文章目录
- visdrone数据集转化为MOT数据集
- MOT17 数据集格式
- train
- det.txt
- gt.txt
- seqinfo.ini
- test
- det.txt
- visdrone——Task 4_ Multi-Object Tracking
- 配置seqinfo.ini文件
- 代码如下
- Linux
visdrone数据集转化为MOT数据集
MOT17 数据集格式
├── MOT17
│ ├── images
│ ├── labels_with_ids
train
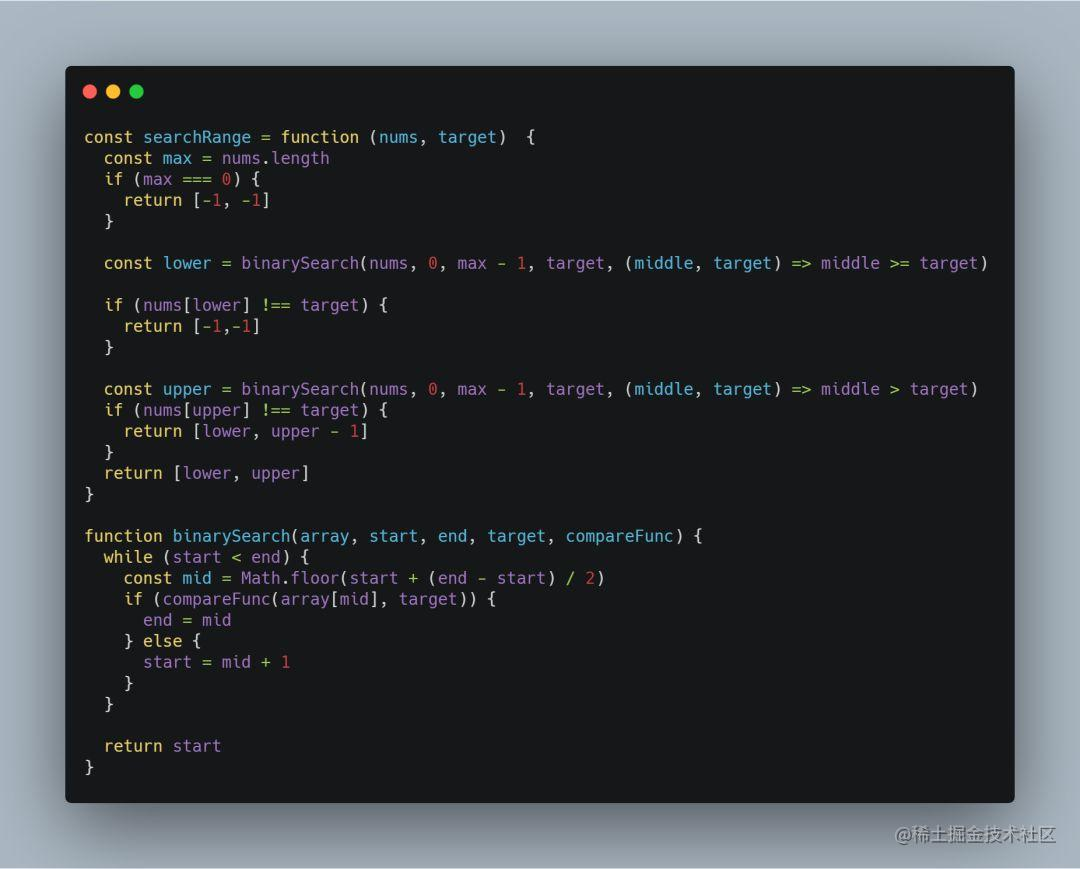
det.txt
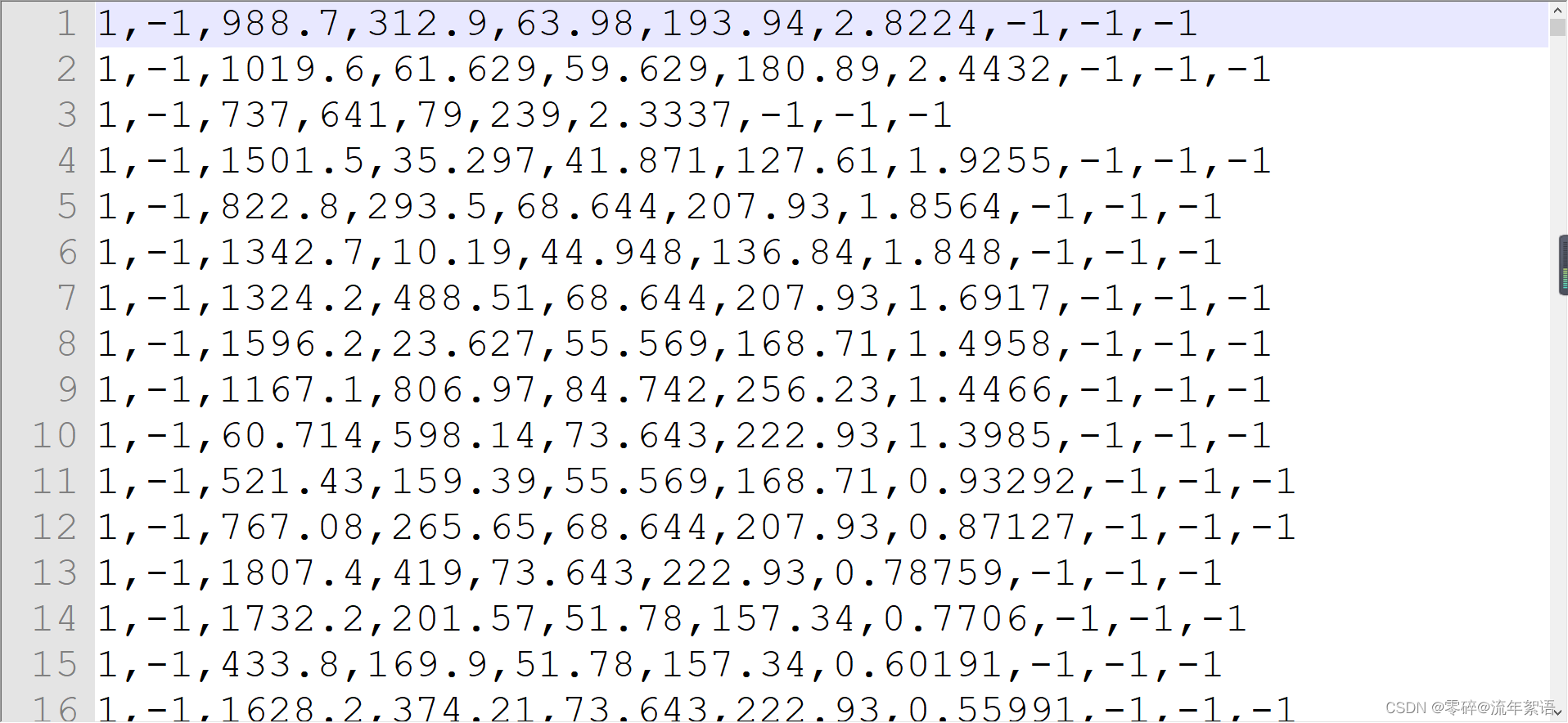
10个参数 或者 8个参数
<frame>, <id>, <bb_left>, <bb_top>, <bb_width>, <bb_height>, <conf>, <x>, <y>, <z>
- 第1个代表第几帧
- 第2个代表轨迹编号(在这个文件里总是为-1)
- bb开头的4个数代表物体框的左上角坐标及长宽
- conf代表置信度
- 最后3个是MOT3D用到的内容,2D检测总是为-1.
