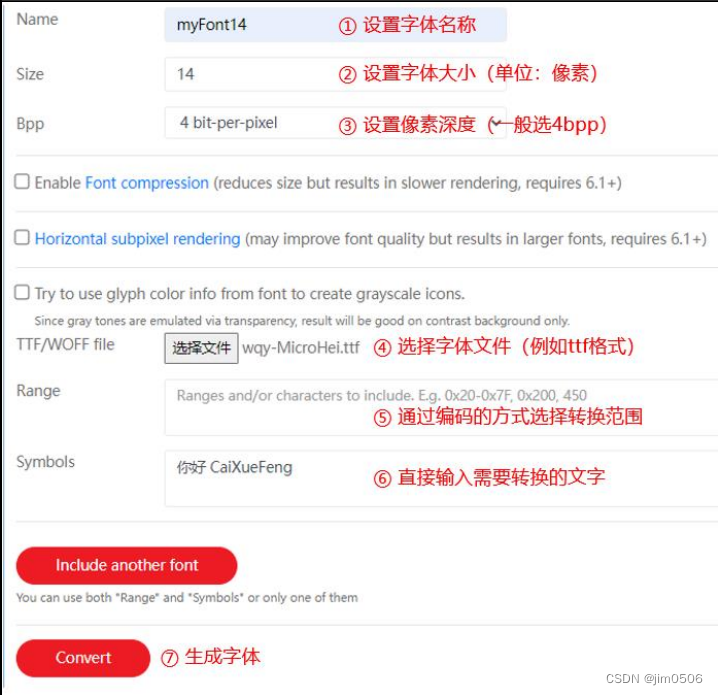
李宏毅机器学习Transformer
Self Attention学习笔记记录一下几个方面的内容
- 1、Self Attention解决了什么问题
- 2、Self Attention 的实现方法以及网络结构
- Multi-head Self Attention
- positional encoding
- 3、Self Attention 方法的应用
- 4、Self Attention 与CNN以及RNN对比
1、Self Attention解决了什么问题
机器翻译任务输入序列的长度与输出序列的长度可能相同也可能不相同;
产品评价预测任务无论输入序列的长度为多少,输出的序列长度都为固定大小;
如果序列中每个词的标签为该次对应词性的任务重输出的序列长度与输入的序列长度相同。

(1)使用 Fully Connected网络来处理,
- 如果每一个出入的向量对应一个Fully Connected网络,每一个向量之间不考虑其他向量之间的上线文关联信息;
(2)可以使用一个window来获取指定范围内向量的上下文信息。
- 当输入的序列长度不固定时,会出现window长度无法确定的问题;
- 如果要获取整合序列的信息,而整个序列很长,window覆盖整个序列长度,那么会出现Fully Connected网络中要处理的信息量很大,网络参数多,计算量大的问题。
要结合整个sequence 的信息需要,使用了Self-Attention的方法。
使Self-Attention,实现每一个输出的向量都整合了所有输入向量的信息。

self attention可以使用多次,在Fully Connected输出层还能再接self attention,因此Self Attention 的输入可以使原始输入 或者 隐藏层。
2、Self Attention 的实现方法以及网络结构
self attention的实现通过计算每一个输入向量与其他所有输入向量的相关性α作为attention score,与当前向量点乘操作,得到输出向量。

计算两个向量相关性的方法为dot-product(点乘)

Self Attention 的公式如下
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
⋅
K
T
d
k
)
⋅
V
Attention(Q,K,V) = softmax(\frac{Q·K^T}{\sqrt{d_k}} ) ·V
Attention(Q,K,V)=softmax(dkQ⋅KT)⋅V
其中 q表示Query,k表示Key。
需要计算每一个节点与其他节点的相关性(这些计算是可以同时进行的)。
以长度为4的序列( a1 ,a2 ,a3 ,a4)为例,
Q
=
W
q
I
Q=W^qI
Q=WqI
K = W k I K=W^kI K=WkI
V = W v I V=W^vI V=WvI
对每一个输入向量,分别乘以矩阵Wq、Wk、Wv,得到对应向量q、k、v。
对于第i个向量,计算与其他向量的相关性,则用qi 分别与其他向量的kj 做点乘。

