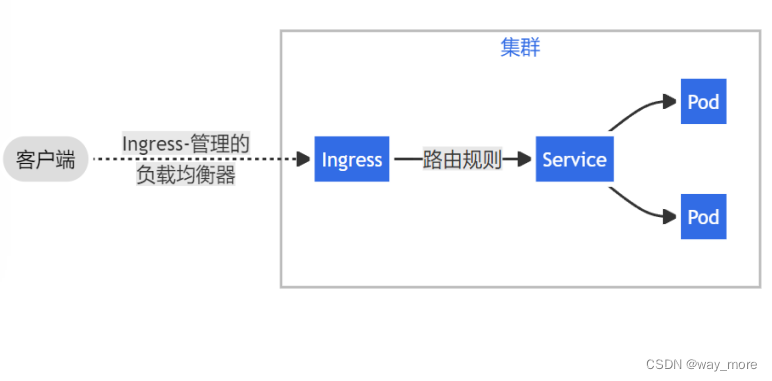
既然单人应用那么就不需要注册、登录了,太麻烦,直接上功能项,而初版太不好看了,略微修改归纳了一下,出了第一版
很有精神,为了纪念,这个网页项目我命名为JRP
主要就是:
1、定义一个类
2、集中定义路由
3、HTML模版使用一个模版,在模版内依靠变量判断是否执行
4、利用CSS进行格式定义(这块待优化,时间短,我等不及让它在我树莓派上工作起来了…)
上代码:
from flask import Flask, render_template, send_file, request
import os
# 定义类
class FileManagementApp:
# 定义类变量,这里是放数据库根目录,我这里就是我树莓派系统上的存储盘挂载位置
gDataPath = os.path.normpath("/data/HOME_NAS/data")
def __init__(self):
self.app = Flask(__name__)
self.app.config['UPLOAD_FOLDER'] = ''
# 添加basename方法,让HTML中使用 路径|basename 输出结果是路径文件夹名或文件名而不是完整路径
self.app.add_template_filter(self.basename)
# 把所有下面函数定义的路由集中到这里,清晰明了
self.app.route('/')(self.mainweb)
self.app.route('/<show_item>')(self.index)
self.app.route('/download/<file_name>')(self.download_file)
self.app.route('/show_folder/<folder_name>')(self.show_folder)
self.app.route('/return_folder/<folder_name>')(self.return_folder)
self.app.route('/upload', methods=['POST'])(self.upload_file)
self.app.route('/search', methods=['POST'])(self.search_file)
def basename(self, value):
return os.path.basename(value)
# 主页面,show_main=True控制让它显示在html中,避免HTML中所有模块都显示在网页中,默认是关闭的,参考HTML模版
def mainweb(self):
return render_template('index.html',
show_main=True
)
# 根据mainweb页面用户点击后的返回,跳转到不同的页面,show_xxx=True 则是打开显示不同的模块,其余不显示
def index(self, show_item):
if show_item == "show_list":
files, folder_names, folder_name = self.getfile()
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_list=True
)
elif show_item == "show_search":
# files, folder_names, folder_name = self.getfile()
files, folder_names, folder_name = [], [], ""
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_search=True
)
elif show_item == "show_upload":
files, folder_names, folder_name = self.getfile()
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_upload=True
)
# 下载文件
def download_file(self, file_name):
# 替换windows系统路径 \\为 /,即兼容不同系统的路径
file_name = os.path.normpath(file_name)
# 将选择的文件下载下来
return send_file(file_name, as_attachment=True)
# 显示当前路径下所有的文件夹和文件,不包含子目录下的
def show_folder(self, folder_name=""):
files, folder_names, folder_name = self.getfile(folder_name)
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_list=True
)
# 返回上级目录
def return_folder(self, folder_name):
refolder = folder_name
full_path = os.path.join(FileManagementApp.gDataPath, refolder)
for root, dirs, files in os.walk(FileManagementApp.gDataPath, topdown=True):
for dir in dirs:
if os.path.join(root, dir) == full_path:
folder_name = os.path.relpath(root, start=FileManagementApp.gDataPath)
if folder_name == ".":
folder_name = ""
files, folder_names, folder_name = self.getfile(folder_name)
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_list=True
