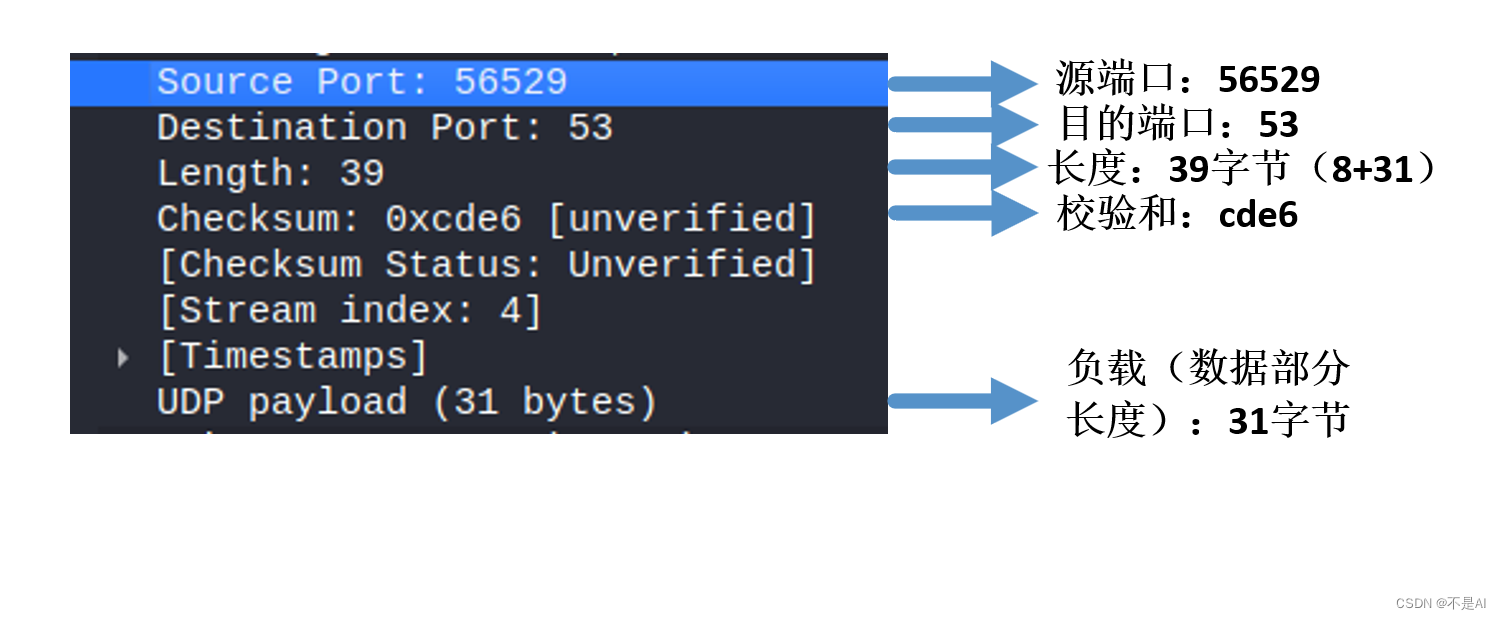
防弹防线:彻底击败Redis缓存穿透问题
- 前言
- 1. 缓存穿透定义和成因
- 定义:缓存穿透的隐秘入侵
- 成因分析:揭秘缓存穿透的幕后黑手
- 故事描述
- 2. 缓存穿透的影响
- 对数据库的影响:当缓存不再是盾牌
- 对性能的影响:缓慢的毒药
- 故事式描述
- 3. 防御策略
- 布隆过滤器:智能守门员
- 空值缓存:筑起虚空的防线
- 请求验证:精确打击非法请求
- 4. 最佳实践
- 代码示例
- 工具与资源
- 结论
前言
在缓存的世界里,有一个幽灵般的存在 —— 缓存穿透。它悄无声息地穿过缓存的防线,直击数据库的要害。如果不加以防范,它可能像一场突如其来的风暴,给你的系统带来灾难性的后果。但别担心,本文将作为你的指南,带你揭开缓存穿透的神秘面纱,教你如何建立坚不可摧的防线。
1. 缓存穿透定义和成因
定义:缓存穿透的隐秘入侵
缓存穿透是一个术语,描述了当请求查询的数据在缓存中不存在时(也不存在于数据库中),请求便会“穿透”缓存层直接查询数据库。在正常情况下,缓存系统会减轻对数据库的访问压力,但在缓存穿透的情况下,大量的无效请求会直接落在数据库上,导致数据库负载激增,甚至可能导致服务瘫痪。在Redis这样的缓存系统中,这个问题尤为突出,因为其高性能特性常被用来应对大量的读操作。
成因分析:揭秘缓存穿透的幕后黑手
-
恶意攻击:
- 描述: 攻击者可能会故意请求缓存中不存在的数据。例如,他们可能会尝试各种不同的查询参数或键值,希望找到系统的漏洞。
- 目的: 这种攻击通常旨在使应用程序变慢或崩溃,从而达到拒绝服务的效果。
-
系统缺陷:
- 设计缺陷: 如果系统没有妥善处理不存在的数据请求,例如未设置合理的默认行为或缓存策略,那么即使是正常的用户行为也可能导致缓存穿透。
- 数据不一致: 在有些情况下,缓存和数据库之间的数据不同步也可能导致缓存穿透。例如,一个项从数据库中删除了,但缓存中的数据没有及时更新。
-
错误的用户输入:
- 无效请求: 用户错误的输入,如错误的ID或查询参数,如果没有妥善处理,也可能导致请求直接查询数据库。
- 缺乏验证: 系统未能验证输入的有效性,也可能导致大量无效查询穿透缓存层。
故事描述
想象一座拥有高墙防御的城堡 —— 这是你的缓存系统,守卫着数据库这座城市的安全。但是,一群幽灵般的敌人(无效请求)找到了一条秘密通道,可以直接穿过城墙,攻击城市(数据库)。城市的守卫(数据库服务器)不得不亲自上阵抵御这些幽灵,导致本可以避免的巨大压力和混乱。这就是缓存穿透的场景,而你的任务是找到并封闭这些秘密通道,保护你的城市免受幽灵的侵扰。
在下一节中,我们将探讨如何有效预防和应对缓存穿透,构建一个更加安全和可靠的缓存系统。
2. 缓存穿透的影响
对数据库的影响:当缓存不再是盾牌
-
负载激增:
- 描绘场景: 在没有缓存穿透的情况下,Redis缓存就像一个勇敢的守卫,保护着数据库不受无休止查询的围攻。但一旦发生缓存穿透,这个守卫就变得无能为力,大量的查询请求像洪水一般涌向了数据库。
