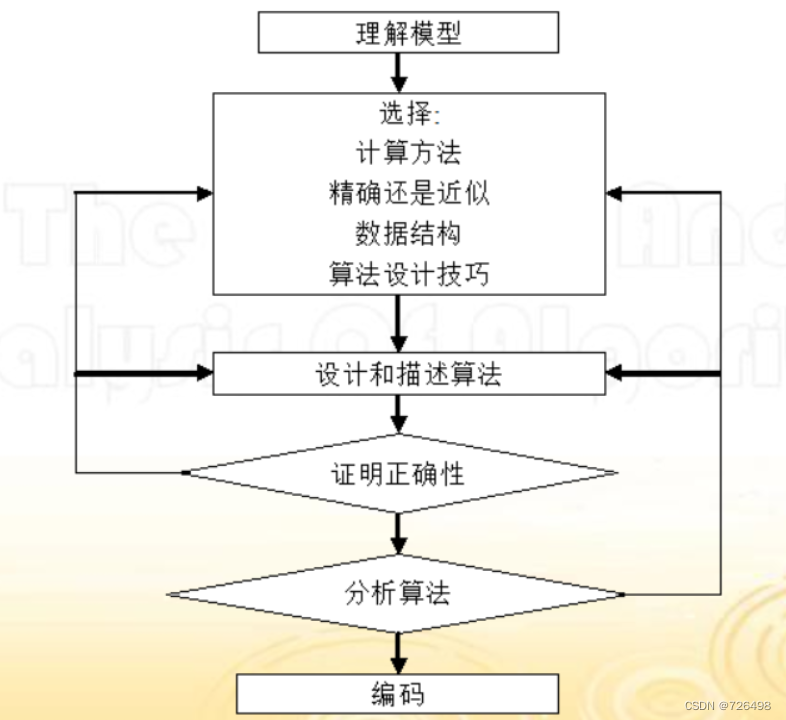
一、绪论
1.算法的概念及特征
1.1 定义:
算法是指求解某个问题或是某类问题的一系列无歧义的指令,也就是说,对于符合一定规范的输入,能够在有限时间内获得所要求的输出。
1.2 特征:
-
输入:算法中的各种运算总是要施加到一些运算对象上,而这些运算对象又可能具有某种初始状态,这是算法执行的起点或是依据。
-
输出: 一个算法有一个或多个输出,以反映对输入数据加工后的结果。
-
有限性:算法必须能在有限的时间内做完,即算法必须能在执行有限个步骤之后终止。
-
确定性: 算法中的每一个步骤都必须是有明确定义的,不允许有模棱两可的解释,也不允许有多义性。
-
有效性:算法的每个步骤,每个操作都是非常基本和简单的。

1.3欧几里得(Euclid'd)算法
问题:求给定两个不同时为零的非负整数的最大公约数GCD(m, n)
例子: GCD(60, 24) = 12, GCD(60, 0) = 60, GCD(0, 0) = ? Euclid’s 算法基于反复应用下面的等式 GCD(m, n) = GCD(n, m mod n) 直到第二个数变为0;GCD(m,0)=m这样所求问题的结果就显而易见了。
例子:GCD(60, 24) = GCD(24, 12) = GCD(12, 0) = 12
2.算法的一般设计模式
3.算法的描述方法
3.1 方法一:自然语言
如欧几里得算法:
-
第一步:输入m和n。
-
第二步:如果n=0,则返回m作为结果,算法停止;否则,执行第三步。
-
第三步:用 m 除以 n 并且把余数赋值给 r;把 n 赋值给 m;把 r 赋值给 n。
-
第四步:返回到第二步。
优点:容易理解
缺点:存在与生俱来的歧义性
3.2 方法二:流程图
概念:
流程图使用一系列相连的几何图形来描述算法,几何图形内部包含对算法步骤的描述。
如欧几里得算法:
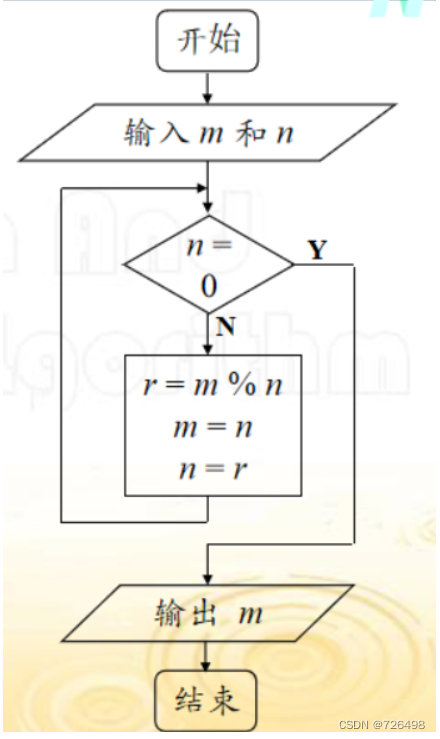
优点:直观
缺点:缺乏灵活性
3.3 方法三:程序语言
#include <iostream.h>
int GCD(int m, int n)
{
int r;
while(n != 0)
{
r = m%n;
m = n;
n = r;
}
return m;
}
void main()
{
cout << GCD(60, 24) << endl;
}
优点:可直接在计算机上运行
缺点:缺乏抽象性
3.4 方法四:伪代码
概念:
伪代码是自然语言和程序设计语言的混合结构,使用程序设计语言的基本语法;但所有的操作用自然语言来描述。
while n ≠ 0
r ← m % n
m ← n
n ← r
end while
return m
优点:比自然语言更简洁
缺点:不存在统一的伪代码形式
二、算法效率分析基础
1.算法的分析
1.1定义:
算法分析指对算法所需要的两种计算机资源:时间和空间进行评估。算法所需要的资源越少,算法效率越高。
1.2种类:
-
时间效率
-
空间效率
1.3方法:
-
理论分析
-
经验分析
2.时间效率的理论分析
2.1目标:确定一个算法在执行时所需要的总体时间
2.2方法:
-
确定一个算法在执行时所需要的精确时间
-
确定一个算法所涉及的所有操作的执行时间,其可作为算法输入规模和输入实例的函数:

其中 N 表示算法的输入规模,I 表示算法的输入实例.
3.算法的操作类型
比较操作:
-
等于, 大于, 小于, …
逻辑操作:
-
与, 或, 异或, 非, …
算术操作:
-
加法操作: 加, 减, 自加, 自减
-
乘法操作: 乘, 除, 取模
赋值操作:
-
X = 1
为了方便起见, 假定每个基本操作都耗时一个时间单元。
4.输入规模
4.1 排序和查找问题:
数组或列表中元素的个数。
4.2 图问题:
图的顶点个数或是边的条数,或是两者的总和。
4.3 计算几何问题:
通常是点数、线段数、面数或是多边形的个数。
4.4 矩阵问题:
矩阵的维数或是矩阵的元素总个数。
4.5数论及密码学:
输入数字二进制表示的位数。
5.例子

输入规模和基本操作的例子

6.最好、最坏与平均分析
6.1最好效率分析
-
相同输入规模下,所有输入实例中最小的执行时间

6.2最坏效率分析*
-
相同输入规模下,所有输入实例中最大的执行时间
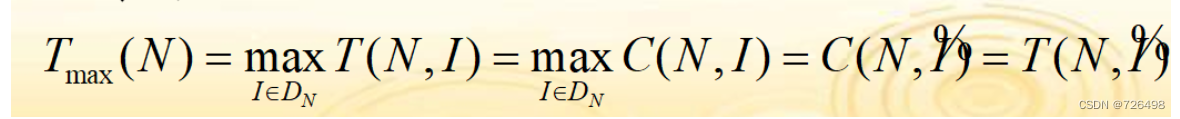
6.3平均效率分析
-
相同输入规模下,所有输入实例的平均执行时间
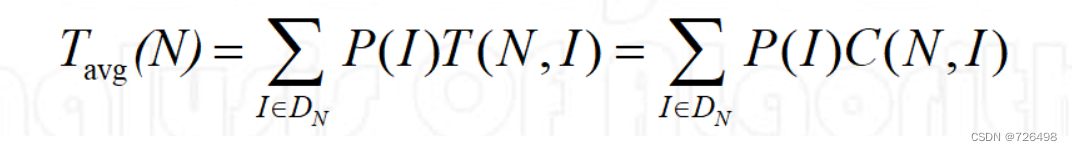
-
一般情况下不是最好和最坏的平均
7.算法分析的总体框架
-
确定算法的输入规模
-
找出算法的基本操作
-
算法的效率是否只依赖于输入规模,若果还依赖于其他因素,需要考虑最好、最坏与平均三种情况
-
给出算法的效率函数
例子:
ALGORITHM SequentialSearch(A[0, …, n – 1],K)
//Search for a given value in a given array by sequential search
//Input: An array A[0, …, n – 1] and a search key K
//Output: The index of the first element of A that matches K
or -1 if there are no matching elements
i ← 0
while i < 1 and A[i] ≠ K
i ← i + 1
end while
if i < n return i
else return -1
end if最好情况分析:最优情况是输入规模为n时,第一个元素等于查找键的列表。C(n)=1。
最坏情况分析:表中没有匹配的元素或者第一个匹配元素恰巧是列表的尾元素,该算法这是比较次数最多:C(n)=n。
平均效率分析:假设:a):查找成功的概率是p;b):对于任意i来说,第一次匹配发送在列表第i个位置的概率是相同的。
在查找成功的情况下,对于任意的i,第一次匹配发生在列表第i个位置的可能性是p/n,在这种情况下。算法所做的比较次数显然是i。在查找不成功的情况下,比较次数是n,这种情况发送的可能性是1-p,所以:
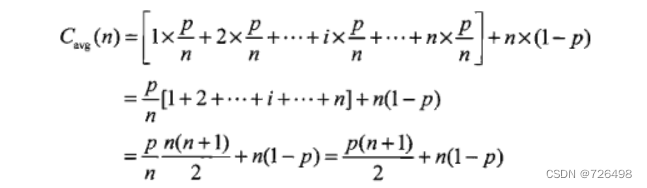
当p=1时,即查找必成功,平均比较次数是:(n+1)/ 2,大约要查找一般的元素;当p=0时,即查找一定不成功,平均比较次数是n,这种情况算法会对n个元素全部检查一遍。
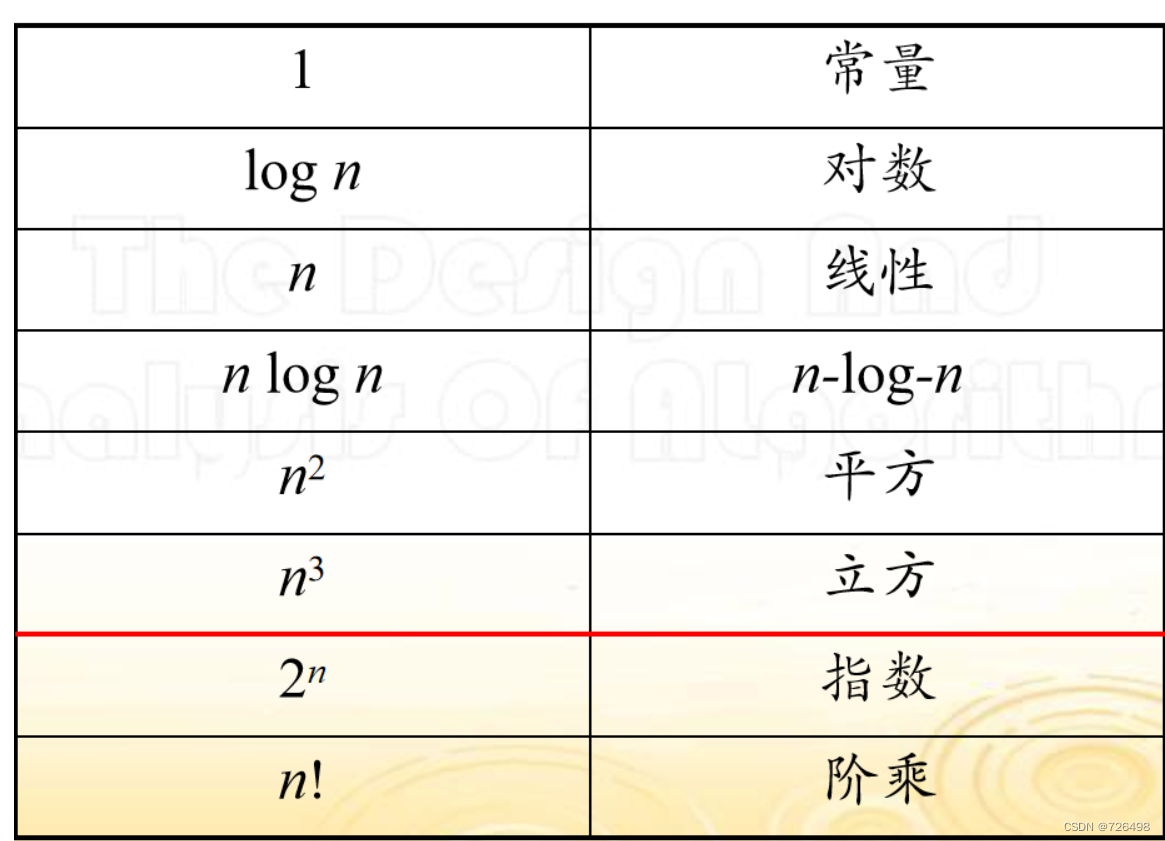
8.渐进符号和基本的效率类型
8.1增长率(增长阶)
8.1.1 定义
-
一个函数的增长率是指当输入规模增大的时候,该函数的值增长得有多快。
对算法分析有重要意义的函数值

显然函数 x^3 比函数 x^2 要增长得快; 如果算法 A 对于输入规模x需要 x^3 个操作,算法 B 需要 x^2 个操作, 算法 B 更高效; 因为函数的增长率, 我们会把函数x^3 + x^2 + x 等同于x^3。
8.1.2 增长率的分类
Big Omega Ω(g):
-
代表增长率大于等于函数g的函数集合
Big Oh O(g):
-
代表增长率小于等于函数g的函数集合
Big Theta θ(g):
-
代表增长率等于函数g的函数集合
8.2 渐进符号:O
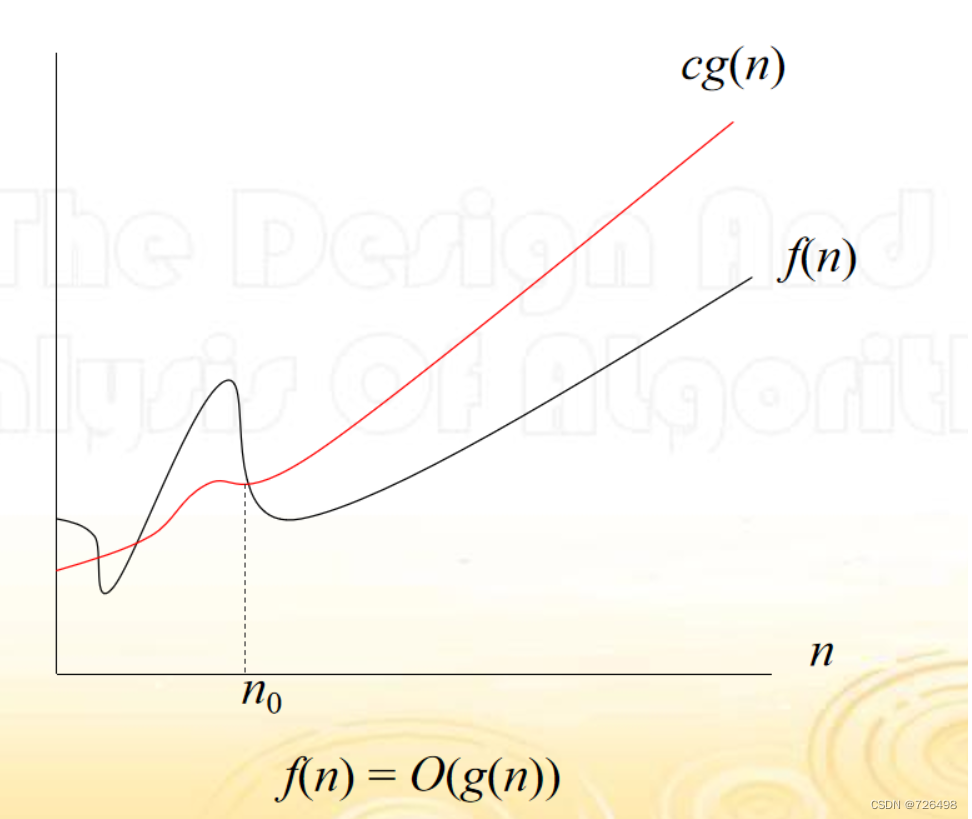
O-符号: 渐进上界
-
称 f(n) = O(g(n)),如果存在正常数 c 以及非负整数 n0 使得 0 ≤ f(n) ≤ cg(n) 对所有 n ≥ n0 成立。
-
f(n) = 2n^3+3n-5 = O(n^3)
-
f(n) = 2n^3+3n-5 = O(n^4)
-
-
在分析语义中, f(n) = O(g(n)) 指 f(n) ∈O(g(n))
将n扩展为实数:(n0之前的情况无关紧要)
8.3渐进符号:Ω
Ω-符号: 渐进下界
-
称 f(n) = Ω(g(n)),如果存在正常数 c 以及非负整数 n0 使得 0 ≤cg(n) ≤ f(n)对所有 n ≥ n0 成立。
-
f(n) = 2n^3+3n-5 = Ω(n^3)
-
f(n) = 2n^3+3n-5 = Ω(n^2)
-
-
在分析语义中, f(n) = Ω(g(n)) 指 f(n) ∈ Ω(g(n))

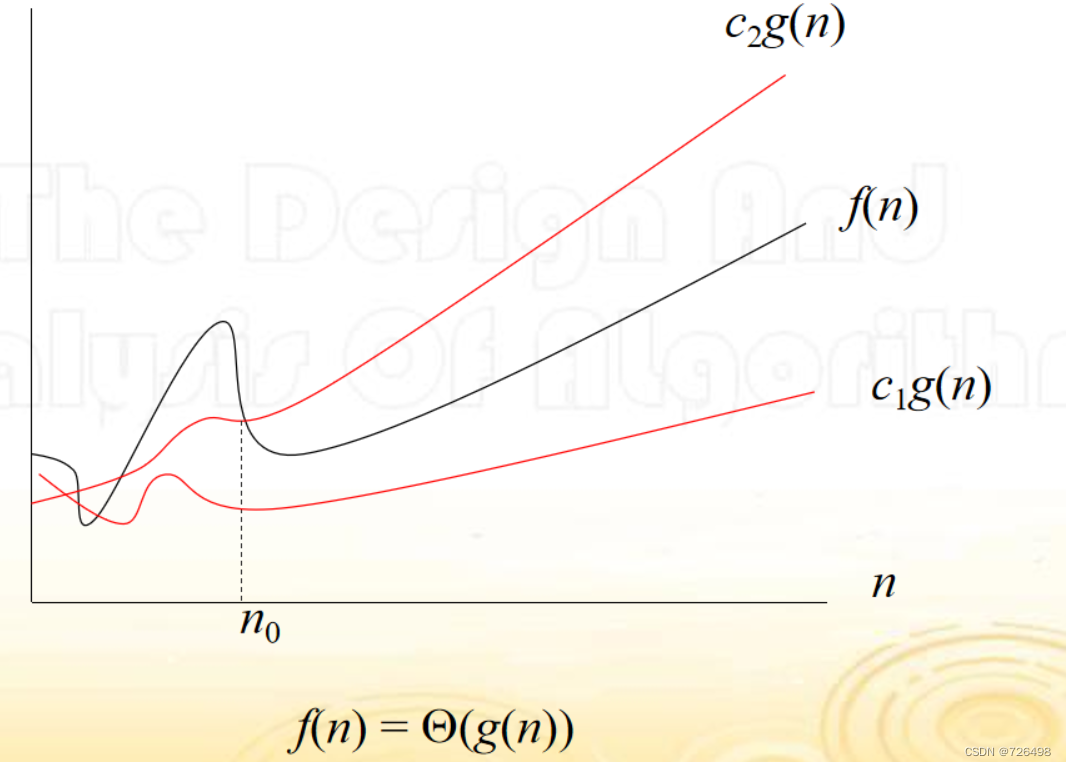
8.4渐进符号:θ
θ-符号:
-
称 f(n) = θ(g(n)),如果存在正常数c1,c2以及非负整数 n0 使得 0 ≤ c1g(n) ≤ f(n) ≤ c2g(n) 对所有 n ≥ n0 成立
-
f(n) = 2n^3+3n-5 = θ(n^3)
-
f(n) = 2n^4+1 = θ(n^3)
-
8.5渐进符号的有用特性
-
f(n) ∈ O(f(n))
-
f(n) ∈ O(g(n)) 当且仅当 g(n) ∈ Ω(f(n))
-
如果 f (n) ∈ O(g (n)) 且 g(n) ∈ O(h(n)) , 则 f(n) ∈ O(h(n))
-
如果 f1(n) ∈ O(g1(n)) 且 f2(n) ∈ O(g2(n)) , 则 f1(n) + f2(n) ∈ O(max{g1(n), g2(n)})
9.利用极限比较两个函数的增长阶
9.1定义:基于计算两个函数比率的极限来比较它们的增长阶:


9.2函数增长率分类例子

9.3基本的效率类型
10渐进符号:o
-
称 f(n) = O(g(n)),如果存在正常数 c 以及非负整数 n0 使得 f(n) < cg(n) 对所有 n ≥ n0 成立。
-
或, 如果

, 那么 f(n) = o(g(n))
-
f(n) = o(g(n)) 当且仅当 f(n) = O(g(n)) ,但 g(n) ≠O(f(n))
-
nlogn = o(n^2) 意味着 nlogn = O(n^2), 但 n^2 ≠ O(nlogn)
使用 o-notation, 我们可以简洁对基本效率类型进行如下分级:
-
多项式基本效率类型:
-
1< logn < n < nlogn < n^2 < n^3
-
-
指数基本效率类型:
-
a^n (a>1)< n! < n^n
-
11.算法分析数学基础
11.1证明方法
11.1.1分类:
直接证明:* 如果 n 是偶数, 则 n^2 是偶数。 间接证明:如果 n^2 是偶数, 则 n 是偶数。 反例法:令 f(n) = n^2 + n + 41 是定义在非负整数集上的函数,则 f(n) 永远是一个素数。 反证法:素数是无限的。
数学归纳法:
-
目标:S(n) 对所有的 n >= k 为真
-
基础步:证明当 n = k 时公式为真
-
归纳假设:假定对任意的 n - 1 公式为真
-
归纳步:证明对 n 公式也为真
11.2底函数与顶函数

定理: 令 f(x)是使得如果f(x)为整数,那么x即为整数的单调递增函数, 则有

11.3求和公式
-
求和公式是用来表示一系列值的和的紧促方式。
-
从1 到 n 这些自然数的和可以表示为:

常用求和公式:
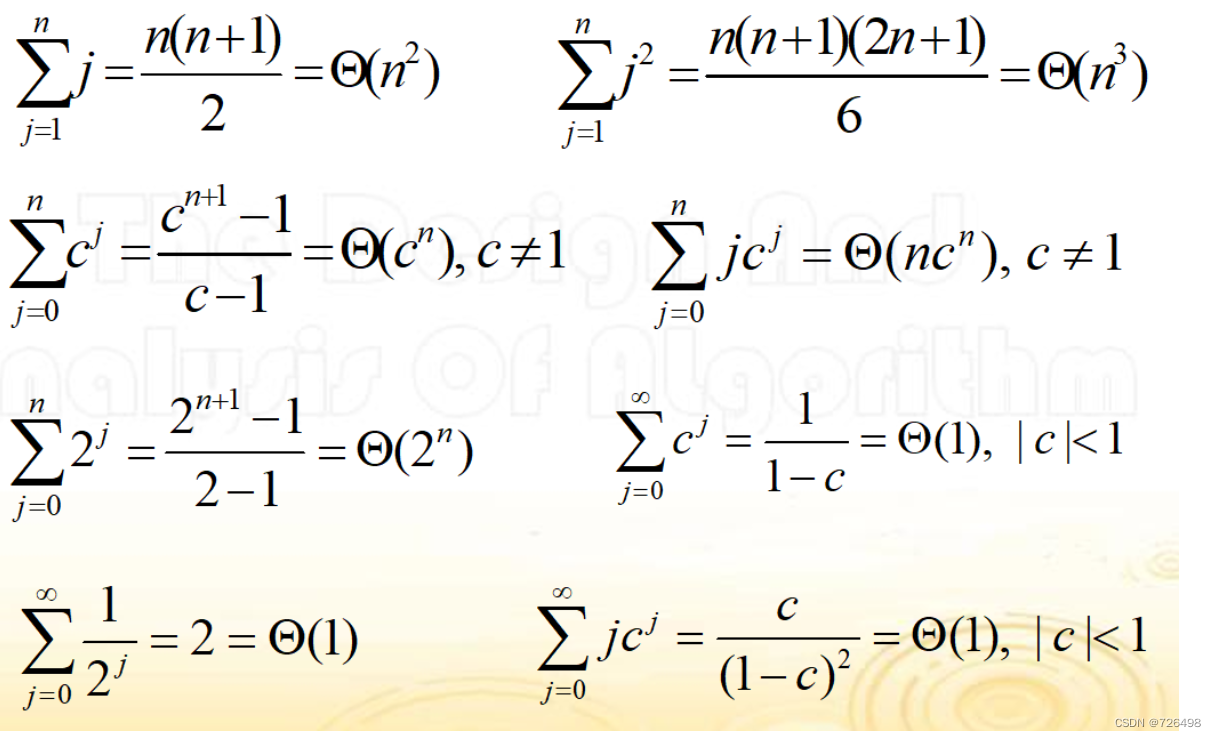

11.4非递归算法的分析框架
11.4.1分析步骤
-
决定用哪个(哪些)参数表示算法的输入规模。
-
找出算法的基本操作(位于最内层循环)。
-
检查基本操作的执行次数是否是只依赖输入规模。如果它还依赖一些其他的特性(比如输入实例),则需要分别研究最好、最差与平均效率。
-
建立一个算法基本操作执行次数的效率函数(求和表达式)。
-
利用求和运算的标准公式和法则给出求和表达式的闭合公式,或者至少确定它的增长阶。
11.4.2例子
-
例1:最大元素问题
ALGORITHM MaxElement(A[0, …, n – 1]) //Determines the value of the largest element in a given array //Input: An array A[0, …, n – 1] of real numbers //Output: The value of the largest element in A max_value ← A[0] for i ← 1 to n – 1 if A[i] > max_value max_value ← A[i] end if end for return max_value输入规模:数组元素个数n
基本操作:比较
最好、最坏与平均:不需要
效率函数(求和公式):

-
例2:元素唯一性问题
ALGORITHM UniqueElement(A[0, …, n – 1])
//Determines whether all the elements in a given array are distinct
//Input: An array A[0, …, n – 1]
//Output: Return “true” if all the elements in A are distinct
and “false” otherwise
for i ← 0 to n – 2
for j ← i + 1 to n – 1
if A[i] = A[j]
return false
end if
end for
end for
return true输入规模:数组元素个数n
基本操作:比较
最好、最坏与平均:需要
效率函数(求和公式):
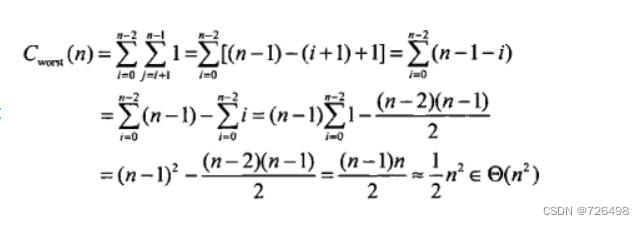
-
例3:矩阵乘积问题
ALGORITHM MatrixMultiplication(Anxn,Bnxn)
//Multiplies two n-by-n matrices by the definition-based algorithm
//Input: Two n-by-n matrices A and B
//Output: Matrix C = AB
for i ← 0 to n – 1
for j ← 0 to n – 1
C[i][j] ← 0
for k ← 0 to n – 1
C[i][j] ← C[i][j] + A[i][k] B[k][j]
end for
end for
end for
return C输入规模:矩阵的维数n
基本操作:两个数的乘法
最好、最坏与平均:不需要
效率函数(求和公式):

-
例4:计算二进制数问题
ALGORITHM Binary(n)
//Input: A positive decimal integer n
//Output: The number of binary digits in n’s binary representation
count ← 1
while n > 1
count ← count + 1
n ← n / 2
return cou输入规模:n
基本操作:比较
最好、最坏与平均:不需要
效率函数(求和公式):大约logn
11.5递归算法的分析框架
11.5.1分析步骤
-
决定用哪个(哪些)参数表示算法的输入规模。
-
找出算法的基本操作。
-
检查基本操作的执行次数是否是只依赖输入规模。如果它还依赖一些其他的特性(比如输入实例),则需要分别研究最好、最差与平均效率。
-
建立一个算法基本操作执行次数的效率函数(一个递推关系式以及相应的初始条件)。
-
求解该递推关系式,或者至少确定它的解的增长阶。
11.5.2递推关系
一个递推关系式定义为一个方程的递归形式,比如:
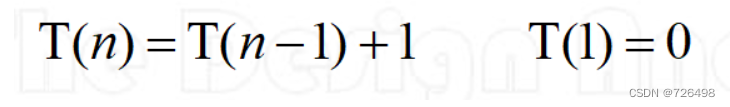
求解递推关系式的方法:
-
生成函数
-
特征方程
-
替代法
11.5.3例子
例1:递归计算n!
定义: n ! = 1 x 2 x … x(n-1) x n for n ≥ 1 且规定 0! = 1
递归定义 n!:F(n) = F(n - 1) x n for n ≥ 1 且 F(0) = 1
ALGORITHM F(n)
//Computes n! recursively
//Input: A nonnegative integer n
//Output: The value of n!
if n = 0 return 1
else return F(n-1) * n输入规模:n
基本操作:乘法
最好、最坏与平均:不需要
递推关系式:
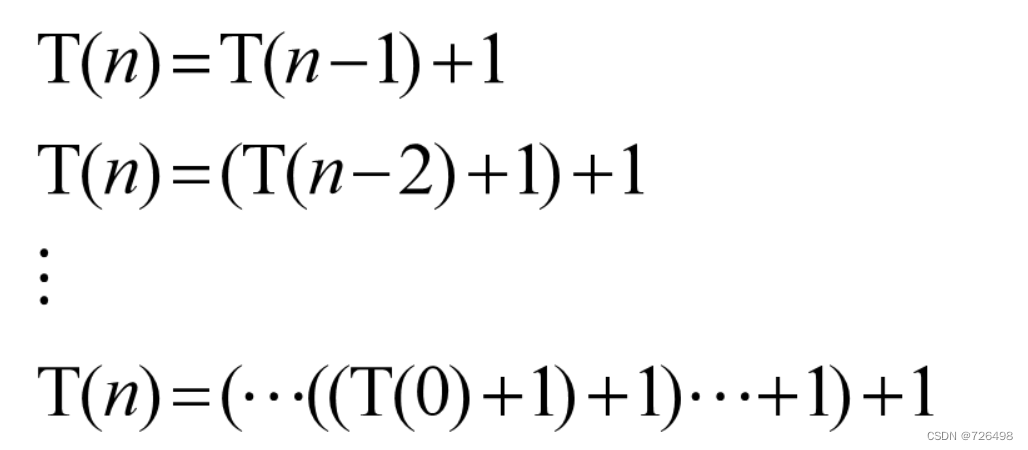
求解递推关系式:
直到到达初始值 T(0):

总共有多少个“+1” 项?
总共必有 n 个 “+ 1” 项
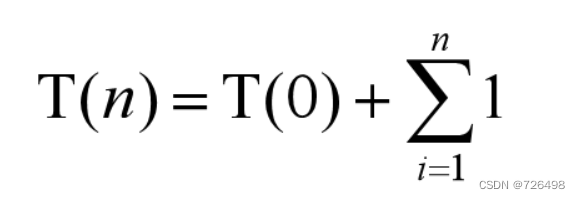
所以, 该递推关系式的闭合式为:

例2:汉诺塔谜题
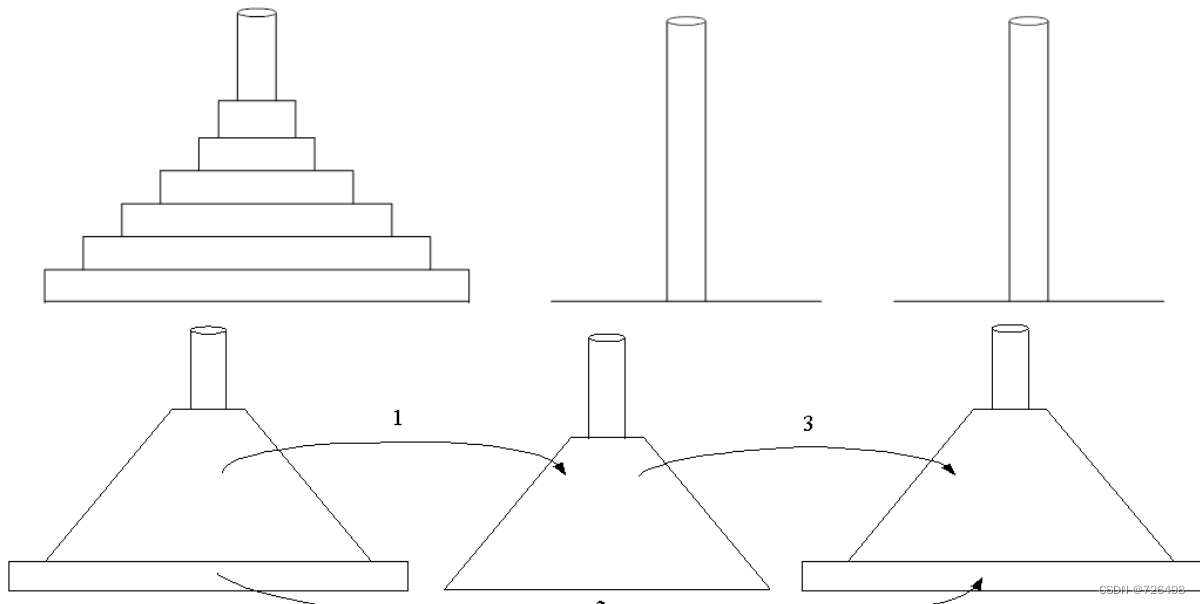
为了把n>1的盘子从木桩1移动到木桩3(借助木桩2)
-
第一步:把n-1个盘子移动到递归地从木桩1移动到木桩2(借助木桩3)
-
第二步:直接把最大的盘(n)从木桩1移动到木桩3
-
第三步:把n-1个盘从木桩2移动到木桩3(借助木桩1)
如果n=1,直接移动到另一个木桩
递推关系式:
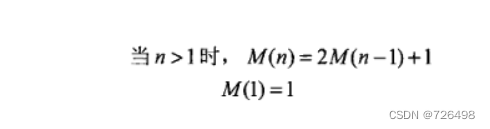
递推关系式求解:
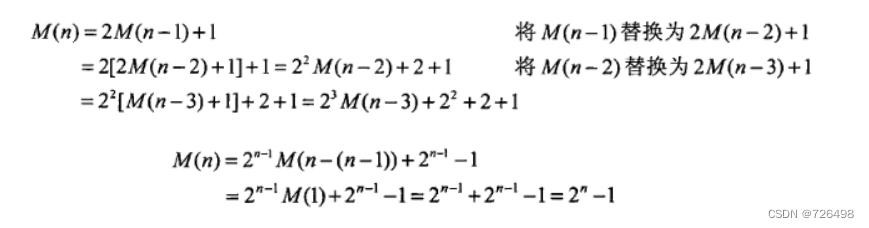
例3:计算#bits
ALGORITHM BinRec(n)
//Input: A nonnegative integer n
//Output: The number of binary digits in n’s binary representation
if n = 1 return 1
else return BinRec(n/2) + 1输入规模:n
基本操作:加法
最好、最坏与平均:不需要
递推关系式:
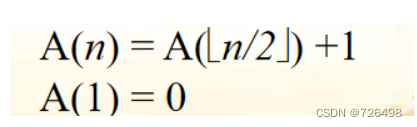
闭合式:

例4:Fibonacci序列
Fibonacci序列如下: 0, 1, 1, 2, 3, 5, 8, 13, 21, …
Fibonacci序列通项的递推关系式: F(n) = F(n-1) + F(n-2) F(0) = 0 F(1) = 1
需求解二阶常系数齐次线性递推关系式: aX(n) + bX(n-1) + cX(n-2) = 0
求解 aX(n) + bX(n-1) + cX(n-2) = 0:
-
建立二次特征方程 ar2 + br + c = 0
-
求解上述二次特征方程的根 r1 和 r2
-
递推式的通解 如果 r1 与 r2 是两个不同的实根: X(n) = αr1n + βr2n 如果 r1 = r2 = r 是两个相等的实根: X(n) = αrn + βnr n
-
通过初始条件求特解。
应用:求Fibonacci序列通项:
F(n) = F(n-1) + F(n-2)
特征方程:r^2 - r - 1=0
特征方程的根:
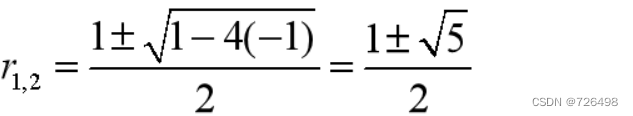
递推关系式的通解:

F(0) =0, F(1)=1 求特解:
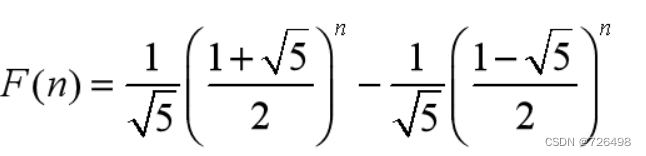
计算Fibonacci序列通项的算法:
1.基于定义的递归算法:
ALGORITHM Fibonacci_R(n)
//Input: A nonnegative integer n
//Output: The nth Fibonacci number
if n ≤ 1 return n
else return Fibonacci_R (n-1) + Fibonacci_R (n-2)输入规模:n
基本操作:加法
最好、最坏与平均:不需要
递推关系式:

闭合式:

2.基于定义的非递归算法:
ALGORITHM Fibonacci_NR(n)
//Input: A nonnegative integer n
//Output: The nth Fibonacci number
F[0] ←0; F[1] ←0
for i ←2 to n
F[i] ← F[i-1] + F[i-2]
return F(n)输入规模:n
基本操作:加法
最好、最坏与平均:不需要
求和公式:

3.显示公式算法:
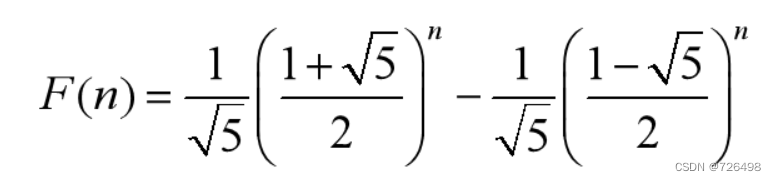
三、蛮力法
1.蛮力法的概念及基本思想
概念:是一种简单直接地解决问题的方法,通常直接基于问题的描述和所涉及的概念定义
基本思想: 逐一处理问题中的每一个元素,即穷举或是遍历。
有的例子:
-
计算 n!
-
两个矩阵相乘
2.蛮力法的优缺点
优点:
-
应用广泛
-
对某些重要问题能给出合理的算法
-
适合求解小规模问题
-
对实例不多的问题性价比高
-
可为教学和研究目的服务
缺点:
-
很少产生高效的算法
-
有些基于蛮力法的算法慢得难以接受
-
没有其它技巧般具有创造性
3.选择排序
3.1基本思想
第一趟从第一个元素开始到最后一个元素,扫描给定序列找出最小元素,然后将其与序列的第一个元素交换;第二趟从第二个元素开始到最后一个元素,扫描剩余序列找出最小元素,然后将其与序列的第二个元素交换;这样一直做,经过 n - 1 趟后, 该序列就排序好了。
算法伪代码:
SelectionSort(A[0..n-1])
for i<-0 to n-2 do
min<-j
for j<-i+1 to n-1 do
if A[j]<A[min] min<-j
swap A[j] and A[min]时间效率:

对于任何输入选择排序都是一个θ(n^2)的算法
稳定性:不稳定
是否在位:是
例子:89,45,68,90,29,34,17

4.冒泡排序
4.1基本思想
第一趟从第一个元素开始到最后一个元素,比较给定序列中的两个相邻元素,如果它们是逆序的话就交换它们的位置,直到最大元素“沉到”了序列的最后一个位置;第二趟从第一个元素开始到倒数第二个元素,重复第一趟的操作,直到第二大元素“沉到”了序列的倒数第二个位置;这样一直做,经过 n - 1 趟后, 该序列就排序好了。
算法伪代码:
BubbleSort(A[0..n-1])
for i<-0 to n-2 do
for j<-0 to n-2 do
if(A[j+1]<A[j]) swap A[j] and A[j+1]时间效率:
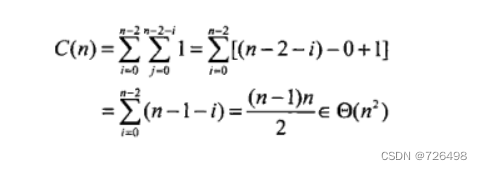
稳定性:稳定
是否在位:是
例子:89,45,68,90,29,34,17

改进的冒泡排序:
ALGORITHM BubbleSort(A[0…n-1])
//Input: An array A[0, …, n - 1] of orderable of elements
//Output: Array A[0, …, n - 1] sorted in ascending order
numberOfComparisons ← n-1
needSwap ← true
While needSwap do
needSwap ← False
for i ← 0 to numberOfComparisons-1 do
if A[i+1] < A[i] then
Swap(A[i], A[i+1])
needSwap ← true
end if
end for
numberOfComparisons ← numberOfComparisons -1
end while4.2时间效率分析
最好情况:
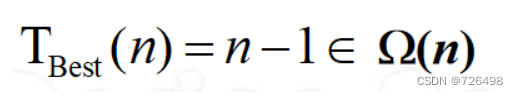
最坏情况:

平均情况:
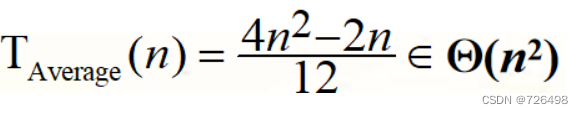
5.蛮力法在查找问题中的应用
5.1串匹配问题
问题描述: 给定两个字符串S=“s1s2…sn” 和 T=“t1t2…tm”,查找子串T在主串S中是否出现,若出现返回子串的相应起始位置。这样的过程称为串匹配或模式匹配, 其中S称作文本,T称为模式。
基本思想: 将文本串与模式串对齐并比较它们的第一个字符,如果相等, 继续比较它们的第二个字符; 如果不相等, 则模式串向右移一位, 然后从模式的第一个字符开始,继续把模式和文本中对应的字符进行比较,重复上述过程,直到模式串中的所有字符都匹配成功。
例子:
假定文本串 S=“ababcabcacbab”, 模式串 T=“abcac”
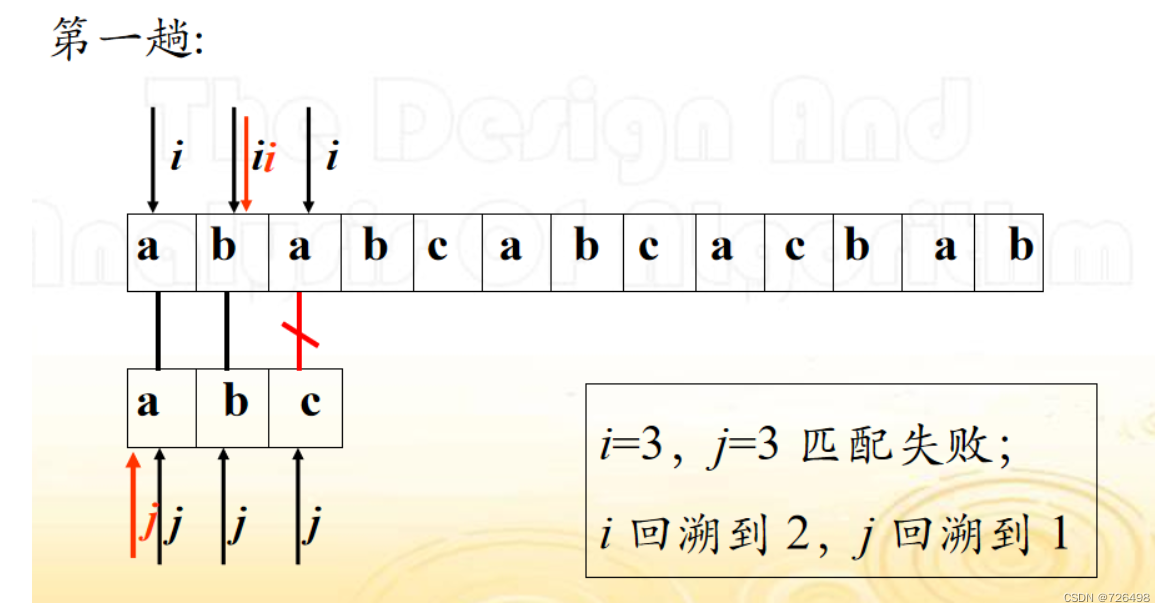
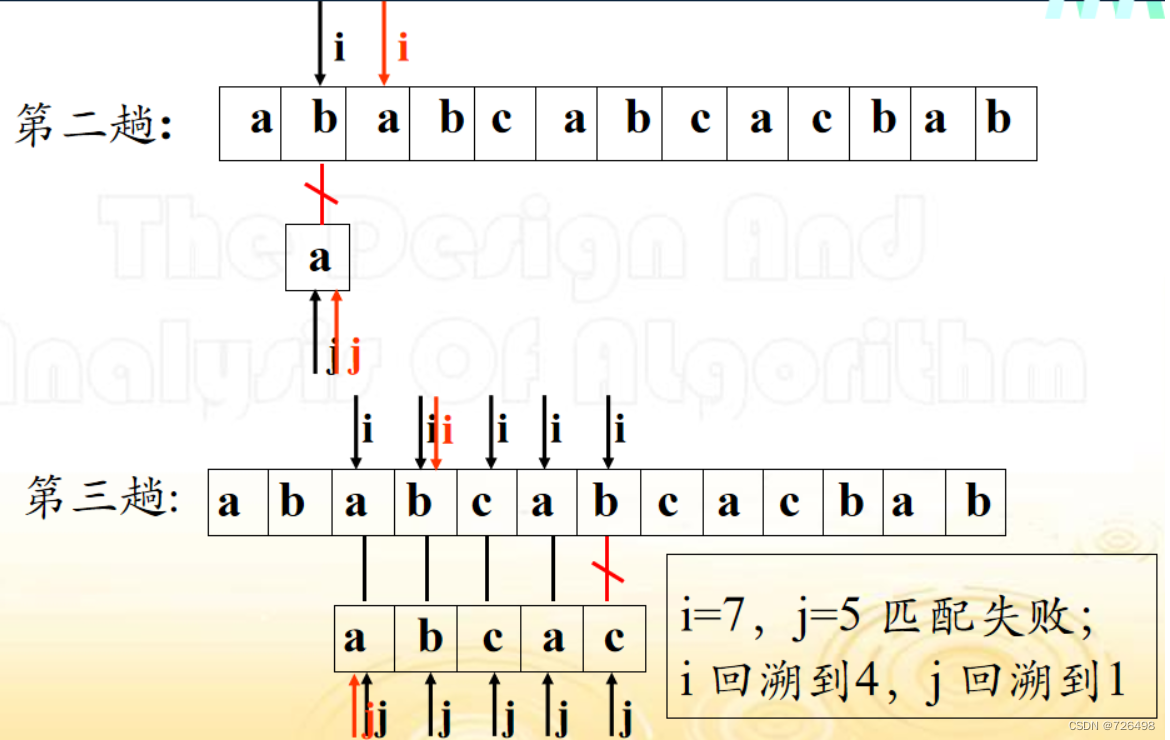
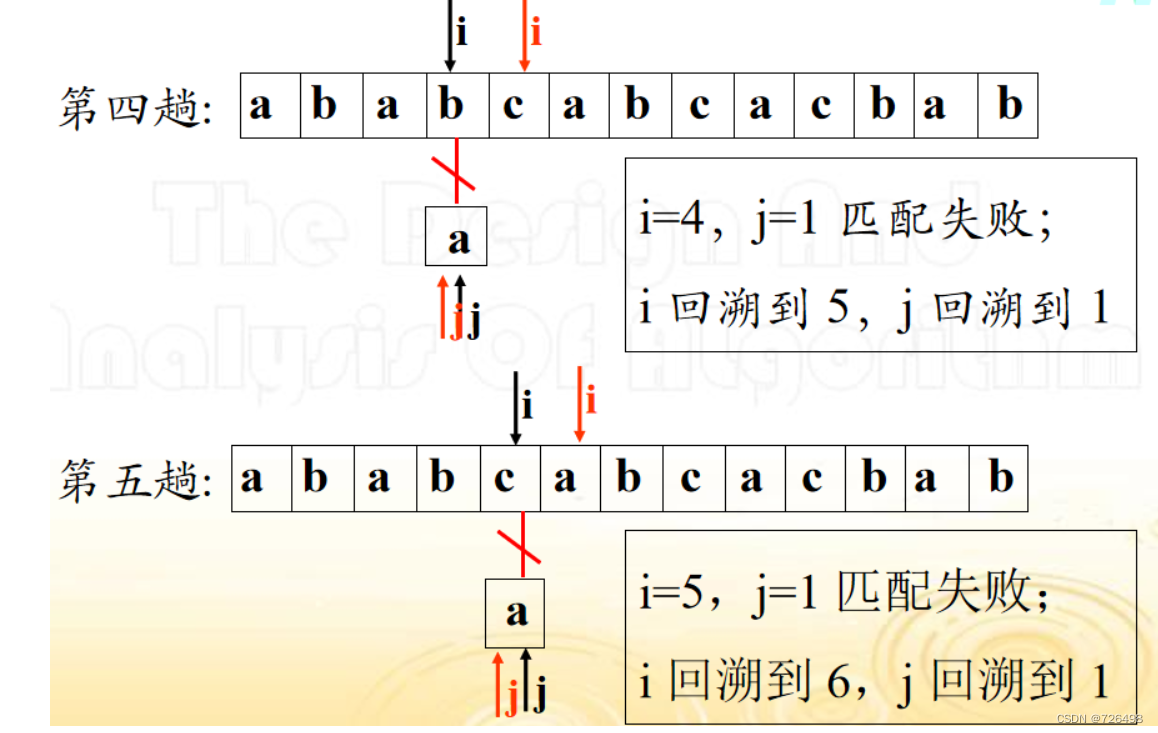

基于蛮力法的串模式匹配算法:
int StringMatch_BF(char text[], char substring[])
{
int subLen = strlen(substring);
int textLen = strlen(text);
int i, j;
for(i=0; i < textLen-sublen+1; i++)
{
j = 0;
while((j < subLen) && (substring[j]==text[i+j]))
j = j + 1;
if( j==subLen)
return i;
}
return -1
}最好情况分析:
设文本串S的长度为n,模式串T的长度为m
匹配成功
-
例子:S="This is a boy";T="This"
-
只需要一趟匹配
-
T(n,m)=m
匹配失败
-
例子:S = “This is very nice“,T = “good"
-
需要n-m+1趟匹配
-
每趟只有一次比较
-
T(n,m)=n-m+1
最坏情况分析:
匹配成功
-
例子:S = “aaaaaaaaab“;T = “aaab"
-
最后一趟匹配成功,并且每一趟匹配失败都出现在模式串T的最后一个字符
-
总共需要n – m + 1趟,每一趟需要m次比较
-
所以总的比较次数为:

匹配失败
-
例子:S = “aaaaaaaaaa“;T = “aaab“
-
匹配不成功,并且每一趟匹配失败都出现在模式串T的最后一个字符
-
总共需要n – m + 1趟,每一趟需要m次比较
-
所以总的比较次数为:

平均情况分析:
-
令

表示第i趟匹配成功所需要的平均比较次数, 那么 i 总共有 n-m+1种情况, 我们假定每种情况出项的概率均等,即为1/(n-m+1)
-
令TA(n,m) 总的平均比较次数, 则:

-
如果第i趟匹配成功, 意味着前面i - 1趟都匹配失败。 每趟匹配失败, 有可能出现在模式串的第一个字符,也有可能是第二个字符,…,也有可能是最后一个字符。假定每种情况出现的概率均等即为 1/m, 那么每趟匹配失败的平均比较次数为

,所以

总结
匹配成功
-
最好:TB(n, m) = m∈Ω(m)
-
最坏:TW(n, m) = mn - m2 + m∈O(mn)
-
平均:TW(n, m) = ((m+1)n - m2 + 3m)/4∈θ(mn)
匹配失败
-
最好:TB(n, m) = n – m + 1 ∈Ω(n)
-
最坏:TW(n, m) = mn - m2 + m ∈O(mn)
-
平均:TW(n, m) = ((m+1)n - m2 + 1)/2∈θ(mn)
四、减治法
1.减治法的基本思想
-
把原始问题变为规模较小的子问题
-
求解子问题的解(递归处理)
-
扩展子问题的解以获得原始问题的解

2.减治法的分类
-
减常数(通常减1)规模技巧(又名减一法):
-
插入排序
-
图的遍历(DFS和BFS)
-
生成排列与子集合
-
-
减常数因子(通常为2)规模技巧(又名减半法):
-
二分查找
-
俄式农夫乘法
-
假币问题
-
尤瑟夫斯问题
-
-
减可变规模技巧
-
求给定两个不同时为零的非负整数的最大公约数
-
查找第k个最小元素
-
插值查找
-
3.已学算法技巧的区别
以计算指数为例:计算a^n
-
蛮力法:
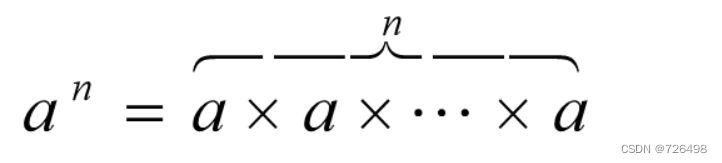
-
分治法:
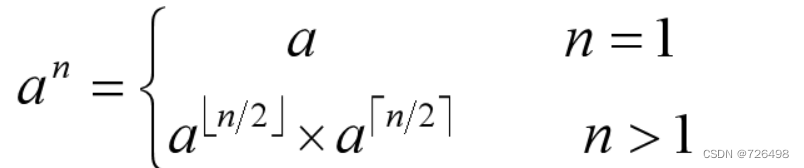
-
减一法:
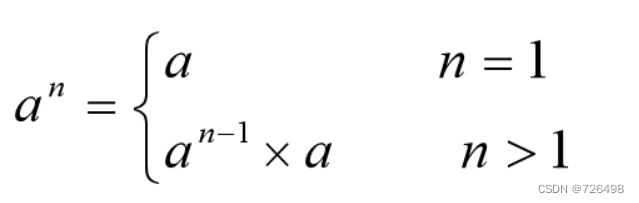
-
减半法:

4.减常数因子在查找问题中的应用
4.1二分查找
基本思想:
-
使用已排序的列表(列表按升序排列)

-
首先用列表的中间元素与查找键值比较
-
如果相等, 返回中间元素的下标,算法终止
-
如果查找键值小于中间元素的值, 则查找键值必在列表的前半部分
-
如果查找键值大于中间元素的值, 则查找键值必在列表的后半部分
-
例子:
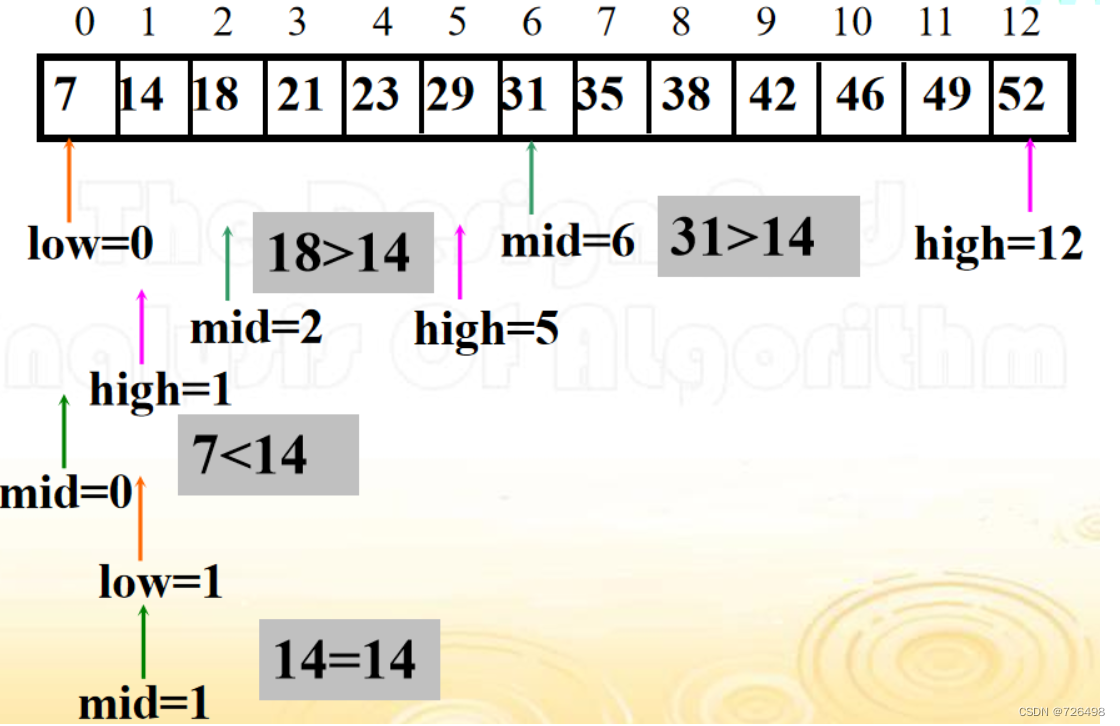
二分查找算法:
BinarySearchNR(A[0…n-1], K)
//Input: An array A sorted in ascending order and a search K
//Output: An index of the array’s element that is equal to K
or -1 if there is no such element
l <- 0; r <- n-1
while l ≤ r do
m <- (l+r)/2
if K = A[m] return m
else if K < A[m] r <- m-1
else l <- m+1
return -1
//递归写法:
binary_search_recursive(array, low, high, target)
mid <- low+(high-low)/2
if target==array[mid] return mid
else if target<array[mid]
binary_search_recursive(array,low,mid-1,target)
else if target>array[mid]
binary_search_recursive(array,mid+1,high,target)
return -1算法分析
最好情况:
-
哪些实例是最好的情况? 那些中间元素与查找键值相等的输入实例就是最好的情况。
这就意味着只需要一次比较 所以: Tbest (n) = O(1)
最坏情况:
-
哪些实例是最坏的情况? 查找键值不在列表中或是最后一趟才找到查找键值的输入实例就是最坏的情况
每一趟只需要一次比较,如果我们知道总共需要执行多少趟, 最坏情况的总比较次数就显而易见了。
如果 n = 2k-1, 则总共会执行k = log(n+1) 趟
所以非形式化地我们有
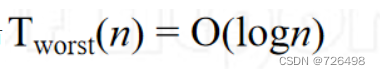
如果n是一个任意的正整数, 令

