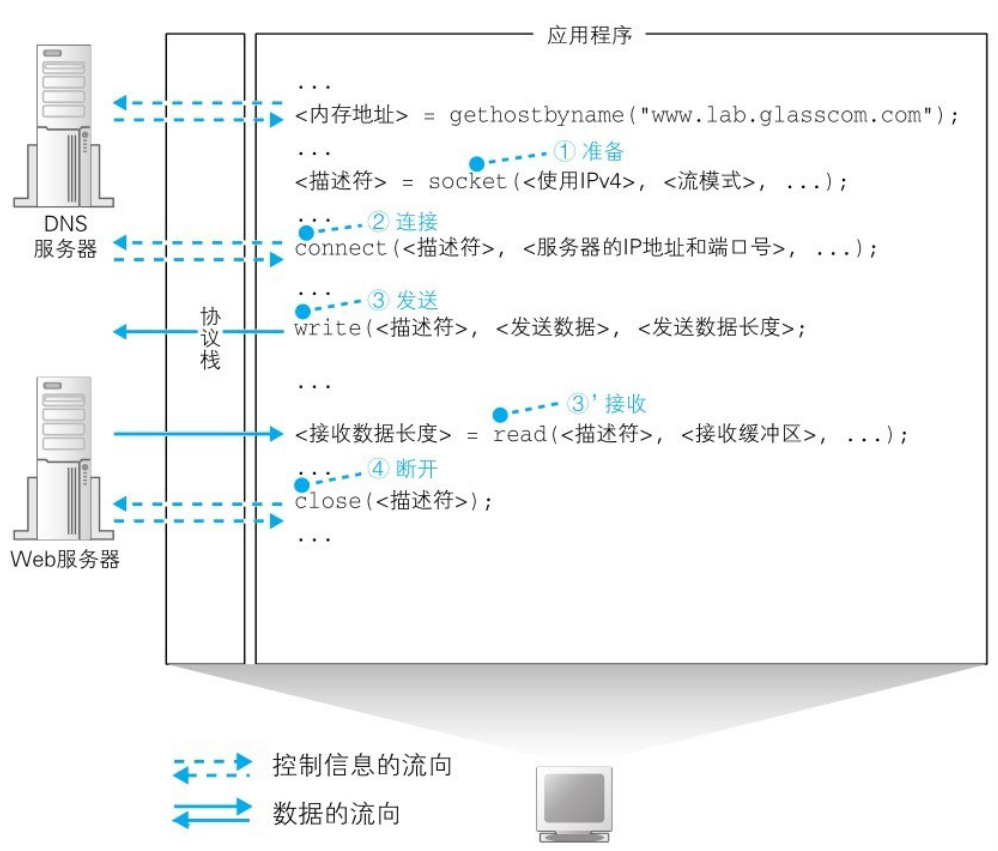
文献速递:人工智能医学影像分割—一个用于 COVID-19 CT 图像的粗细分割网络
01
文献速递介绍
2019 年新型冠状病毒疾病(COVID-19)正在全球迅速传播。自 2019 年以来,已有超过一千万人感染,其中数十万人死亡。COVID-19 是由一种严重急性呼吸综合征冠状病毒引起的,这种病毒可以快速传播给其他人,从而显著增加感染人数。因此,迅速诊断并给予适当治疗至关重要。不幸的是,目前还没有针对 COVID-19 患者的有效药物或疫苗,因此医生必须根据患者的病情实施不同的治疗计划。然而,由于缺乏量化标准,确定患者的病情颇具挑战。
胸部计算机断层扫描(CT)是一种便捷的肺炎诊断工具,广泛用于检测 COVID-19 的典型成像特征 。最近,许多方法被提出,通过 CT 中的特征区分 COVID-19 患者和健康人或其他类型患者。例如,提出了一种 COVID-Net ,通过深度学习方法从 CT 中检测 COVID-19 患者。Kamini 等人 使用一系列预训练的深度模型进行集成学习,以敏感地识别 COVID-19 患者。还有几种分类方法 被提出,用于使用 CT 判断一个人是否感染 COVID-19。然而,上述大多数研究侧重于分类,无法充分利用胸部 CT 的信息,也无法提供更合理的治疗方案。
最近的一项综述得出结论,胸部 CT 成像对检测 COVID-19 是敏感的。患者的典型成像特征包括磨玻璃样不透明、实变和纤维化。然而,手动标记这些区域是昂贵的。最近的研究 表明,可以从成像特征的面积推断 COVID-19 患者的病情严重程度。因此,准确的医学图像分割为设计合理治疗提供了一种可行的方式来估计感染的进展。因此,迫切需要一种有效的病灶区域分割方法。
深度学习技术的发展为医学图像分割提供了强有力的支持。最近,提出了残差注意力 U-Net ,用于自动分割多个 COVID-19 感染区域。它利用残差网络和注意力机制提高了 U-Net 的效果。Inf-Net 可以自动识别 CT 中的感染区域。它提高了边界分割的质量,但在检测小型病灶区域方面不够有效。因此,这些模型在 COVID-19 病灶的分割中并不是非常有效。
Title
题目
A coarse-refine segmentation network for COVID-19 CT images
一个用于 COVID-19 CT 图像的粗细分割网络
Abstract
摘要
The rapid spread of the novel coronavirus disease 2019 (COVID-19) causes a significant impact on public health. It is critical to diagnose COVID-19 patients so that they can receive reasonable treatments quickly. The doctors can obtain a precise estimate of the
infection’s progression and decide more effective treatment options by segmenting the CT images of COVID-19 patients. However, it is challenging to segment infected regions in CT slices because the infected regions are multi-scale, and the boundary is not clear due to the low contrast between the infected