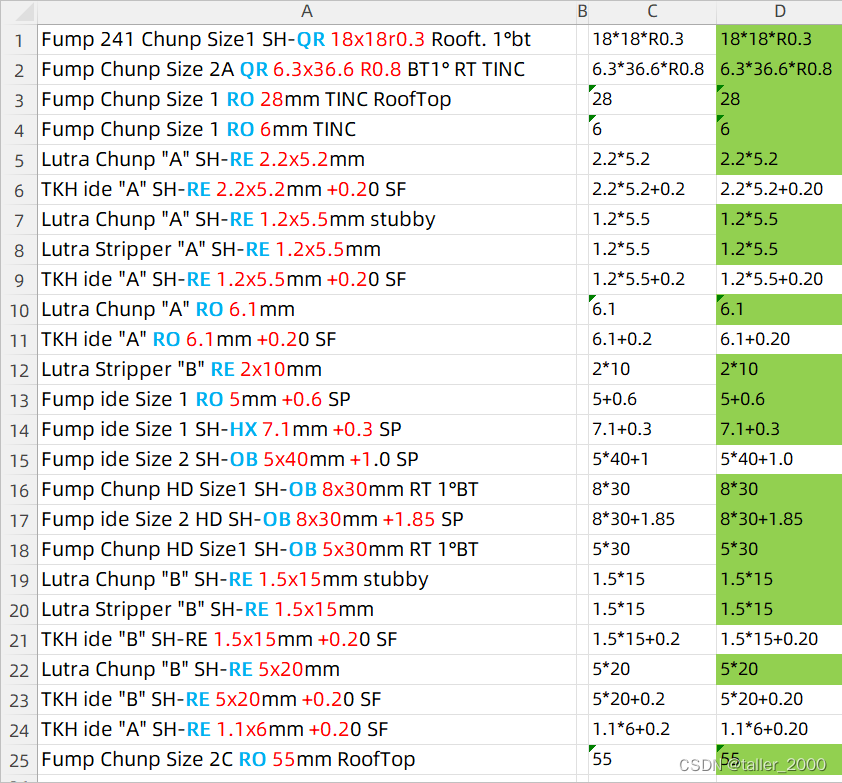
stacking方法,boosting算法,与bagging的区别,adboost算法权重固定,regionboost权重动态学习
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
文章目录
- stacking方法,boosting算法,与bagging的区别,adboost算法权重固定,regionboost权重动态学习
- @[TOC](文章目录)
- stack方法:分类器级联起来,不同的分类器,权重不同
- boosting算法具体咋做?
- boosting算法与bagging算法的区别
- 如果加大上一层错误分类器的权重,下一级就会重点关注并训练它:adboost算法
- adboost误差上界趋近于0的理论推导,没兴趣不必看
- region boost算法
- 集成学习ensemble learning总结
- 总结
文章目录
- stacking方法,boosting算法,与bagging的区别,adboost算法权重固定,regionboost权重动态学习
- @[TOC](文章目录)
- stack方法:分类器级联起来,不同的分类器,权重不同
- boosting算法具体咋做?
- boosting算法与bagging算法的区别
- 如果加大上一层错误分类器的权重,下一级就会重点关注并训练它:adboost算法
- adboost误差上界趋近于0的理论推导,没兴趣不必看
- region boost算法
- 集成学习ensemble learning总结
- 总结
stack方法:分类器级联起来,不同的分类器,权重不同
后面分类器的输入,是N-1那个分类器的输出
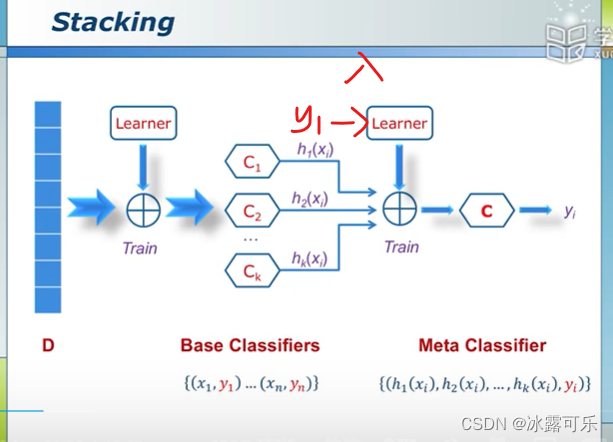
它脚stacking
而不是combine
boosting算法具体咋做?
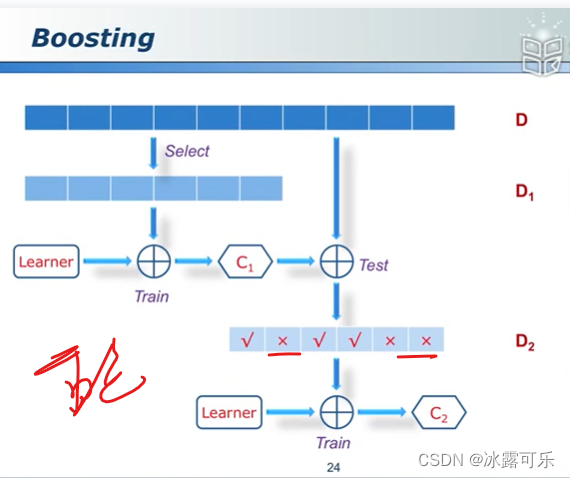
C2必须等C1训练完事,利用它的输出
重点关注C1分错的那些点
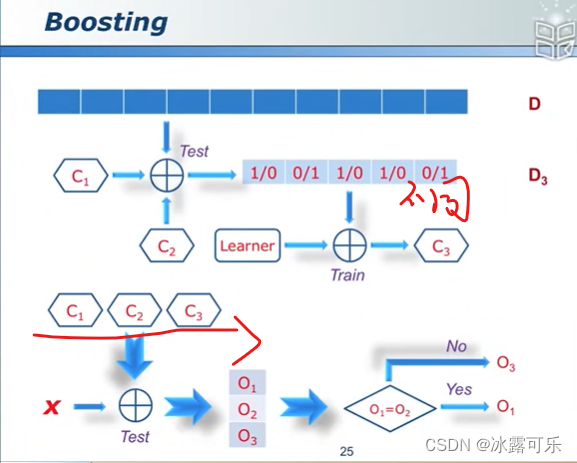
C3关注那些C1,C2有差异的那些点。
分错了样本,那下一个分类器加大这个权重。