)
# 抓取指定路径下所有的文件,文件夹(不包含子文件夹下的内容)
def getfile(self, folder_name=""):
files = []
folder_names = []
full_path = os.path.join(FileManagementApp.gDataPath, folder_name)
fileList = os.listdir(full_path)
for file in fileList:
file = os.path.join(full_path, file)
file = os.path.normpath(file)
if os.path.isfile(file):
files.append(file)
else:
folder_names.append(file)
return files, folder_names, folder_name
# 上传文件,上传的路径就是现在进到的路径,不允许在网页创建新的目录文件夹
def upload_file(self):
# 读取网页返回的值
file = request.files['file']
folder_name = request.form['folder_name']
UPLOAD_FOLDER = os.path.join(FileManagementApp.gDataPath, folder_name)
self.app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
if 'file' not in request.files:
return 'No file part'
file = request.files['file']
if file.filename == '':
return 'No selected file'
# 将文件保存到指定路径下
file.save(os.path.join(self.app.config['UPLOAD_FOLDER'], file.filename))
files, folder_names, folder_name = self.getfile(folder_name)
# 维持在这个上传文件的路径
return render_template('index.html',
files=files,
folder_names=folder_names,
folder_name=folder_name,
show_upload=True
)
# 查找文件
def search_file(self):
sfile_result = []
sfolder_result = []
# keyword = request.text['keyword'] ## error
keyword = request.form.get('keyword', '') # 获取名为 'keyword' 的表单字段的值
if keyword == "":
pass
else:
files, folder_names = self.perform_search_file()
for file in files:
if keyword in file:
sfile_result.append(file)
for sfolder in folder_names:
if keyword in sfolder:
sfolder_result.append(sfolder)
return render_template('index.html',
files=sfile_result,
folder_names=sfolder_result,
folder_name="",
show_search=True,
)
# 执行搜索的功能,遍历存储路径下所有的文件,看是否有包含关键字的文件并返回
def perform_search_file(self):
file_result = []
folder_result = []
for root, dirs, files in os.walk(FileManagementApp.gDataPath, topdown=True):
for file in files:
full_path = os.path.join(root, file)
full_path = os.path.normpath(full_path)
file_result.append(full_path)
for dir in dirs:
full_path = os.path.join(root, dir)
full_path = os.path.normpath(full_path)
folder_result.append(full_path)
return file_result, folder_result
# 运行服务
def run(self):
self.app.run(host='0.0.0.0', port=5000)
if __name__ == '__main__':
# 实例化并开始执行
file_app = FileManagementApp()
file_app.run()
下面是index.html模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Folder Viewer</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 20px;
}
h1 {
color: #333;
}
p {
margin-bottom: 10px;
}
form {
margin-bottom: 20px;
}
ul {
list-style: none;
padding: 0;
}
li {
margin-bottom: 5px;
}
a {
text-decoration: none;
color: #007BFF;
}
a:link {color:#110101;} /* 未访问链接*/
a:visited {color:#00FF00;} /* 已访问链接 */
