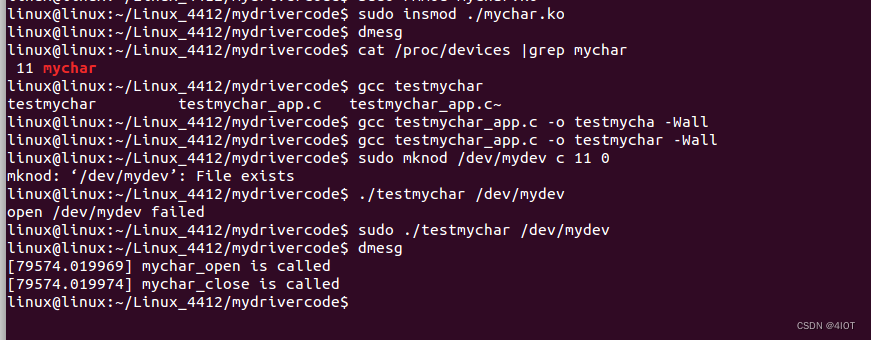
lv14 注册字符设备 3
1 注册字符设备
1.1 结构体介绍
struct cdev
{struct kobject kobj;//表示该类型实体是一种内核对象struct module *owner;//填THIS_MODULE,表示该字符设备从属于哪个内核模块const struct file_operations *ops;//指向空间存放着针对该设备的各种操作函数地址str…

win10安装虚拟机
一、下载virualbox
https://www.virtualbox.org/wiki/Downloads,要开启cpu虚拟化,无脑安装
二、下载vargrant
https://www.vagrantup.com/,无脑安装
下载完重启电脑,在命令窗口输入vagrant有提示则安装成功 通过查询vagrant的…
