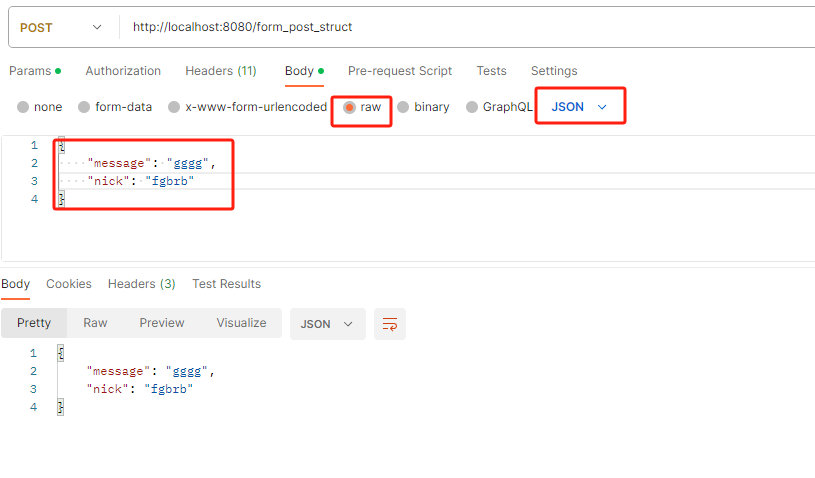
JS调用栈:为何会栈溢出
- JS调用栈
- 什么是函数调用
- 什么是栈
- 在开发中利用调用栈
- 栈溢出
JS调用栈
JavaScript 经常会出现一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构,首先你要先弄明白函数调用和栈结构
什么是函数调用
先来看一段简单的示例代码:
var a = 2
function add() {
var b = 10
return a + b
}
add()
下面利用这段简单的示例代码来解释下函数调用的过程(参考下图):
- 在执行函数
add()之前,JavaScript 引擎会为上面这段代码创建全局执行上下文,代码中全局变量和函数都保存在这个全局上下文的变量环境中 - 执行上下文准备好之后,便开始执行全局代码,当执行到
add()时,JavaScript 判断这是一个函数调用,那么将会从全局执行上下文中取出add函数代码 - 接下来对取出的
add函数代码进行编译,并创建该函数的执行上下文和可执行代码 - 最后执行代码,输出结果
流程可以参考下图:
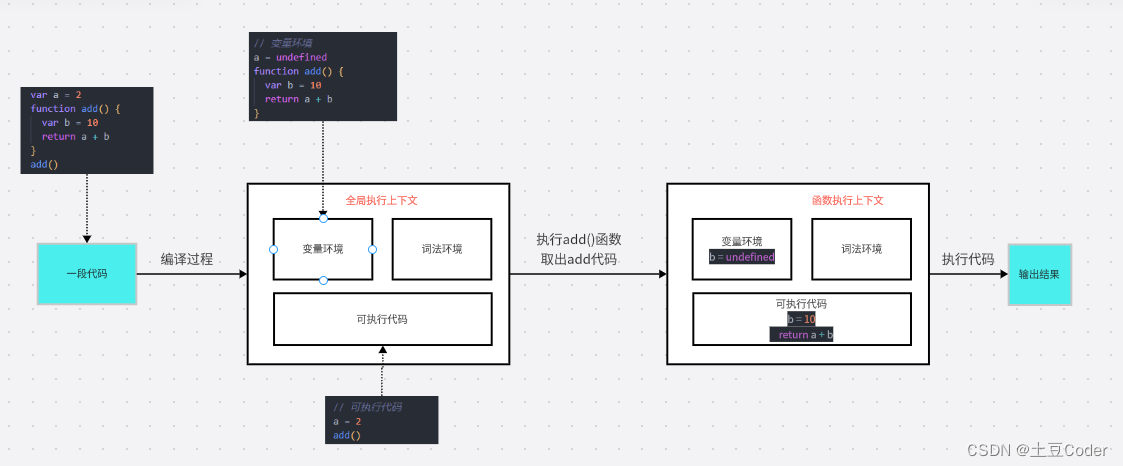
如果你不知道为何变量环境中的
a = undefined,建议你先去了解JS变量和函数提升
也就是说在执行 JavaScript 时,可能会存在多个执行上下文,那么 JavaScript 引擎是如何管理这些执行上下文的呢?