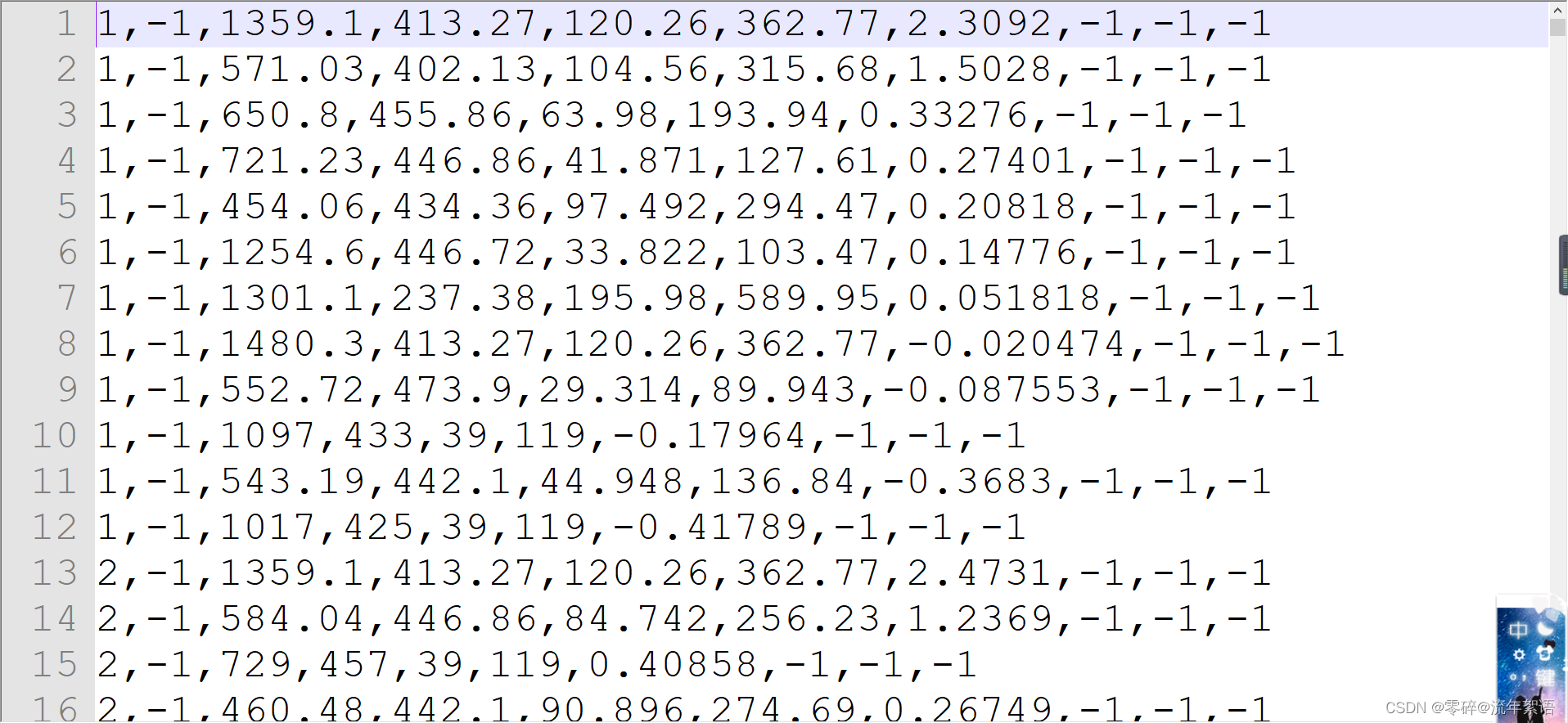
gt.txt
9个参数
- 第1个代表第几帧
- 第2个值为目标运动轨迹的ID号
- 第3个到第6个数代表物体框的左上角坐标及长宽
- 第7个值为目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active
- 第8个值为该轨迹对应的目标种类(种类见下面的表格中的label-ID对应情况)
- 第9个值为box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。
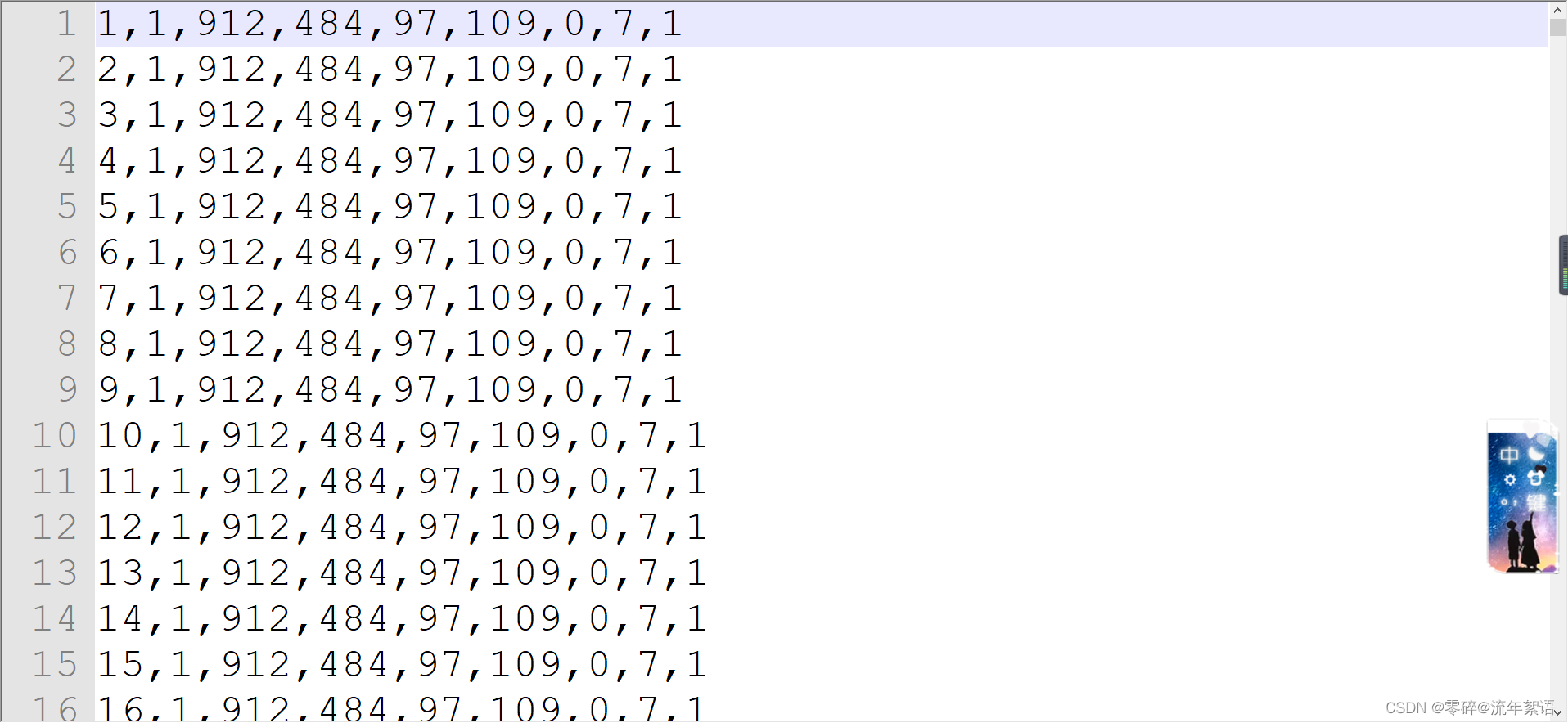
seqinfo.ini
主要介绍视频的帧率、分辨率等基本信息。
test
det.txt
数据标签含义与train相同。
visdrone——Task 4_ Multi-Object Tracking
<frame_index>,<target_id>,<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,<score>,<object_category>,<truncation>,<occlusion>
-----------------------------------------------------------------------------------------------------------------------------------
Name Description
-----------------------------------------------------------------------------------------------------------------------------------
<frame_index> The frame index of the video frame
<target_id> In the DETECTION result file, the identity of the target should be set to the constant -1.
In the GROUNDTRUTH file, the identity of the target is used to provide the temporal corresponding
relation of the bounding boxes in different frames.
<bbox_left> The x coordinate of the top-left corner of the predicted bounding box
<bbox_top> The y coordinate of the top-left corner of the predicted object bounding box
<bbox_width> The width in pixels of the predicted object bounding box
<bbox_height> The height in pixels of the predicted object bounding box
<score> The score in the DETECTION file indicates the confidence of the predicted bounding box enclosing
an object instance.
The score in GROUNDTRUTH file is set to 1 or 0. 1 indicates the bounding box is considered in evaluation,
while 0 indicates the bounding box will be ignored.
<object_category> The object category indicates the type of annotated object, (i.e., ignored regions(0), pedestrian(1),
people(2), bicycle(3), car(4), van(5), truck(6), tricycle(7), awning-tricycle(8), bus(9), motor(10),
others(11))
<truncation> The score in the DETECTION file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the degree of object parts appears outside a frame
(i.e., no truncation = 0 (truncation ratio 0%), and partial truncation = 1 (truncation ratio 1% ~ 50%)).