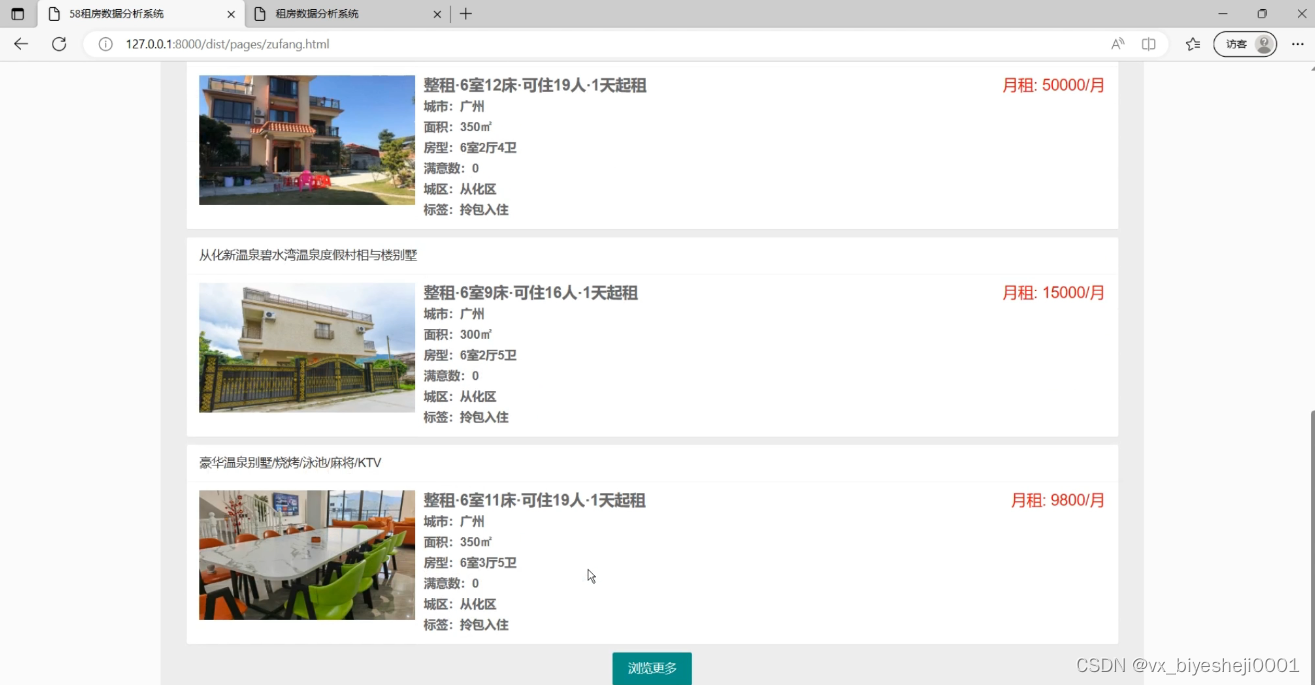
租房数据分析可视化大屏+58同城 Django框架 大数据毕业设计(附源码)✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题ÿ…
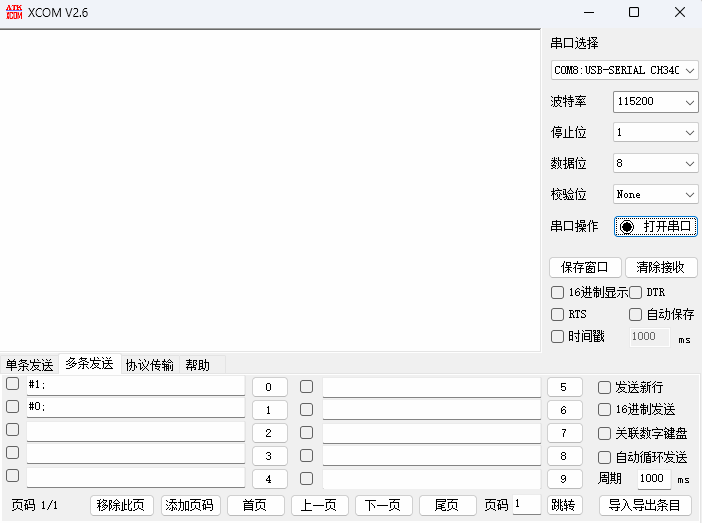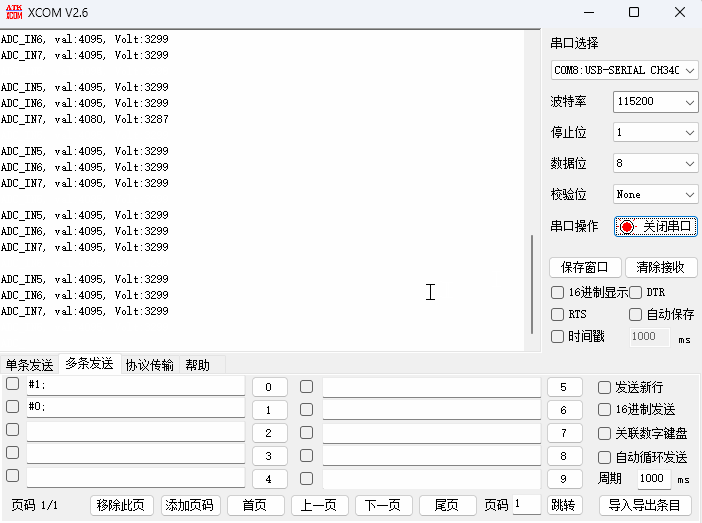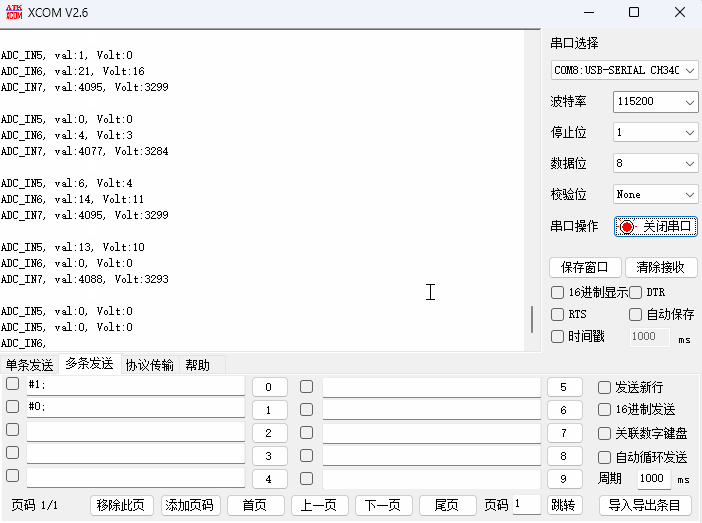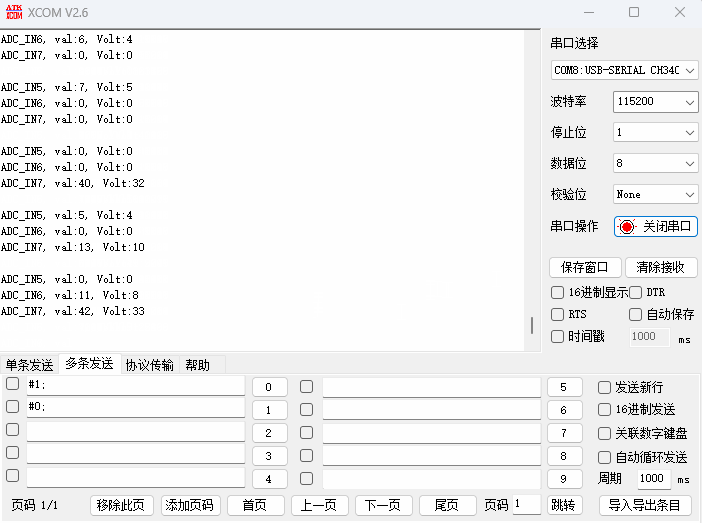
STM32CubeMX教程14 ADC - 多通道DMA转换
目录
1、准备材料
2、实验目标
3、实验流程
3.0、前提知识
3.1、CubeMX相关配置
3.1.1、时钟树配置
3.1.2、外设参数配置
3.1.3、外设中断配置
3.2、生成代码
3.2.1、外设初始化调用流程
