前言:近几年大数据概念很多,数据库和数据仓库还没搞清楚,就又出了数据湖,现在又开始流行湖仓一体。互联网公司拼命造高大上概念来忽略小白买单的能力还是可以的。
1、数据库
数据库是结构化信息或数据的有序集合,一般以电子形式存储在计算机系统中。通常由数据库管理系统 (DBMS) 来控制。在现实中,数据、DBMS 及关联应用一起被称为数据库系统,通常简称为数据库。为了提高数据处理和查询效率,当今最常见的数据库通常以行和列的形式将数据存储在一系列的表中,支持用户便捷地访问、管理、修改、更新、控制和组织数据。另外,大多数数据库都使用结构化查询语言 (SQL) 来编写和查询数据。
可以把数据库理解为一个虚拟的图书馆,每一本书都代表了一个数据记录,而书架和分类系统则对应数据库和表格和索引,读者可以快速查找和管理所需要的信息。
数据库的应用很常见,基本上每个业务系统都会有自己的数据库。比如你每天总是要打开基金看一眼涨没涨,这后面就有数据库在做支撑。一般来说,除了安全性之类的硬性条件,衡量一个数据库好不好,关键在看它每秒能干多少事。
自 20 世纪 60 年代初诞生至今,数据库已经发生了翻天覆地的变化。最初,人们使用分层数据库(树形模型,仅支持一对多关系)和网络数据库(更加灵活,支持多种关系)这样的导航数据库来存储和操作数据。这些早期系统虽然简单,但缺乏灵活性。20 世纪 80 年代,关系数据库开始兴起;20 世纪 90 年代,面向对象的数据库开始成为主流。最近,随着互联网的快速发展,为了更快速地处理非结构化数据,NoSQL 数据库应运而生。现在,云数据库和自治驾驶数据库在数据收集、存储、管理和利用方面正不断取得新的突破。
2、数据仓库
为解决企业的数据集成与分析问题,数据仓库之父比尔·恩门于1990年提出数据仓库(Data Warehouse)。数据仓库主要功能是将企业经年累月所累积的大量数据,通过数据仓库特有的数据储存架构进行OLAP,最终帮助决策者能快速有效地从大量数据中,分析出有价值的信息,提供决策支持。自从数据仓库出现之后,信息产业就开始从以关系型数据库为基础的运营式系统慢慢向决策支持系统发展。
数据仓库相比数据库,主要有以下两个特点:
-
数据仓库是面向主题集成的。数据仓库是为了支撑各种业务而建立的,数据来自于分散的操作型数据。因此需要将所需数据从多个异构的数据源中抽取出来,进行加工与集成,按照主题进行重组,最终进入数据仓库。
