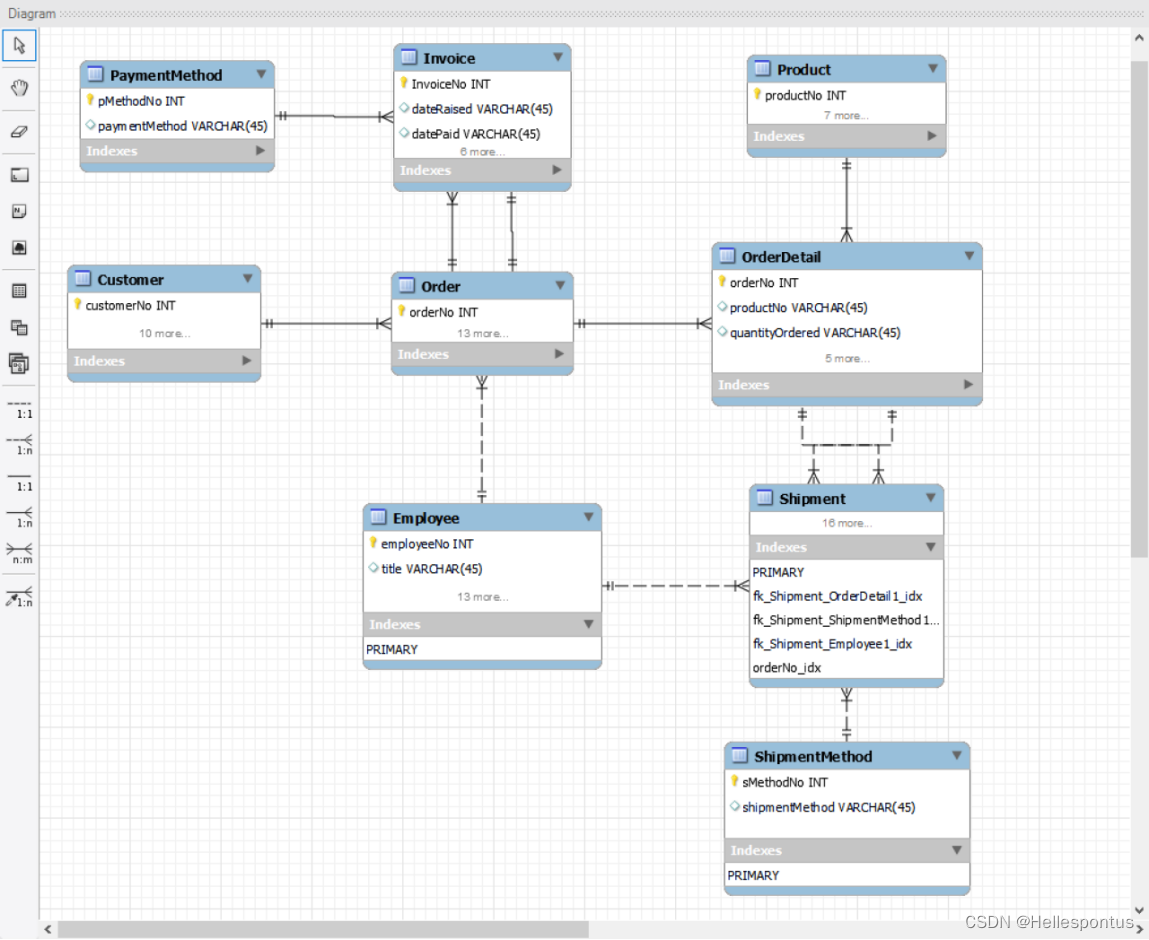
链表
链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指向下一个节点)。通过节点之间的指针连接,形成一个链式结构。
链表可以分为单向链表和双向链表两种类型。在单向链表中,每个节点只有一个指针,指向下一个节点;而在双向链表中,每个节点有两个指针,分别指向前一个节点和后一个节点。
链表的优点是插入和删除操作的时间复杂度为O(1),而不受数据规模的影响。但是,访问链表中的特定元素需要从头开始遍历链表,时间复杂度为O(n),其中n是链表的长度。
链表在实际应用中有广泛的用途,比如实现栈、队列、哈希表等数据结构,以及解决一些特定的问题,如反转链表、合并有序链表等。
需要注意的是,在使用链表时,我们需要额外的空间来存储指针,因此链表对内存的利用率较低。同时,在频繁插入和删除操作较多,而对访问操作要求不高的情况下,链表是一个较为合适的选择。

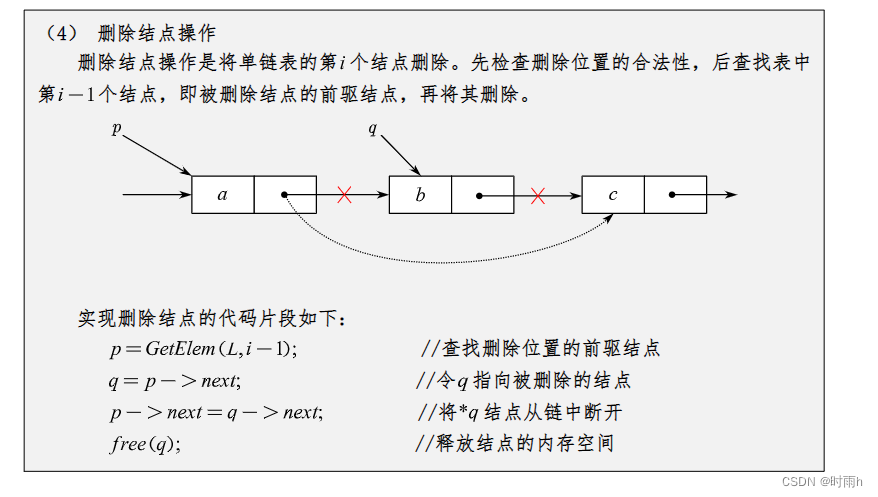
单链表(Singly Linked List)是一种常见的链表结构,由一系列节点按顺序连接而成。每个节点包含两个部分:数据域(存储元素值)和指针域(指向下一个节点)。最后一个节点的指针域指向空(NULL)。
以下是单链表的基本结构:
Node:
- 数据域(Data): 存储元素值
- 指针域(Next): 指向下一个节点
LinkedList:
- 头指针(Head): 指向链表的第一个节点
单链表的头指针(Head)用于标识链表的起始位置。通过头指针,可以遍历整个链表,或者在链表中插入、删除节点。
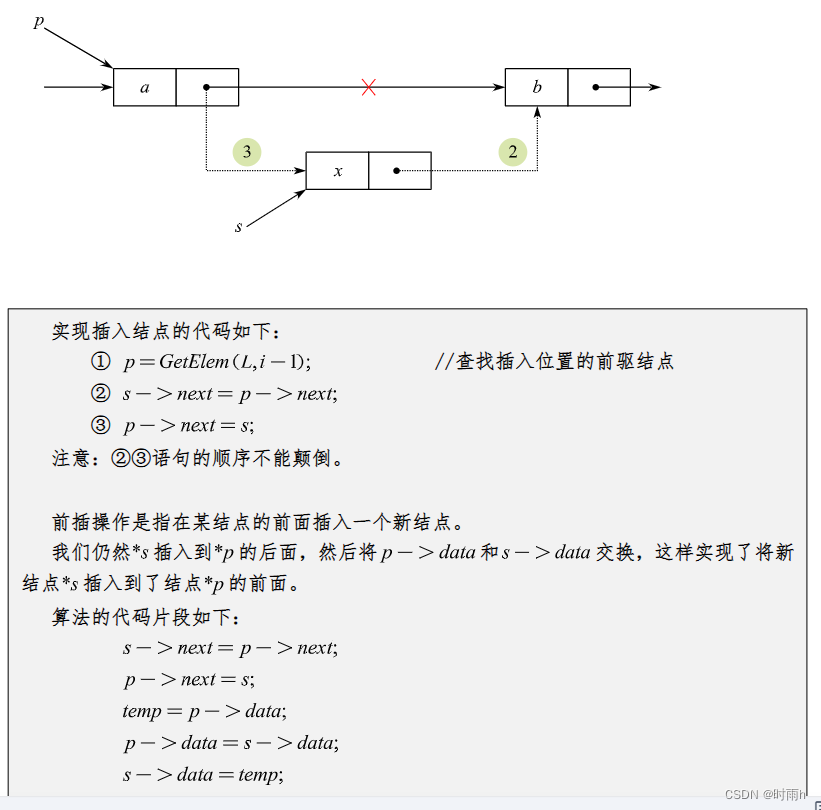
单链表的特点是每个节点只有一个指针域,指向下一个节点,最后一个节点的指针域为空。这意味着,在单链表中,只能从前往后遍历,无法直接访问前一个节点,因此对于某些操作,比如在给定节点之前插入一个新节点,需要额外的操作来处理指针。
需要注意的是,单链表中的节点可以动态地分配内存,这意味着可以根据需求灵活地扩展或缩小链表的长度。
下面是一个示例单链表的结构:
Head -> Node1 -> Node2 -> Node3 -> ... -> NULL
其中,Head是头指针,Node1、Node2、Node3等为节点,箭头表示指针域的指向关系,NULL表示链表的结束。
单链表的操作包括插入节点、删除节点、查找节点、遍历链表等,这些操作可以根据具体需求进行实现。

题1.若线性表采用链式存储,则表中各元素的存储地址()。
A.必须是连续的
B.部分地址是连续的
C.一定是不连续的
D.不一定是连续的
答案:D
题2.单链表中,增加一个头结点的目的是为了()。
A.使单链表至少有一个结点
B.标识表结点中首结点的位置
C.方便运算的实现
D.说明单链表是线性表的链式存储
答案:C
题1的答案是D. 不一定是连续的。
如果线性表采用链式存储方式,表中各元素的存储地址不需要连续。链式存储通过节点之间的指针连接,每个节点可以分配在内存的任意位置。节点的指针域存储着下一个节点的地址,通过指针的链接,实现了元素之间的逻辑关系。
题2的答案是C. 方便运算的实现。
增加一个头结点的目的是为了方便对单链表进行操作和实现一些常用的操作,如插入、删除、查找等。头结点不存储具体的数据,它的存在主要是为了简化操作,使得对链表的操作更加统一和方便。头结点可以作为操作的起点,避免了对空链表的特殊处理,提高了代码的可读性和可维护性。
引入头结点后,可以带来两个优点:
①由于第一个数据结点的位置被存放在头结点的指针域中,所以在链表的第一个位置上的操作和在表的其他位置上的操作一致,无需进行特殊处理。
②无论链表是否为空,其头指针都指向头结点的非空指针(空表中头结点的指针域为空)。
单链表的实现
以下是单链表的详细实现示例(使用C语言):
- 定义节点结构(Node):
struct Node {
int data;
struct Node *next;
};
- 定义链表结构(LinkedList):
struct LinkedList {
struct Node *head;
};
- 实现插入操作:
void insert(struct LinkedList *list, int data) {
struct Node *new_node = (struct Node *)malloc(sizeof(struct Node)); // 创建新节点
new_node->data = data;
new_node->next = NULL;
if (list->head == NULL) { // 如果链表为空,将新节点设为头节点
list->head = new_node;
} else {
struct Node *current = list->head;
while (current->next != NULL) { // 遍历到最后一个节点
current = current->next;
}
current->next = new_node; // 将新节点插入在最后一个节点之后
}
}
- 实现删除操作:
void delete(struct LinkedList *list, int target) {
if (list->head == NULL) { // 如果链表为空,无法删除
return;
}
if (list->head->data == target) { // 如果要删除的节点是头节点
struct Node *temp = list->head;
list->head = list->head->next;
free(temp);
} else {
struct Node *current = list->head;
while (current->next != NULL && current->next->data != target) { // 查找要删除节点的前一个节点
current = current->next;
}
if (current->next != NULL) { // 找到要删除的节点
struct Node *temp = current->next;
current->next = current->next->next;
free(temp);
}
}
}
- 实现查找操作:
int search(struct LinkedList *list, int target) {
struct Node *current = list->head;
while (current != NULL) {
if (current->data == target) { // 找到匹配的节点
return 1;
}
current = current->next;
}
return 0; // 遍历完链表未找到匹配的节点
}
- 实现遍历操作:
void traverse(struct LinkedList *list) {
struct Node *current = list->head;
while (current != NULL) {
printf("%d ", current->data); // 访问节点的数据域
current = current->next;
