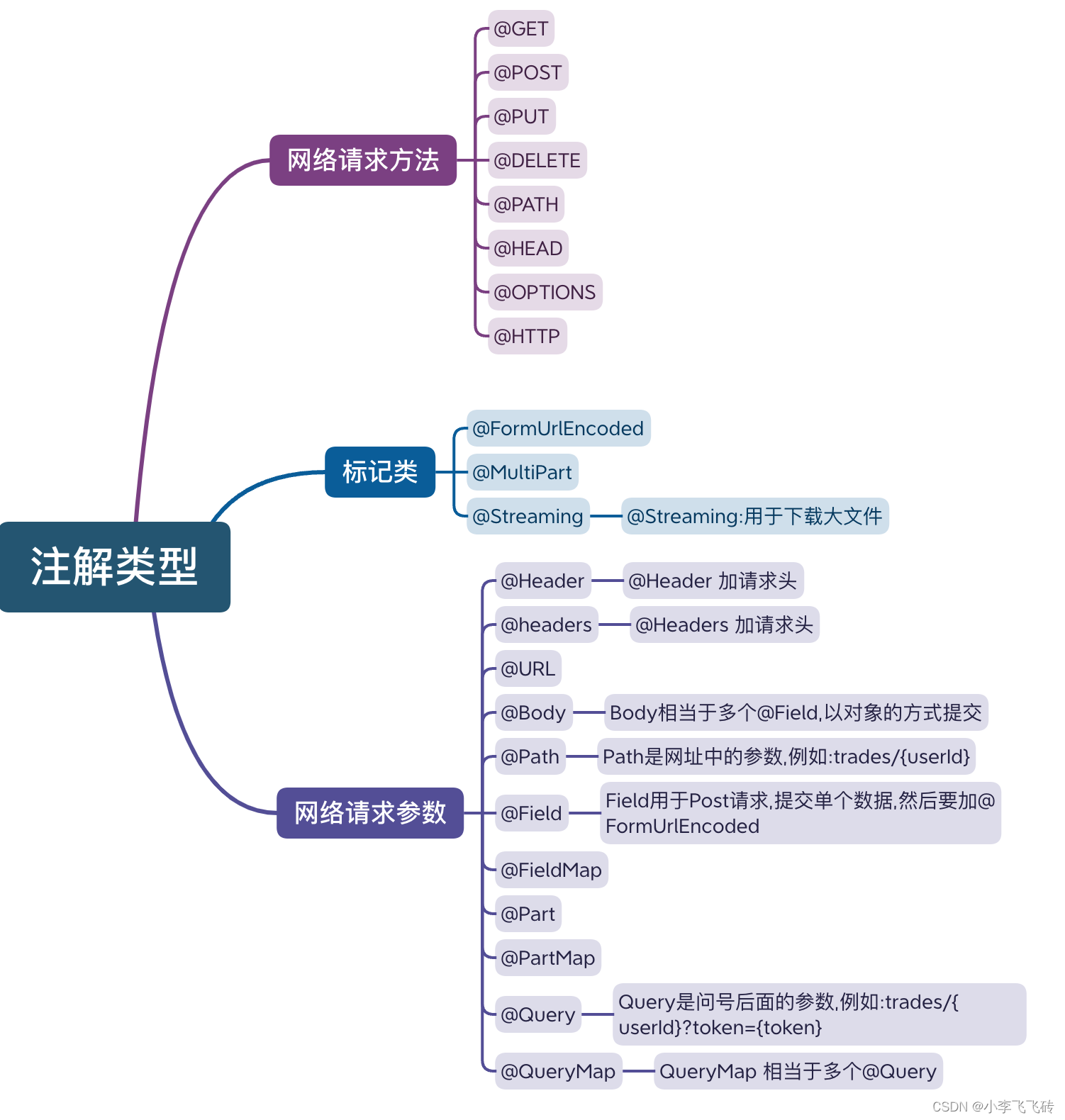
数学和PY
向量是同时拥有大小和方向的量。向量可以表示为排成一排的数字集合,在 Python 实现中可以处理为一维数组。
 向量和矩阵可以分别用一维数组和二维数组表示。另外,在矩阵中,将水平方向上的排列称为行(row),将垂直方向上的排列称为列(column)。将向量和矩阵扩展到 N 维的数据集合,就是张量。
向量和矩阵可以分别用一维数组和二维数组表示。另外,在矩阵中,将水平方向上的排列称为行(row),将垂直方向上的排列称为列(column)。将向量和矩阵扩展到 N 维的数据集合,就是张量。