-
数据仓库主要用于支撑企业决策分析,所涉及的数据操作主要是数据查询。因此数据仓库通过表结构优化、存储方式优化等方式提高查询速度、降低开销。
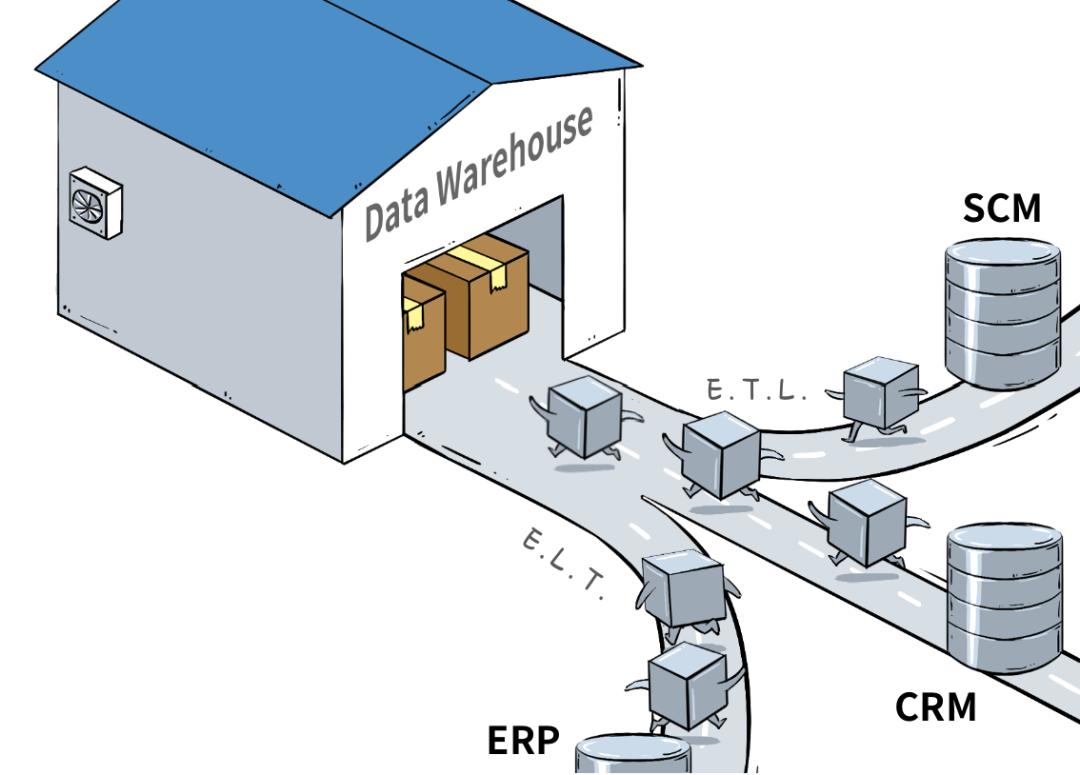
数据仓库的核心是有序性,主要为了分析用。在原有数据库的基础上,数据经过OLAP和ETL后,得出能够被业务人员直接进行分析的业务数据包。这很好理解,不同的业务部门使用不同的业务系统,系统之间数据不共通,指标混乱。但实际业务进行分析的时候通常涉及多个业务系统数据,取数、整理数据非常耗费时间。这时候就需要用到数据仓库,先把不同业务系统中的数据预先处理好,以业务数据包的形式存放在数据仓库里,业务需要分析的时候直接就能使用。
通常来说,数据仓库里都是结构化的数据,它的价值也在于帮助企业把运营数据转化成为高价值的可以获取的信息,并且在恰当的时间通过恰当的方式把恰当的信息传递给恰当的人。一般来说,数据仓库基本和BI一起搭配使用,前者把数据处理好,后者进行前端数据分析展示。
3、数据湖
数据湖(data lake)即一个以大量原始格式保存了公司级别的数据知识库。数据湖的概念最早出现Hadoop World大会上提出的。提出者希望数据湖, 能解决数据集市面临两个。
第一,数据集市只保留了部分属性,只能解决预先定义好的问题;
第二,数据集市中反映细节的原始数据丢失了,限制了通过数据解决问题;
从解决问题的角度出发,希望有一个合适的存储来保存这些明细的、未加工的数据。
2017年,亚马逊云最早推出AWS Lake,提供一套中心化的存储构建一个数据分析、数据科学和机器学习的数据湖解决方案。与此同时,Uber推出了Hudi(Hadoop Updates and Incrementals),最早也是被用于解决Uber内部离线数据的合规问题。
HUDI 最为相对成熟的数据湖技术,和 另外的Iceberg、Delta Lake一起被称为数据湖的三剑客。
有了支撑存储查询的数据库和探索分析的数据仓库,还要数据湖来干嘛?
就像你不舍得丢掉塑料袋想着“万一以后有用呢?”,老板也不舍得放过任何数据,万一这里面就有能够让营业额一飞冲天的利器呢?所以,企业就造了一个湖,把生产经营中产生的所有数据都能够全部放进去,方便后面要用的时候直接从这里面拿。数据湖的核心是开放性,里面是无序的数据。想要用好数据湖,一个是存储的架构要足够强大,另一个是数据处理足够牛逼。