}
}
这是一个简单的单链表实现示例。由于C语言需要手动管理内存,因此在使用malloc函数分配内存时需要检查是否分配成功,并在删除节点时需要使用free函数释放内存。您可以根据这个示例进行自定义扩展和适应具体需求。



双链表

双链表(Doubly Linked List)是一种常见的数据结构,它与单链表相比,在每个节点中都有两个指针,分别指向前一个节点和后一个节点,因此可以实现双向遍历。这使得在双链表中插入、删除节点等操作更加高效。
下面是一个更详细的双链表的 C 代码实现:
#include <stdio.h>
#include <stdlib.h>
// 双链表节点结构
typedef struct Node {
int data;
struct Node* prev;
struct Node* next;
} Node;
// 创建新节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败\n");
exit(1);
}
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
// 在链表头部插入节点
void insertFront(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
newNode->next = *head;
(*head)->prev = newNode;
*head = newNode;
}
}
// 在链表末尾插入节点
void insertEnd(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
}
// 在指定位置插入节点
void insertAt(Node** head, int data, int position) {
if (position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
insertFront(head, data);
return;
}
Node* newNode = createNode(data);
Node* curr = *head;
int count = 1;
while (count < position - 1 && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
newNode->next = curr->next;
newNode->prev = curr;
if (curr->next != NULL) {
curr->next->prev = newNode;
}
curr->next = newNode;
}
// 删除链表头部节点
void deleteFront(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* temp = *head;
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
}
// 删除链表末尾节点
void deleteEnd(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
if (curr->prev != NULL) {
curr->prev->next = NULL;
} else {
*head = NULL;
}
free(curr);
}
// 删除指定位置节点
void deleteAt(Node** head, int position) {
