PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
4. PanGu-Draw
4.1 时间解耦训练策略
4.2 Coop-Diffusion: 多扩散融合
5. 实验
S. 总结
S.1 主要贡献
S.2 方法
0. 摘要
目前的大规模扩散模型代表了有条件图像合成的一大进步,能够解释各种线索,如文本、人体姿势和边缘。然而,它们对大量计算资源和广泛数据收集的依赖仍然是一个瓶颈。另一方面,整合现有的扩散模型,每个模型专门用于不同的控制,并在独特的潜在空间中运行,由于图像分辨率和潜在空间嵌入结构不兼容,使它们共同使用变得具有挑战性。为了解决这些约束,我们提出了 “PanGu-Draw”,这是一个为资源高效的文本到图像合成设计的新颖的潜在扩散模型,能够灵活地适应多个控制信号。首先,我们提出了一种资源高效的 “时间解耦训练策略”,该策略将整体的文本到图像模型分为结构和纹理生成器。每个生成器都使用一种方案进行训练,该方案最大限度地利用数据并提高计算效率,将数据准备减少了 48%,并将训练资源减少了 51%。其次,我们引入了“Coop-Diffusion”,这是一种算法,能够在统一的去噪过程中协同使用具有不同潜在空间和预定义分辨率的各种预训练扩散模型。这允许在任意分辨率下进行多控制图像合成,而无需额外的数据或重新训练。Pangu-Draw 的实证验证展示了它在文本到图像和多控制图像生成方面的卓越能力,为未来模型训练效率和生成多样性提供了有希望的方向。最大的 5B T2I PanGu-Draw 模型已在Ascend 平台上发布。项目页面:https://pangu-draw.github.io