- 影响分析: 数据库需要处理远远超过平常的请求量,这可能导致响应时间延迟,甚至在极端情况下,数据库服务可能完全崩溃。
-
资源耗尽:
- 详述: 数据库服务器有限的资源(如CPU、内存、IO)在处理这些额外的请求时会迅速耗尽。这不仅影响到受攻击的服务,还可能影响到同一数据库服务器上的其他服务。
- 后果: 这种资源耗尽可以导致服务质量下降,甚至导致整个系统变得不稳定。
对性能的影响:缓慢的毒药
-
响应时间增加:
- 现象描述: 当缓存无法拦截大量请求时,这些请求直接落在了数据库上。每个请求的处理时间都会增加,因为数据库相比缓存而言处理速度要慢得多。
- 用户体验: 用户可能会遇到长时间的加载和响应延迟,这直接影响到用户的满意度和留存率。
-
系统整体性能下降:
- 连锁反应: 不仅仅是数据库受到影响,应用服务器也需要处理更多的等待和响应逻辑。这会增加应用服务器的负担,导致整个系统性能下降。
- 潜在影响: 长期来看,如果缓存穿透问题频繁发生,可能会导致硬件过早老化,增加维护成本,甚至需要更频繁的硬件升级。
故事式描述
想象一下,你的系统是一条高效运转的交通网络,Redis缓存是高速公路,数据库是城市中的小路。平时,大部分车辆(请求)都在高速公路上快速通行。但当发生缓存穿透时,所有车辆都被迫涌入小路,导致拥堵和混乱,整个交通网络的效率急剧下降。司机(用户)开始感到不耐烦,因为他们的目的地(请求结果)变得遥遥无期。
3. 防御策略
缓存穿透问题可能给系统带来灾难性的后果,但幸运的是,有多种策略可以有效地预防和缓解这个问题。下面是三种常用的防御策略:
布隆过滤器:智能守门员
-
原理简介:
- 如何工作:布隆过滤器是一种空间效率很高的数据结构,它可以告诉你某个元素是否在一个集合中。它使用多个哈希函数将元素映射到位数组中的几个点。如果检查时所有点都是1,那么元素可能存在;如果任何一个点是0,则元素一定不存在。
- 适用场景:对于缓存穿透问题,布隆过滤器可以作为请求的第一道防线,用来检查请求的数据是否有可能存在于数据库中。
-
应用于缓存穿透:
- 设置过程:首先,将所有可能的有效数据的标识(例如ID)添加到布隆过滤器中。然后,每次缓存查询前先查询布隆过滤器。
- 效果:如果布隆过滤器说数据一定不存在,就可以直接拒绝请求,避免查询数据库。这样,即使请求是非法的或恶意的,也不会对数据库产生影响。
空值缓存:筑起虚空的防线
-
策略说明:
- 核心思想:即使一个查询的结果是空(即数据在数据库中不存在),也将这个“空”结果缓存起来。这样,下次相同的查询来时,直接从缓存中返回空结果,而不需要再次查询数据库。
- 实施注意:给这些空结果设置一个较短的过期时间,避免长时间内有效数据被错误地判定为不存在。
-
优势与考量:
- 减轻数据库压力:这种方法可以显著减少对数据库的无效查询。
- 慎用原则:过多的空结果缓存可能会占用大量缓存空间,应根据实际情况和业务需求适度使用。
请求验证:精确打击非法请求
-
实施验证:
- 参数检查:对每个请求的参数进行严格的格式和合法性检查。比如,如果你知道ID应该是一个整数,那么任何非整数形式的ID都应该直接被拒绝。