(
k
1
k
2
k
2
k
4
)
⋅
q
1
=
(
α
1
,
1
α
1
,
2
α
1
,
3
α
1
,
4
)
\begin{pmatrix} k_1 \\ k_2 \\k_2\\k_4 \end{pmatrix}·q^1=\begin{pmatrix} α_{1,1} \\ α_{1,2}\\α_{1,3}\\α_{1,4} \end{pmatrix}
k1k2k2k4
⋅q1=
α1,1α1,2α1,3α1,4
(
k
1
k
2
k
2
k
4
)
⋅
q
2
=
(
α
2
,
1
α
2
,
2
α
2
,
3
α
2
,
4
)
\begin{pmatrix} k_1 \\ k_2 \\k_2\\k_4 \end{pmatrix}·q^2=\begin{pmatrix} α_{2,1} \\ α_{2,2}\\α_{2,3}\\α_{2,4} \end{pmatrix}
k1k2k2k4
⋅q2=
α2,1α2,2α2,3α2,4
(
k
1
k
2
k
2
k
4
)
⋅
q
3
=
(
α
3
,
1
α
3
,
2
α
3
,
3
α
3
,
4
)
\begin{pmatrix} k_1 \\ k_2 \\k_2\\k_4 \end{pmatrix}·q^3=\begin{pmatrix} α_{3,1} \\ α_{3,2}\\α_{3,3}\\α_{3,4} \end{pmatrix}
k1k2k2k4
⋅q3=
α3,1α3,2α3,3α3,4
(
k
1
k
2
k
2
k
4
)
⋅
q
4
=
(
α
4
,
1
α
4
,
2
α
4
,
3
α
4
,
4
)
\begin{pmatrix} k_1 \\ k_2 \\k_2\\k_4 \end{pmatrix}·q^4=\begin{pmatrix} α_{4,1} \\ α_{4,2}\\α_{4,3}\\α_{4,4} \end{pmatrix}
k1k2k2k4
⋅q4=
α4,1α4,2α4,3α4,4
(
k
1
k
2
k
2
k
4
)
⋅
(
q
1
,
q
2
,
q
3
,
q
4
)
=
(
α
1
,
1
,
α
2
,
1
,
α
3
,
1
,
α
4
,
1
α
1
,
2
,
α
2
,
2
,
α
3
,
2
,
α
4
,
2
α
1
,
3
,
α
2
,
3
,
α
3
,
3
,
α
4
,
3
α
1
,
4
,
α
2
,
4
,
α
3
,
4
,
α
4
,
4
)
\begin{pmatrix} k_1 \\ k_2 \\k_2\\k_4 \end{pmatrix}·\begin{pmatrix}q^1,q^2,q^3, q^4\end{pmatrix}=\begin{pmatrix} α_{1,1},α_{2,1},α_{3,1},α_{4,1} \\ α_{1,2},α_{2,2},α_{3,2},α_{4,2}\\α_{1,3},α_{2,3},α_{3,3},α_{4,3}\\α_{1,4},α_{2,4},α_{3,4},α_{4,4} \end{pmatrix}
k1k2k2k4
⋅(q1,q2,q3,q4)=
α1,1,α2,1,α3,1,α4,1α1,2,α2,2,α3,2,α4,2α1,3,α2,3,α3,3,α4,3α1,4,α2,4,α3,4,α4,4
K
T
⋅
Q
=
A
K^T ·Q=A
KT⋅Q=A
将α值经过SoftMax,转化为0-1之间的值,且α值之和等于1。

以第一个向量为例,计算与每一个向量的相关系数α’
α
1
,
i
′
=
e
x
p
(
α
1
,
i
)
/
∑
j
e
x
p
(
α
1
,
j
)
α'_{1,i}=exp(α_{1,i})/\sum_{j}exp(α_{1,j})
α1,i′=exp(α1,i)/j∑exp(α1,j)
以上计算的向量结果侧重提取向量与其他向量的attention score,再与向量V点乘,V向量只包含输入向量的信息。
b
i
=
∑
j
α
1
,
i
′
⋅
v
i
b_i=\sum_{j}α'_{1,i}·v^i
bi=j∑α1,i′⋅vi

最终得到输出向量b。
根据自己理解画了一张self attention 的结构图

用向量机算来表示self attention的过程如图所示:

其中Wq 、Wk 、Wv 是可以训练的参数。
对于第一步由输入向量αi 分别与矩阵Wq 、Wk 、Wv做点乘,可以将输入向量的矩阵合并计算:

第二步将当前向量的query向量Q与其他所有向量的K点乘计算

可以将转置后的K向量合并后与合并后的Q做点乘运算

第三步得到α向量后经过softmax后的**α’**与合并后的向量V做点乘

Multi-head Self Attention
Multi-head Self Attention 多头注意力机制在原Self Attention上增加了不同的q(Query)。
将第一步得到的qi分别与不同的向量点乘操作,生成qi,1,qi,2
q i , 1 = W q , 1 ⋅ q i q^{i,1}=W^{q,1}·q^i qi,1=Wq,1⋅qi
q i , 2 = W q , 2 ⋅ q i q^{i,2}=W^{q,2}·q^i qi,2=Wq,2⋅qi
不同的q负责不同的相关性(问题中有几种不同的相关性,就使用几个head)。
那么生成了多个q,对应也要生成多个k和v;

计算时,分别取每个q值与对应的第二个下标值相同的k向量做点乘;
经过softmax后与对应下标值相同的v向量做点乘,得到输出向量结果。
positional encoding
在self attention中还需体现向量的位置信息。
在网络中输入向量加入了一个位置向量ei

向量ei 的值通过手动添加或者在网络中训练得到。
3、Self Attention 方法的应用
-
语音处理
对于输入的一段长度为L语音序列,做self attention计算α得到的attention metrix的维度是L×L。当序列过长时,考虑运算速度,使用Truncated Self-attention,只在一个设定的范围内使用Self-attention。

-
Self attention应用在图像处理
将一张图片看做是一系列向量,对于一个三通道的图片,将每一个像素点看做是一个三维的向量

4、Self Attention 与CNN以及RNN对比
- Self Attention与CNN
CNN对于固定的kernel对应在特征图上是固定大小的receiptive field,而self attention 提取到的是整张图片的信息。self attention的receiptive field大小是通过学习得到的。
CNN是Self Attention特例情况 - Self Attention与RNN
RNN网络只能够看到已经输入到网络中的信息,Self Attention能够使用到所有输入向量的信息。
RNN计算当前时间点需要依赖于上一个时间点的计算结果,当前向量之前的所有向量的信息都需要存放在内存中。Self Attention当前向量中包含了每一个输入向量的信息。
Self Attention可以实现并行处理。
对于K、Q、V向量的理解
是由原始输入向量分别与三个向量点乘后获得,这三个向量又是可以学习的参数。

参数Q和K共同作用,来决定两个向量的相关系数。
感谢:
小白都能看懂的超详细Attention机制详解
https://www.bilibili.com/video/BV1v3411r78R/?p=1&vd_source=91cfed371d5491e2973d221d250b54ae
https://www.bilibili.com/video/BV1Kq4y1H7FL/?spm_id_from=333.999.0.0&vd_source=91cfed371d5491e2973d221d250b54ae