答案就是通过一种叫栈的数据结构。
什么是栈
栈就类似于一端被堵住的单行线,栈中的元素满足后进先出的特点。JavaScript 引擎正是利用栈的这种结构来管理执行上下文的,在执行上下文创建好后,JavaScript 引擎会将其压入栈中,通常这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈(call stack)。
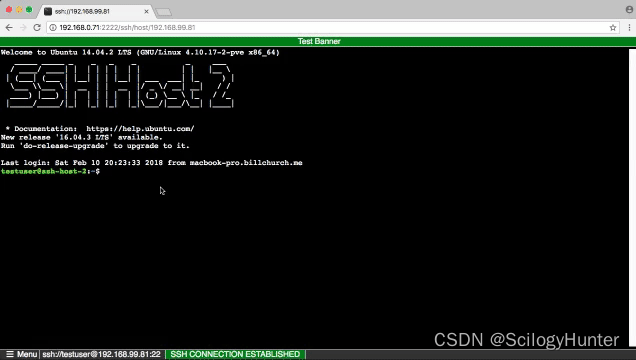
为了更好的理解调用栈,下面来看一段稍微复杂点的示例代码:
var a = 2
function add(b, c) {
return b + c
}
function addAll(b, c) {
var d = 10
result = add(b, c)
return a + result + d
}
addAll(3, 6)
- 第一步,创建全局上下文,并将其压入栈底。变量
a、函数add和addAll都保存在了全局上下文的变量环境对象中 - 此时已经没有声明变量和函数了,开始执行可执行代码,首先会执行
a = 2的赋值操作 - 继续执行,调用
addAll()函数。JavaScript 引起会编译该函数,并为其创建一个函数执行上下文,并将其压入栈中 addAll的执行变量中先定义d = undefined,然后执行可执行代码时会执行add()函数- 为
add函数创建函数上下文,并将其压入栈中 - 当
add函数返回时,该函数的执行上下文就会从栈顶弹出,并将result值设置为add()执行的返回值 - 紧接着
addAll()执行最后一个操作后返回,addAll的执行上下文也会从栈顶弹出,此时调用栈就只剩下全局上下文了 - 至此,整个 JavaScript 流程执行结束
流程图可参考下图:
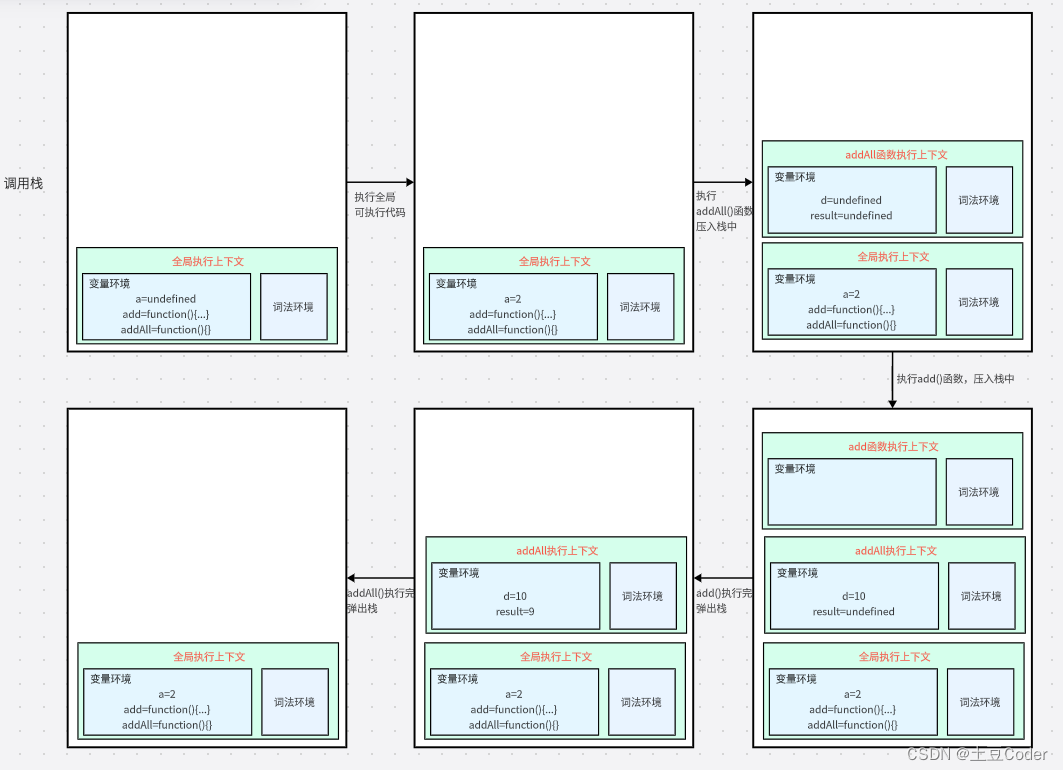