3.2.2、外设中断调用流程
3.2.3、添加其他必要代码
4、常用函数
5、烧录验…
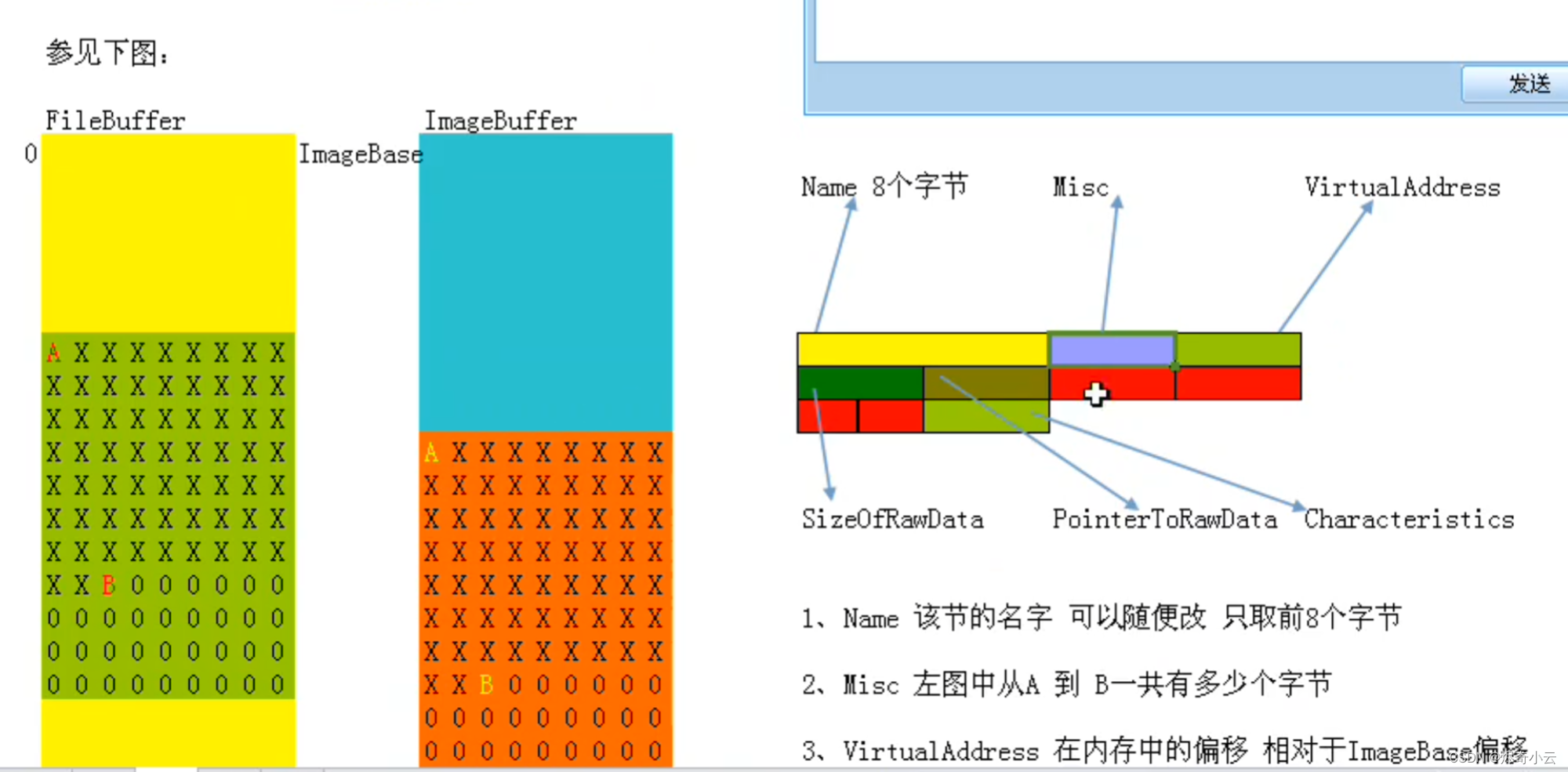
PE解释器之PE文件结构
PE文件是由许许多多的结构体组成的,程序在运行时就会通过这些结构快速定位到PE文件的各种资源,其结构大致如图所示,从上到下依次是Dos头、Nt头、节表、节区和调试信息(可选)。其中Dos头、Nt头和节表在本文中统称为PE文件头(因为SizeOfHeaders…
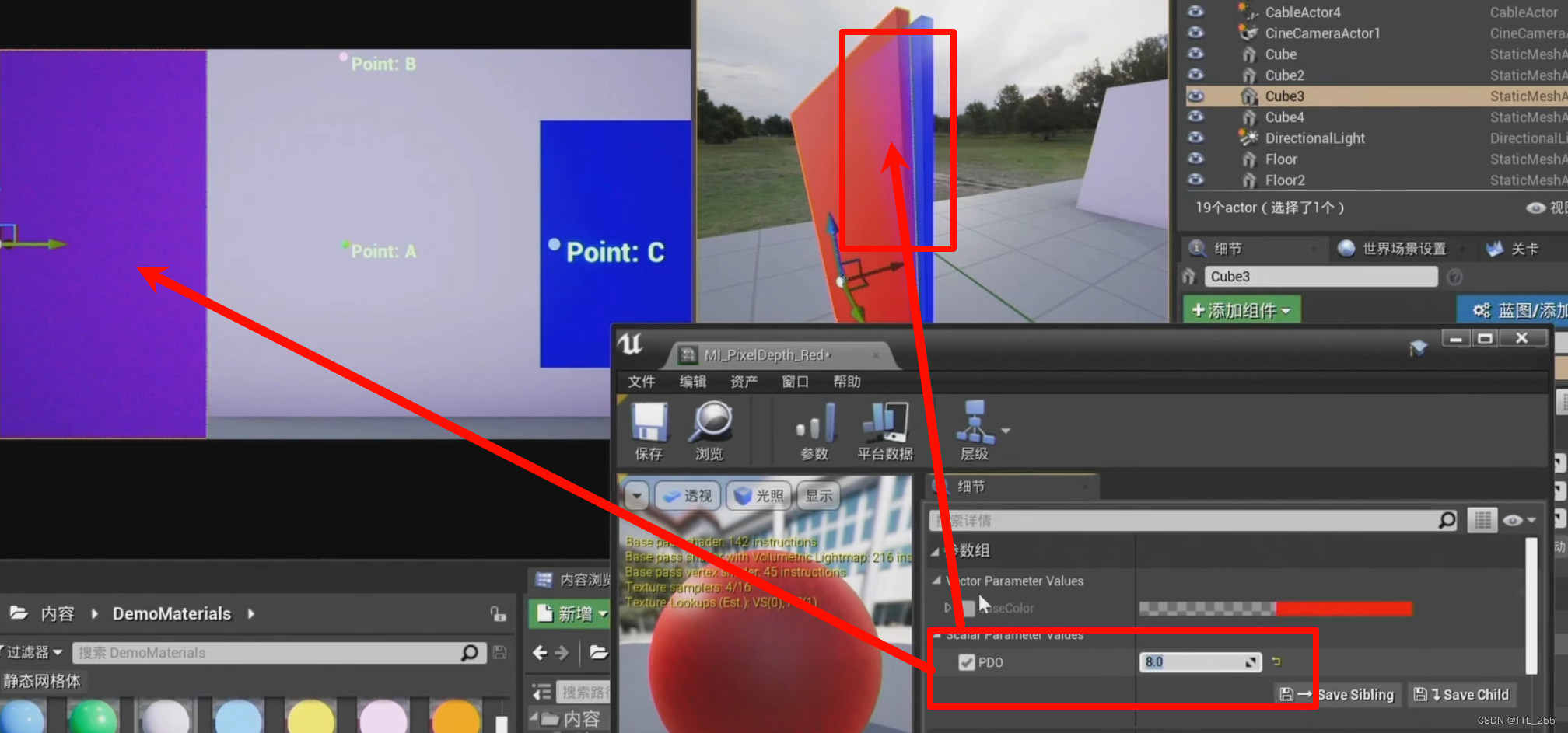
虚幻UE 材质-PDO像素深度偏移量
2024年的第一天!!!大家新年快乐!!! 可能是长大了才知道 当你过得一般 你的亲朋好友对你真正态度只可能是没有表露出来的冷嘲热讽了 希望大家新的一年平安、幸福、 永远活力满满地追求自己所想做的、爱做的&…
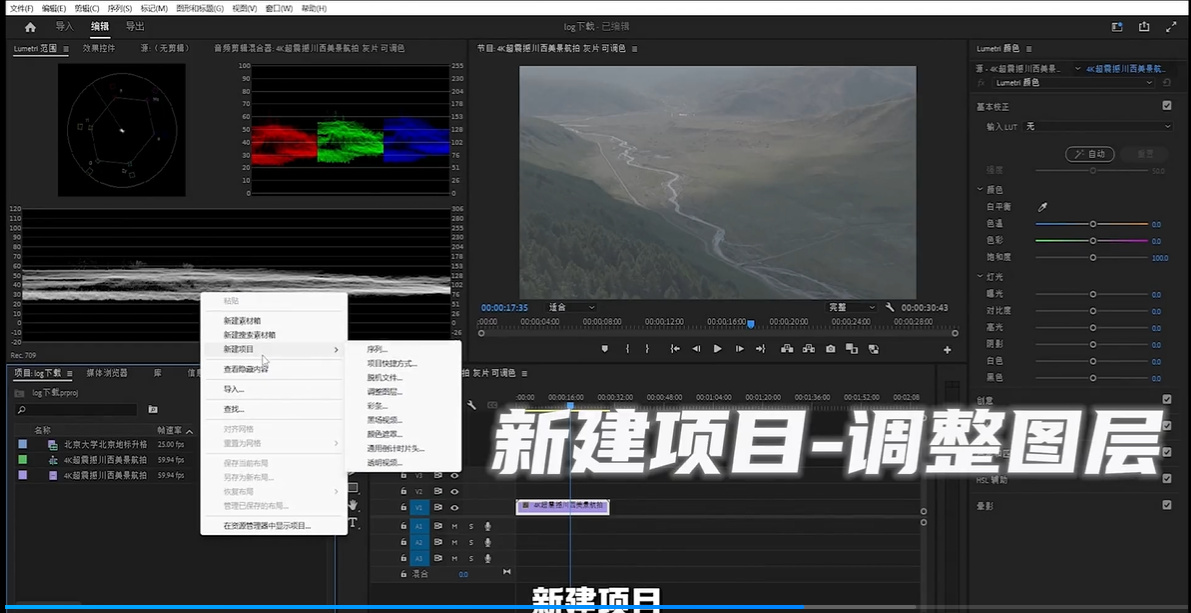