a:hover {color:#FF00FF;} /* 鼠标移动到链接上 */
a:active {color:#0000FF;} /* 鼠标点击时 */
h2 {
margin-top: 20px;
color: #333;
}
</style>
</head>
<body>
<!--show_main|default(false) 设定这个show_main的默认值是false,就是假设没传参进来就是false的-->
{% if show_main|default(false) %}
<h1>欢迎进入JRP系统主页</h1>
<h1>当前版本 1.2023.12.28</h1>
<h1>作者:零时搞学习</h1>
<h1></h1>
<li><a href="{{ url_for('index', show_item='show_upload') }}">上传</a></li>
<li><a href="{{ url_for('index', show_item='show_list') }}">浏览</a></li>
<li><a href="{{ url_for('index', show_item='show_search') }}">搜索</a></li>
{% endif %}
{% if show_upload|default(false) %}
<li><a href="{{ url_for('mainweb') }}">首页</a></li>
<form method="post" enctype="multipart/form-data" action="/upload">
<input type="file" name="file">
<!--隐藏项,不会显示,但是可以返回folder_name值给脚本-->
<input type="hidden" name="folder_name" value="{{ folder_name }}">
<input type="submit" value="Upload">
</form>
{% endif %}
{% if show_search|default(false) %}
<li><a href="{{ url_for('mainweb') }}">首页</a></li>
<h1>文件搜索</h1>
<form action="/search" method="post">
<input type="text" name="keyword" placeholder="输入关键字">
<button type="submit">搜索</button>
</form>
<ul>
<h2>搜索结果</h2>
<h2>文件夹:</h2>
{% for foldername in folder_names %}
<li><a href="{{ url_for('search_file', folder_name=foldername) }}">{{ foldername|basename }}</a></li>
{% endfor %}
<h2>文件:</h2>
{% for filename in files %}
<li><a href="{{ url_for('download_file', file_name=filename) }}" download>{{ filename|basename }}</a></li>
{% endfor %}
</ul>
{% endif %}
{% if show_list|default(false) %}
<li><a href="{{ url_for('mainweb') }}">首页</a></li>
<h1>文件上传下载列表</h1>
{% if folder_name == "" %}
<p>当前路径:</p>
{% else %}
<p>当前路径:</p>
<li><a href="{{ url_for('return_folder', folder_name=folder_name) }}">返回:{{ folder_name|basename }}</a></li>
{% endif %}
<ul>
<h2>文件夹:</h2>
{% for foldername in folder_names %}
<li><a href="{{ url_for('show_folder', folder_name=foldername) }}">{{ foldername|basename }}</a></li>
{% endfor %}
<h2>文件:</h2>
{% for filename in files %}
<li><a href="{{ url_for('download_file', file_name=filename) }}" download>{{ filename|basename }}</a></li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>
下面是执行效果:
我的树莓派IP是 192.168.9.103
在代码中使用了了 host='0.0.0.0,port=5000',进行广播,port为5000,这样我在同网域才能访问网页
如下:网页地址为192.168.9.103:5000

服务器端运行起来了
接下来随便找台同网域的破电脑访问这个网页:
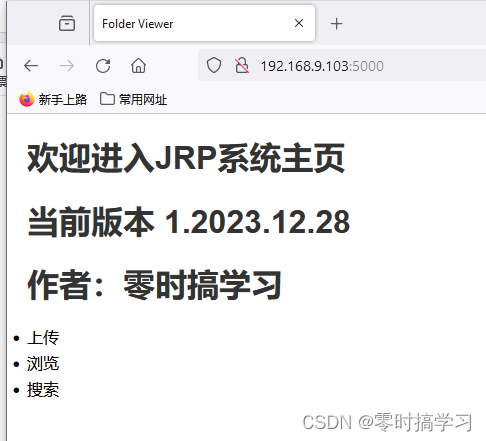
显示的首页如下:
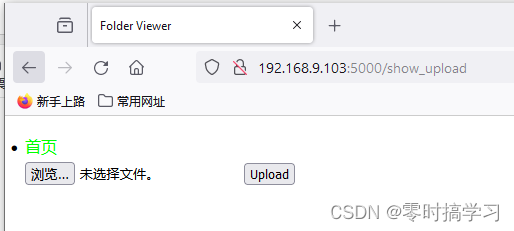
点击上传链接,进入上传页面,上传完成后这个页面会刷新,保持这个状态显示,点击首页可以返回首页
点击浏览可以显示当前文件夹下所有的文件和文件夹,不包含子文件,原则上不允许通过网页创建新的文件夹
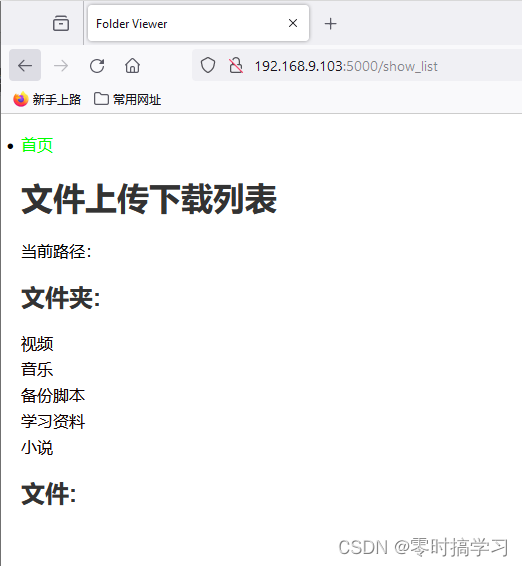
在这个页面下,文件夹和可以下载的文件是分开的,文件夹点击进入文件夹并显示下面的文件夹和文件,点击文件则是下载:
----然后出Bug了,嗯~~~~
Linux系统下处理貌似和Windows下是不同的,尽量考虑了,但是还是出问题了
后续再继续debug一下,今天先睡~~~~~~~~