area and the normal area. In this paper, a coarse refine segmentation network is proposed to address these challenges. The coarse-refine architecture and hybrid loss is used to guide the model to predict the delicate structures with clear boundaries to address the problem of unclear boundaries. The atrous spatial pyramid pooling module in the network is added to improve the performance in detecting infected regions with different scales. Experimental results show that the model in the segmentation of COVID-19 CT images outperforms other familiar medical segmentation models, enabling the doctor to get a more accurate estimate on the progression of the infection and thus can provide more reasonable treatment options.
2019 年新型冠状病毒疾病(COVID-19)的迅速传播对公共卫生产生了重大影响。诊断 COVID-19 患者是至关重要的,以便他们能够迅速接受合理的治疗。通过对 COVID-19 患者的 CT 图像进行分割,医生可以获得感染进展的精确估计,并决定更有效的治疗方案。然而,由于感染区域呈多尺度,且由于感染区域与正常区域之间对比度低,边界不清晰,因此在 CT 切片中对感染区域进行分割具有挑战性。在本文中,提出了一种粗细分割网络以应对这些挑战。使用粗细结构和混合损失来指导模型预测具有清晰边界的精细结构,以解决边界不清晰的问题。在网络中增加了空洞空间金字塔池化模块,以提高检测不同尺度感染区域的性能。实验结果表明,该模型在 COVID-19 CT 图像分割方面的性能优于其他熟悉的医学分割模型,使医生能够更准确地估计感染的进展,从而提供更合理的治疗方案。
Methods
方法
This section starts with the dataset introduction. We describe the dataset in Section 2.1 followed by the strategy for dataset split in Section 2.2 and data augmentation section in Section 2.3.
Then we introduce the architecture overview of our network in Section 2.4. The coarse segmentation module is described in Section 2.5, and the segmentation refinement module is intro duced in Section 2.6. Finally, the loss function is presented in Section 2.7, and the part of the classifier is mentioned in Sec tion 2.8.