在数学和深度学习等许多领域,向量一般作为列向量处理
>>> import numpy as np
>>> x = np.array([1, 2, 3])
>>> x.__class__ # 输出类名
<class 'numpy.ndarray'>
>>> x.shape
(3,)
>>> x.ndim
1
>>> W = np.array([[1, 2, 3], [4, 5, 6]])
>>> W.shape
(2, 3)
>>> W.ndim
2
可以使用 np.array() 方法生成向量或矩阵。该方法会生成NumPy 的多维数组类 np.ndarray
>>> W = np.array([[1, 2, 3], [4, 5, 6]])
>>> X = np.array([[0, 1, 2], [3, 4, 5]])
>>> W + X
array([[ 1, 3, 5],
[ 7, 9, 11]])
>>> W * X
array([[ 0, 2, 6],
[12, 20, 30]])
在 NumPy 多维数组中,形状不同的数组之间也可以进行运算
>>> A = np.array([[1, 2], [3, 4]])
>>> A * 10
array([[10, 20],
[30, 40]])
这个计算是一个 2 × 2 的矩阵 A 乘以标量 10。此时,如图 所示,标量 10 先被扩展为 2 × 2 的矩阵,之后进行对应元素的运算。这个灵巧的功能称为广播(broadcast)

因为 NumPy 有广播功能,所以可以智能地执行不同形状的数组之间的运算
向量内积可以表示为

向量内积是两个向量对应元素的乘积之和。
向量内积直观地表示了“两个向量在多大程度上指向同一方向”。如果限定向量的大小为 1,当两个向量完全指向同一方向时,它们的向量内积是 1。反之,如果两个向量方向相反,则内积为−1

# 向量内积
>>> a = np.array([1, 2, 3])
>>> b = np.array([4, 5, 6])
>>> np.dot(a, b)
32
# 矩阵乘积
>>> A = np.array([[1, 2], [3, 4]])
>>> B = np.array([[5, 6], [7, 8]])
>>> np.dot(A, B)
array([[19, 22],
[43, 50]])
当 np.dot(x, y)的参数都是一维数组时,计算向量内积。当参数都是二维数组时,计算矩阵乘积
在矩阵乘积中,要使对应维度的元素个数一致
神经网络
简单地说,神经网络就是一个函数。函数是将某些输入变换为某些输出的变换器,与此相同,神经网络也将输入变换为输出。
 用〇表示神经元,用箭头表示它们的连接。此时,在箭头上有权重,这个权重和对应的神经元的值分别相乘,其和(严格地讲,是经过激活函数变换后的值)作为下一个神经元的输入。另外,此时还要加上一个不受前一层的神经元影响的常数,这个常数称为偏置。因为所有相邻的神经元之间都存在由箭头表示的连接,所以图的神经网络称为全连接网络。
用〇表示神经元,用箭头表示它们的连接。此时,在箭头上有权重,这个权重和对应的神经元的值分别相乘,其和(严格地讲,是经过激活函数变换后的值)作为下一个神经元的输入。另外,此时还要加上一个不受前一层的神经元影响的常数,这个常数称为偏置。因为所有相邻的神经元之间都存在由箭头表示的连接,所以图的神经网络称为全连接网络。
这里用 (x1, x2) 表示输入层的数据,用 w11 和 w12 表示权重,用 b1 表示偏置。这样一来,图中的隐藏层的第 1 个神经元就可以如下进行计算
h1 = x1w11 + x2w21 + b1

