我们在做实验时,不免需要对模型结构进行修改来检测自己的改进性能,对于一般模型而言,我们只需要简单的在代码中添加网络层即可,但对于一些预训练好的模型,我们则需要进行较为复杂的修改。以我们的YOLOV7模型为例,yolo_v7.pth为预训练模型,里面已经根据image_Net训练好了大量的权值,是具有通用性的,如果我们不选择该模型而选择自己重新训练的话,无疑会增大计算成本,同时也可能无法取到满意的效果。
今天主要是尝试为YOLO模型添加简单的网络层,为之后模型的修改完善打下基础。
基础知识
首先我们先来熟悉一下模型文件,.pt,.pth,.pkl的PyTorch模型文件。
它们并不存在格式上的区别,只是后缀名不同而已。在用torch.save()函数保存模型文件的时候,有些人喜欢用.pt后缀,有些人喜欢用.pth或 .pkl,用相同的 torch.save()语句保存出来的模型文件没有什么不同。在PyTorch官方的文档里,有用.pt的,也有用.pth的。
据某些文章的说法,一般惯例是使用 .pth,但是官方文档里貌似.pt居多,而且官方也不是很在意固定地用某一种。
简单测试
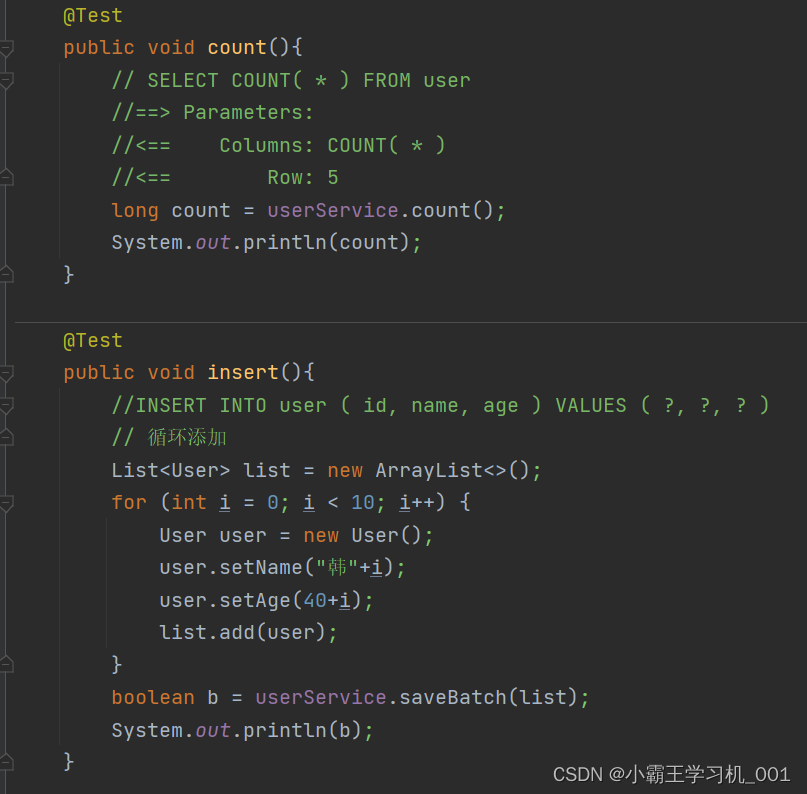
我们来简单测试一下模型文件的生成,保存和读取:
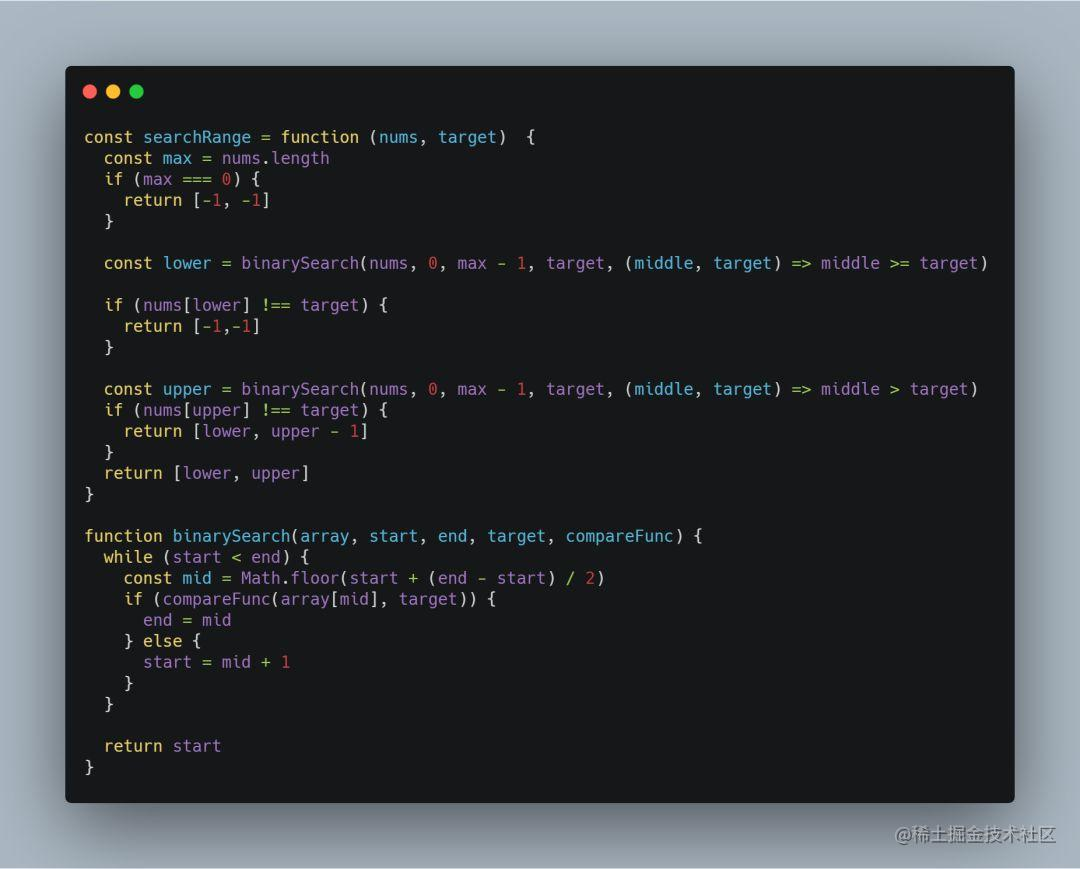
我们自定义一个模型,然后将其保存并读取:
import torch
from torch import nn
class Qu(nn.Module):
def __init__(self):
super(Qu, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return
def test_model():
qu = Qu()
torch.save(qu, "qu_method1.pth")
model = torch.load("qu_method1.pth")
print(model)
test_model()
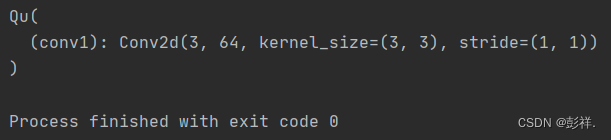