表示最坏情况的总比较次数,则

其闭合式为:
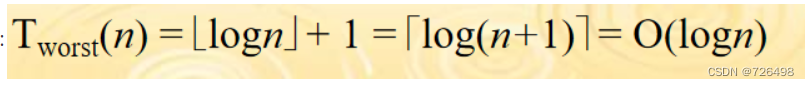
平均情况:
-
总是查找成功:
-
有多少种情况是可以查找成功的? -n 种
-
假定每种情况出现的概念均等, 其概率是多少? -1/n
-
第一趟有多少个可能的位置需要检查? -1个
-
第二趟有多少个可能的位置需要检查? -2个
-
第三趟有多少个可能的位置需要检查? -4个
-
第4趟呢?
-8个
-
所以二分查找可以表示成一个二叉树(n = 7):

-
在上述二叉树中, 我们可以看出查找 i 层上的节点需要 i 次比较;
-
第 i 层总共有 2i-1 个节点;
-
如果一个列表有 n = 2k-1 个元素,则上述二叉树有k层;
-
那么总是查找成功的比较次数为:

-
有时查找成功
-
有多少种情况是可以查找成功的
-n种
-
有多少种情况是查找不成功的
-n+1 种(要查找的关键字可位于列表第一个元素之前,任何两个元素之间,或是最后一个元素之后, 有n+1 个不同地方)
-
总共2n+1中情况,假定每种情况出现的概念均等,其概率是多少? -1/(2n+1)
-
查找成功的比较次数跟总是查找成功的情况一样(只是出现概率不同), 查找不成功的比较次数都是 k 次(如果n = 2k-1)
-
那么总是有时查找不成功的比较次数为:
-

4.2俄式农夫乘法
问题描述:计算两个给定正整数n和m的乘积
可用减常数因子方法的解法如下:
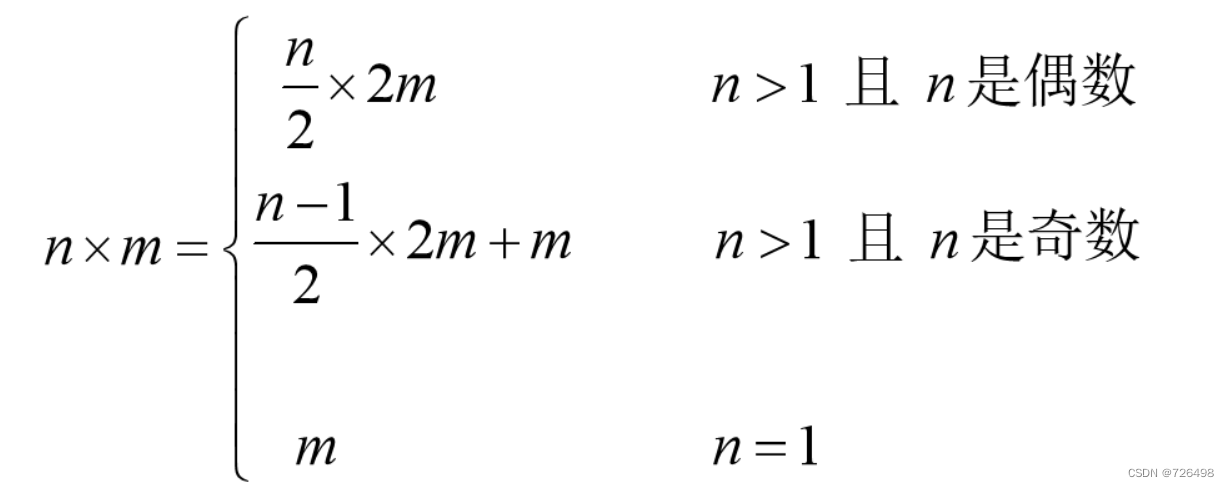
例子:计算50*65

俄式农夫乘法算法:
RusseNR(n, m)
//输入: 两个正整数 n 与 m
//输出: n 与 m 的乘积
p <- 0
while n ≠ 1 do
if n % 2 = 0 // n是偶数
n <- n/2; m <- 2 x m
else // n是奇数
n <-n/2; m <-2 x m;p <- p + m;
return p+m
//递归:
RusseNR(n, m)
//输入: 两个正整数 n 与 m
//输出: n 与 m 的乘积
if n=1 return m
if n%2=0
return RusseNR(n/2,2 x m)
else
return RusseNR(n/2,)+m
4.3假币问题
简单版本:
问题描述:
在一堆外表一样总数为n的硬币中, 有一枚硬币是假币。已知假币的重量比真币轻, 请使用不带砝码的天平秤检测出该枚假币
减常数因子2的算法:
-
基本情况: 如果只有两枚硬币,直接比较它们的重量,找出较轻的一枚。
-
分组: 将硬币分成两组,每组硬币数量相等。如果 n 是奇数,留下一枚放在一旁。
-
比较重量: 将两组硬币放在天平两端。如果天平平衡,说明假币就是旁边的硬币。如果天平不平衡,说明假币在较轻的那一组。
-
递归: 对于可能包含假币的那一组,重复上述步骤。直到找到假币。
减常数因子3的算法:
三分法的思想是将硬币分成三组而不是两组,然后根据天平的情况决定假币所在的组。
4.4尤瑟夫斯问题
问题描述: 有n个人围成一个圈,并将他们从1到n进行编号。然后从编号为1的那个人那里开始残酷的杀人游戏,每次杀掉第二个人直到只留下一个幸存者。我们的目标就是要求算出该幸存者的编号(用J(n)表示)。
例子:

为了求解J(n), 我们分别考虑n为奇数和偶数的情况
如果n为偶数, 即n=2k J(2k) = 2J(k)-1
如果n为奇数, 即n=2k+1 J(2k+1) = 2J(k)+1
问题的解:
能否将上述两种情况合并成一种情况并给出闭合形式的解(初始条件J(1) = 1)呢?
答案是肯定的, 求解如下:
-
计算 J(n),n=1,2,…,15
-
发现规律并给出闭合形式的解
-
证明解的一般性
闭合形式的解:

实用公式(便于用计算机求解):

技巧:将n的二进制数向左做一次循环移位
5.减可变规模在数值问题中的应用
5.1Euclid 算法
Euclid算法的思想是重复应用下列等式,直到m mod n = 0
GCD(m, n) = GCD(n, m mod n)
那么Euclid算法是否属于减可变规模技巧呢? (why)
答案是肯定的:如果以第二个参数n作为输入规模,那么应用一次上述等式后, n变成了(m mod n),它可以是 0到n - 1中的任何一个数
Euclid算法的时间效率是多少?
我们可以证明连续两次应用上述等式后,输入规模至少减少一半,所以 T(n) ∈O(log n)
5.2选择第k个最小元素
问题描述:给定一个列表,其包含 n 个元素,要求找出第 k 个最小元素。
-
排序法
-
蛮力法
-
基于减可变规模技巧
基于可变规模技术的算法:
基于快速排序中使用的分划思想。假定经过一次分划后产生的两个子列表如下, s 是分划位置:

假定列表中元素的编号为1到n: 如果s = k, 问题解决; 如果s > k, 在左边子列表中查找第k个最小元素; 如果s < k, 在右边子列表中查找第k-s个最小元素。
例子: 4 1 10 9 7 12 8 2 15 其中: n = 9,k = 9/2(取顶) = 5

FindkthSmallestVSD_NR(A[0…n-1], k)
//Input: An array A of orderable elements and integer k (1≤k≤n)
//Output: The value of the kth smallest element in A[0…n-1]
l ← 0; r ← n -1
While l ≤ r
p ←A[l]; j ← l
for i ← l +1 to r
if A[i] ≤ p
j ← j + 1
if j≠ i swap(A[j], A[i])
swap(A[l], A[j])
if j > k - 1 r ← j - 1
else if j < k - 1 l ← j + 1
else return A[k-1]最好情况分析:
根据分划算法, 如果每次都产生两个规模相同的子列表, 这将是最好的情况。 如果列表元素为n,分划算法需要n - 1次比较。
所以,最好情况下总比较次数的递推关系式如下:
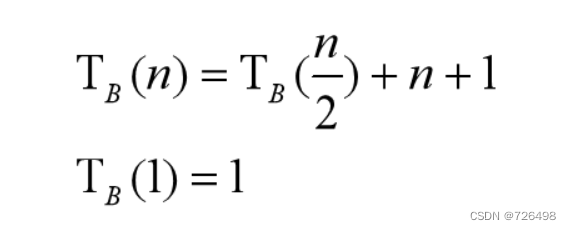
上式的闭合式为:
TB(n) = 2n – 1 + logn = Ωn)
最坏情况分析:
根据分划算法, 如果每次产生两个子列表的规模为0:n – 1,这将是最坏的情况。
如果列表元素为n,分划算法需要n - 1次比较。
所以,最坏情况下总比较次数的递推关系式如下:

上式的闭合式为:

平均情况分析:
如果列表元素为n, 每次分划轴值的位置会有n种可能,我们假定每种可能的概率均等,即为1/n
如果列表元素为n,分划算法需要n - 1次比较。
所以,平均情况下总比较次数的递推关系式如下:
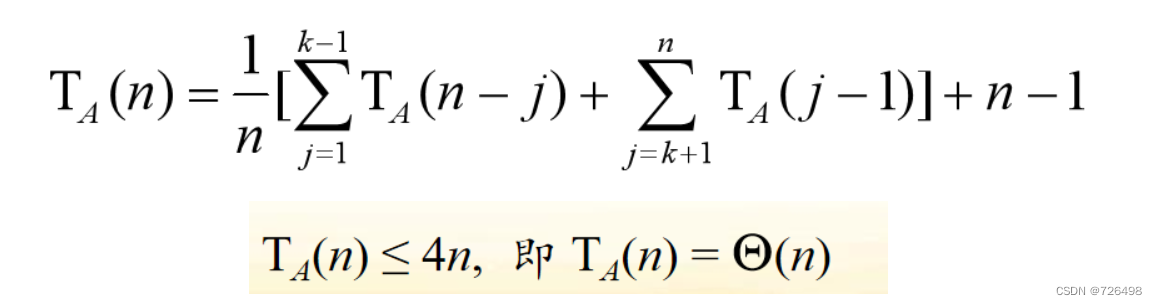
时间效率总结:
总比较次数: 最好情况: Ω(n) 最坏情况: O(kn) 平均情况: θ(n)
5.3插值查找
问题描述:跟二分查找一样,在某个排序好的列表中查找某个关键字。
思路:根据要查找关键字的值v来估算它在列表A[l … r]中的位置。
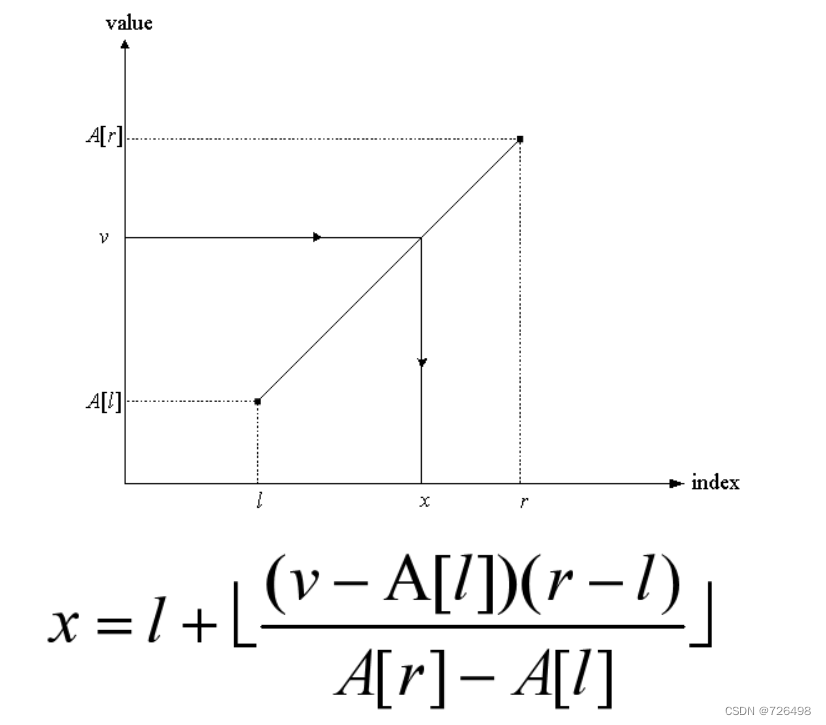
InterpolationSearch_R(A[l…r], v)
//Input: A sorted array A in increasing order and a search key v
//Output: An index of the array’s element that is equal to v or -1
if l > r return -1
else
m ← l + (v – A[l])*(r – l) /(A[r] – A[l])
if m < l m ← l
if m > r m ← r
if v = A[m]
return m
else if v < A[m]
return InterpolationSearch_R(A[l ,…, m-1], v)
else
return InterpolationSearch_R(A[m+1, …, r], v)平均情况:
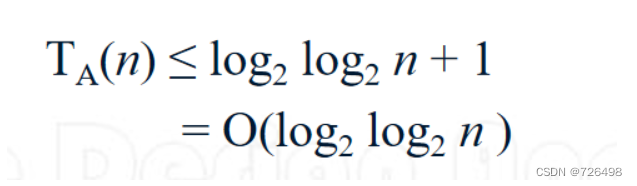
最坏情况:
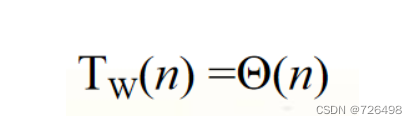
五、分治法
例子:
在有n个元素的列表中找出其最大元素和最小元素 8, 3, 6, 2, 1, 9, 4, 5, 7
基于蛮力法的算法:
max_min_BF(A, n, &e_max, &e_min)
//input:A given list A[0, …, n – 1] of n numbers
//output: The maximum and minimum element of the list
e_max ← A[0]; e_min ← A[0]
for i = 1 to n - 1
if A[i] < e_min e_min ← A[i]
if A[i] > e_max e_max ← A[i]
end for上述算法的时间效率
-
C(n) = 2n - 2
该问题能解决得更好吗?
-
当然, 可以如下处理

改进算法:
max_min_DAC(A, low, high, &e_max, &e_min)
//input:A given list A[0, …, n – 1] of n numbers
//output:The maximum and minimum element of the list
if (high – low) <= 1 // left no more than 2 elements
if A[high] > A[low]
e_max ← A[high]
e_min ← A[low]
else
e_max ← A[low]
e_min ← A[high]
end if
else // left more than 3 elements
mid ← (low + high) / 2
max_min_DAC(A, low, mid, &x1, &y1)
max_min_DAC(A, mid + 1, high, &x2, &y2)
e_max ← max(x1, x2)
e_min ← min(y1, y2)
end if
改进算法分析:
-
令T(n) 表示比较的次数, 简单起见, 我们假定n是2的幂。
-
当 n=2, 算法执行一次比较(算法第5行); 当 n>2, 算法递归调用本身2次(规模为 n/2 个元素) (算法第16和17行) 以及执行两次比较 (算法第18和19行).
-
所以算法总比较次数地推关系式如下:

-
改进算法的时间效率为:

-
原算法的时间效率为:
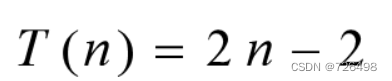
分治法图示:

分治法通用算法:

通用算法效率递推关系式:
T(n) = aT(n/b) + f (n) 其中 f(n) ∈ θ(n^d), d ≥ 0

1.分治法在排序问题中的应用
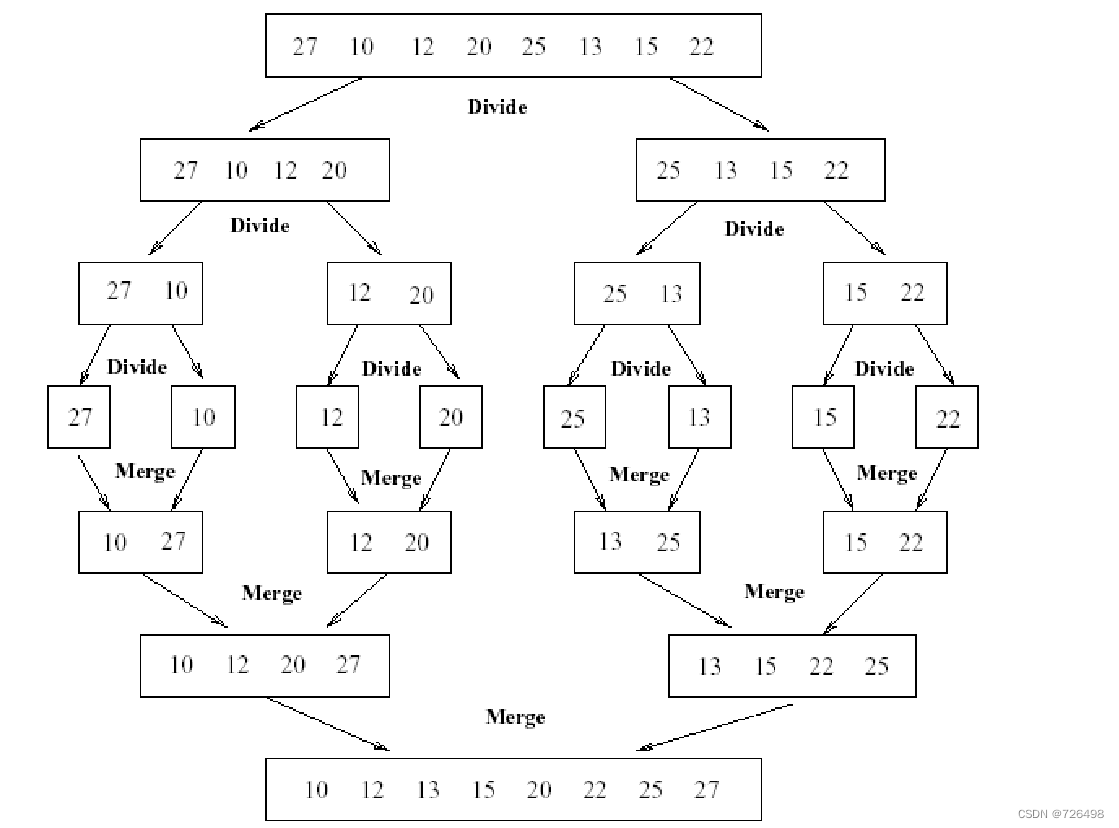
1.1合并排序
合并排序的基本思想:
合并排序是排序算法中非常重要的一员,它也是能很好地展示分治法思想精髓的一个完美例子。
其基本思想可直接从分治法思想框架导出
-
分划:把给定的列表{r1, r2, …, rn} 分成长度基本相等的** 两个子列表 {r1, r2, …, rn/2} 和 {rn/2+1, r2, …, rn}**
-
治理:分别对两个子列表进行排序(通常是以递归的方** 式),从而得到两个排好序的子列表**
-
合并:把两个已经排好序的子列表合并成一个有序列表
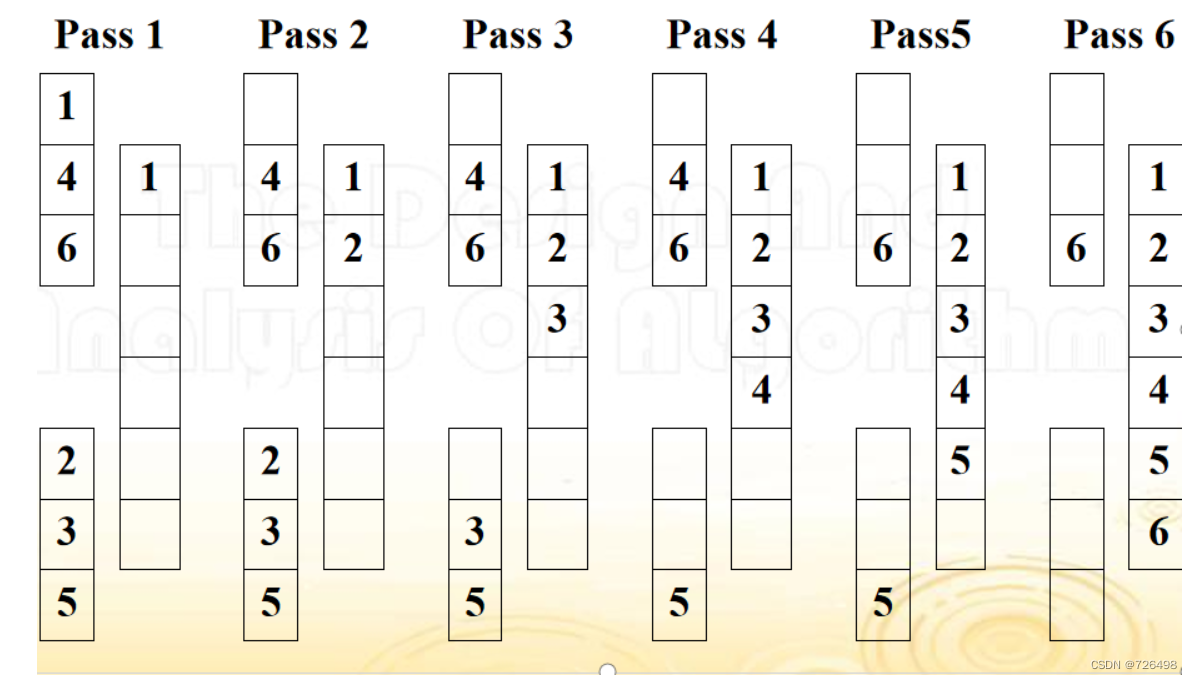
如何合并两个已排序好的列表?
两个已排好序的列表B和C合并到A,思想如下:
-
重复下面的步骤知道列表B或是C中的元素已处理完毕:
-
比较两个列表各自剩余元素中的第一个元素
-
把其中较小的元素复制到列表A的尾部, 同时被复制列表中的指针后移,指向该较小元素的后继元素
-
-
一旦某个列表中的所有元素已处理完毕, 再把未处理完列表中剩余的所有元素依序复制到列表A的尾部
两个已排序好列表合并例子
两个已排好序列表合并算法:
ALGORITHM MergeLists(A, first, middle, last)
//Input: A: both A[first...middle] and A[middle+1…last] are sorted
//Output: Sorted array A in nondecreasing order
start1 ← first; start2 ←middle+1; indexR ← 0
while (start1 ≤ middle) and (start2 ≤ last)
if A[start1] ≤ A[start2]
R[indexR] ← A[start1];
start1 ← start1 + 1
else
R[indexR] ← A[start2];
start2 ← start2 + 1
end if
indexR ← indexR + 1
end while
if start1 ≤ middle
for i ← start1 to middle
R[indexR] ← A[i];
indexR ← indexR + 1
end for
else
for i ← start2 to last
R[indexR] ← A[i];
indexR ← indexR + 1
end for
end if
indexR ← 0
for i ← first to last
A[i] ← R[indexR];
indexR ← indexR + 1
end for合并排序算法分析:
-
最好情况:
B(n) = 2B(n/2) + n/2
B(1) = 0
闭合形式:B(n) = (nlogn)/2= Ω(nlogn)
-
最坏情况:
W(n) = 2W(n/2) + n - 1
W(1) = 0
闭合形式:W(n) = nlogn-n+1=O(nlogn)
平均效率:
-
合并排序最好的时间效率增长阶为Ω(nlogn),最坏的时间效率增长阶为O(nlogn), 这意味着对任何一个规模为n的输入实例,算法所需要的比较次数为cnlogn (c是某个常数), 所以合并排序平均的时间效率增长阶为θ(nlogn)。
合并排序的几个补充问题
-
是否在位:不在位,需要额外存储空间
-
是否稳定:稳定,不改变相同元素位置
-
递归实现:
Mergesort(A[0...n])
if n>1
copy A[0..n/2-1] to B[0..n/2-1]
copy A[n/2..n-1] to C[0..n/2-1]
Mergesort(B)
Mergesort(C)
Merge(B,C,A)
Merge(B[0..p-1],C[0..q-1],A[0..p+q-1])
i=0,j=0,k=0
while i<p and j<q do
if B[i]<=C[j]
A[k]<-B[i];i<-i+1
else A[k]<-C[j];j<-j+1
k<-k+1
if i=p
copy C[j...q-1] to A[k..p+q-1]
else copy B[i..p-1] to A[k..p+q-1]1.2快速排序
快速排序的基本思想:
快速排序是另外一个能很好地展示分治法思想精髓的完美例子。 其基本思想描述如下:
-
分划: 把给定数组A[p, ..., r] 分成两个子数组 A[p, ..., q - 1] 与 A[q + 1, ..., r]
-
不变式: 子数组A[p, ..., q - 1]中的每一个元素都≤子数组 A[q+1, …, r]中的元素
-
治理:分别对两个子数组进行排序(递归处理)
-
合并: 不需要,已经排好序
ALGORITHM QuickSort(A, l, r)
//Sorts a subarray by quicksort
//Input: A subarray A[l…r] of A[0…n-1], defined by its
// left and right indices l and r
//Output: Subarray A[l…r] sorted in nondecreasing order
if l < r
s ← Partition(A, l, r) //s is a split position
QuickSort(A, l, s-1)
QuickSort(A, s+1, r)
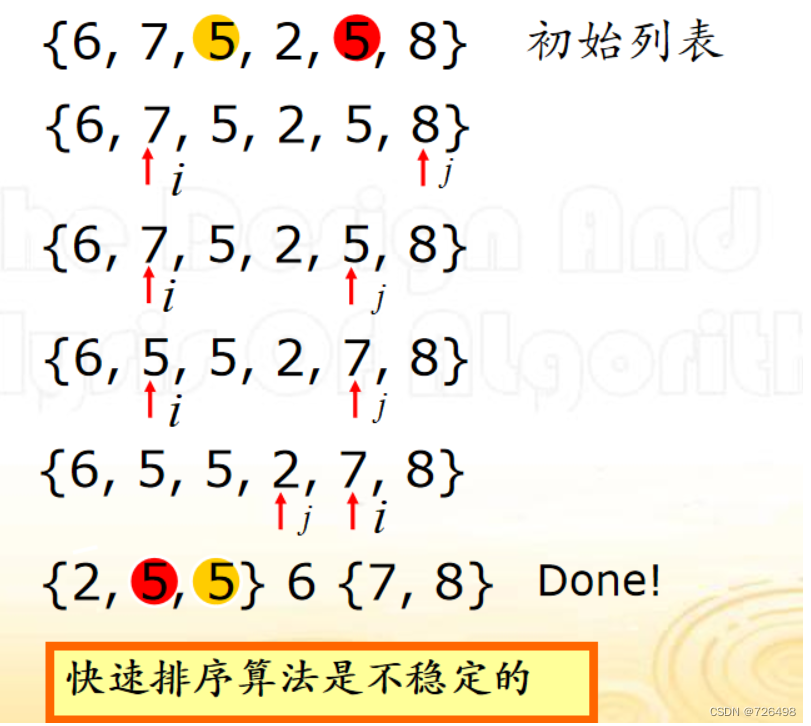
end if分化算法思想:
很明显,快速排序的主要任务是如何把原有数组分成两个满足要求的子数组,其思想如下:
-
挑选一个轴值,并根据该轴值来划分子数组
-
得到结果:
-
两个子数组由轴值分开
-
前面子数组的所有元素都小于或是等于轴值
-
后面子数组的所有元素都大于或是等于轴值
-
-
返回分开两个子数组的轴值的下标
分化算法描述:
给定数组 A[0,…,n-1], 分划如下:
-
(1) 初始: 挑选数组第一个元素作为 “轴值”, 让指针 i 和 j 分别指向数组的第二个元素和倒数第一个 元素,并让它们指向的元素同轴值进行比较
-
(2) 左扫描: 增加 i 直到A[i] 大于或是等于轴值
-
(3) 右扫描: 减少 j 直到A[j] 小于或是等于轴值
-
(4) 交换 A[i] 与 A[j]
-
(5) 重复 (2),(3) ,(4) 直到 j≤i
-
(6) 交换 A[i] 与 A[j], 交换 A[0] 与 A[j], 返回 j
ALGORITHM Partition1(A, l, r)
//Input: A subarray A[l…r] of A[0…n-1], defined by its left
// and right indices l and r (l<r)
//Output: A partition of A[l…r], with the split position
// returned as this function’s value
p ←A[l]
i ← l; j ← r + 1
repeat
repeat i ← i + 1 until A[i] ≥ p
repeat j ← j - 1 until A[j] ≤ p
swap(A[i], A[j]);
until i ≥ j
swap(A[i], A[j]) // undo last swap when i ≥ j
swap(A[l], A[j])
return j // j is the final index of pivot
ALGORITHM Partition2(A, l, r)
//Input: A subarray A[l…r] of A[0…n-1], defined by its left
// and right indices l and r (l<r)
//Output: A partition of A[l…r], with the split position
// returned as this function’s value
p ←A[l]; j ← l
for i ← l +1 to r do
if A[i] ≤ p
j ← j + 1
if j≠ i swap(A[j], A[i])
end if
end for
swap(A[l], A[j])
return j // j is the final index of pivot 例子:

最好情况:
什么情况下算法执行最快(最好情况)?
-
分划总是完美均衡的, 这就意味着原数组被分成两个几乎等长的子数组
-
最好情况时间效率: Tbest(1) = 0 Tbest(n) = 2Tbest(n/2) + n-1
-
上述递推式的闭合式是什么? T(n) = Ω(nlogn)
最坏情况:
什么情况下算法执行最慢(最坏情况)?
-
分划总是不均衡的
-
能给出最坏情况下的具体实例吗? 输入实例是已经排好序的
-
最坏情况下, 分划算法通过n-1次比较, 产生一个有 n-1元素的子数组和一个没有元素的子数组,即 T(1) = 0 T(n) = T(n - 1) + n – 1
-
T(n) = O(n^2)
平均情况分析:
-
如果输入是随机的, 快速排序平均时间效率的增长率应该更取向于Θ(nlogn),而不是O(n2)。
-
首先, 看一个直观的例子:
-
假定分划算法总是产生 9-to-1 的分划,这看上去应该相当不均衡!
-
那么时间效率递推表达式为: T(n) = T(9n/10) + T(n/10) + n-1
-
本质上讲, 现实生活中执行快速排序算法,”好”的分划与”坏”的分划应该是交替出现的。
-
它们会随机地分布在递归树中
-
不妨假定好的情况 (n/2 : n/2) 与坏的情况 (n-1 : 0)交替出现
-
那么第一次是坏的情况,接下来一次是好的情况会发生什么?
-
得到三个子数组, 规模分别为 0, (n-1)/2, (n-1)/2
-
两次产生分划总的比较次数= n-1 + n -2 = 2n -3 = O(n)
-
不比第一次就是好的分划的情况差多少
-
-
所以,1个(或是2个或是3个)不均衡的坏分划产生的比较次数 ,可被每个均衡的好分划吸收到 O(n)中
-
这样一来, ”好”的分划与”坏”的分划交替出现的时间效率增长阶仍为O(nlogn), 只不过带一个稍大一点的常数而已。
-
怎么样更严格一些呢?
-
所有分划的情况 如下:(0:n-1, 1:n-2, 2:n-3, … , n-2:1, n-1:0) 假定每种情况出现的概率均等,即为 1/n
-
令 T(n)表示平均时间效率(平均比较次数),则

1.3合并排序与快速排序的区别
分划:
-
合并排序: 按照元素在数组中的位置对它们进行划分,可立即得到两个子数组,且两个子数组规模基本相等
-
快速排序: 按照元素的值对它们进行划分,不能立即得到两个子数组,且两个子数组规模一般情况下都不相等
合并:
-
合并排序: 把两个排好序的子数组合并成一个有序数组
-
快速排序: 两个子数组已经排好序,不需要合并
时间效率最坏情况:
-
合并排序:O(n^2);
-
快速排序:O(nlogn)
稳定与否:
-
合并排序:稳定;
-
快速排序:不稳定
在位与否:
-
合并排序:不在位;
-
快速排序:在位
2.分治法在数值问题中的应用
2.1两个大整数相乘
A = 12345678901357986429 B = 87654321284820912836
小学常用算法:

基于DAC的标准算法
-
假定给定两个整数的位数n是2的幂,即n=2^k,name两个整数可拆分如下:

-
时间效率: T(n) = 4T(n/2), T(1) = 1
-
闭合形式: T(n) = n2
基于DAC的改进算法
-
为了提升算法的时间效率, 那么乘法的总次数必须降低:

-
两种方案:

-
时间效率: T(n) = 3T(n/2), T(1) = 1
-
闭合形式: T(n) = n^log3
2.2两个矩阵相乘
-
基于定义的算法:
void MATRIX_MULTIPLY(float A[][n], float B[][n], float C[][n])
{
for (int i = 0; i<n; i++)
for (int j = 0; j<n; j++)
{
C[i][i] = A[i][0] * B[0][j];
for (int k = 1; k<n; k++)
C[i][j] = C[i][j] + A[i][k] * B[k][j];
}
}-
时间效率 : T(n) = n^3 + (n^3 – n^2)
基于DAC的标准算法:
-
假定给定两个矩阵A 和 B的维数都是n x n, 且n = 2^k, 那我们就可以用分治法来求解。
-
如果 n ≥ 2,则把矩阵A,B与结果矩阵 C都分成维数为 n/2 x n/2 的4块:

-
按照分块矩阵的乘法,结果矩阵C计算如下:
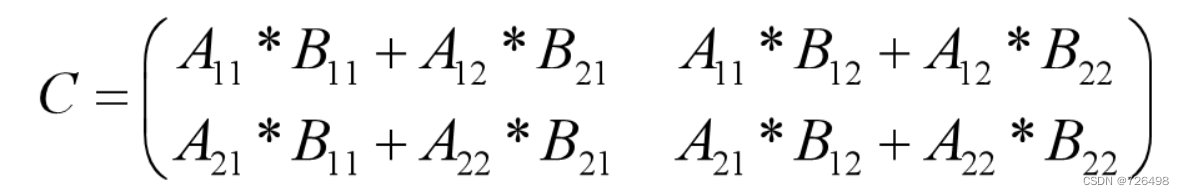
算法分析:
-
令T(n)表示算法总的乘法和加法次数,则
-
T(n) = 8T(n/2) + 4(n/2)2 if n >= 2
-
T(1) = 1
-
-
T(n) = n^3 + (n^3 - n^2)
-
实际上, 该算法需要 n^3 次乘法,n^3 – n^2 次加法,所以它不比基于定义的算法快。相反, 由于该算法的递归实现,需要更多的时间与空间。
Strassen 矩阵相乘方法
-
Strassen注意到:计算两个2阶方阵的乘积只需要7次乘法运算,所有他设计了7个公式(每个公式一次乘法)来计算两个2阶方阵的乘积
-
这些公式不要求乘法满足交换律,所以元素可以是矩阵
-
该思想可以递归应用, 比如: 两个4阶矩阵的乘积可以把每个4阶矩阵分成4个2阶矩阵。

-
首先计算7个临时值:
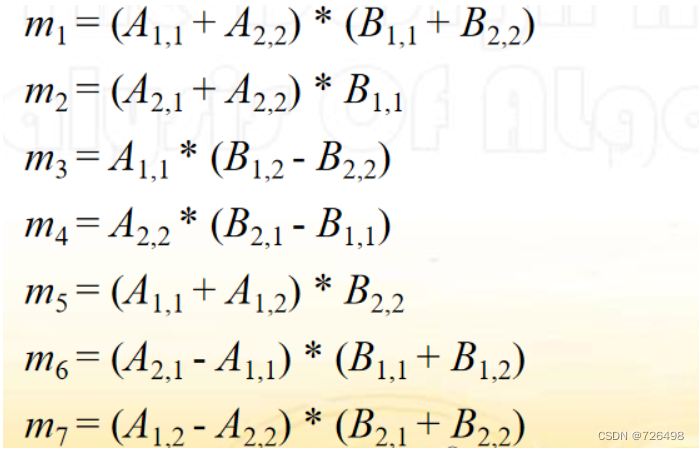

-
然后计算C1,1到C2,2:

-
两个2 X 2 的矩阵相乘使用Strassen公式需要7 次乘法,18 次加法,令T(n)表示总的乘法与加法次数,则
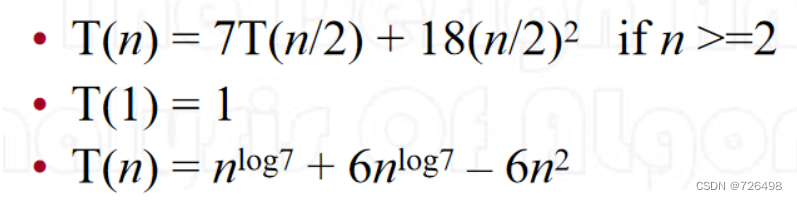
-
大约 n2.81 次乘法,6n2.81-6n2 次加法
-
定义 vs 标准DAC vs Strassen

3.分治法在组合问题中的应用
3.1Tromino谜题 (棋盘覆盖)
问题描述:
-
Tromino 是一个由棋盘上的三个邻接方块组成的L型瓦片。问题是,如何用tromino 覆盖一个缺少了一个方块(可以在棋盘上的任何位置)的2k×2k 棋盘。除了这个缺失的方块, tromino应该覆盖棋盘上的所有方块,而且不能重叠。

基于分治法的算法
基本思想:
-
把2k×2 的棋盘分成四个2^k-1×2^k-1子棋盘(见图(a))。假定缺失块在西北方向的子棋盘中, 从其它三个子棋盘中去除靠近原始棋盘中心的方块, 从东北、西南和东南方向的子棋盘中去除的三个方块刚好可由一个tromino覆盖 (见图(b))。
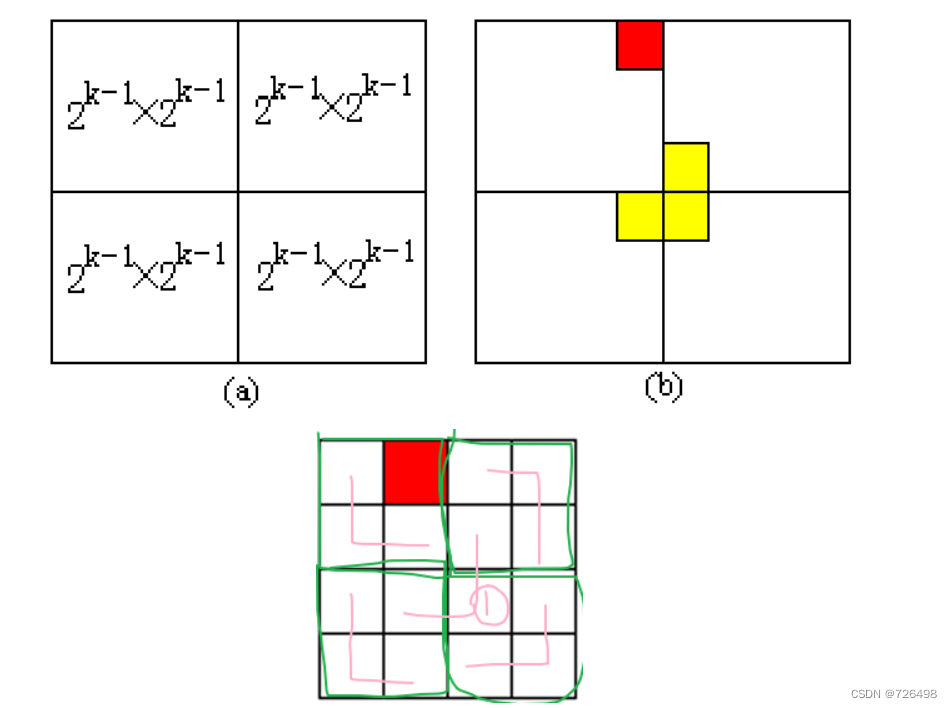
算法分析:
-
令T(k)表示覆盖任何一个2^k×2^k的棋盘所需要的操作次数,基于划分的策略, 其操作次数递推表达式可以描述如下:
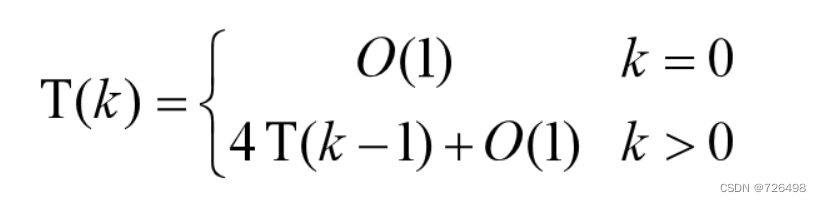
-
求解上述递推表达式可得:
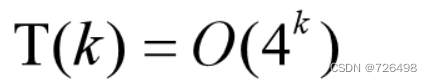
覆盖任何一个2^k×2^k的棋盘所需要的Tromino是(4^k - 1)/3个,所以该算法是最优的
六、变治法
1.变治法的基本思想
-
变治法包含一组基于“转换”思想的算法设计方法
-
第一阶段, 把原始问题的实例转换为更容易求解的实例,称为“变”的阶段
-
第二阶段,对转换的实例进行求解