影视后期:PR 调色处理,灰片还原,校色偏色素材
灰片还原
确定拍摄灰片的相机型号品牌官网下载专用log文件LUT-浏览-导入slog3分析亮部波形-增加画面对比分析矢量示波器-提高整体饱和
校正LUT可以将前期拍摄的log色彩模式的视频转换为成709色彩模式,即将灰度视频转换为正常效果(灰片还原) 各个相机有对应的校正L…
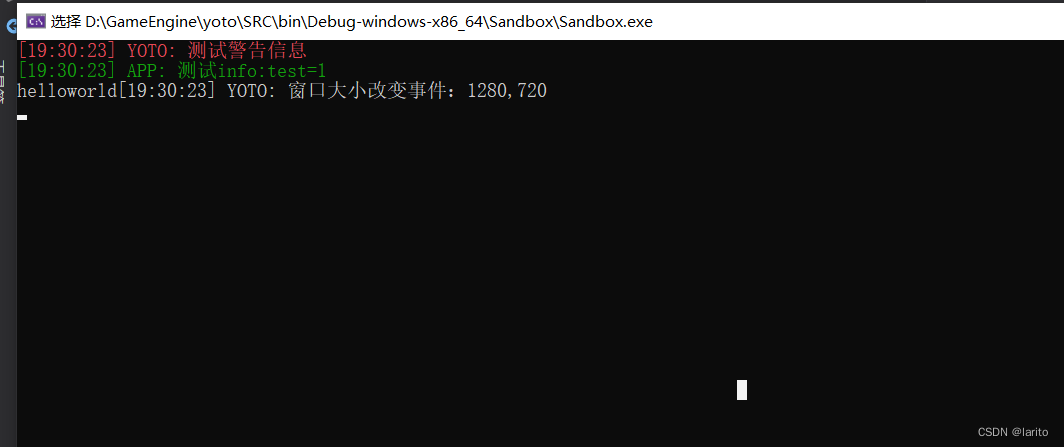
跟着cherno手搓游戏引擎【3】事件系统和预编译头文件
不多说了直接上代码,课程中的架构讲的比较宽泛,而且有些方法写完之后并未测试。所以先把代码写完。理解其原理,未来使用时候会再此完善此博客。
文件架构: Event.h:核心基类
#pragma once
#include"../Core.h"
#inclu…
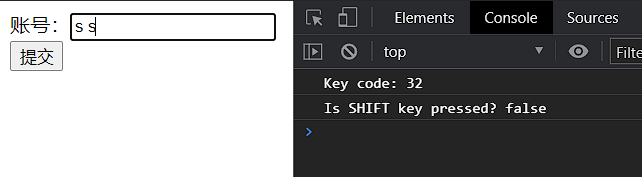
javaScript中的常用事件