弱分类器只要比随机分配瞎猜的好一丢丢就行
但是以整体就非常牛逼
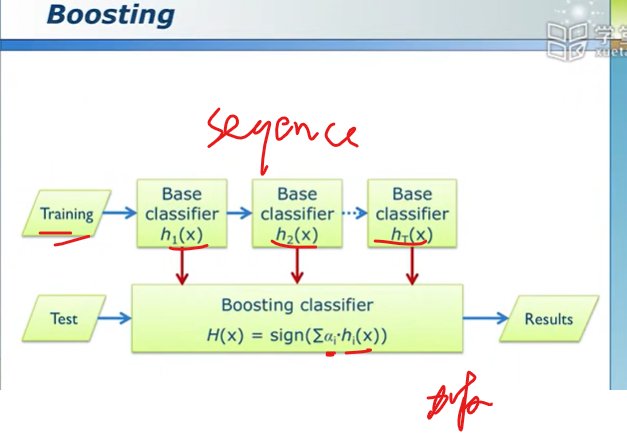
boosting算法与bagging算法的区别
并行和串行吧
bagging并行combine,以多数投票为准
boosting串行boost,不同分类器结果加权组合
如果加大上一层错误分类器的权重,下一级就会重点关注并训练它:adboost算法
权重是学习出来的

Zt是重要的,保证权重和为1

圈内是错的

左边圈内错了

组合
三条线搞定
adboost是十大算法之一,它很强
在数学书,它能证明,自己和牛逼
adboost误差上界趋近于0的理论推导,没兴趣不必看
模型误差error,怎么表示