隐藏层的神经元被整理为 (h1, h2, h3, h4),它可以看作 1 × 4 的矩阵(或者行向量)。另外,输入是 (x1, x2),这是一个 1 × 2 的矩阵。再者,权重是 2 × 4 的矩阵,偏置是 1 × 4 的矩阵。
 输入是 x,隐藏层的神经元是 h,权重是 W,偏置是 b,这些都是矩阵。
输入是 x,隐藏层的神经元是 h,权重是 W,偏置是 b,这些都是矩阵。
根据形状检查,可知各mini-batch被正确地进行了变换。此时,N 笔样本数据整体由全连接层进行变换,隐藏层的 N 个神经元被整体计算出来。用 Python 写出 mini-batch 版的全连接层变换。
>>> import numpy as np
>>> W1 = np.random.randn(2, 4) # 权重
>>> b1 = np.random.randn(4) # 偏置
>>> x = np.random.randn(10, 2) # 输入
>>> h = np.dot(x, W1) + b1
全连接层的变换是线性变换。激活函数赋予它“非线性”的效果。严格地讲,使用非线性的激活函数,可以增强神经网络的表现力。
sigmoid 函数呈 S 形曲线


sigmoid 函数接收任意大小的实数,输出 0 ~ 1 的实数。
>>>def sigmoid(x):
return 1 / (1 + np.exp(-x))
>>> a = sigmoid(h)
基于 sigmoid 函数,可以进行非线性变换。然后,再用另一个全连接层来变换这个激活函数的输出 a(也称为 activation)。这里,因为隐藏层有 4个神经元,输出层有 3 个神经元,所以全连接层使用的权重矩阵的形状必须设置为 4 × 3,这样就可以获得输出层的神经元。以上就是神经网络的推理。
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(10, 2)
W1 = np.random.randn(2, 4)
b1 = np.random.randn(4)
W2 = np.random.randn(4, 3)
b2 = np.random.randn(3)
h = np.dot(x, W1) + b1
a = sigmoid(h)
s = np.dot(a, W2) + b2
这里,x 的形状是 (10, 2),表示 10 笔二维数据组织为了 1 个 mini-batch。最终输出的 s 的形状是 (10, 3)。同样,这意味着 10 笔数据一起被处理了,每笔数据都被变换为了三维数据.
得分是计算概率之前的值。得分越高,这个神经元对应的类别的概率也越高。
将神经网络进行的处理实现为层。这里将全连接层的变换实现为 Affine 层,将 sigmoid 函数的变换实现为 Sigmoid 层。因为全连接层的变换相当于几何学领域的仿射变换,所以称为 Affine层。另外,将各个层实现为 Python 的类,将主要的变换实现为类的 forward() 方法。
- 所有的层都有 forward() 方法和 backward() 方法
- 所有的层都有 params 和 grads 实例变量
forward() 方法和 backward() 方法
分别对应正向传播和反向传播。其次,params 使用列表保存权重和偏置等参数(参数可能有多个,所以用列表保存)。grads 以与 params 中的参数对应的形式,使用列表保存各个参数的梯度
首先实现sigmoid层,实现为一个类。主 变 换 处 理 被 实 现 为forward(x) 方法。这里,因为 Sigmoid 层没有需要学习的参数,所以使用空列表来初始化实例变量 params。
import numpy as np
class Sigmoid:
def __init__(self):
self.params = []
def forward(self, x):
return 1 / (1 + np.exp(-x))
实现全连接层Affine层
class Affine:
def __init__(self, W, b):
self.params = [W, b]
def forward(self, x):
W, b = self.params
out = np.dot(x, W) + b
return out
Affine 层在初始化时接收权重和偏置。此时,Affine 层的参数是权重和偏置(在神经网络的学习时,这两个参数随时被更新)。因此,我们使用列表将这两个参数保存在实例变量 params 中。然后,实现基于 forward(x) 的正向传播的处理
现在,我们使用上面实现的层来实现神经网络的推理处理