调用栈是 JavaScript 引擎追踪函数执行的一个机制,当一次有多个函数被调用时,通过调用栈能够追踪到哪个函数正在被执行以及函数之间的调用关系。
在开发中利用调用栈
当我们在 add 函数返回值之前打入一个断点
function add(b, c) {
debugger
return b + c
}
刷新页面,打开浏览器开发者中的 Source 面板
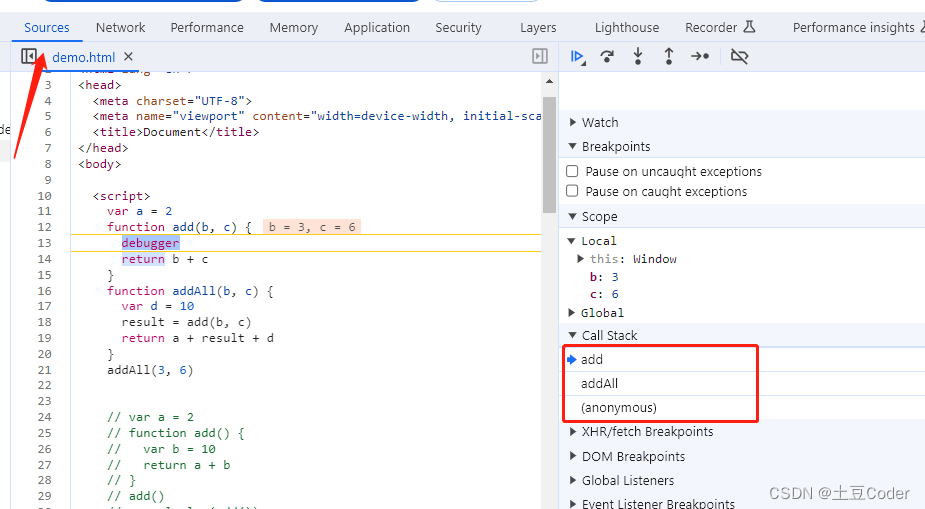
图中,Call Stack 下面显示出来的就是函数的调用栈,栈底部是 anonymous,也就是全局的函数入口,中间的是 addAll 函数,顶部是 add 函数,跟我们上面分析的执行流程图一样,这就清晰地反映了函数的调用关系。
除此以外,还可以使用 console.trace() 来输出当前的函数调用关系,比如将上面的 debugger 替换成 console.trace(),控制台打印结果如下:

栈溢出
调用栈是有大小的,当入栈的执行上下文超过一定数目,JavaScript 引擎就会报错,我们将这种错误叫做栈溢出。特别是在写递归的时候,很容易出现这种错误。比如下面的这段代码:
function division(a, b) {
return division(a, b)
}
console.log(division(1, 2))
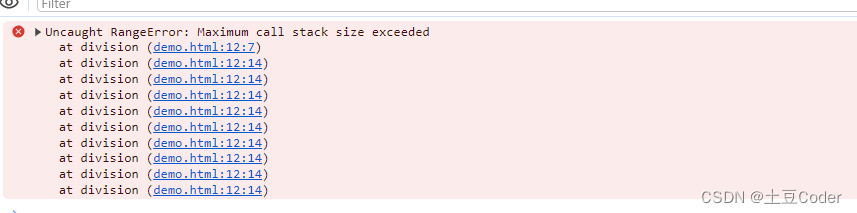
JavaScript 引擎调用函数 division 时创建函数执行上下文,压入栈中;执行 division 函数内部可执行代码时又遇到了 division 函数,所以它会再创建一个函数执行上下文,因为这个函数是递归且没有任何终止条件的,所以会一直反复创建函数执行上下文并压入栈中,但栈是有容量限制的,超过最大数量后就会出现栈溢出的错误。