然后我们读取一下yolov7_weights.pth文件:
def load_model():
import torch
weights = '../model_data/yolov7_weights.pth'
net = torch.load(weights)
print(type(net), len(net))
for k, v in net.items():
print(k, type(v), v.size())
load_model()
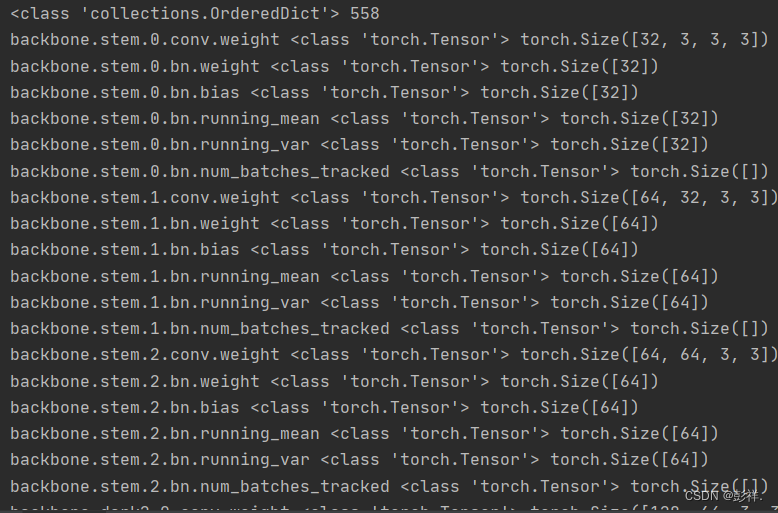
可以看到其读取出的文件为权重值,偏置项的配置,包含初始化值,这便是预训练权重,是在image_net上训练得到的,具有通用性,而我们便是在修改了自己的网络模型上,在预训练权值的基础上进行微调,从而得到符合我们数据集的权重,进而完成我们的实验。
微调(Fine Tune)
什么是模型微调呢,比如我们已知一个网络模型:
Y=Wx 这里我们没有设置偏置项
我们想要找到W,使X=2时,Y=1,即W=0.5
那么我们就要对W进行初始化,其初始化值符合均值为0,方差为1的分布,假设我们开始初始值为0.1,当我们的X=2时,Y=0.2,此时Y的实际值与理想值误差为0.8,相差较大,0.8的误差值去反向传播更新W,假设此时更新为0.2,那么依旧有0.6的误差,可能经过十几次乃至几十次的反向传播,最后我们得到了理想的权重值。
而如果一开始时,有人告诉我们说我们的权重值在0.48附近,那么我们我们第一次的误差值便只有0.04了,那么我们肯能只需要几次反向传播便可以得到理想的结果,我么是在一个已有范围的基础上稍微调整,即称为微调。
这个告诉我么的初始权值范围便相当于一个预训练模型,而我么之后的训练便是微调的过程。
我们选择的预训练模型一般都是在image_net,VOC,COCO等这种大型数据集上训练得到的,具有公信力和通用性。而如果我么自己从头训练的话,若是数据集数量过少,而我们的权值参数数量很多,那么就可以存在过拟合线性,泛化性能不佳。
何时可用微调?