if (*head == NULL || position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
deleteFront(head);
return;
}
Node* curr = *head;
int count = 1;
while (count < position && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
if (curr->prev != NULL) {
curr->prev->next = curr->next;
} else {
*head = curr->next;
}
if (curr->next != NULL) {
curr->next->prev = curr->prev;
}
free(curr);
}
// 打印链表
void printList(Node* head) {
Node* curr = head;
while (curr != NULL) {
printf("%d ", curr->data);
curr = curr->next;
}
printf("\n");
}
int main() {
Node* head = NULL;
// 插入节点
insertFront(&head, 1);
insertEnd(&head, 2);
insertEnd(&head, 3);
insertAt(&head, 4, 2);
// 打印链表
printf("双链表:");
printList(head);
// 删除节点
deleteFront(&head);
deleteEnd(&head);
deleteAt(&head, 1);
// 打印链表
printf("删除节点后的双链表:");
printList(head);
return 0;
}
这段代码实现了双链表的创建节点、在链表头部、末尾和指定位置插入节点,以及删除链表头部、末尾和指定位置节点,并且可以打印链表。你可以根据自己的需求进行扩展和修改。
双链表的插入操作
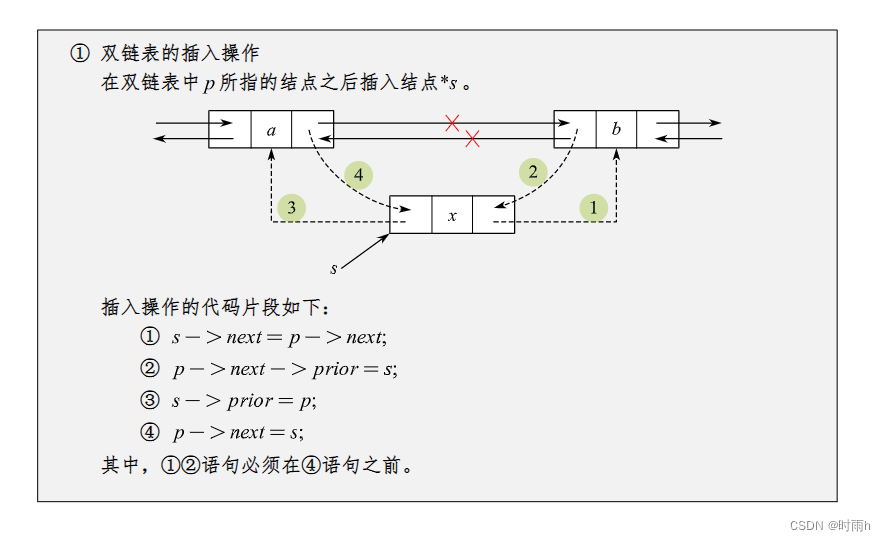
双链表的插入操作有三种情况:
- 在链表头部插入节点
- 在链表末尾插入节点
- 在指定位置插入节点
下面是这三种情况的详细说明和代码实现。
- 在链表头部插入节点
在链表头部插入节点,只需要将新节点插入到原头节点前面,并更新头节点的指针。
void insertFront(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
newNode->next = *head;
(*head)->prev = newNode;
*head = newNode;
}
}
- 在链表末尾插入节点
在链表末尾插入节点,需要遍历整个链表,找到最后一个节点,并将新节点插入到最后一个节点后面。
void insertEnd(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
}
- 在指定位置插入节点
在指定位置插入节点,需要遍历链表,找到指定位置的节点,并将新节点插入到该节点的前面,并更新相邻节点的指针。
void insertAt(Node** head, int data, int position) {
if (position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
insertFront(head, data);
return;
}
Node* newNode = createNode(data);