2.变治法的分类
-
实例化简:转换为同样问题的一个更简单或更方便的实例
-
预排序
-
线性方程组求解
-
-
表达形式改变:转换为同样实例的不同表达形式
-
多项式计算
-
堆排序
-
-
问题规约:转换为另外一个问题,该问题的求解算法是已知的
-
最小公倍数问题
-
线性规划
-
3.实例化简在预排序中的应用
3.1预排序的应用
-
很多涉及到列表的问题,一旦给定的列表排过序后问题会更容易解决
-
查找
-
检查所有元素互异性
-
计算众值
-
-
另外:
-
预排序也常用到结合问题算法中
-
3.2数值问题中的应用-高斯消去法
线性方程组求解:
-
例子:去和求解鸡兔同笼问题
-
在许多问题中,我们需要求解一个包含n个方程的n元联立方程组

-
标准方法((cramer法则)
-
高斯消去法:
-
转换为:一个等价的由n个方程构成的n元联立方程,该方程有着一个上三角系数矩阵(消去过程)
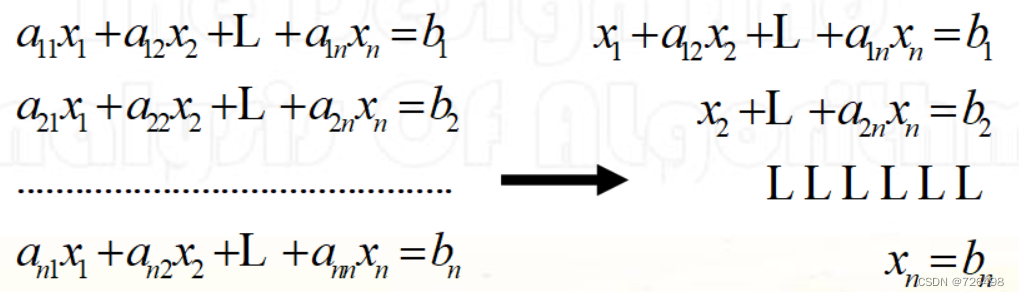
-
求解后者:从最后一个方程开始直到第一个方程 (回代过程)
-
消去过程:
从第一行到最后一行(k=1, 2, …, n), 进行下面的转换 (初等变换):
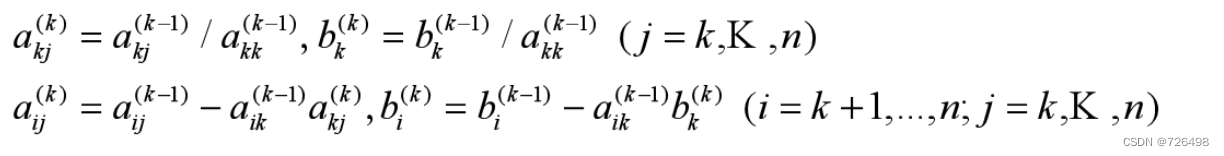
-
转换的结果为:

-
回带过程:
从最后一行到第一行 (i=n, n-1,…,1), 进行如下的回代操作:
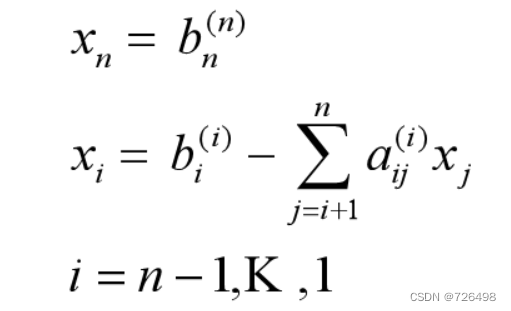
-
结果为:
-

例子:
求解:

结果:
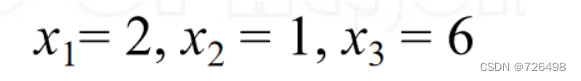
高斯消去法算法:
void GSElimination(int n, double **a, double *b)
{
int k, i, j;
for(k=0; k<n; k++) //Elimination process
{
for(j=k+1; j<n; j++)
a[k][j] = a[k][j]/a[k][k];
b[k] = b[k]/a[k][k];
for(i=k+1; i<n; i++)
{
for(j=k+1; j<n; j++)
a[i][j] = a[i][j] - a[i][k]*a[k][j];
b[i] = b[i] - a[i][k]*b[k];
}
}
//Backward substitution process
for(i=n-2; i>=0; i--)
{
for(j=i+1; j<n; j++)
{
b[i] = b[i] - a[i][j]*b[j];
}
}
} // end of algorithm算法分析:
-
消去过程的乘法次数:

-
会带过程的乘法次数:
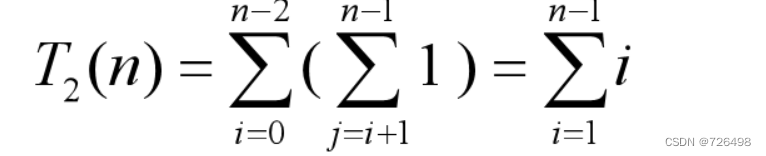
-
总的乘法次数:
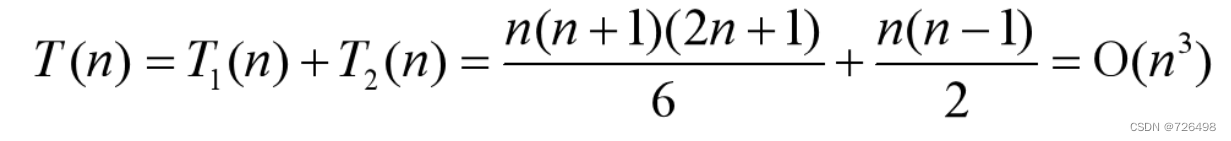
思考:
-
上述算法总是正确吗?
不是。如果A[i,i]=0, 那么它不能作为除数。
-
如何修订上述问题?
可通过第一种初等变换将第i行与该行下面的第i列不为零的某行进行交换。
-
还有其他问题吗?
是。如果A[i, i]非常小,导致A[j, i]/A[i, i] 非常大,从而 A[j, k]会因为舍入误差变得面目全非。
-
如何修订上述问题?
从第i行下面的所有行中挑选第i列绝对值最大的一行与第i行进行交换。
4.表达形式改变在数值问题中的应用
4.1多项式值得计算
问题描述:给定一个n次多项式

以及一个具体的值x,计算多项式p在该点的值。
基于蛮力法的算法伪代码:
p <- a0+ a1*x
power <- x
for i <- 2 to n do
power <- power * x
p <- p + ai * power
return p
Horner法则
-
Horner法则的思想:基于不断地把x作为公因子从降次以后的剩余多项式中提取出来:

-
例子: p(x) = 2x^4 - x^3 + 3x^2 + x – 5
-
可以方便地用一个两行的表来计算: 多项式系数 2 -1 3 1 -5 x = 3 2 3*2+(-1)=5 3 x 5 +3=18 3x18+1=55 3x55+(-5)=160
算法描述与分析
HornersMethod(p[0…n], x)
//Input: An array p[0…n] of coefficients of a polynomial of degree
// n (stored from the lowest to the highest) and a number x
//Output: The value of the polynomial at x
result <- p[n]
for i <- n-1 downto 0 do
result <- result * x + p[i]
return resultHorner法则的时间效率: # multiplications = # additions = n
5.表达形式改变在排序问题中的应用
5.1堆的概念:
定义: 给定列表{r1,r2, …, rn}, 称该列表是一个堆当且仅当其元素满足下列条件:

-
从上面的定义, 可把堆看成一个满足下述两个条件的二叉树:
-
树形要求:二叉树是几乎完全的, 即除了最后一层外其它所有层都是满的,最后一层的叶子节点靠左对齐
-
父母支配优势要求:任何节点的值≥ 其子结点的值
-
5.2堆的例子:
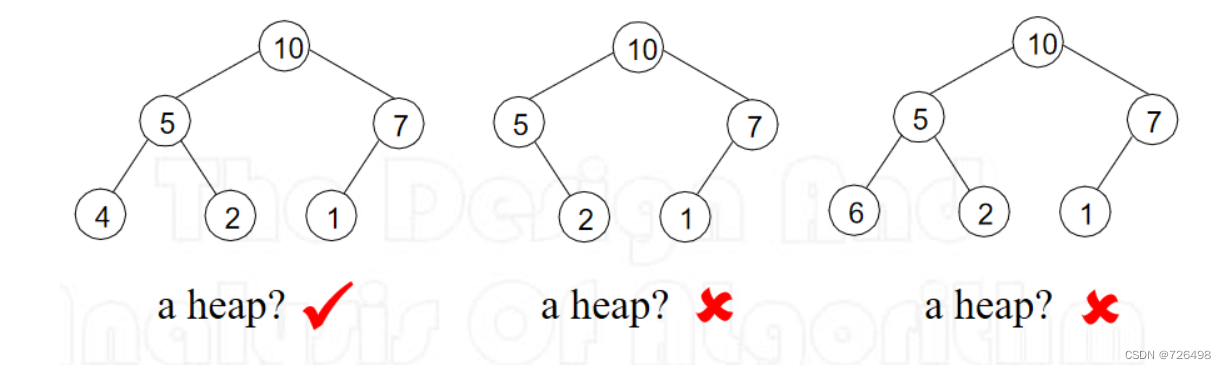
注意: 在堆中,键值是从上到下排序的,也就是说在任何从根到某个叶子的路径上,键值的序列是递减的(非递增的)。然而,键值之间并不存在从左到右的次序
5.3堆的一些重要属性
-
只存在一颗n个节点的几乎完全二叉树, 其高度

-
堆的根总是包含了堆的最大元素
-
堆的一个节点以及该节点的子孙也是一个堆
-
所有的叶子节点在h 或 h-1层
-
第i层上的节点数为2^i, 其中0≤ i ≤ h-1
-
h -1层上的分支节点靠左对齐
-
任何节点的值≥ 其子孙结点的值
5.4堆的数组表示
-
把一个几乎完全二叉树转换成一个数组:
-
根节点是A[1]
-
节点i 是A[i]
-
节点i 的父母节点是A[i/2] (注意:/是整数)
-
节点i 的左子节点是A[2i]
-
节点i 的右子节点是A[2i + 1]
-

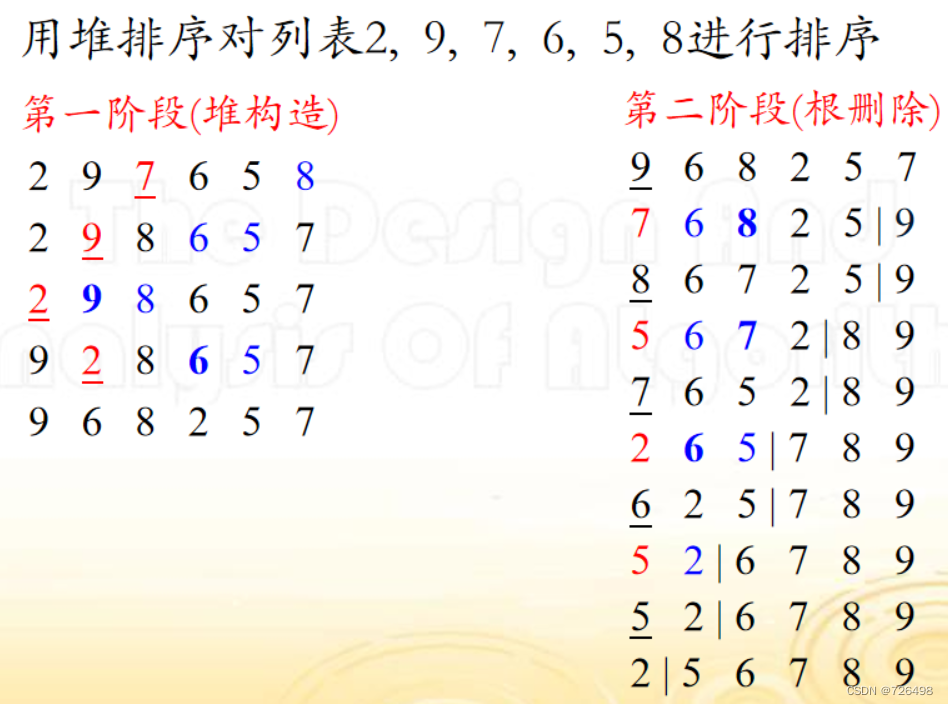
5.5堆排序
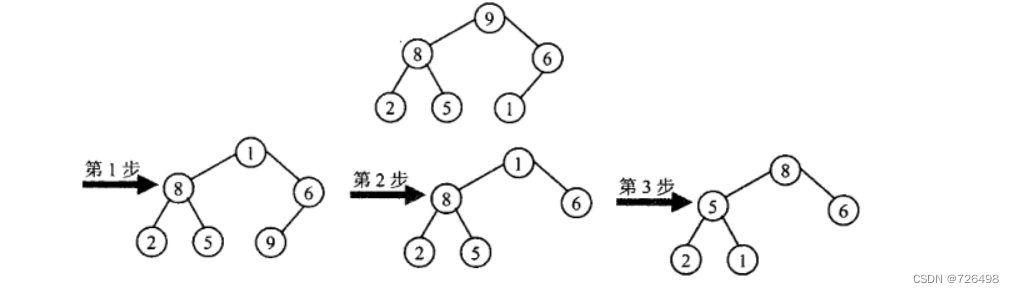
基本思想:
-
第1阶段(堆构造): 把一个给定的由n 个元素组成的列表转换成一个堆。
-
第2阶段(根删除): 重复根删除操作 n-1次:
-
把根节点的值与最后一个叶子节点(最后一层最右边的节点)的值交换
-
把堆的规模减1
-
如有需要, 重新堆化
-
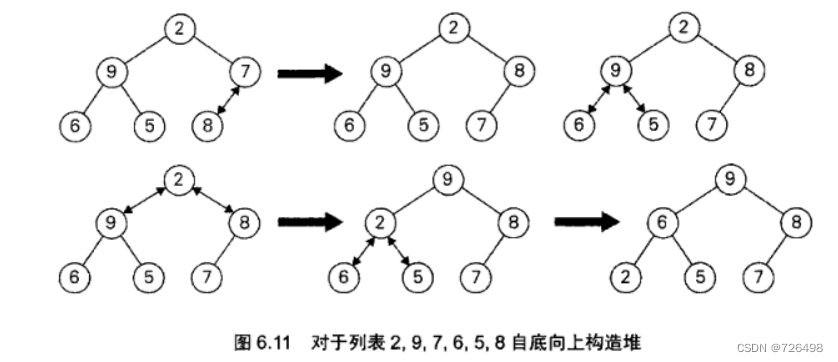
5.6堆的构造
5.6.1自底向上构造法
-
初始步: 把给定列表按元素顺序初始化为几乎完全二叉树
-
第1步: 从最后一个分支节点(最右边一个) 开始, 检查其父母支配优势要求是否成立, 如果不成立 第1.1步: 把该节点的值同其子节点中的大者进行交换 第1.2步: 检查该节点到新的位置后其父母支配优势要求是否成立,如果不成立重复第1.1步
-
第2步: 对前一个分支节点重复第1步,直到根节点
对构造例子:
根删除例子:
堆调整算法:
FixHeap(A[1…n], index, value, size)
//Input: An array A[1…n] of orderable items, the location index
and value value to fix, the size size
//Output: A heap A[1…n]
valueIndex <- index
while 2* valueIndex ≤ size do
childIndex <- 2* valueIndex
if (childIndex < size) and (A[childIndex+1]>A[childIndex])
childIndex <- childIndex + 1
if value ≥A[childIndex] break
else
A[valueIndex] <- A[childIndex];
valueIndex <- childIndex
A[valueIndex] <- value堆构造即排序算法:
HeapBottomUp(A[1…n])
//Input: An array A[1…n] of orderable items
//Output: A heap A[1…n]
for i <- n/2 downto 1 do
FixHeap(A, i, A[i], n)
HeapSort(A[1…n])
//Input: An array A[1…n] of orderable items
//Output: The A[1…n] sorted in ascending order
HeapBottomUp(A)
for i <- n downto 2 do
max <- A[1]
FixHeap(A, 1, A[i], i-1)
A[i] <- max堆排序例子:
最坏情况分析:(堆构造过程)
-
假定待排序的列表有n个元素, 那么转换成二叉树后其高度为
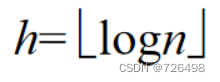
层
-
第i 层的节点往下最多移动h-i 层, 没往下移动一层需要2次比较
-
第i层的节点数为2i
-
需要做向下移动操作的层为: 0 层到 h-1层(即0≦ i ≦h-1)
-
由上述分析可得:
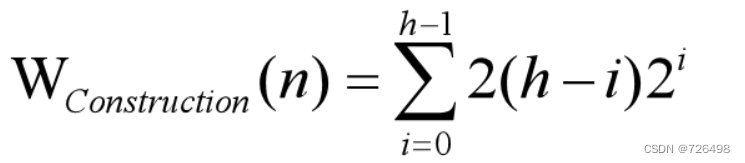
根删除过程:
-
在该过程中,从堆中删除一个元素(即堆的规模减1),然后调用FixHeap,总共需要n - 1趟。
-
在第ith趟, 堆中还剩n - i 个元素,所以二叉树的层高为
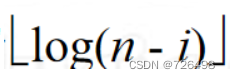
,根元素向下移动时最多需要
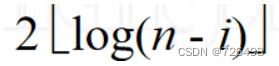
次比较 。
-
由上述分析可得:
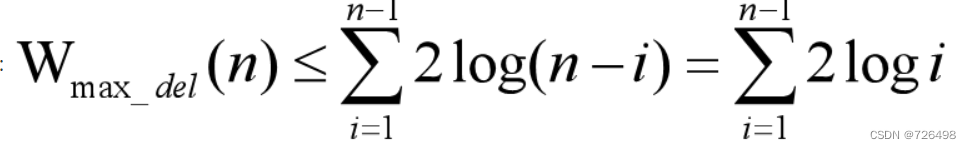
-
所以堆排序在最坏情况下总的比较次数为:
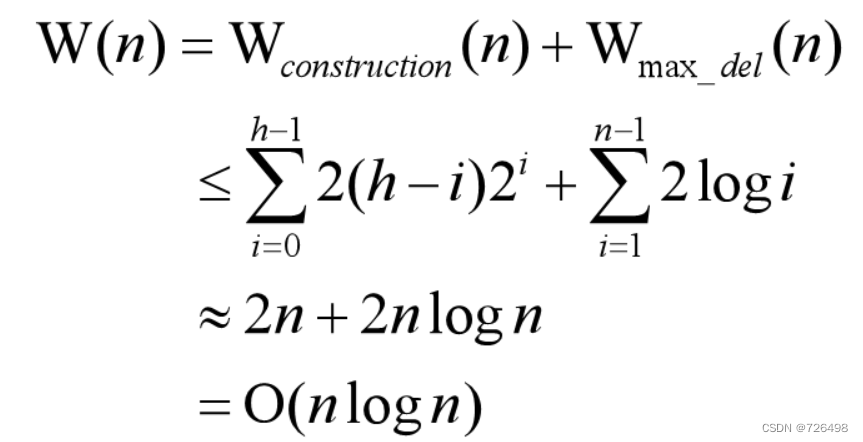
最好情况分析:
-
所有元素在初始是逆序排序的实例就是最好的情况
-
这意味着在堆构造阶段调用一次FixHeap只需要2次比较
-
堆构造阶段大约一半的元素需要调用FixHeap
-
可知: Bconstruction≈ n
-
在根删除阶段, 比较次数仍为:

-
所以堆排序在最好情况下总的比较次数为:

平均情况分析:
-
堆排序的最好情况和最坏情况分别为 Ω(nlogn)和O(nlogn), 这就意味着对于算法每一个可能的输入实例,需要的总比较次数约为cnlogn(c是某个正常数), 所以堆排序的平均情况为θ(nlogn)。
5.6.2自顶向下对构造
-
把新元素插入到已有堆的最后一个位置;
-
将新插入元素同它父母节点比较, 如果违反了堆的条件, 交换它们;
-
继续上一步操作,直到堆条件满足。
例子:

时间效率 : T(n) ≈ nlogn
七、动态规划
-
动态规划在计算机领域是用来求解能分解成交叠子问题的某些问题的一种通用算法设计技巧。
1.二项式系数计算
-
二项式系数:

-
C(n,k)的递归定义:
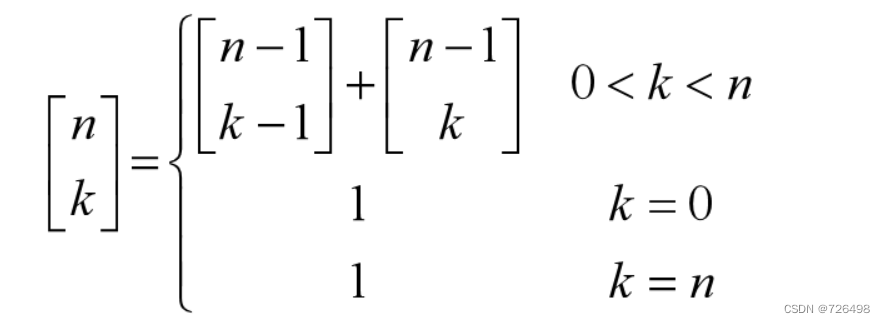
-
方法一:(递归计算)
C(n,k)=C(n-1,k-1)+C(n-1,k) C(n,0)=C(n,n)=1
-
方法二:(非递归计算)

BinomialCoefficient(n, k)
//Imput: A pair of nonnegative integers n≥k≥0
//Output: The value of C(n,k)
for i <- 0 to n do
m <- min (i, k)
for j <- 0 to m do
if j = 0 or j = i
C[i, j] <- 1
else
C [i, j] = C [i-1, j-1] + C[i-1, j]
return C[n,k]-
方法三:(显示公式)

2.1适合用DP求解的优化问题应满足的关键要素

2.2四个步骤和三个组件
-
用Dp求解优化问题的思想:
-
刻画最优解的最优子结构特征
-
给出最优解的最优值得递推表达式
-
以自底向上的方式计算最优值
-
根据上述计算信息构造最优解
-
-
DP算法的实现基于三个基本的组件:
-
一个递推表达式(用于定义最优解的最优值);
-
一个表格(用于计算最优解的最优值);
-
一个回溯程序(用于构造最优解)
-
3.DP在图中的应用
3.1全源最短路径问题
问题:给定一个有向图G = (V, E), 以及一个权函数 w: E -> R。
目标: 如果存在,求出任何一对节点间的最短路径。
需要输出: 一个V x V 的矩阵 D = (dij), 其中 dij 存储的是从节点i 到节点j最短路径的长度; 一个V x V的矩阵π = (πij), 其中πij存储的是从节点i 到节点j最短路径上节点j 的直接前驱节点。
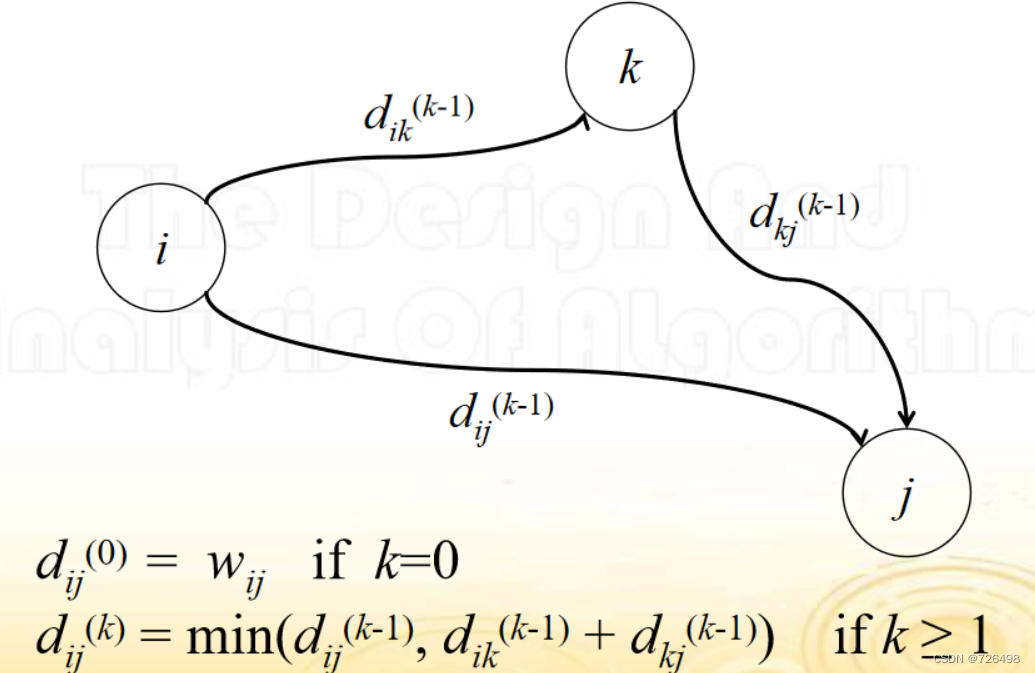
刻画最优解的最优子结构特征:
-
如果 i, v1, v2 ,…, vk-1, vk, vk+1, …, j 从节点i 到节点 j 的最短路径, 那么 i, v1, v2, …, vk-1, vk 以及 vk, vk+1, …, j 必分别是从节点 i 到节点 vk 以及从节点 vk 到节点 j 的最短路径。
定义最优优值的递推表达式:


构造最优解:
-
For k=0

-
For k>=1
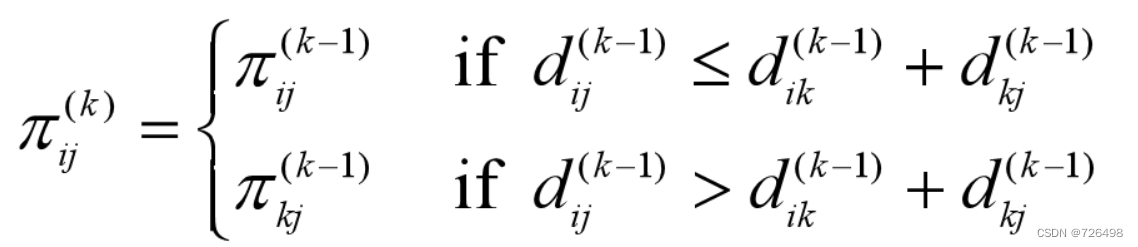
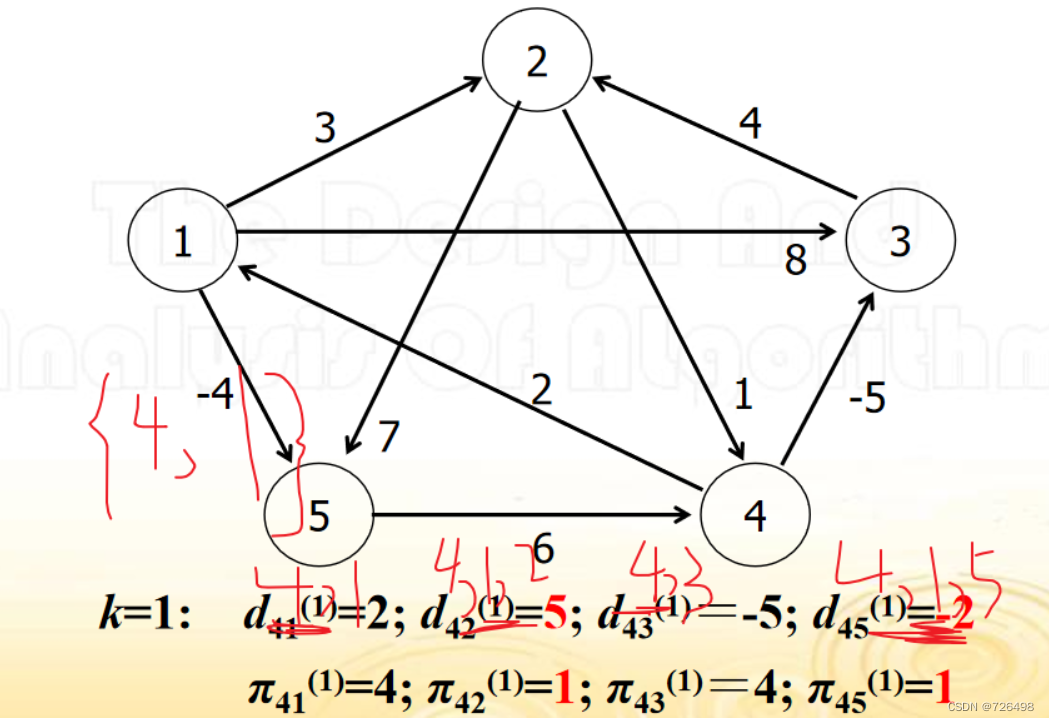
例子:




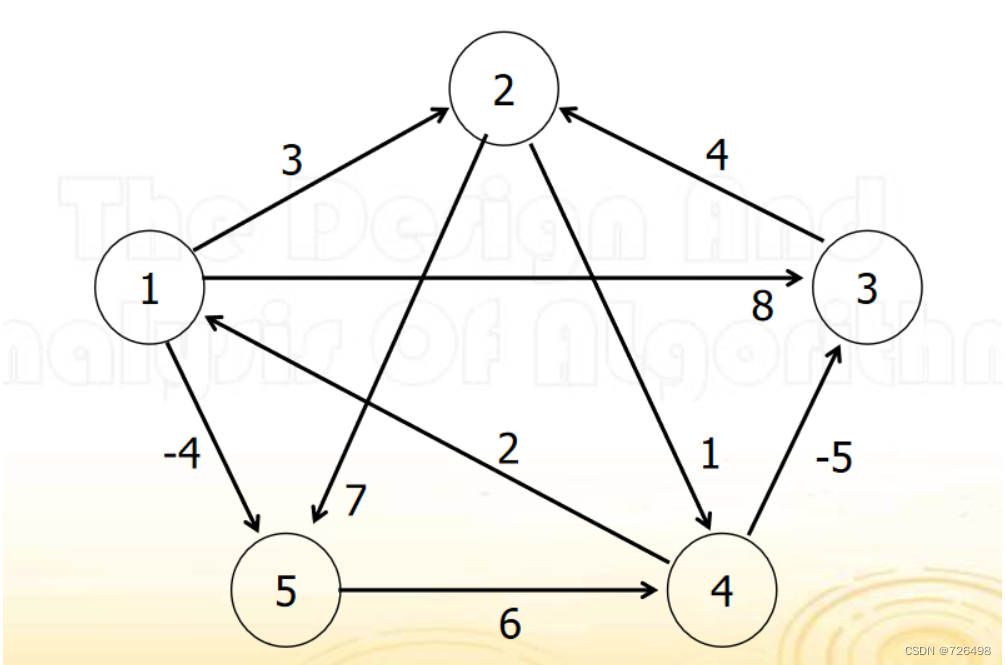
3.2Floyd算法

减少空间:

例子:


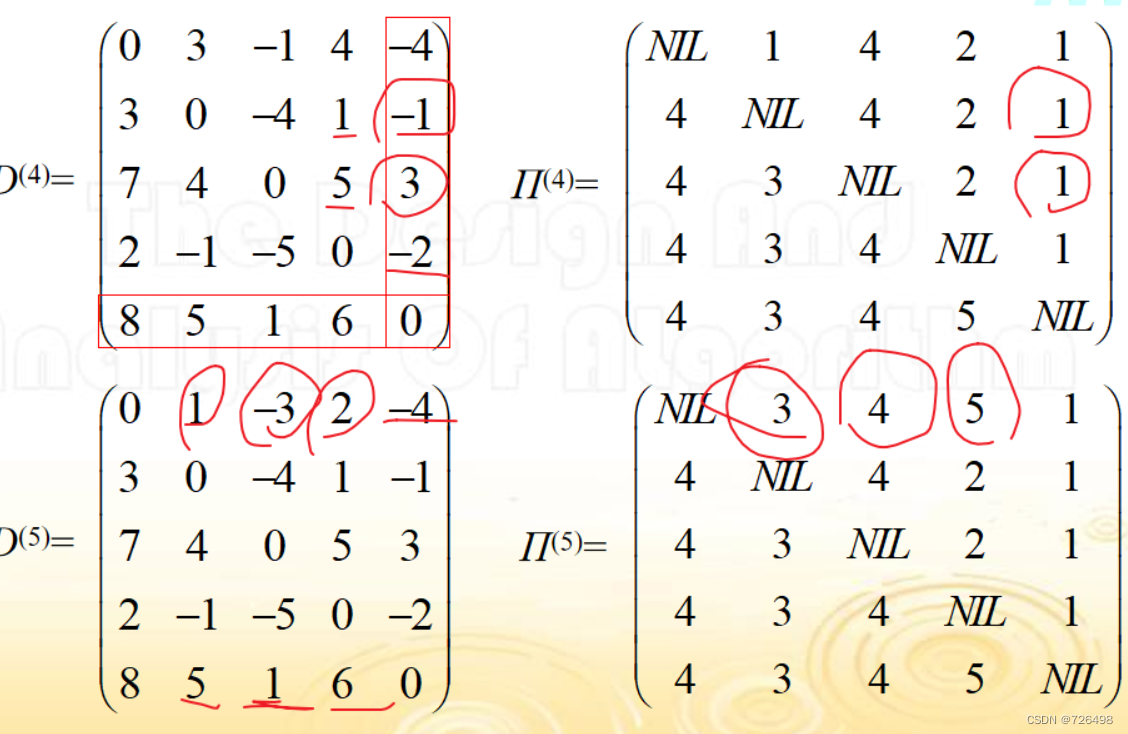
构造最优解算法:
ShortestPath (i, j,Π[1…n,1…n])
//Input: The endpoint i, j of shorted path and the matrix Π[1…n,1…n] generated by Floyd
//Output: The shortest path from i to j
if i = j
print i
else if π[i, j] = NIL
print “There is no path from” i “to” j “exists”
else
ShortestPath(i, π[i, j], Π)
print j3.3传递闭包问题
定义: 给定一个具有n个节点的有向图,其传递闭包定义为一个n-by-n的布尔矩阵 T={tij}, 如果从节点i到节点j存在一条有向路径可达,则该矩阵的第i (1≤i≤n)行第j(1≤j≤n)列的元素tij=1,否则tij=0。
例子

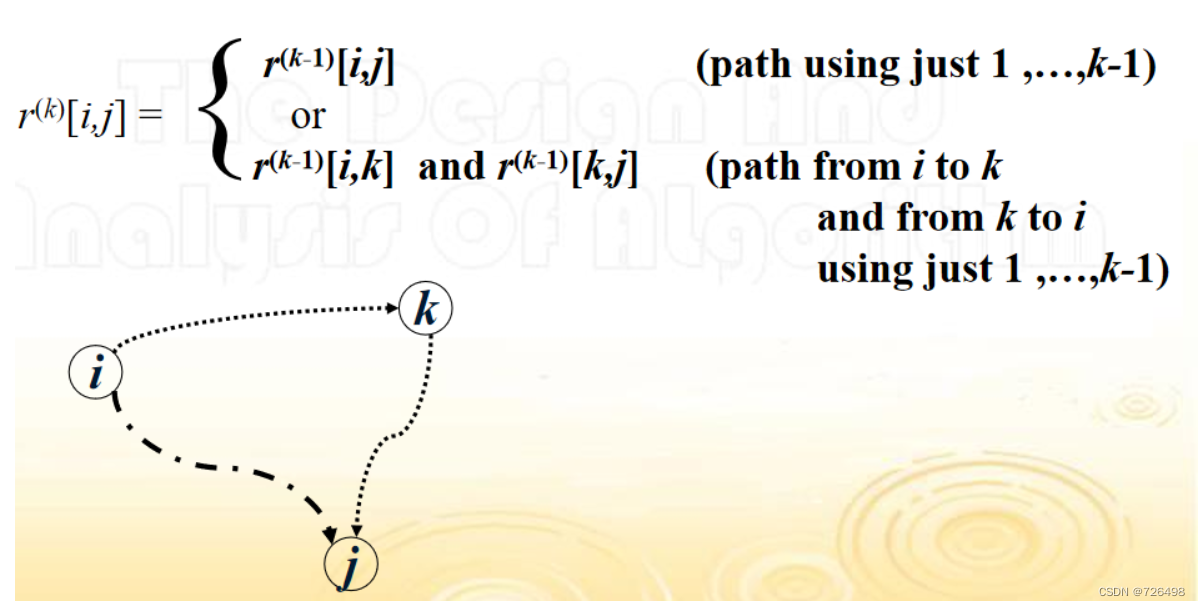
Warshall 算法(基本思想)
分阶段构造一个n-by-n矩阵序列R(0), … , R(k), … , R(n),其中 r(k)[i, j] = 1当且仅当从节点i到节点j有一条仅以前k个节点作为中间节点的有向路径可达。序列中的最后一个矩阵即为给定有向图的传递闭包。 注:R(0) = A(给定有向图的邻接矩阵), R(n) = T(传递闭包)