文章目录 javaScript中什么是事件?基本原理javaScript中的时间使用1,窗口事件1.1、onblur1.2、onfocus1.3、onload1.4、onresize 2,表单事件2.1、onchange2.2、**oninput**2.3、oninvalid2.4、onselect2.5、onsubmit 3,键盘事件3.…

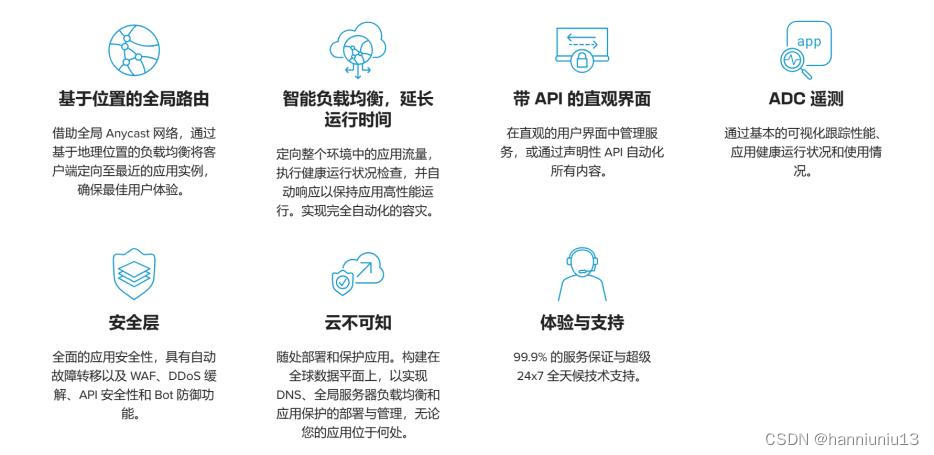
如何确保云中高可用?聊聊F5分布式云DNS负载均衡
在当今以应用为中心的动态化市场中,企业面临着越来越大的压力,不仅需要提供客户所期望的信息、服务和体验,而且要做到快速、可靠和安全。DNS是网络基础设施的重要组成部分,拥有一个可用的、智能的、安全和可扩展的DNS基础设施是至…

面试高频算法专题:数组的双指针思想及应用(算法村第三关白银挑战)
所谓的双指针其实就是两个变量,不一定真的是指针。