本节从数据集介绍开始。我们在第 2.1 节描述数据集,接着在第 2.2 节讨论数据集的分割策略,以及在第 2.3 节讨论数据增强部分。
然后我们在第 2.4 节介绍我们网络的架构概览。粗分割模块在第 2.5 节描述,细分割模块的介绍在第 2.6 节。最后,损失函数在第 2.7 节提出,分类器部分在第 2.8 节提及。
Results
结果
We ran the experiment on Ubuntu 16 with an NVIDIA TITAN RTX 1080 GPU with 11 GB of memory. We use Python 3.6 and PyTorch 1.0 to implement those algorithms. The size of all CT slices is 512×512. We use Adam optimiser to optimise all methods, and the learning rate is set to 3e-4 by default. We train all models with a mini-batch size of 8. We run up to 200 epochs for each method. The training monitors the loss on the validation dataset, and it will early stop if the loss increases too much. All those methods had the same train ing strategy and made the same data augmentation mention before.
Firstly, we train the whole segmentation network, and when the segmentation network converges, we freeze all parameters of the segmentation model. Later, we train the classification part of the coarse segmentation module except for the input layer and the first four stages until the classification model conver gence. In the test process, for each image of a patient, we first input the image into the encoder of the segmentation network to determine whether it has lesions. If it has some lesion of COVID-19, we continue to segment it. When all the images of a patient are tested, if no CT image contained the lesion area, the model will predict that this person is not infected with COVID-19. Otherwise, it will indicate the person is infected
我们在装有NVIDIA TITAN RTX 1080 GPU、11 GB内存的Ubuntu 16上运行了这个实验。我们使用Python 3.6和PyTorch 1.0来实现这些算法。所有CT切片的大小为512×512。我们使用Adam优化器来优化所有方法,学习率默认设置为3e-4。我们使用8的小批量大小来训练所有模型。我们为每种方法运行最多200个周期。训练监控验证数据集上的损失,并且如果损失增加太多,它将提前停止。所有这些方法都有相同的训练策略,并进行了之前提到的相同的数据增强。
with COVID-19.首先,我们训练整个分割网络,当分割网络收敛后,我们冻结分割模型的所有参数。随后,我们训练粗略分割模块的分类部分,除了输入层和前四个阶段,直到分类模型收敛。
在测试过程中,对于每个病人的每张图像,我们首先将图像输入到分割网络的编码器中,以确定它是否有病变。如果有COVID-19的某些病变,我们继续对其进行分割。当测试了病人的所有图像后,如果没有CT图像包含病变区域,模型将预测此人未感染COVID-19。否则,它将指示此人感染了COVID-19。
Conclusions
结论
In this paper, we propose a coarse-refine network for the CT lesion segmentation of the COVID-19. Experimental results show that our model in the segmentation of COVID-19 CT images outperforms other familiar medical segmentation mod els, enabling the doctor to get a more accurate estimate on the progression of the infection and thus can provide more reason able treatment options. In the previous work, various U-Net and their variants have been developed, achieving reasonable segmentation results in COVID-19 applications. Military et al. propose the V-Net, which utilises the residual blocks as the basic convolutional block and optimises the network by a Dice loss. By equipping the convolutional blocks with the so called bottleneck blocks, Shan et al. [16] use a VB-Net for more efficient segmentation. Oktay et al. [38] propose an attention U-Net that is capable of capturing fine structures in medical images, thereby suitable for segmenting lesions and lung nod ules in COVID-19 applications. Inf-Net [20] can automatically recognise infected regions from CT. It improves the quality of boundary segmentation. However, the above methods often regard all COVID-19 lesions as one category, which cannot give the severity of a patient’s infection according to the occur rence of many different lesions. Therefore, these methods can’t provide more reasonable treatment options. Besides, the above methods do not well consider the differences between COVID-19 lesions and other segmentation tasks, making COVID-19 lesions difficult to segment. The main differences between COVID-19 lesions and other segmentation tasks are as follows:some boundaries of infected regions are not evident ;some areas of infection have low contrast with natural areas ;the shape and size of infected areas are multi-scale . We propose a model to address those difficulties. We use a coarse segmentation module to obtain a rough segment result from input images. We employ a refining module to learn the resid uals between the rough segment result and the ground truth to adjust the erroneous segmentation output, especially the edge. Moreover, we add an atrous spatial pyramid pooling module to both the coarse segmentation module and the refine mod ule so that the network can accurately detect infected regions with different scales. We adopt the hybrid loss as training loss, which helps guide the model to predict the delicate struc tures with clear boundaries accurately. However, our method also has its limitations. The structure of our network is rela tively heavy, and the parameters of the model are relatively large, which requires more corresponding computing resources than some other methods. We believe that this method is universal and can achieve good results in other segmentation tasks. We will try this method in other fields in the future.