输入 X 经由 Affine 层、Sigmoid 层和 Affine 层后输出得分 S。我们将这个神经网络实现为名为 TwoLayerNet 的类,将主推理处理实现为 predict(x) 方法
TwoLayerNet 的代码如下所示
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size):
I, H, O = input_size, hidden_size, output_size
# 初始化权重和偏置
W1 = np.random.randn(I, H)
b1 = np.random.randn(H)
W2 = np.random.randn(H, O)
b2 = np.random.randn(O)
# 生成层
self.layers = [
Affine(W1, b1),
Sigmoid(),
Affine(W2, b2)
]
# 将所有的权重整理到列表中
self.params = []
for layer in self.layers:
self.params += layer.params
def predict(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
在这个类的初始化方法中,首先对权重进行初始化,生成 3 个层。然后,将要学习的权重参数一起保存在 params 列表中。这里,因为各个层的实例变量 params 中都保存了学习参数,所以只需要将它们拼接起来即可。
这样一来,TwoLayerNet 的 params 变量中就保存了所有的学习参数。像这样,通过将参数整理到一个列表中,可以很轻松地进行参数的更新和保存。此外,Python 中可以使用 + 运算符进行列表之间的拼接。
>>> a = ['A', 'B']
>>> a += ['C', 'D']
>>> a
['A', 'B', 'C', 'D']
在上面的 TwoLayerNet的实现中,通过将各个层的 params 列表加起来,从而将全部学习参数整理到了一个列表中。
x = np.random.randn(10, 2)
model = TwoLayerNet(2, 4, 3)
s = model.predict(x)
这样就可以求出输入数据 x 的得分 s 了。像这样,通过将层实现为类,可以轻松实现神经网络。
损失函数
在神经网络的学习中,为了知道学习进行得如何,需要一个指标。这个指标通常称为损失(loss)。损失指示学习阶段中某个时间点的神经网络的性能。基于监督数据(学习阶段获得的正确解数据)和神经网络的预测结果,将模型的恶劣程度作为标量(单一数值)计算出来,得到的就是损失。计算神经网络的损失要使用损失函数(loss function)。进行多类别分类的神经网络通常使用交叉熵误差(cross entropy error)作为损失函数。此时,交叉熵误差由神经网络输出的各类别的概率和监督标签求得。
现在,我们来求一下之前一直在研究的那个神经网络的损失。这里,我们将 Softmax 层和 Cross Entropy Error 层新添加到网络中。用 Softmax 层求 Softmax 函数的值,用 Cross Entropy Error 层求交叉熵误差。

X 是输入数据,t 是监督标签,L 是损失。此时,Softmax层的输出是概率,该概率和监督标签被输入 Cross Entropy Error 层。
首先,Softmax函数可由下式表示:

是当输出总共有 n 个时,计算第 k 个输出 yk 时的算式。这个yk 是对应于第 k 个类别的 Softmax 函数的输出。如式 所示,Softmax函数的分子是得分 sk 的指数函数,分母是所有输入信号的指数函数的和。Softmax 函数输出的各个元素是 0.0 ~ 1.0 的实数。另外,如果将这些元素全部加起来,则和为 1。因此,Softmax 的输出可以解释为概率。之后,这个概率会被输入交叉熵误差
交叉熵误差可由下式表示:

tk 是对应于第 k 个类别的监督标签。log 是以纳皮尔数 e 为底的对数(严格地说,应该记为 log e)。监督标签以 one-hot 向量的形式表示,比如t = (0, 0, 1)。one-hot 向量是一个元素为 1,其他元素为 0 的向量。因为元素 1 对应正确解的类
另外,在考虑了 mini-batch 处理的情况下,交叉熵误差可以由下式表示:


其实只是将表示单笔数据的损失函数的式扩展到了 N 笔数据的情况。用式除以 N,可以求单笔数据的平均损失。通过这样的平均化,无论 mini-batch 的大小如何,都始终可以获得一致的指标

加法节点构成“复杂计算”的一部分

计算图的反向传播

加法节点的正向传播(左图)和反向传播(右图)
 乘法节点的正向传播(左图)和反向传播(右图)
乘法节点的正向传播(左图)和反向传播(右图)

流过节点的数据都是“单变量”。但是,不仅限于单变量,也可以是多变量(向量、矩阵或张量)。当张量流过加法节点(或者乘法节点)时,只需独立计算张量中的各个元素。也就是说在这种情况下,张量的各个元素独立于其他元素进行对应元素的运算。
分支节点的正向传播(左图)和反向传播(右图)

严格来说,分支节点并没有节点,只有两根分开的线。此时,相同的值被复制并分叉。因此,分支节点也称为复制节点。它的反向传播是上游传来的梯度之和。
分支节点有两个分支,但也可以扩展为 N 个分支(副本),这里称为Repeat 节点。