4. PanGu-Draw
4.1 时间解耦训练策略
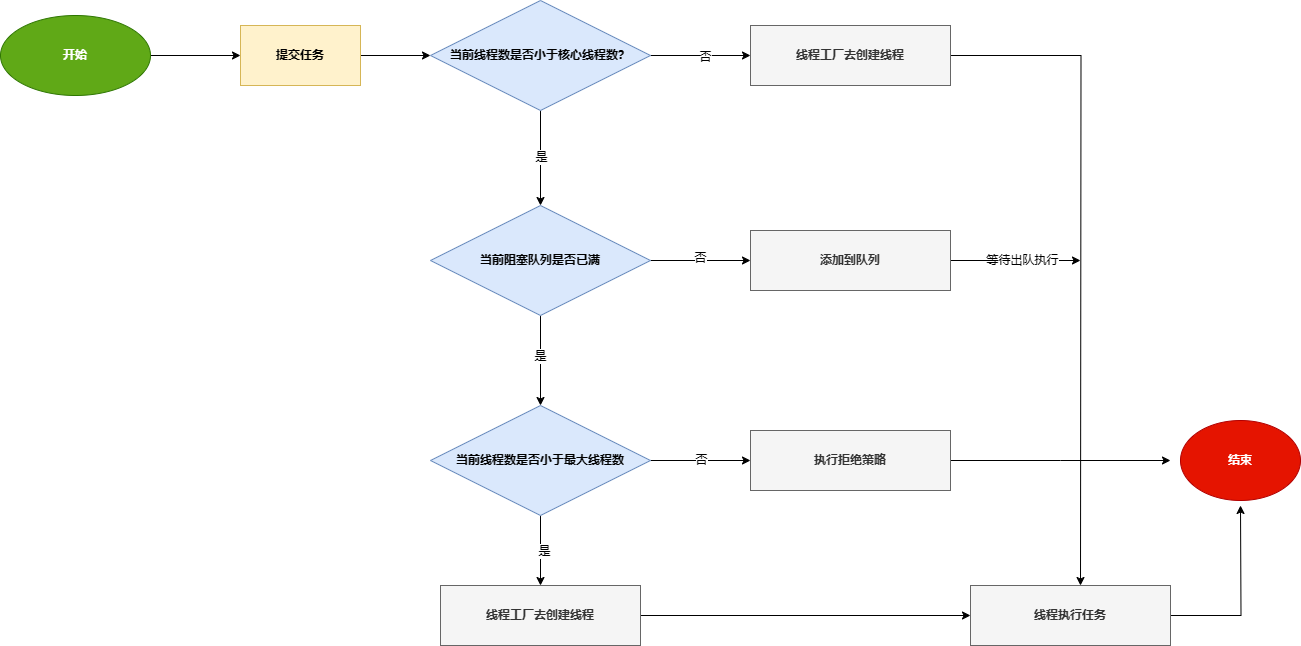
提高文本到图像模型的数据、训练和推断效率对于其实际应用至关重要。图 1 显示了两种现有的训练策略:(a) 级联训练,使用三个模型逐步提高分辨率,具有高效的数据利用率,但会使训练和推断时间增加三倍。 (b) 分辨率提升训练从 512x512 开始,然后提高到 1024x1024 分辨率,丢弃较低分辨率的数据,并在所有时间步骤上提供单模型推断,具有适度的效率,但训练成本更高。这些方法与我们的时间解耦策略有所不同,如下所述。
为了提高效率,我们从扩散过程的去噪轨迹中汲取灵感,其中初始去噪阶段主要塑造图像的结构基础,而后期阶段则精炼其纹理复杂性。有了这个见解,我们引入了时间解耦训练策略。该方法将全面的文本到图像模型表示为 ϵ_θ,分为两个在不同时间间隔内运行的专业子模型:结构生成器 ϵ_struct 和纹理生成器 ϵ_texture。每个子模型的大小是原始模型的一半,从而增强了可管理性并减轻了计算负担。
如图 1(c) 所示,结构生成器 ϵ_struct 负责较大时间步骤进行早期去噪,特别是在 T, ..., T_struct 范围内,其中 0 < Tstruct < T。该阶段专注于建立图像的基本轮廓。相反,纹理生成器 ϵ_texture 在后来的较小时间步骤中运行,由 T_struct, ..., 0 表示,以详细生成纹理细节。每个生成器都在隔离环境中进行训练,这不仅减轻了对高内存计算设备的需求,还避免了与模型分片及其伴随的机器间通信开销相关的复杂性。
在推断阶段,ϵ_struct 首先从初始随机噪声向量 z_T 构建基本结构图像 z_(T_struct)。随后, ϵ_texture 通过精练基本图像来增强纹理细节,最终产生最终输出 z_0。这种顺序处理促使了更加资源高效的工作流程,显著减少了硬件占用,并在不损害模型性能或输出质量的情况下加快了生成过程,正如我们在第 5.3 节的实验证明的那样。