<occlusion> The score in the DETECTION file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the fraction of objects being occluded
(i.e., no occlusion = 0 (occlusion ratio 0%), partial occlusion = 1 (occlusion ratio 1% ~ 50%),
and heavy occlusion = 2 (occlusion ratio 50% ~ 100%)).
├── visdrone
│ ├── images
│ │ ├── train
│ │ │ ├── 视频目录
│ │ │ │ ├── gt
│ │ │ │ ├── img1
│ │ │ │ ├── seqinfo.ini
│ │ ├── test
│ ├── labels_with_ids
│
配置seqinfo.ini文件
[Sequence]
name=MOT17-02-DPM
imDir=img1
frameRate=30
seqLength=600
imWidth=1920
imHeight=1080
imExt=.jpg
其中,imWidth、imHeight、imExt分别为图片的宽、高、格式;seqLength表示此视频被抽成了多少帧。frameRate为画面更新率。
代码如下
import os
import shutil
from tqdm import tqdm
from PIL import Image
def copyfile(old_folder_path,new_folder_path):
print('---------------------')
for file in os.listdir(old_folder_path):
old_file_path=os.path.join(old_folder_path,file)
# print(file)
# print(new_folder_path)
shutil.copy(old_file_path, new_folder_path)
def makedir(filepath):
if not os.path.exists(filepath):
os.mkdir(filepath)
def process(path):
annotations_path = os.path.join(path, "annotations")
ann_set = os.listdir(annotations_path)
# print(ann_set)
file_path=os.path.join(path,'sequences')
file_set=os.listdir(file_path)
# print(file_set)
for i in tqdm(ann_set):
f = open(annotations_path + "/" + i, "r")
print(i)
name = i.replace(".txt", "")
print(name)
img_path=os.path.join(file_path,name)
img_set=os.listdir(img_path)
img=Image.open(os.path.join(img_path,img_set[0]))
for line in f.readlines():
line = line.replace("\n", "")
if line.endswith(","): # filter data
line = line.rstrip(",")
line_list = [int(i) for i in line.split(",")]
new_line_list=[line_list[i] for i in range(0,8)]
print(line_list)
# print(new_line_list)
if(line_list[8]==0 and line_list[9]==0):
new_line_list.append(1)
if (line_list[8] == 0 and line_list[9] == 1):
new_line_list.append(0.9)
if (line_list[8] == 1 and line_list[9] == 0):
new_line_list.append(0.8)
if (line_list[8] == 0 and line_list[9] == 2):
new_line_list.append(0.7)
if (line_list[8] == 1 and line_list[9] == 1):
new_line_list.append(0.5)
if (line_list[8] == 1 and line_list[9] == 2):
new_line_list.append(0.3)
# print(new_line_list)
url1 = os.path.join(path,name)
makedir(url1)
url2=os.path.join(name,'gt')
makedir(url2)
file_url=url2+'\\gt.txt'
print(url2)
print(file_url)
if not os.path.isfile(file_url):
fd = open(file_url, mode="w", encoding="utf-8")
makedir(file_url)
with open(file_url, 'a') as file_name:
str_text = str(new_line_list[0]) + ',' + str(new_line_list[1]) + ',' + str(new_line_list[2]) + ',' + str(
new_line_list[3]) + ',' + str(new_line_list[4]) + ',' + str(new_line_list[5]) + ',' + str(
new_line_list[6]) + ',' + str(new_line_list[7])+ ',' + str(new_line_list[8])
print(str_text)
file_name.write(str_text + '\n')
ini_path = os.path.join(path, name)
ini_file=ini_path+'\\seqinfo.ini'
print('***********************************')
if not os.path.isfile(ini_file):
fd = open(ini_file, mode="w", encoding="utf-8")
with open(ini_file, 'a') as ini_name:
ini_text ='[Sequence]\n'+'name='+name+'\n'+'imDir=img1\n'+'frameRate=30\n'+'seqLength='+str(len(img_set))+'\n'+'imWidth = '+str(img.size[0])+'\n'+'imHeight = '+str(img.size[1])+'\n'+'imExt =.jpg\n'
print(ini_text)
ini_name.write(ini_text + '\n')
break
old_path=os.path.join(file_path,name)
new_path=os.path.join(path,name,'img1')
print(old_path)
print(new_path)