>>> import numpy as np
>>> D, N = 8, 7
>>> x = np.random.randn(1, D) # 输入
>>> y = np.repeat(x, N, axis=0) # 正向传播
>>> dy = np.random.randn(N, D) # 假设的梯度
>>> dx = np.sum(dy, axis=0, keepdims=True) # 反向传播
这里通过 np.repeat() 方法进行元素的复制。上面的例子中将复制 N 次数组 x。通过指定 axis,可以指定沿哪个轴复制。因为反向传播时要计算总和,所以使用 NumPy 的 sum() 方法。此时,通过指定 axis 来指定对哪个轴求和。另外,通过指定 keepdims=True,可以维持二维数组的维数。在上面的例子中,当 keepdims=True 时,np.sum() 的结果的形状是 (1, D);当keepdims=False 时,形状是 (D,)。
Sum 节点是通用的加法节点。这里考虑对一个 N × D 的数组沿第 0 个轴求和。此时,Sum 节点的正向传播和反向传播如图

>>> import numpy as np
>>> D, N = 8, 7
>>> x = np.random.randn(N, D) # 输入
>>> y = np.sum(x, axis=0, keepdims=True) # 正向传播
>>> dy = np.random.randn(1, D) # 假设的梯度
>>> dx = np.repeat(dy, N, axis=0) # 反向传播
Sum 节点的正向传播通过 np.sum() 方法实现,反向传播通过 np.repeat() 方法实现。有趣的是,Sum 节点和 Repeat 节点存在逆向关系。所谓逆向关系,是指 Sum 节点的正向传播相当于 Repeat 节点的反向传播,Sum 节点的反向传播相当于 Repeat 节点的正向传播。
将矩阵乘积称为 MatMul 节点。MatMul 是 Matrix Multiply 的缩写。 MatMul节点的正向传播:矩阵的形状显示在各个变量的上方






通过确认矩阵形状,推导反向传播的数学式

class MatMul:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.x = None
def forward(self, x):
W, = self.params
out = np.dot(x, W)
self.x = x
return out
def backward(self, dout):
W, = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
self.grads[0][...] = dW
return dx
MatMul 层在 params 中保存要学习的参数。另外,以与其对应的形式,将梯度保存在 grads 中。在反向传播时求 dx 和 dw,并在实例变量 grads 中设置权重的梯度。
另外,在设置梯度的值时,像 grads[0][…] = dW 这样,使用了省略号。
由此,可以固定 NumPy 数组的内存地址,覆盖 NumPy 数组的元素。
>>> a = np.array([1, 2, 3])
>>> b = np.array([4, 5, 6])
不管是 a = b,还是 a[…] = b,a 都被赋值 [4,5,6]。但是,此时 a 指向的内存地址不同。我们将内存(简化版)可视化

在 a = b 的情况下,a 指向的内存地址和 b 一样。由于实际的数据(4,5,6)没有被复制,所以这可以说是浅复制。而在 a[…] = b时,a 的内存地址保持不变,b 的元素被复制到 a 指向的内存上。这时,因为实际的数据被复制了,所以称为深复制。由此可知,使用省略号可以固定变量的内存地址
在 grads 列表中保存各个参数的梯度。此时,grads 列表中的各个元素是 NumPy 数组,仅在生成层时生成一次。然后,使用省略号,在不改变 NumPy 数组的内存地址的情况下覆盖数据。这样一来,将梯度汇总在一起的工作就只需要在开始时进行一次即可。
以上就是 MatMul 层的实现



class Sigmoid:
def __init__(self):
self.params, self.grads = [], []
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
将正向传播的输出保存在实例变量 out 中。然后,在反向传播中,使用这个 out 变量进行计算。
通过 MatMul 节点进行矩阵乘积的计算。偏置被 Repeat节点复制,然后进行加法运算(可以认为 NumPy 的广播功能在内部进行了Repeat 节点的计算)。下面是 Affine 层的实现

class Affine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
W, b = self.params
out = np.dot(x, W) + b
self.x = x
return out
def backward(self, dout):
W, b = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
db = np.sum(dout, axis=0)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
Affine 层将参数保存在实例变量 params 中,将梯度保存在实例变量 grads 中。它的反向传播可以通过执行 MatMul 节点和Repeat 节点的反向传播来实现。Repeat 节点的反向传播可以通过 np.sum()计算出来,注意矩阵的形状,就可以清楚地知道应该对哪个轴(axis)求和。最后,将权重参数的梯度设置给实例变量 grads。以上就是 Affine 层的实现
将 Softmax 函数和交叉熵误差一起实现为 Softmax with Loss 层。