1.数据集很相似,个人数据集与预训练数据集很相似
2.数据集很相似,但数量太少,不能满足训练要求
3.计算资源匮乏,如果计算力差,那么使用预训练模型无疑是一个好的选择。
4.自己搭建的模型准确性太差
通过对我们拥有的较小数据集进行训练(即反向传播),对现有网络进行微调,这些网络是在像ImageNet这样的大型数据集上进行训练的,以达到快速训练模型的效果。假设我们的数据集与原始数据集(例如ImageNet)的上下文没有很大不同,预先训练的模型将已经学习了与我们自己的分类问题相关的特征。
我们也可以冻结网络中的层数来进行训练。
最后我们调用一下YOLO模型:
def yolo_model():
import nets.yolo as yolo
import torch
YOLO=yolo.YoloBody()
torch.save(YOLO, "YOLO.pth")
model = torch.load("YOLO.pth")
print(model)
yolo_model()
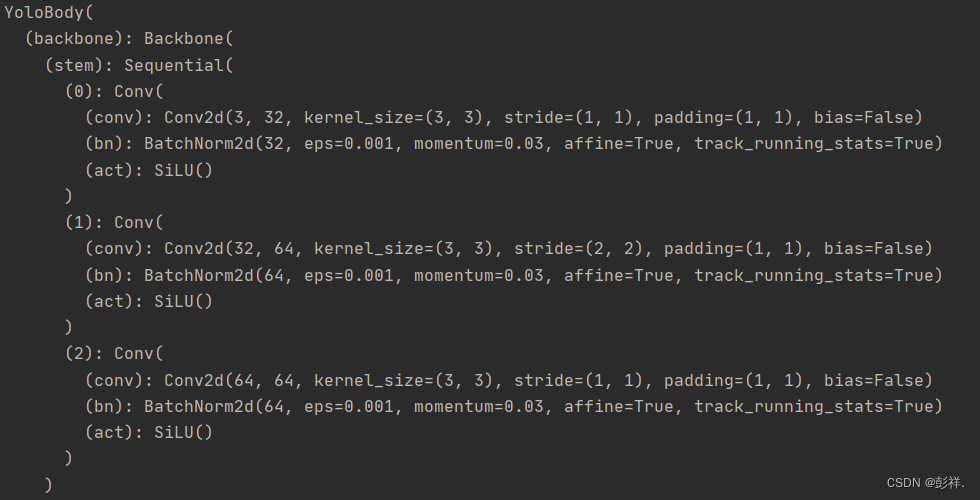
可以看到其网络输出通道数以及特征图大小与我们的模型图一致。