快慢指针:一起向前走对撞指针、相向指针:从两头向中间走背向指针:从中间向两头走
移除值为val的元素
题目描述
27. 移除元素 - 力扣(LeetCode)
给你…
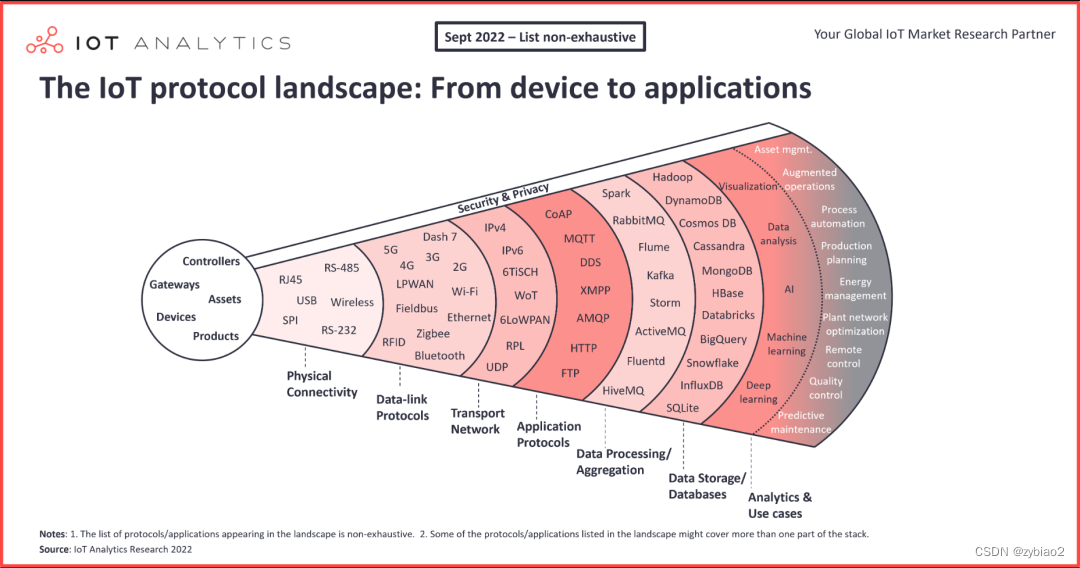
IoT 物联网常用协议
物联网协议是指在物联网环境中用于设备间通信和数据传输的协议。根据不同的作用,物联网协议可分为传输协议、通信协议和行业协议。 传输协议:一般负责子网内设备间的组网及通信。例如 Wi-Fi、Ethernet、NFC、 Zigbee、Bluetooth、GPRS、3G/4G/5G等。这些…
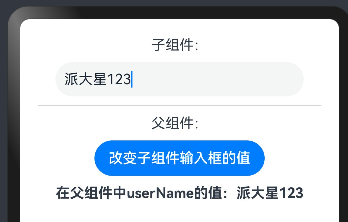
ArkTS - @Prop、@Link
一、作用
Prop 装饰器 和Link装饰器都是父组件向子组件传递参数,子组件接收父组件参数的时候用的,变量前边需要加上Prop或者Link装饰器即可。(跟前端vue中父组件向子组件传递参数类似)