资源高效的专门训练制度。我们进一步采用了上述两个模型的专门训练设计。从文本中导出图像结构的结构生成器 ϵ_struct 需要在涵盖广泛概念的大量数据集上进行训练。传统方法,如稳定扩散,通常会消除低分辨率图像,丢弃约 48% 的训练数据,从而增加数据集成本。相反,我们将高分辨率图像与放大的低分辨率图像结合在一起。正如我们在第 5.3 节的实验中证明的那样,这种方法没有性能下降,因为预测的 z_(T_struct) 仍然包含大量噪噪声。通过这种方式,我们实现了更高的数据效率,并避免了语义退化的问题。
此外,由于图像结构在 z_(T_struct) 中确定,而纹理生成器 ϵ_texture 专注于细化纹理,我们建议在较低分辨率下训练 ϵ_texture,同时仍以高分辨率进行采样。如我们在第 5.3 节的实验中所示,这种策略不会导致性能下降,也不会出现结构问题(例如,重复呈现 [21])。因此,我们在训练效率方面取得了总体 51% 的改进。图 1 总结了不同训练策略的数据、训练和推断效率。除了更高的数据和训练效率外,我们的策略还在推断效率方面取得了更高的成就,与级联训练策略相比,推断步骤更少,与分辨率提升训练策略相比,每步模型更小。.
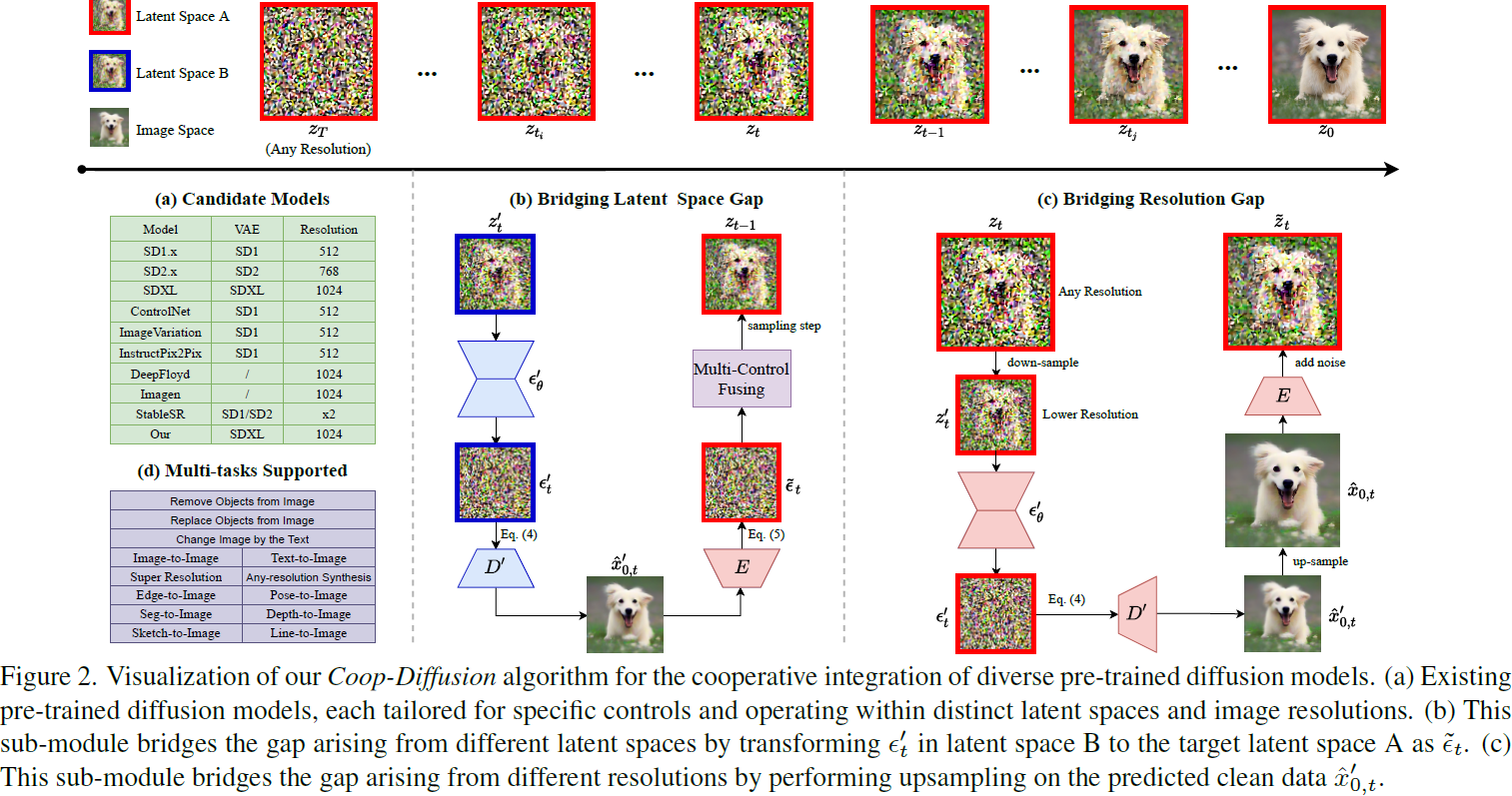
4.2 Coop-Diffusion: 多扩散融合
如图 2(a) 所示,存在许多预训练的扩散模型,如各种 SD、ControlNet、图像变化等,每个模型都专为特定的控制和图像分辨率而设计。将这些预训练模型融合起来,可以实现多控制或多分辨率图像生成,而无需训练新模型,这是具有潜力的。然而,这些模型具有不同的潜在空间和分辨率,妨碍了由不同模型控制的图像的联合合成,从而限制了它们的实际应用。为了应对这些挑战,我们提出了 Coop-Diffusion 算法,具有两个关键的子模块,如图 2(b) 和 (c) 所示,以弥合潜在空间差距和分辨率差距,并在相同空间中统一去噪过程。
弥合潜在空间差距。为了弥合空间 A 和 B 之间的潜在空间差距,我们提出通过使用图像空间作为中间步骤,将潜在空间 B 中的模型预测 ϵ′_t 转换为潜在空间 A 中的模型预测。具体做法如下:首先,我们预测干净数据 ˆz′_(0,t),如下所示:
![]()
其中,z'_t 是有噪潜在,ϵ′_t 是模型预测的噪声。然后,使用潜在解码器模型 D' 将 ˆz′_(0,t) 解码为像素级图像 ˆx'_(0,t)。使用图像编码器模型 E 将这个图像编码到潜在空间 A,即 ˜z_(0,t) = E(ˆx'_(0,t)),最后转换为模型预测,如下所示:

有了统一的 ˜ϵ_t,我们现在可以在 ˜ϵ_t 和 ϵ_t 之间执行多控制融合(其中 ϵ_t 是模型 ϵ_θ 使用潜在空间 A 中的 z_t 得到的预测,在图 2 中为简洁起见被省略)。具体而言,融合过程如下:
![]()
其中,d 和 1−d 是每个模型的引导强度,d ∈ [0, 1],用于共同引导两个模型的去噪过程,以进行多控制图像生成。算法 1 进一步说明了这个融合过程。


弥合分辨率差距。为了整合低分辨率模型和高分辨率模型的去噪过程,需要进行上采样和/或下采样。传统的双线性上采样通常应用于去噪过程中的中间结果 z_t,但可能放大像素相关性。这种放大偏离了最初的独立同分布(Independent and Identically Distributed,IID)假设,导致最终图像中出现严重的伪影,如图 3(a) 所示。相反,下采样不会出现这个问题。为了解决上采样中的 IID 问题,我们提出了一种新的上采样算法,保持 IID 假设,从而弥合不同预训练分辨率模型之间的分辨率差距。
图 2(c) 可视化了我们的上采样算法。具体而言,对于低分辨率的 z'_t,我们使用图像空间作为中间空间,将低分辨率空间中的 z'_t 转换为高分辨率空间中的 ˜z_t。我们首先使用去噪模型 ϵ'_θ 预测噪声 ϵ'_t,然后根据 Eq. 4 预测干净数据 ˆz'_(0,t),这通过解码器 D' 转换为图像 ˆx'0,t。然后,我们对 ˆx'_(0,t) 进行上采样,得到其高分辨率对应物 ˆx_(0,t)。最后,使用编码器 E 将 ˆx_(0,t) 编码到潜在空间,得到 ˆz_(0,t),然后添加 t 步噪声,最终得到高分辨率空间中的 ˜z_t。
有了统一的 ˜z_t,我们现在可以执行多分辨率融合。首先,我们使用低分辨率模型进行去噪,得到中间 z'_t 和其高分辨率对应物 ˜z_t。然后,我们使用高分辨率模型从 ˜z_t 开始进行去噪,反之亦然。这种方法使我们能够进行单阶段超分辨率,而无需进行所有低分辨率去噪步骤,从而提高推断效率。算法 1 进一步说明了这个融合过程。
5. 实验

在自动评估中,PanGu-Draw 表现突出。在人工评估中,PanGu-Draw 与最先进模型差异不大。

在多控制图像生成中,PanGu-Draw 表现良好。

在多分辨率图像生成中,PanGu-Draw 表现良好。

消融研究表明:时间解耦策略表现突出(图 4);仅使用低分辨率图像训练文本编码器不会造成性能退化(图 5);当去噪时间步 500 作为结构生成器和纹理生成器的分界点时,模型性能最好(图 6)。
S. 总结
S.1 主要贡献
本文提出了 “PanGu-Draw”,使用资源高效的 “时间解耦训练策略”,将文本到图像模型分为结构和纹理生成器,提高了数据利用率和计算效率。还引入了“Coop-Diffusion”,在统一的去噪过程中协同使用具有不同潜在空间和预定义分辨率的各种预训练扩散模型。这允许在任意分辨率下进行多控制图像合成,无需额外的数据或重新训练。
S.2 方法
本文使用的时间解耦策略如图 1c 所示:
- 该方法将文本到图像模型分为两个在不同时间间隔内运行的子模型:结构生成器和纹理生成器,每个子模型的大小是原始模型的一半。
- 结构生成器负责早期去噪,该阶段专注于建立图像的基本轮廓。
- 纹理生成器负责晚期去噪,以详细生成纹理细节。
- 结构生成器结合使用高分辨率图像与放大的低分辨率图像进行训练,提高了数据利用率。
- 由于图像结构在结构生成器中确定,而纹理生成器专注于细化纹理。可在较低分辨率下训练 纹理生成器,同时仍以高分辨率进行采样。实验结果表明,该方法不会导致性能下降,且可以提升训练效率。
Coop-Diffusion: 多扩散融合具有两个关键的子模块,以弥合潜在空间差距和分辨率差距,并在相同空间中统一去噪过程,如图 2 所示。
弥合潜在空间差距。为了弥合空间 A 和 B 之间的潜在空间差距,通过使用图像空间作为中间步骤,将潜在空间 B 中的噪声预测转换为潜在空间 A 中的噪声预测。如图 2b 所示。
- 基于潜在空间 B 中的噪声预测干净潜在
- 使用解码器把潜在转化为图像
- 使用图像编码器把图像转化为潜在空间 A 中的干净潜在
- 基于潜在空间 A 中有噪潜在和干净潜在,预测潜在空间 A 中的噪声
- 使用转化到 A 中的预测噪声和 A 中预测噪声的线性组合,来引导去噪过程
弥合分辨率差距。为整合低分辨率模型和高分辨率模型的去噪过程,需要进行上采样和/或下采样。传统的双线性上采样可能放大像素相关性,导致最终图像中出现严重的伪影。为解决这个问题,使用图像空间作为中间空间,将低分辨率空间中的潜在转换为高分辨率空间中的潜在。
- 使用去噪模型预测噪声,然后预测干净潜在
- 使用解码器把潜在转化为图像
- 对图像进行上采样,得到其高分辨率图像
- 使用编码器将高分辨率图像编码到潜在空间,然后添加 t 步噪声,最终得到高分辨率空间中的有噪潜在
- 然后可以执行多分辨率融合。首先,使用低分辨率模型进行去噪,得到中间潜在和其高分辨率对应物。然后,使用高分辨率模型从高分辨率潜在开始进行去噪
- 使用该方法可以进行单阶段超分辨率,而无需进行所有低分辨率去噪步骤,从而提升推断效率