move(old_path,new_path)
def move(old_path,new_path):
makedir(new_path)
copyfile(old_path,new_path)
if __name__ == '__main__':
path1=r'D:\pythonProjects\Test\visdrone2mot\annotations'
path2=r'D:\pythonProjects\Test\visdrone2mot\sequences'
path=r'D:\pythonProjects\Test\visdrone2mot'
process(path)
Linux
import os
import shutil
from tqdm import tqdm
from PIL import Image
def copyfile(old_folder_path,new_folder_path):
print('---------------------')
for file in os.listdir(old_folder_path):
old_file_path=os.path.join(old_folder_path,file)
# print(file)
# print(new_folder_path)
shutil.copy(old_file_path, new_folder_path)
def makedir(filepath):
if not os.path.exists(filepath):
os.mkdir(filepath)
def process(path):
annotations_path = os.path.join(path, "annotations")
ann_set = os.listdir(annotations_path)
# print(ann_set)
file_path=os.path.join(path,'sequences')
file_set=os.listdir(file_path)
# print(file_set)
for i in tqdm(ann_set):
f = open(annotations_path + "/" + i, "r")
print(i)
name = i.replace(".txt", "")
print(name)
img_path=os.path.join(file_path,name)
img_set=os.listdir(img_path)
img=Image.open(os.path.join(img_path,img_set[0]))
old_path = os.path.join(file_path, name)
new_path = os.path.join(path, name, 'img1')
print(old_path)
print(new_path)
move(old_path, new_path)
for line in f.readlines():
line = line.replace("\n", "")
if line.endswith(","): # filter data
line = line.rstrip(",")
line_list = [int(i) for i in line.split(",")]
new_line_list=[line_list[i] for i in range(0,8)]
print(line_list)
# print(new_line_list)
if(line_list[8]==0 and line_list[9]==0):
new_line_list.append(1)
if (line_list[8] == 0 and line_list[9] == 1):
new_line_list.append(0.9)
if (line_list[8] == 1 and line_list[9] == 0):
new_line_list.append(0.8)
if (line_list[8] == 0 and line_list[9] == 2):
new_line_list.append(0.7)
if (line_list[8] == 1 and line_list[9] == 1):
new_line_list.append(0.5)
if (line_list[8] == 1 and line_list[9] == 2):
new_line_list.append(0.3)
# print(new_line_list)
url1 = os.path.join(path,name)
makedir(url1)
print('url1:',url1)
url2=os.path.join(url1,'gt')
print('url2:',url2)
makedir(url2)
file_url=url2+'/gt.txt'
print(url2)
print(file_url)
if not os.path.isfile(file_url):
fd = open(file_url, mode="w", encoding="utf-8")
makedir(file_url)
with open(file_url, 'a') as file_name:
str_text = str(new_line_list[0]) + ',' + str(new_line_list[1]) + ',' + str(new_line_list[2]) + ',' + str(
new_line_list[3]) + ',' + str(new_line_list[4]) + ',' + str(new_line_list[5]) + ',' + str(
new_line_list[6]) + ',' + str(new_line_list[7])+ ',' + str(new_line_list[8])
print(str_text)
file_name.write(str_text + '\n')
ini_path = os.path.join(path, name)
ini_file=ini_path+'/seqinfo.ini'
print('***********************************')
if not os.path.isfile(ini_file):
fd = open(ini_file, mode="w", encoding="utf-8")
with open(ini_file, 'a') as ini_name:
ini_text ='[Sequence]\n'+'name='+name+'\n'+'imDir=img1\n'+'frameRate=30\n'+'seqLength='+str(len(img_set))+'\n'+'imWidth = '+str(img.size[0])+'\n'+'imHeight = '+str(img.size[1])+'\n'+'imExt =.jpg\n'
print(ini_text)
ini_name.write(ini_text + '\n')
# break
def move(old_path,new_path):
makedir(new_path)
copyfile(old_path,new_path)
if __name__ == '__main__':
path='/home/course/ldw/dataset/VisDrone2019-MOT-val/'
process(path)
![[Linux]----守护进程](https://img-blog.csdnimg.cn/e8603c06422645efb3d67a8b3a283dc5.png)