// 子组件
Component
struct SonCom {Prop…
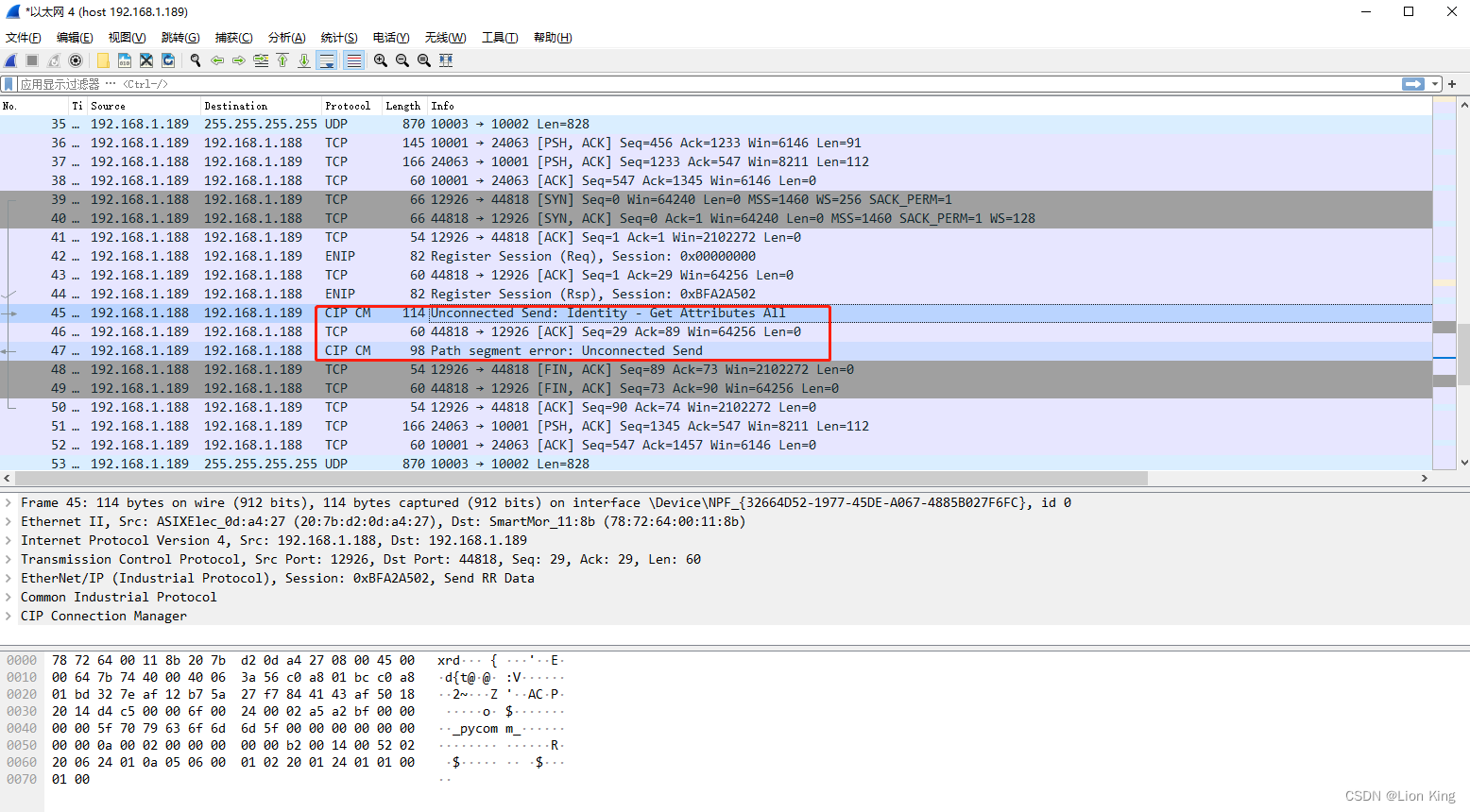
python实现Ethernet/IP协议的客户端(二)
Ethernet/IP是一种工业自动化领域中常用的网络通信协议,它是基于标准以太网技术的应用层协议。作为工业领域的通信协议之一,Ethernet/IP 提供了一种在工业自动化设备之间实现通信和数据交换的标准化方法。python要实现Ethernet/IP的客户端,可…
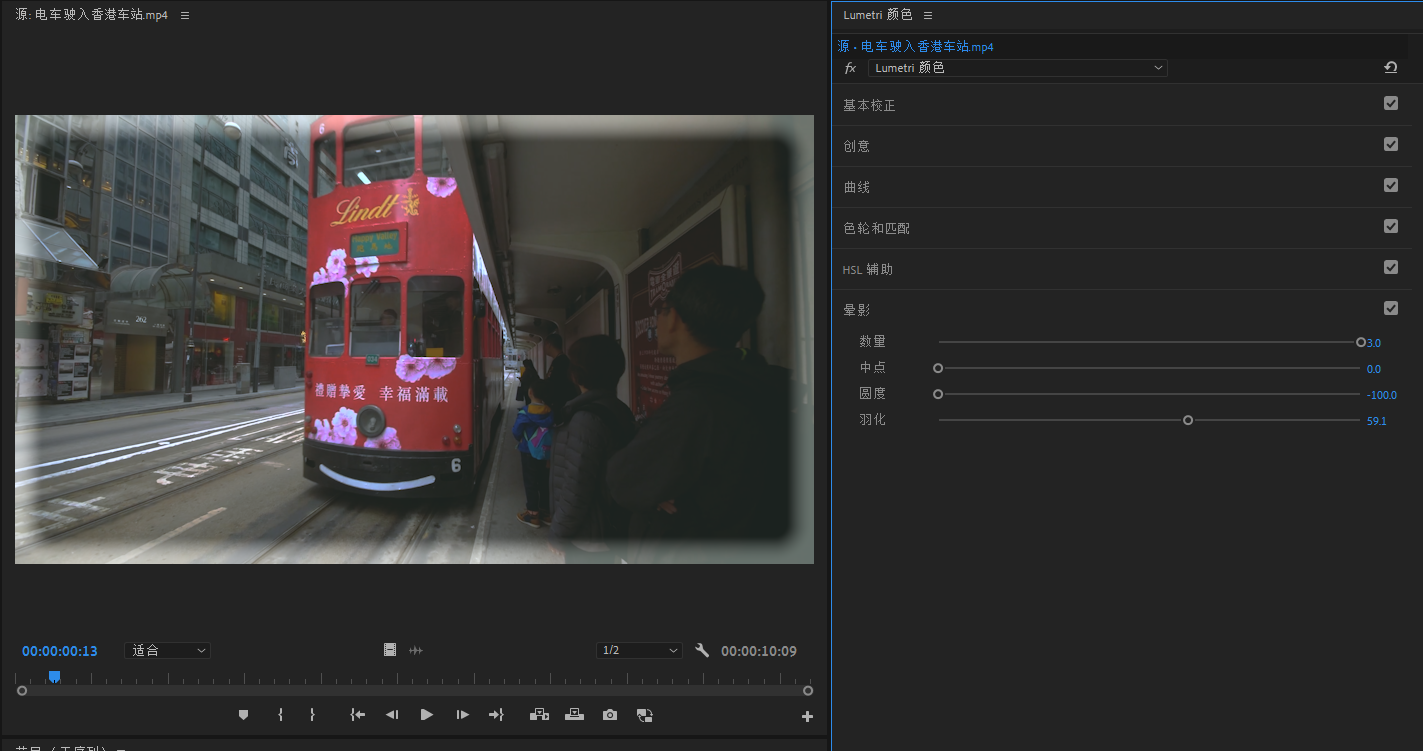
影视后期: PR调色处理,调色工具面板介绍
写在前面 整理一些影视后期的相关笔记博文为 Pr 调色处理,涉及调色工具面板简单认知包括 lumetri 颜色和范围面板理解不足小伙伴帮忙指正 元旦快乐哦 _ 名词解释 饱和度
是指色彩的鲜艳程度,也被称为色彩的纯度。具体来说,它表示色相中灰色…