在本文中,我们提出了一种用于 COVID-19 CT 病灶分割的粗细网络。实验结果表明,我们的模型在 COVID-19 CT 图像分割方面优于其他熟悉的医学分割模型,使医生能够更准确地估计感染的进展,从而提供更合理的治疗方案。在以前的工作中,开发了各种 U-Net 及其变体,在 COVID-19 应用中取得了合理的分割结果。Military 等人提出了 V-Net,它使用残差块作为基本的卷积块,并通过 Dice 损失优化网络。Shan 等人 通过配备所谓的瓶颈块,使用 VB-Net 进行更高效的分割。Oktay 等人 提出了一种能够捕捉医学图像中精细结构的注意力 U-Net,因此适用于 COVID-19 应用中病灶和肺结节的分割。Inf-Net可以自动识别 CT 中的感染区域。它提高了边界分割的质量。然而,上述方法通常将所有 COVID-19 病灶视为一类,不能根据许多不同病灶的发生给出患者感染的严重程度。因此,这些方法不能提供更合理的治疗方案。此外,上述方法没有很好地考虑 COVID-19 病灶与其他分割任务之间的差异,使 COVID-19 病灶难以分割。COVID-19 病灶与其他分割任务的主要区别如下:一些感染区域的边界不明显 ;一些感染区域与自然区域的对比度低;感染区域的形状和大小是多尺度的。我们提出了一个模型来解决这些困难。我们使用一个粗分割模块从输入图像获取粗略的分割结果。我们采用一个细化模块来学习粗分割结果与真实值之间的残差,以调整错误的分割输出,特别是边缘部分。此外,我们在粗分割模块和细化模块中都加入了空洞空间金字塔池化模块,使网络能够准确检测不同尺度的感染区域。我们采用混合损失作为训练损失,帮助指导模型准确预测具有清晰边界的精细结构。然而,我们的方法也有其局限性。我们网络的结构相对较重,模型的参数也相对较大,与一些其他方法相比需要更多相应的计算资源。我们相信这种方法是通用的,在其他分割任务中也能取得良好效果。我们将来会在其他领域尝试这种方法。
Figure
图

FIGURE 1 The proposed segmentation network. the green, blue, and red dotted boxes are the coarse segmentation, the segmentation refinement, and the atrous spatial pyramid pooling (ASPP) modules, respectively
图 1所提出的分割网络。绿色、蓝色和红色虚线框分别代表粗分割、分割细化和空洞空间金字塔池化(ASPP)模块。
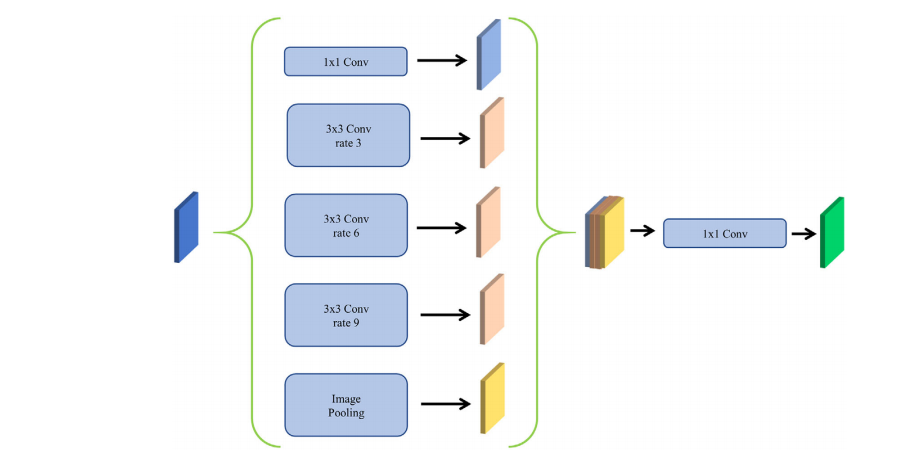
FIGURE 2 The atrous spatial pyramid pooling structure of our model
图 2我们模型的空洞空间金字塔池化结构
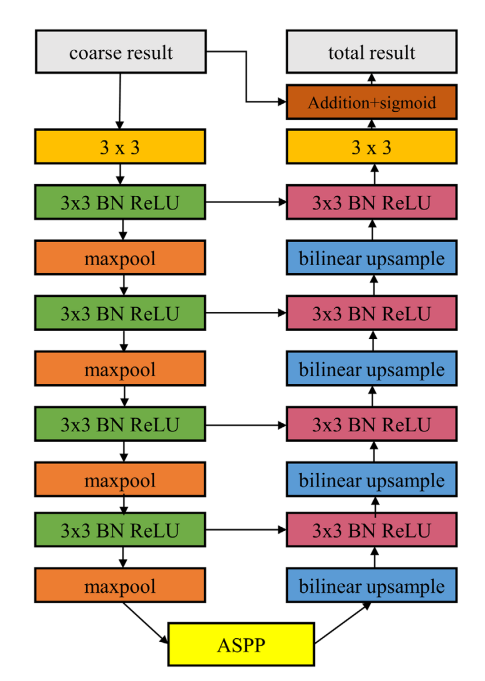
FIGURE 3 The structure of the segmentation refinement module
图 3分割细化模块的结构
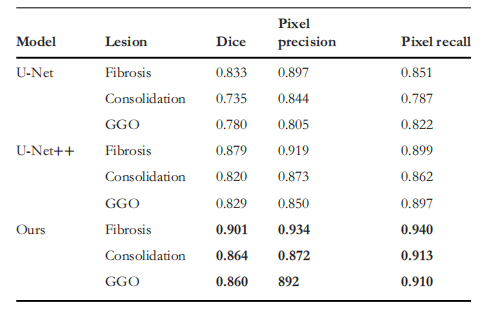