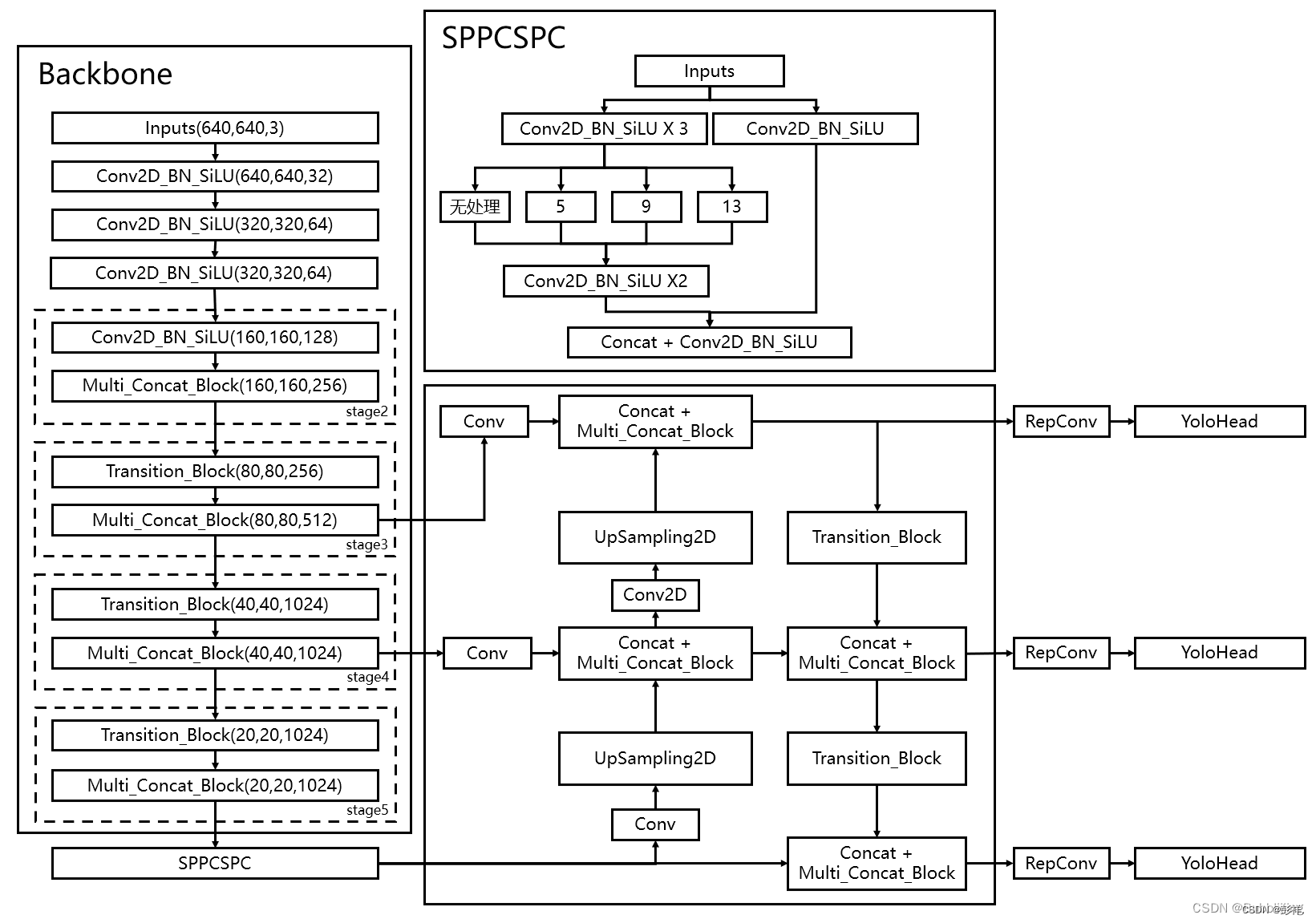
模型修改
终于到我们的重头戏了,首先我们先要定义一下我们的模型结构,博主定义了一个SE模块,这是一个通道注意力模型。
import torch
import torch.nn as nn
class SELayer(nn.Module):
def __init__(self, c1, r=16):
super(SELayer, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
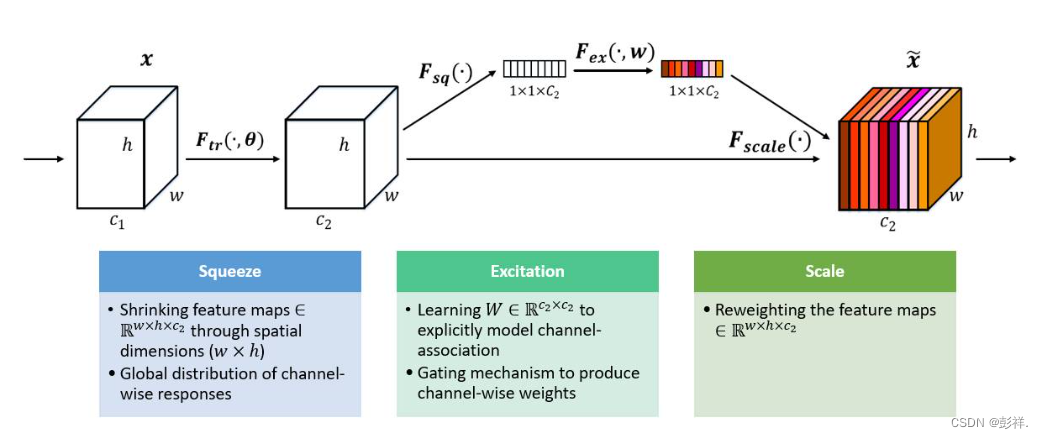
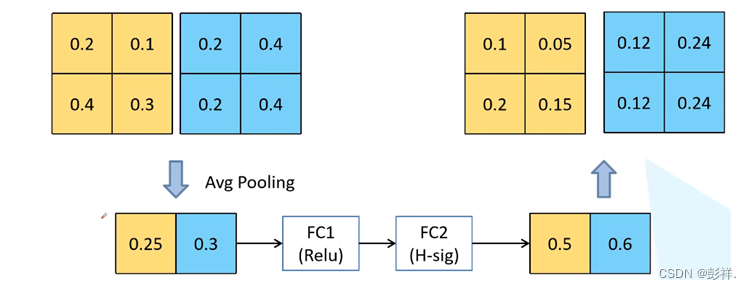
demo:
模型结构如图所示,然后我们需要确定我们想要将模型结构所添加的位置,我们选择一个容易添加的位置,比如在yolo的head头的最后的部分。如下图所示
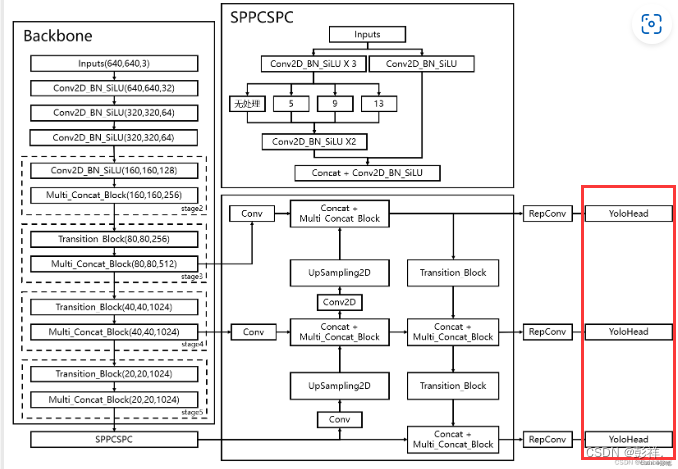
那么确定了要添加位置后就在网络结构中进行定义;