递推表达式:k个阶段, 任何两个结点i, j之间的路径只允许使用结点1, 2 , …, k作为中间结点:
ALGORITHM Warshall(W[1…n,1…n])
// Input: The adjacent matrix W of a digraph with n vertices
// Output: The transitive closure matrix R of the digraph
for i <- 1 to n do // Initialization
for j <- 1 to n do
R[i, j] <- W[i, j]
for k <- 1 to n do
for i <- 1 to n do
for j <- 1 to n do
R[i, j] <- (R[i, j] or (R[i, k] and R[k, j]))
return R
Time efficiency: Θ(n3)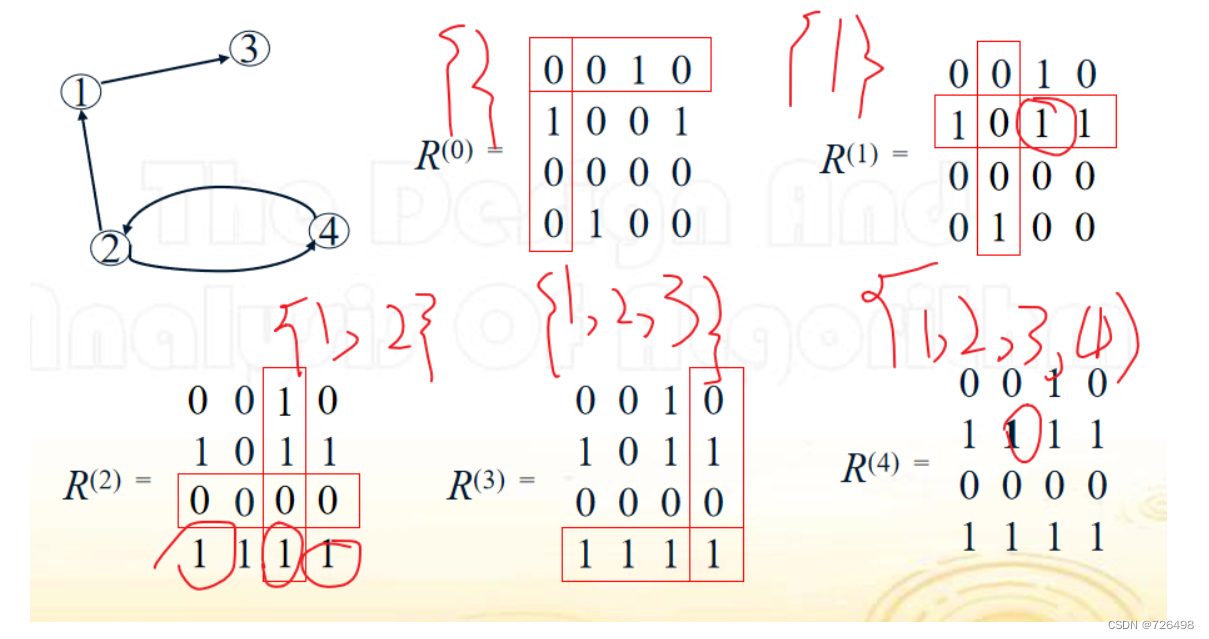
4.DP在组合问题中的应用
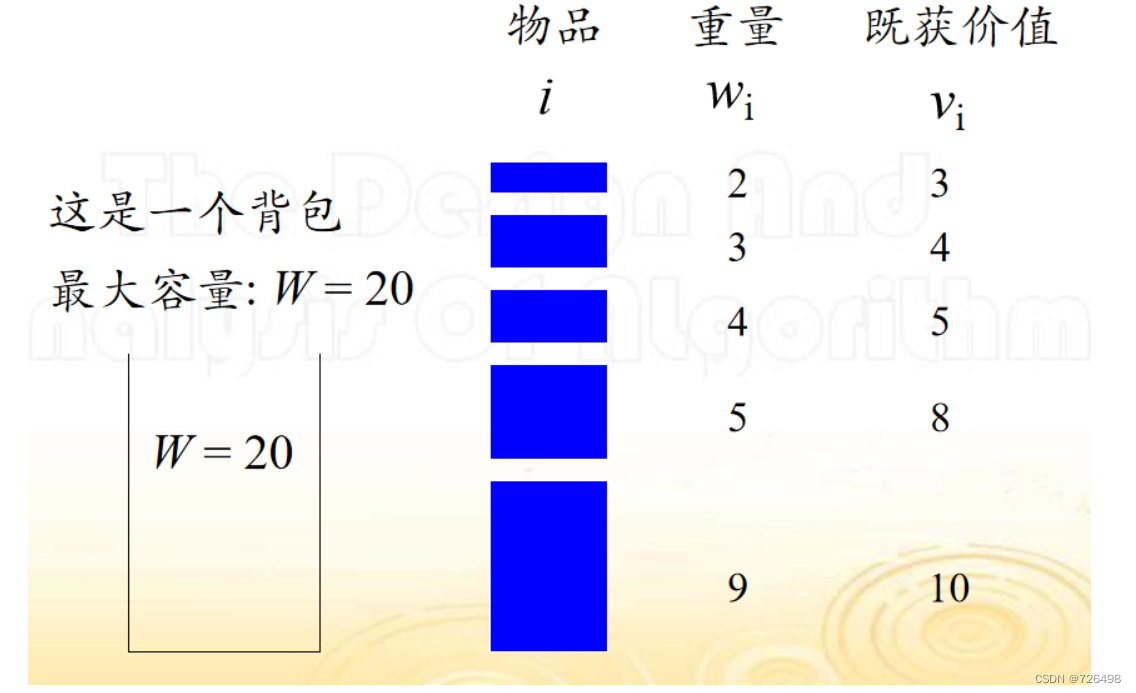
背包问题
-
给定一个容量为W的背包, 以及一个由n个物品组成的物品集
-
每个物品i 都有相应的重量wi 和既获价值vi (所有wi , vi以及W都是整数)
-
问题: 如何从物品集中挑选物品放入背包以使得总的既获价值最大而又不超出背包的容量?
可分背包问题
-
在往背包中装物品时,可以把物品掰开,只装该物品的一部分,即为可分背包问题。
-
令 xi (0≤xi≤1) 表示物品i装进背包的比率,那么可分背包问题可建模如下:

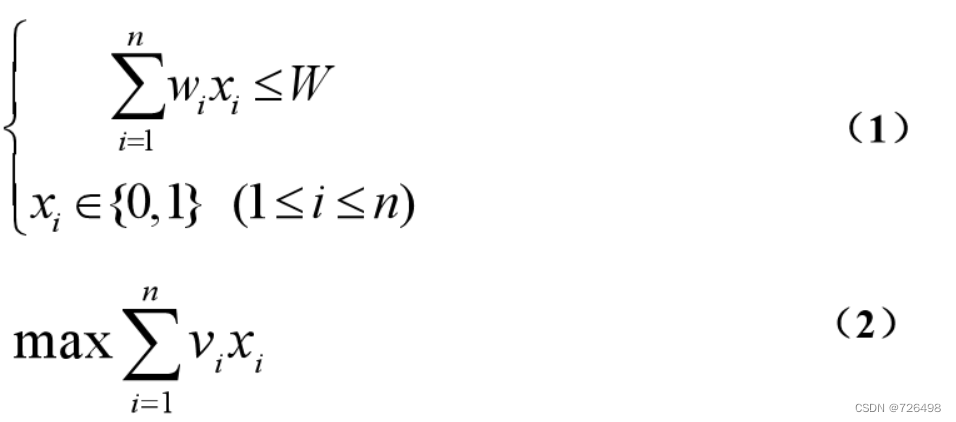
-
目标:求解满足约束(1)和目标函数(2)的解向量 X = (x1, x2, …, xn)
0-1背包问题
-
在往背包中装物品时,每个物品要么全部装要么不装,即为0/1背包问题。
-
令 xi (xi∈{0, 1})表示物品i装进背包的比率,那么可分背包问题可建模如下:
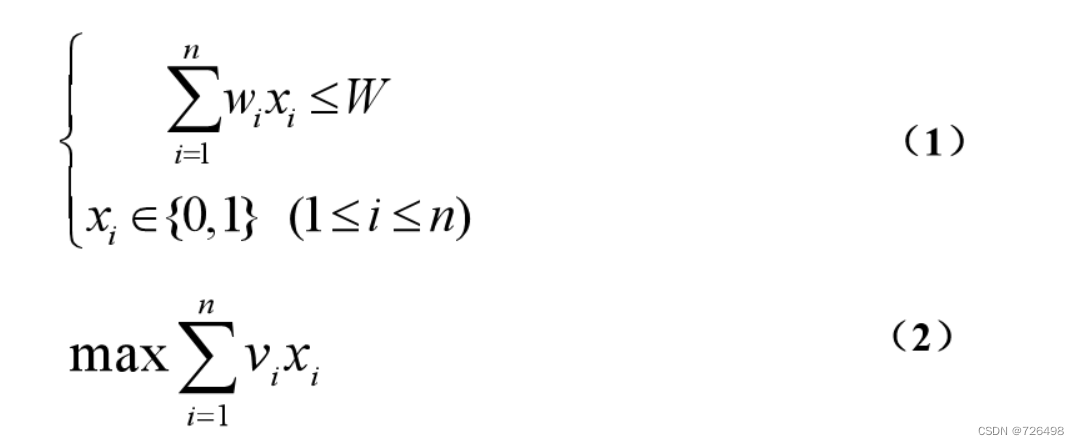
-
目标:求解满足约束(1)和目标函数(2)的解向量X = (x1, x2, …, xn)
穷举搜索--蛮力法
基本思想:
-
以系统的方式把所有可能的解生成一个列表
-
对所有可能的解一个一个评估, 去除那些不可行(不满足约束条件)的解, 对于优化问题, 一直追溯目前最好的解
-
直到所有可能的解评估完毕,最后那个最好的解就是最优解
基于穷举法的背包问题求解:

基于动态规划的背包问题求解
-
首先需要仔细地定义子问题
试试如下的定义: 如果物品编号为 1..n, 那么子问题可定义为:在物品集Si = {物品编号 1, 2, .. i}中寻找最优解
-
这显然是一个有效的子问题定义方式,且子问题是重叠的
-
问题是: 原始问题(Sn )的最优解能否包含子问题(Si)的最优解? 即最优子结构属性是否满足?
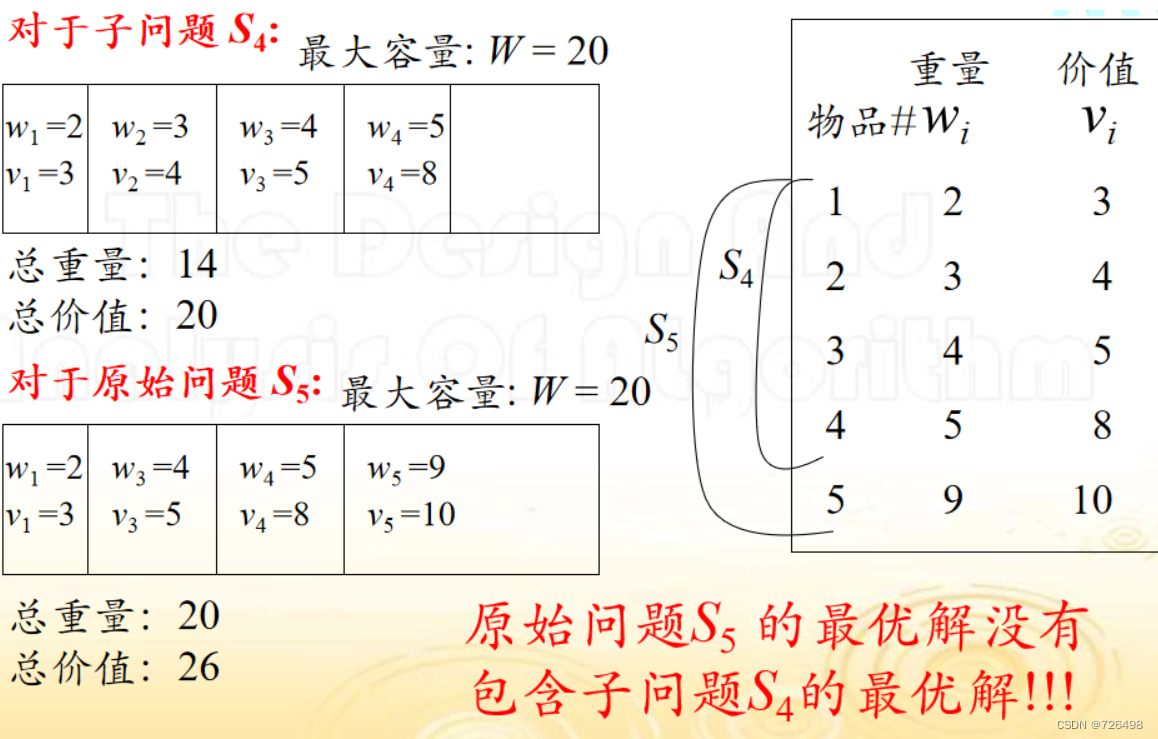
-
正如我们所看到的,原始问题S5 的最优解没有包含子问题S4的最优解
-
所以我们上述定义子问题的方式存在瑕疵,怎么修正呢?
-
需要增加另外一个变量: j, 用于表示目前为止背包所剩余的容量
-
给定一个容量为W的背包, 以及一个由n个物品组成的物品集S。 假定 (y1, y2, …, yn) 上述0/1 背包问题的最优解, 那么 (y1, …, yk) 必是下述子问题的最优解:

定义最优值的递推表达式
-
令 V[i, j] 表示从前i个物品中选择物品装入剩余容量为j(j W)的背包中所取得的最大价值,即子问题S(i, j)的最优值。
-
最优值的递推表达式可定义如下:

计算最优值
DPKnapsack(w[1…n], v[1…n], W)
// Input: Arrays w[1…n] and v[1…n] of weights and values of n items, knapsack capacity W
// Output: Table V[0…n, 0…W] that contains the value of an optimal subset in V[n, W] and from which the items of an optimal subset can be found
for i <- 0 to n do V[i, 0] <-0
for j <- 1 to W do V[0, j] <-0
for i <- 1 to n do
for j <- 1 to W do
if j ≥ w[i]
if V[i-1, j - w[i]]+v[i] > V[i-1, j]
V[i, j] <- V[i-1, j - w[i]]+v[i]
else V[i, j] <- V[i-1, j]
else V[i, j] <- V[i-1, j]
return V[n, W], V时间效率: O(nW)
构造最优解算法:
KnapsackOptimalSolution(w[1…n], v[1…n], W, V[0…n,0…W])
// Input: Arrays w[1…n] and v[1…n] of weights and values of n items, knapsack capacity W, and V[0..n, 0…w] generated by DPKnapsack
// Output: List T[1…k] of the items composing an optimal solution
k <-0 // Number of items composing an optimal solution
j <- W // Unused knapsack capacity
for i <- n downto 1 do
if V[i, j] > V[i-1, j]
k <- k +1
T[k] <- i // Including item i
j <- j – w[i]
if j=0 break
return T八、贪心法
例子:找零钱问题
-
问题描述:给定币制d1, … , dm , 每种币制的纸币数量无限,如何用最少张数的纸币找零钱n。
-
例: d1 = 100, d2 =50, d3 =20, d4 =10, d5 =5, d6 = 2, d7 = 1 ,零钱 n = 66
-
解为: d2 + d4+ d5+ d7=66
-
问题的解
-
对任何“规范”币制总能得到最优解。
-
对任意的币制一般不能得到最优解。
-
1.基本思想
通过一系列步骤来构造问题的解,每一步对到目前为止所构造的部分解进行一个扩展,直到获得问题的完整解为止。其核心是所做的每一步选择必须满足以下三个条件:
-
可行的(feasible):即它必须满足问题的约束;
-
局部最优的(locally optimal):即它是当前步骤中所有可行选择中最佳的局部选择;
-
不可撤销的(irrevocable):即选择一旦做出,在算法的后面步骤中就无法改变了。
对有些问题, 一系列局部的最优选择对于它们的每一个实例都能产生一个全局最优解;对大多数问题可能不是这种情况,但它能快速地得到一个近似解,所以贪心法仍是有价值的。
如何判断一个具体的问题是否适合用贪心法求解以及能否得到该问题的最优解呢?
最好的策略就是举反例,如果要严格的数学证明,一般有两种:
-
数学归纳法
-
反转法
另外,适合贪心求解的问题必须有以下两个特征:
-
最优子结构属性:原始问题的最优解一定包含子问题的最优解
-
贪心选择策略:问题的全局最优解一定可以通过一系列局部最优选择获得
2.贪心的通用算法
Greedy(C) //C is the input set, i.e., candidate set
{
S = { }; //S is the solution set, initially empty
while (not solution(S)) //solution() is a function to check
whether S is a complete solution of the problem
{
x = select(C); //select() is a function to do greedy selection in C
if feasible(S, x) //feasible is a function to check whether the
extended solution satisfy the constraints
S = S + {x};
C = C - {x};
}
return S;
}3.生成树问题
生成树:给定一个连通图G=(V, E),包含图G所有顶点的一个连通无环的子图T称为图G的生成树.
连通图G的生成树T(n个顶点,m条边)有下列属性:
-
连通无环;
-
无环,且m = n-1;
-
连通,且m = n-1;
-
无环,但在T中任意不相邻接的两顶点之间增加一条边,就得到唯一的环;
-
连通,但删除T中任一条边后,便不连通;
-
T中每一对顶点之间有唯一一条真路(n≥2)。
带权图:每条边都以实数赋权的图称为带权图。
当G是带权图时, 常将其表示为有序三元组G = (V, E, f), 这里f是一由边集E到实数集R的函数 f:E->R。
最小生成树(MST):设G=(V, E, f)是一连通带权图,T是G的一棵生成树,T的边集用E(T)表示,T的各边权值之和W(T)=
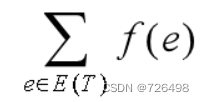
称为T的权。G的所有生成树中权最小的生成树称为G的最小生成树。
最优子结构属性:
最小生成树问题满足最优子结构属性:
-
令T是图G的一颗最小生成树,(u,v)是T的一条边
-
从T中删除边(u,v),得到两颗子树T1 和 T2
-
则:T1图G1 = (V1, E1)的最小生成树, 且T2图G2 = (V2, E2)的最小生成树 (V1与V2会共享结点吗? 为什么?)
-
它们是 T 的两个非空子集,它们的并集是整个顶点集 V。也就是说,V1∩V2=∅V1∩V2=∅,而V1∪V2=V V1∪V2=V。
因此,T1 和 T2 不共享结点,它们的顶点集合是互不相交的。这是因为从最小生成树 T 中删除一条边 (u, v) 会将 T 分割成两个非相交的连通分量,每个分量对应一个子树。所以,V1∩V2=∅ V1∩V2=∅。
-
-
证明: w(T) = w(u,v) + w(T1) + w(T2)
-
证明:
首先,我们注意到 T1 和 T2 是 T 的两个连通分量,因为它们是通过删除一条边 (u, v) 而形成的。
现在,我们来证明 G1 和 G2 分别是 T1 和 T2 的最小生成树。我们将证明的步骤分为两个部分:
部分一:G1 是 T1 的最小生成树。
考虑 T1,它是通过从 T 中删除边 (u, v) 而得到的。我们假设存在比 w(T1) 更小的生成树 T1',则 T1' 必定是不包含 (u, v) 的生成树。
现在,我们可以将 T1' 和边 (u, v) 结合成一个新的生成树 T'。由于 T' 包含所有的顶点,并且没有包含环路,所以 T' 是图 G 的生成树。然而,由于 T 是最小生成树,w(T) 小于等于 w(T')。
由于 T' 不包含边 (u, v),因此 w(T') 小于 w(T1'),这与假设 T1' 是 T1 的最小生成树矛盾。因此,我们得出结论:G1 是 T1 的最小生成树。
部分二:G2 是 T2 的最小生成树。
类似地,考虑 T2,它是通过从 T 中删除边 (u, v) 而得到的。我们假设存在比 w(T2) 更小的生成树 T2',则 T2' 必定是不包含 (u, v) 的生成树。
现在,我们可以将 T2' 和边 (u, v) 结合成一个新的生成树 T'。由于 T' 包含所有的顶点,并且没有包含环路,所以 T' 是图 G 的生成树。然而,由于 T 是最小生成树,w(T) 小于等于 w(T')。
由于 T' 不包含边 (u, v),因此 w(T') 小于 w(T2'),这与假设 T2' 是 T2 的最小生成树矛盾。因此,我们得出结论:G2 是 T2 的最小生成树。
综合部分一和部分二,我们证明了最小生成树问题满足最优子结构属性,即:
w(T)=w(u,v)+w(T1)+w(T2)
这就完成了证明。
-
4.最小生成树问题有两种贪心选择策略
4.1 最近点策略(Prim算法)
-
Prim算法通过一系列不断扩张的子树来构造一个最小生成树。
-
初始子树T1只包含一个顶点(从顶点集合中任意选择一个),然后每次往子树中增加一个顶点,使子树不断长大,得到一系列不断扩张的子树 T2, T3, …, Tn-1,直到最小生成树Tn产生。
-
每一次迭代, 会从不在子树Ti的顶点集中选择一个离已在子树Ti中的顶点最近的顶点加入到子树Ti中,以构造子树Ti+1, ( “贪心选择”)
-
直到所有顶点都包含其中,算法终止。
算法实现:
MST-PRIM(G)
//Imput: A weighted connected graph G=(V, E)
//Output: T, the set of edges composing a minimum spanning tree of G and U, the vertices
T <- ∅
U <- {v0} /*(v0 is an arbitrary node in V) */
N <- V-{v0}
for i <- 1 to |V|-1 do
find a minimum-weight edge e=(u, v) among all the edges
such that u is in U and v in N
T <- T ∪{e}
U <- U∪{v}
N <- N-{v}
return T
Prim算法的堆实现
MST-PRIM(G)
T <- ∅
U[0] <- true
for j <- 1 to n-1 do
W[j] <- ∞ U[j] <- false
for each j <- Adj[0] do
P[j] <- 0; W[j] <- c[0][j]; INSERT(H, j)
for i <- 1 to n-1 do
j <- DELETEMIN(H); T <- T ∪{(P[j], j)}; U[j] <- true
for each k <- Adj[j] do
if U[k]==false and c[j][k]<W[k]
P[k] <- j; W[k] <- c[j][k]
if k∉H INSERT(H, k)
else SIFTUP(H, k)
return T