Node* curr = *head;
int count = 1;
while (count < position - 1 && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
newNode->next = curr->next;
newNode->prev = curr;
if (curr->next != NULL) {
curr->next->prev = newNode;
}
curr->next = newNode;
}
注意,如果指定位置为1,则直接调用insertFront()函数插入节点。如果指定位置大于链表长度,则插入失败,输出错误信息。
上述代码中,createNode()函数创建一个新节点,Node** head表示指向头节点指针的指针,因为在插入操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
双链表的删除操作
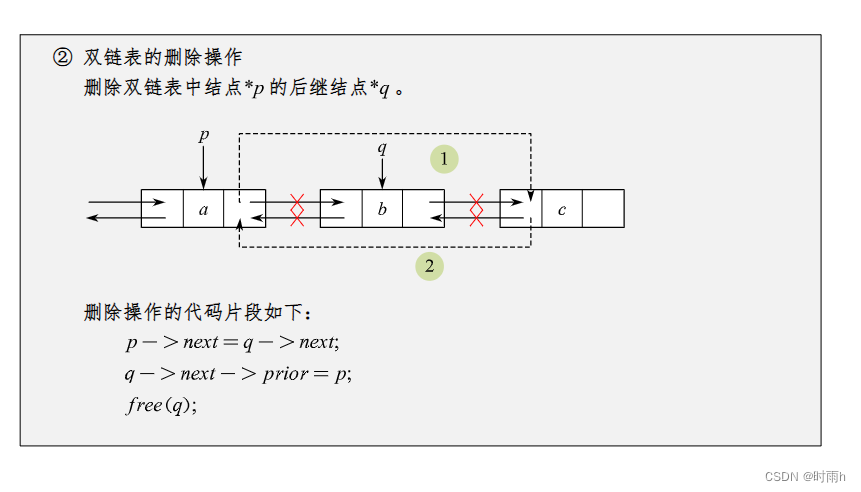
双链表的删除操作有三种情况:
- 删除链表头部节点
- 删除链表末尾节点
- 删除指定位置节点
下面是这三种情况的详细说明和代码实现。
- 删除链表头部节点
删除链表头部节点,只需要将头节点的下一个节点作为新的头节点,并释放原头节点的内存。
void deleteFront(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* temp = *head;
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
}
- 删除链表末尾节点
删除链表末尾节点,需要遍历整个链表,找到最后一个节点,并将倒数第二个节点的next指针置为NULL,并释放最后一个节点的内存。
void deleteEnd(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
if (curr->prev != NULL) {
curr->prev->next = NULL;
} else {
*head = NULL;
}
free(curr);
}
- 删除指定位置节点
删除指定位置节点,需要遍历链表,找到指定位置的节点,更新相邻节点的指针,并释放目标节点的内存。
void deleteAt(Node** head, int position) {
if (*head == NULL || position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
deleteFront(head);
return;
}
Node* curr = *head;
int count = 1;
while (count < position && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
if (curr->prev != NULL) {
curr->prev->next = curr->next;
} else {
*head = curr->next;
}
if (curr->next != NULL) {
curr->next->prev = curr->prev;
}
free(curr);
}
注意,如果指定位置为1,则直接调用deleteFront()函数删除头部节点。如果指定位置大于链表长度,则删除失败,输出错误信息。