- 行为分析:对请求模式进行分析,识别出异常行为,如短时间内大量访问不同的不存在数据。
-
防御效果:
- 直接拦截:通过拦截不合法或不合理的请求,可以直接减少对后端数据库的无效查询。
- 动态调整:结合实时监控,可以动态调整验证规则,应对潜在的攻击或异常行为。
4. 最佳实践
防御缓存穿透是一项重要的工作,要求开发者不仅要理解潜在的问题,还需要掌握一系列实用的工具和策略。以下是一些代码示例和推荐的工具与资源,以帮助你实现和加强对缓存穿透的防御。
代码示例
-
布隆过滤器实现 (伪代码):
from pybloom_live import BloomFilter # 假设我们预计将有10000个元素,误报率为0.001 bloom = BloomFilter(capacity=10000, error_rate=0.001) # 添加元素到布隆过滤器中 for item in existing_data: bloom.add(item) # 检查元素是否可能存在 def is_possible(item): return item in bloom -
空值缓存策略 (伪代码):
def get_data(key): # 尝试从缓存中获取数据 data = cache.get(key) if data is None: # 数据不存在,查询数据库 data = db.query(key) if data: # 如果数据库中有数据,缓存结果 cache.set(key, data) else: # 如果数据确实不存在,缓存空值 cache.set(key, "EMPTY", timeout=30) # 30秒后过期 return data
工具与资源
-
工具:
- Redis Bloom: Redis的模块,提供了布隆过滤器的功能。这是直接在Redis中实现布隆过滤器的好方法。
- Google Guava: Java的一个库,其中包含了布隆过滤器的实现。
- 监控工具: 如Prometheus, Grafana等,帮助你实时监控缓存和数据库的性能。
-
资源:
- 官方文档: 阅读Redis的官方文档,了解其各种数据类型和模块的使用方法。
- 博客和案例研究: 阅读关于缓存穿透和其他缓存问题的博客文章和案例研究,了解其他人是如何解决这些问题的。
- 社区和论坛: 加入Redis相关的社区和论坛,如Stack Overflow上的Redis板块,与其他开发者交流经验和策略。
结论
实现有效的缓存穿透防御策略需要深入理解问题的本质,并结合实际情况采取适当的技术和方法。通过使用布隆过滤器、空值缓存以及严格的请求验证,你可以大大减少缓存穿透的风险。同时,利用现有的工具和资源,你可以更快地实施这些策略,并保持对最新最佳实践的了解。记住,防御缓存穿透是一个持续的过程,需要不断地监控、评估和调整策略。


![[Angular] 笔记 18:Angular Router](https://img-blog.csdnimg.cn/direct/20be427c23b54e0fad6b8485d64ba820.png)