FIGURE 4 The relation diagram between different types of lesions and the severity of the disease, the abscissa is the severity of the disease, and the ordinate is the ratio area of the lesion in the lung area. the (a), (b), and ©, in turn, represent fibrosis, consolidation, and ground-glass opacity. the ground truth is represented by blue on the left and the predict result is represented by brown on the right
图 4不同类型病灶与疾病严重程度之间的关系图,横坐标是疾病的严重程度,纵坐标是病灶在肺部区域的比例面积。其中 (a)、(b) 和 © 分别代表纤维化、实变和磨玻璃样不透明。真实情况以左侧的蓝色表示,预测结果以右侧的棕色表示。
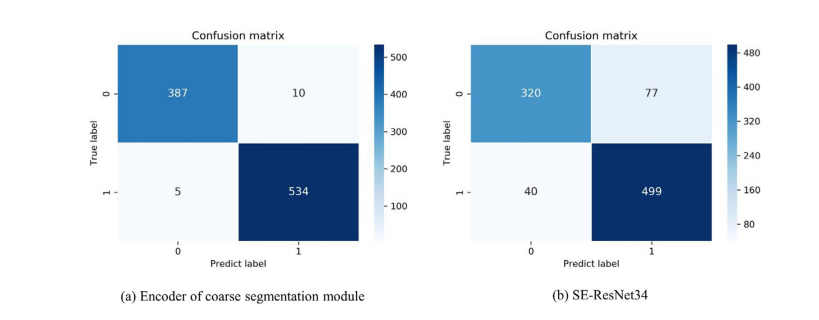
FIGURE 5 The confusion matrix on the five-fold test set for diagnosing whether a person is infected with COVID-19. the person that predicted without COVID-19 is represented by 0, and the patient with COVID-19 is represented by 1. (a) represent the classification model is the encoder of the coarse segmentation model, and (b) mean the classification is the SE-ResNet34
图 5用于诊断一个人是否感染 COVID-19 的五折测试集上的混淆矩阵。预测未感染 COVID-19 的个体用 0 表示,感染 COVID-19 的患者用 1 表示。其中 (a) 代表分类模型是粗分割模型的编码器,(b) 表示分类是 SE-ResNet34。

FIGURE 6 The visualisation of the segmentation results. blue, green, and red represent fibrosis, consolidation, and ground-glass opacity, respectively. column (a) are the original images, column (b) are the contour labels of the lesion regions given by the doctors, column © is the segmentation result of U-Net which dice is 0.793 and the accuracy is 0.856, and column (d) is our result which dice is 0.870, and the accuracy is 0.983