-
存储架构强大指得是存得下、放得久。业务数据是实时变化的,要做到跟随业务系统数据实时变化的技术就复杂了,比如数据写入数据湖的时候要保证ACID,要高效支持upsert /delete历史数据,要能容忍数据频繁导入文件系统上产生的大量的小文件(显然HDFS就不行了)。Delta、iceberg和hudi等开源数据湖就是一些特定技术解决方案,但很多企业连hadoop生态还没搞通搞透呢,又搞出这么多技术,而且还没有统一标准,很让人头大。
-
数据处理足够牛逼是指数据放进去的时候,存放在里面的时候,以及用的时候拿出来的时候都要足够顺滑。如果放进去的时候就没有进行合理地约束,那时间久了就和垃圾堆没区别,更别说用了。关于数据湖的使用,其实更多是在互联网行业,比如机器学习、探索式分析之类的。
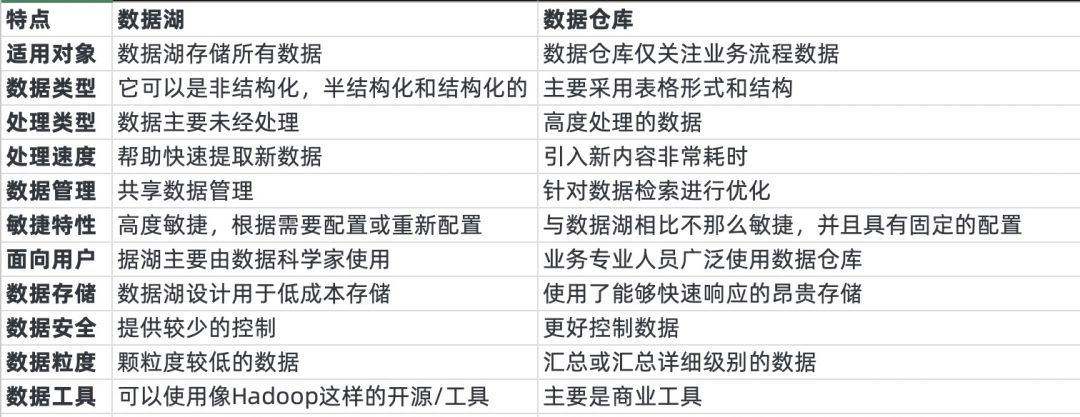
数据湖和数据仓库的区别:
4、湖仓一体
我们谈论数据湖仓一体时,我们指的是当前数据存储库平台的组合使用。数据仓库可以定义为一个现代数据平台,该平台由数据湖和数据仓库组成。更具体地说,数据湖仓储利用数据池中非结构化数据的灵活存储以及数据仓库中的管理功能和工具,然后从战略角度将它们作为一个更大的系统一起实施。这两个独特的工具的集成为用户带来了两全其美的结果。
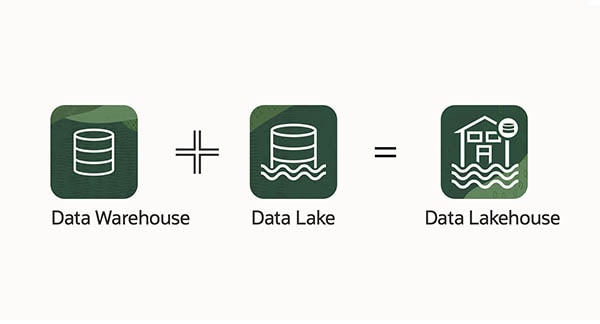
数据仓库和数据湖的结合就是湖仓一体,湖仓一体可以理解为把数据湖这个大杂间分了很多的区,每个区是一个应用站点,有的站点做BI,有的站点做大数据处理。
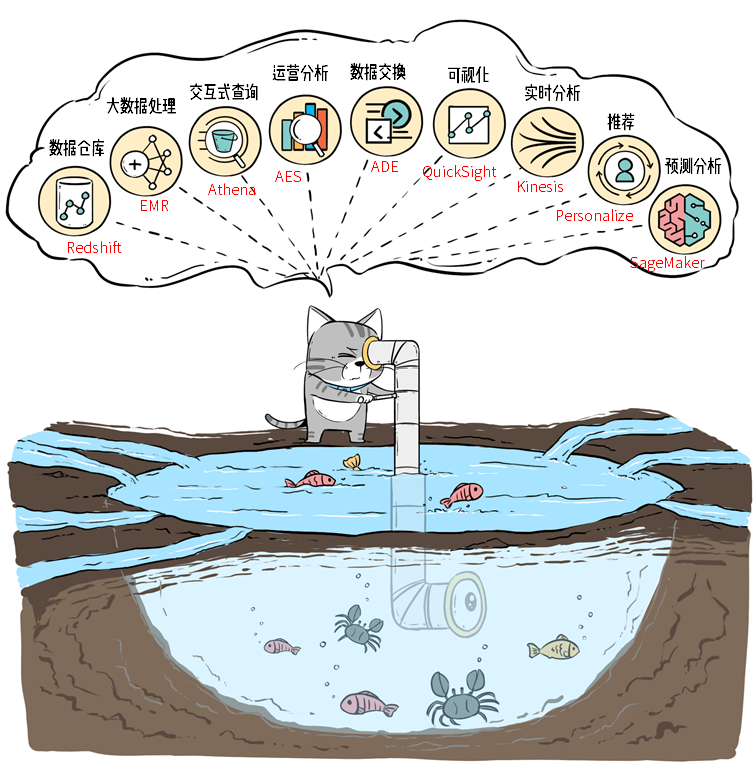
湖仓一体的架构,最终想要实现的,就是通过把数据湖作为中央存储库,围绕数据湖建立各种提供服务的站点,比如数据仓库,供业务分析和接入BI使用;再比如供机器学习用的站点;供大数据处理的站点等等,最终实现随心所欲地使用数据湖中的数据。
参考链接:
什么是数据湖仓一体?| Oracle 中国
数据库、数据仓库、数据湖、湖仓一体分别是什么? - 知乎
白话讲IT系列:数据仓库、数据湖、湖仓一体,究竟有什么区别?