然后再前向传播中引入:
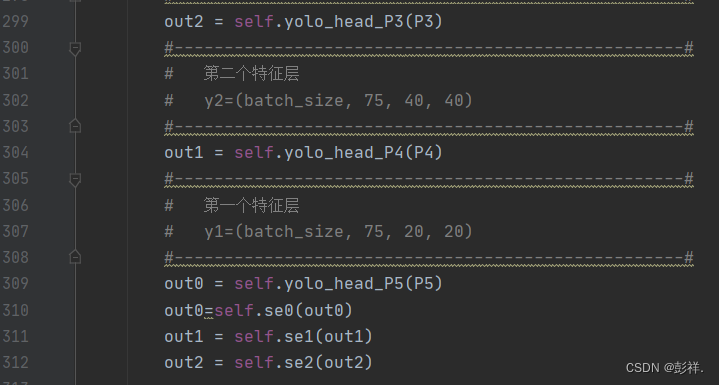
完成后我们开始训练,此时我们使用的依然是yolov7_weights.pth这个预训练模型。为了方便实验,博主只进行了一次迭代。
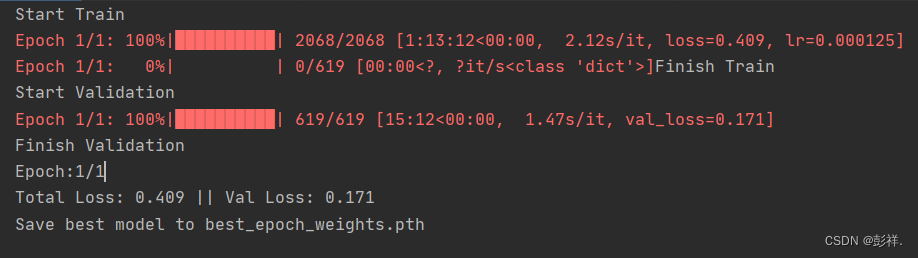
保存好我们训练的模型后,此时的pth里面是包含我们刚刚训练好的参数的。
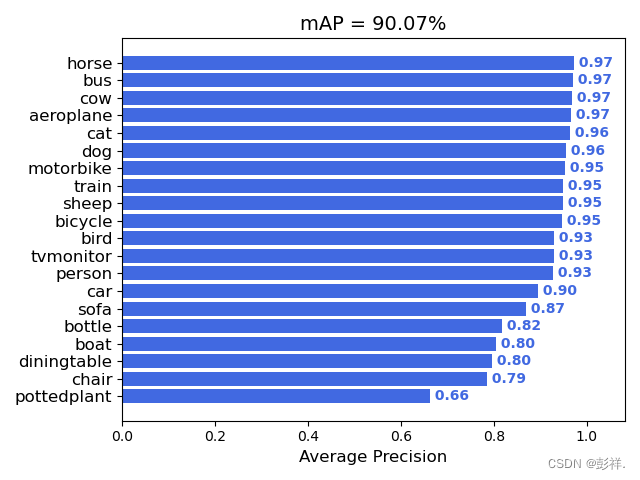
我们计算mAP值来看看加入SENet后的效果,原mAP为90.07%:
将模型替换为刚刚训练好的模型文件:将yolo文件中的模型地址替换:
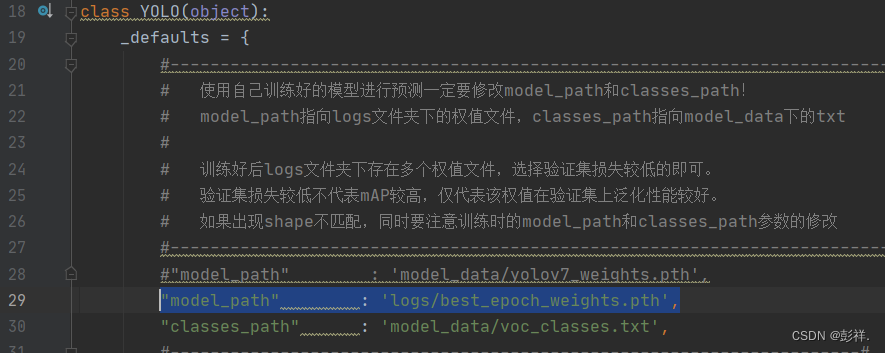
计算mAP可以看到,效果很差,理论上计算效果差些也不该直接没有结果的,这说明我们的改进肯定出问题了:
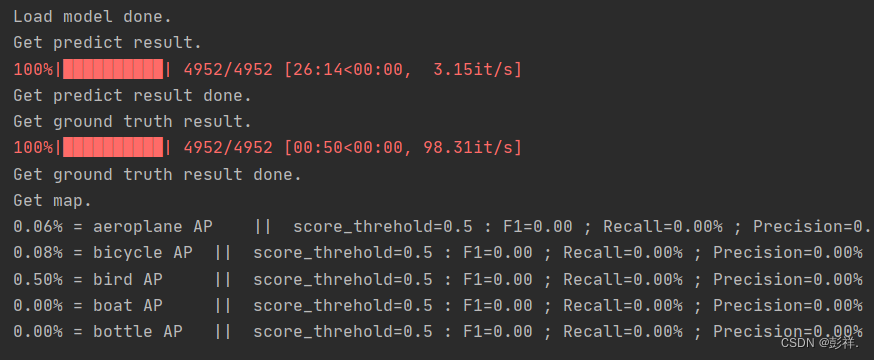
呜呜呜,当然也可能是训练次数太少导致的,正在找原因。。。。后面找到原因后会更新的
常用模块
下面介绍几种即插即用的注意力机制模块
CBAM模型
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# 写法二,亦可使用顺序容器
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
# c_ = int(c2 * e) # hidden channels
# self.cv1 = Conv(c1, c_, 1, 1)
# self.cv2 = Conv(c1, c_, 1, 1)
# self.cv3 = Conv(2 * c_, c2, 1)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out
ECA模块
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x=x*y.expand_as(x)
return x * y.expand_as(x)
![[Linux]----守护进程](https://img-blog.csdnimg.cn/e8603c06422645efb3d67a8b3a283dc5.png)