样本预测值分错了则
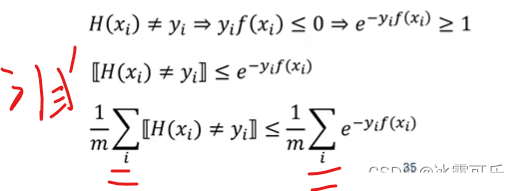
左边就是模型误差
上界为右边


e就是error
很简单权重
最小化这个误差,权重美滋滋就出来了

误差上界就是可以趋近于0
爽得很
只要一个分类器,别随机分类器好一丢丢就行了
region boost算法
对于adboost,权重是固定的,蓝色和红色五角星,属于圈,还是×?
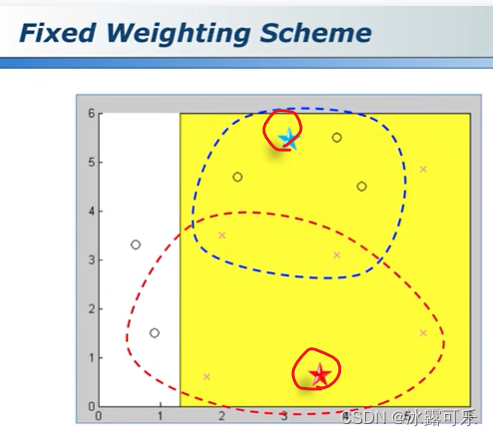
你要是认为蓝色五角星是圈
红色五角星是×
这波其实是有很大的不可信的
因为目前分类器是弱鸡
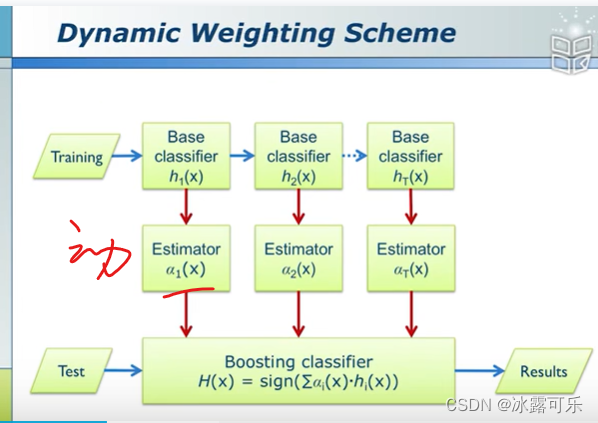
当x不同,权重就会变,动态学习
那就OK了

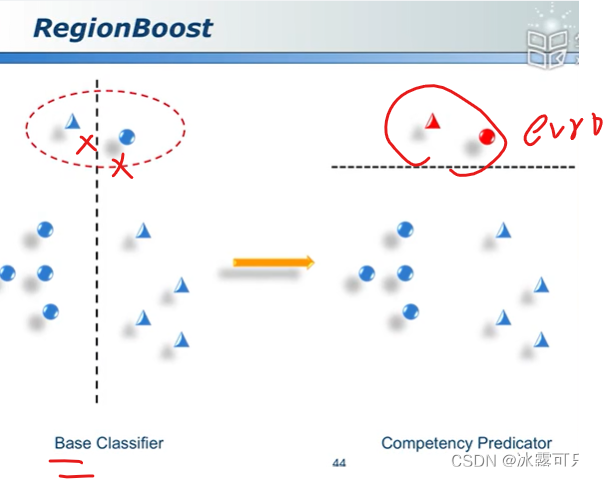
上面错误的region
下面正确的区域

靠谱不靠谱,算一下
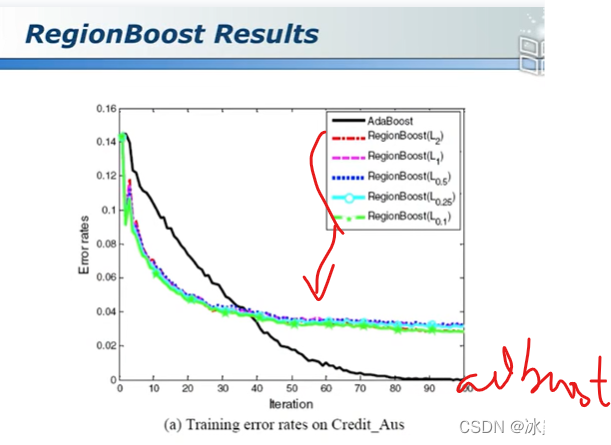
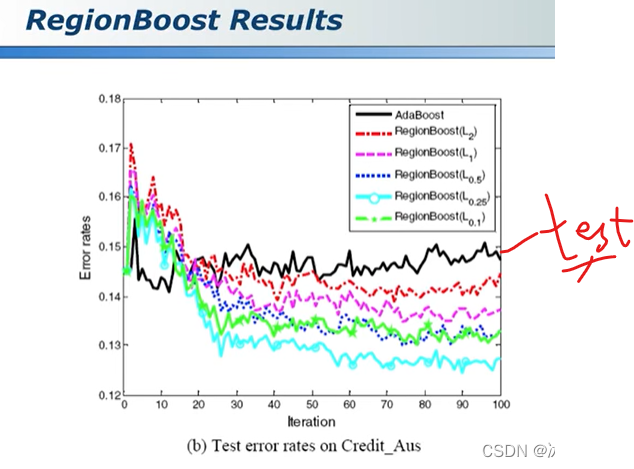
集成学习ensemble learning总结

总结
提示:重要经验:
1)
2)
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。