上述代码中,Node** head表示指向头节点指针的指针,因为在删除操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
循环链表
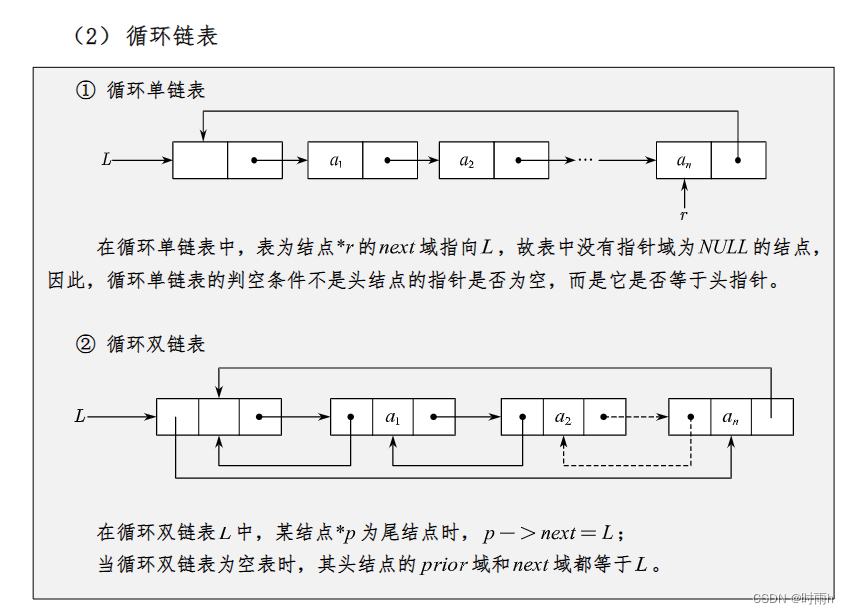
循环链表是一种特殊的链表,它与普通链表的区别在于,最后一个节点的next指针不是指向NULL,而是指向第一个节点,从而形成一个环形结构。
循环链表有两种基本类型:单向循环链表和双向循环链表。单向循环链表中每个节点只有一个指针域,即指向下一个节点的指针,而双向循环链表中每个节点有两个指针域,即分别指向前一个节点和后一个节点的指针。
下面是一个单向循环链表的定义:
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct CircularLinkedList {
Node* head;
} CircularLinkedList;
在单向循环链表中,头节点的next指针指向第一个节点,而最后一个节点的next指针则指向头节点。
循环链表的插入和删除操作与普通链表类似,唯一的区别是在插入和删除末尾节点时需要特殊处理,因为末尾节点的next指针指向头节点而非NULL。
下面是一个简单的单向循环链表的插入和删除操作的示例代码:
// 创建新节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在链表末尾插入节点
void insertEnd(CircularLinkedList* list, int data) {
Node* newNode = createNode(data);
if (list->head == NULL) {
list->head = newNode;
newNode->next = list->head;
} else {
Node* curr = list->head;
while (curr->next != list->head) {
curr = curr->next;
}
curr->next = newNode;
newNode->next = list->head;
}
}
// 删除指定位置的节点
void deleteAt(CircularLinkedList* list, int position) {
if (list->head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = list->head;
Node* prev = NULL;
int count = 1;
while (count < position && curr->next != list->head) {
prev = curr;
curr = curr->next;
count++;
}
if (count < position) {
printf("无效的位置\n");
return;
}
if (prev == NULL) {
Node* tail = list->head;
while (tail->next != list->head) {
tail = tail->next;
}
list->head = curr->next;
tail->next = list->head;
} else {
prev->next = curr->next;
}
free(curr);
}
注意,上述代码中,在删除末尾节点时需要特判。如果目标节点是头节点,则需要更新头节点指针的值,并将最后一个节点的next指针指向新的头节点。如果目标节点不是头节点,则直接更新相邻节点的指针即可。
循环链表的遍历和其他操作与普通链表类似,只需要判断是否回到了头节点即可。