图 6分割结果的可视化。蓝色、绿色和红色分别代表纤维化、实变和磨玻璃样不透明。列 (a) 是原始图像,列 (b) 是由医生给出的病灶区域轮廓标签,列 © 是 U-Net 的分割结果,其 Dice 系数为 0.793,准确度为 0.856,列 (d) 是我们的结果,其 Dice 系数为 0.870,准确度为 0.983。
Table
表
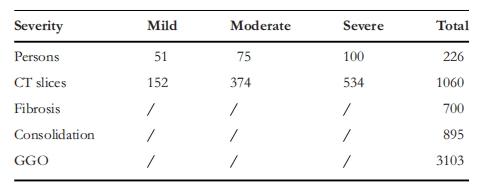
TABLE 1 The number of patients, CT slices, and the number of annotated numbers of lesions for three different severity levels of patients withCOVID-19
表1患者数量、CT 切片数量以及三种不同严重程度的 COVID-19 患者病灶注释数量
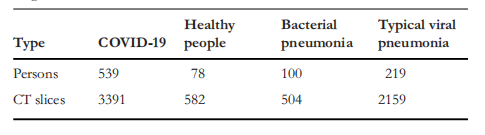
TABLE 2 The number of persons and CT slices of the different kinds of lung classification dataset
表 2不同种类的肺分类数据集的人数和 CT 切片数量
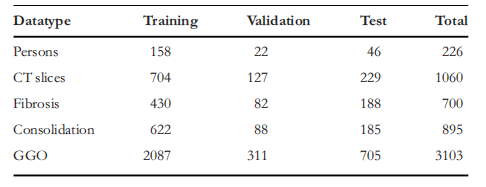
TABLE 3 The number of COVID-19 patients, the number of CT slices, and the number of various types of lesions in a fold of training set, validation set, and test set
表 3 COVID-19 患者数量、CT 切片数量以及训练集、验证集和测试集中各种类型病灶的数量
TABLE 4Results of segmentation between different models in different type lesions
表 4不同模型在不同类型病灶分割中的结果
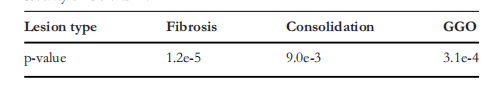
TABLE 5 The p-value of the predicted proportion of lesion area and severity of COVID-19
表 5预测的病灶面积比例与 COVID-19 严重程度的 p 值
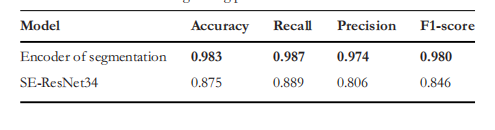
TABLE 6 Performance comparisons on SE-ResNet34 and our classification model in distinguishing patients with COVID-19
表 6 在区分 COVID-19 患者方面,SE-ResNet34 与我们的分类模型的性能比较
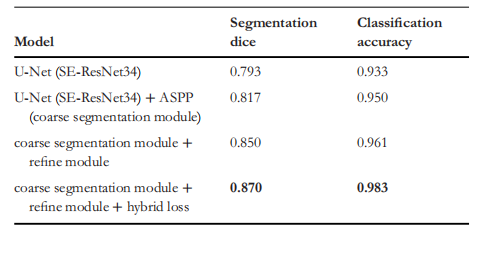
TABLE 7 The improvement of each component in our model
表 7我们模型中每个组件的改进情况