通过误差反向传播法求出梯度后,就可以使用该梯度更新神经网络的参数。此时,神经网络的学习按如下步骤进行
• 步骤 1:mini-batch
从训练数据中随机选出多笔数据。
• 步骤 2:计算梯度
基于误差反向传播法,计算损失函数关于各个权重参数的梯度。
• 步骤 3:更新参数
使用梯度更新权重参数。
• 步骤 4:重复
根据需要重复多次步骤 1、步骤 2 和步骤 3。按照上面的步骤进行神经网络的学习。首先,选择 mini-batch 数据,根据误差反向传播法获得权重的梯度。这个梯度指向当前的权重参数所处位置中损失增加最多的方向。因此,通过将参数向该梯度的反方向更新,可以降低损失。这就是梯度下降法(gradient descent)。
权重更新方法有很多,这里实现其中最简单的随机梯度下降法(Stochastic Gradient Descent,SGD)。其中,“随机”是指使用随机选择的数据(mini-batch)的梯度。
SGD 是一个很简单的方法。它将(当前的)权重朝梯度的(反)方向更新一定距离。如果用数学式表示,则有:

进行参数更新的类的实现拥有通用方法 update(params, grads)。这里,在参数 params 和 grads 中分别以列表形式保存了神经网络的权重和梯度。此外,假定 params 和 grads 在相同索引处分别保存了对应的参数和梯度。这样一来,SGD 就可以像下面这样实现
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for i in range(len(params)):
params[i] -= self.lr * grads[i]
初始化参数 lr 表示学习率(learning rate)。这里将学习率保存为实例变量。然后,在 update(params, grads) 方法中实现参数的更新处理。使用这个 SGD 类,神经网络的参数更新可按如下方式进行
model = TwoLayerNet(...)
optimizer = SGD()
for i in range(10000):
...
x_batch, t_batch = get_mini_batch(...) # 获取mini-batch
loss = model.forward(x_batch, t_batch)
model.backward()
optimizer.update(model.params, model.grads)
...
通过独立实现进行最优化的类,系统的模块化会变得更加容易。
神经网络实现
现在,实现一个具有一个隐藏层的神经网络。首先,import 语句和初始化程序的 init() 如下所示
import sys
sys.path.append('..')
import numpy as np
from common.layers import Affine, Sigmoid, SoftmaxWithLoss
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size):
I, H, O = input_size, hidden_size, output_size
# 初始化权重和偏置
W1 = 0.01 * np.random.randn(I, H)
b1 = np.zeros(H)
W2 = 0.01 * np.random.randn(H, O)
b2 = np.zeros(O)
# 生成层
self.layers = [
Affine(W1, b1),
Sigmoid(),
Affine(W2, b2)
]
self.loss_layer = SoftmaxWithLoss()
# 将所有的权重和梯度整理到列表中
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
初始化程序接收 3 个参数。input_size 是输入层的神经元数,hidden_size 是隐藏层的神经元数,output_size 是输出层的神经元数。在内部实现中,首先用零向量(np.zeros())初始化偏置,再用小的随机数(0.01 * np.random.randn())初始化权重。通过将权重设成小的随机数,学习可以更容易地进行。接着,生成必要的层,并将它们整理到实例变量 layers 列表中。最后,将这个模型使用到的参数和梯度归纳在一起。
因为 Softmax with Loss 层和其他层的处理方式不同,所以不将它放入 layers列表中,而是单独存储在实例变量 loss_layer中。
接着,我们为 TwoLayerNet 实现 3 个方法,即进行推理的 predict() 方法、正向传播的 forward() 方法和反向传播的 backward() 方法
def predict(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
def forward(self, x, t):
score = self.predict(x)
loss = self.loss_layer.forward(score, t)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
学习用的代码。首先,读入学习数据,生成神经网络(模型)和优化器。然后,按照之前介绍的学习的 4 个步骤进行学习。另外,在机器学习领域,通常将针对具体问题设计的方法(神经网络、SVM等)称为模型。学习用的代码如下所示
import sys
sys.path.append('..')
import numpy as np
from common.optimizer import SGD
from dataset import spiral
import matplotlib.pyplot as plt
from two_layer_net import TwoLayerNet
# ❶ 设定超参数
max_epoch = 300
batch_size = 30
hidden_size = 10
learning_rate = 1.0
# ❷ 读入数据,生成模型和优化器
x, t = spiral.load_data()
model = TwoLayerNet(input_size=2, hidden_size=hidden_size, output_size=3)
optimizer = SGD(lr=learning_rate)
# 学习用的变量
data_size = len(x)
max_iters = data_size // batch_size
total_loss = 0
loss_count = 0
loss_list = []
for epoch in range(max_epoch):
# ❸ 打乱数据
idx = np.random.permutation(data_size)
x = x[idx]
t = t[idx]
for iters in range(max_iters):
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
# ❹ 计算梯度,更新参数
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# ❺ 定期输出学习过程
if (iters+1) % 10 == 0:
avg_loss = total_loss / loss_count
print('| epoch %d | iter %d / %d | loss %.2f'
% (epoch + 1, iters + 1, max_iters, avg_loss))
loss_list.append(avg_loss)
total_loss, loss_count = 0, 0
首先,在代码❶的地方设定超参数。具体而言,就是设定学习的 epoch数、mini-batch 的大小、隐藏层的神经元数和学习率。接着,在代码❷的地方进行数据的读入,生成神经网络(模型)和优化器。我们已经将 2 层神经网络实现为了 TwoLayerNet 类,将优化器实现为了 SGD 类
epoch 表示学习的单位。1 个 epoch 相当于模型“看过”一遍所有的学习数据(遍历数据集)。
epoch 为单位打乱数据,对于打乱后的数据,按顺序从头开始抽取数据。数据的打乱(准确地说,是数据索引的打乱)使用 np.random.permutation() 方法。给定参数 N,该方法可以返回 0 到 N − 1 的随机序列,其实际的使用示例如下所示
>>> import numpy as np
>>> np.random.permutation(10)
array([7, 6, 8, 3, 5, 0, 4, 1, 9, 2])
>>> np.random.permutation(10)
array([1, 5, 7, 3, 9, 2, 8, 6, 0, 4])
接着,在代码❹的地方计算梯度,更新参数。最后,在代码❺的地方定期地输出学习结果。这里,每 10 次迭代计算 1 次平均损失,并将其添加到变量 loss_list 中。
随着学习的进行,损失在减小。我们的神经网络正在朝着正确的方向学习!