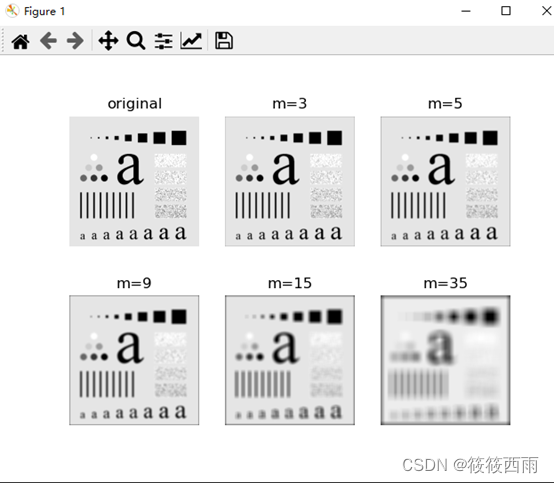
python实现平滑线性滤波器——数字图像处理
原理:
平滑线性滤波器是一种在图像处理中广泛使用的工具,主要用于降低图像噪声或模糊细节。这些滤波器的核心原理基于对图像中每个像素及其邻域像素的线性组合。
邻域平均: 平滑线性滤波器通过对目标像素及其周围邻域像素的强度值取平均来工…
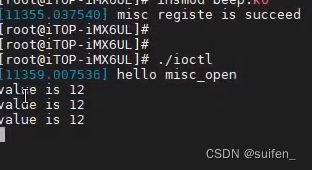
Linux驱动学习—ioctl接口
1、unlock_ioctl和ioctl有什么区别?
kernel 2.6.36 中已经完全删除了struct file_operations 中的ioctl 函数指针,取而代之的是unlocked_ioctl 。ioctl是老的内核版本中的驱动API,unlock_ioctl是当下常用的驱动API。unlocked_ioctl 实际上取…