Trainer类的fit()方法的参数。表中的"(=XX)"表示参数的默认值
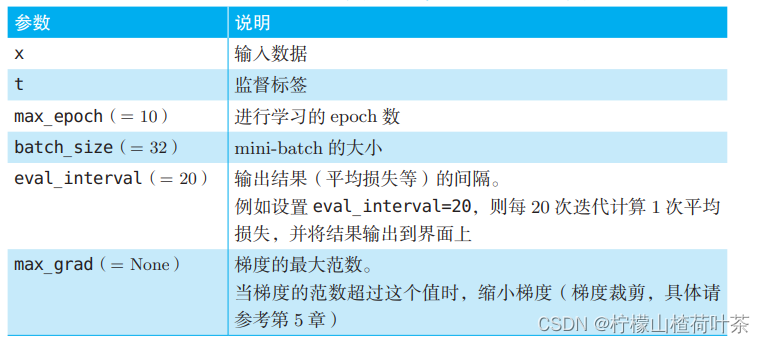
另外,Trainer 类有 plot() 方法,它将 fit() 方法记录的损失(准确地说,是按照 eval_interval 评价的平均损失)在图上画出来。使用 Trainer 类进行学习的代码如下所示
import sys
sys.path.append('..')
from common.optimizer import SGD
from common.trainer import Trainer
from dataset import spiral
from two_layer_net import TwoLayerNet
max_epoch = 300
batch_size = 30
hidden_size = 10
learning_rate = 1.0
x, t = spiral.load_data()
model = TwoLayerNet(input_size=2, hidden_size=hidden_size, output_size=3)
optimizer = SGD(lr=learning_rate)
trainer = Trainer(model, optimizer)
trainer.fit(x, t, max_epoch, batch_size, eval_interval=10)
trainer.plot()
深度学习的计算由大量的乘法累加运算组成。这些乘法累加运算的绝大部分可以并行计算,这是 GPU 比 CPU 擅长的地方。因此,一般的深度学习框架都被设计为既可以在 CPU 上运行,也可以在 GPU 上运行。
使用 Cupy,可以轻松地使用 NVIDIA 的 GPU 进行并行计算。更重要的是,CuPy 和 NumPy 拥有共同的 API。