导入库
import torchvision
import torch
from torchvision.transforms import ToTensor
from torch import nn
import matplotlib.pyplot as plt导入手写字体数据
train_ds=torchvision.datasets.MNIST('data/',train=True,transform=ToTensor(),download=True)
test_ds=torchvision.datasets.MNIST('data/',train=False,transform=ToTensor(),download=True)
train_dl=torch.utils.data.DataLoader(train_ds,batch_size=64,shuffle=True)
test_dl=torch.utils.data.DataLoader(test_ds,batch_size=46)
imgs,labels=next(iter(train_dl))
print(imgs.shape)
print(labels.shape)
从上述代码中可以看到,train_dl返回的图片数据是四维的,4个维度分别代表批次、通道数、高度和宽度(batch,channel,height,width),这正是PyTorch下卷积模型所需要的图片输入格式
创建卷积模型并训练
下面创建卷积模型来识别MNIST手写数据集。我们所创建的卷积模型先试用两个卷积层和两个池化层,然后将最后一个池化的输出展平为二维数据形式连接到全连接层,最后是输出层,中间的每一层都是用ReLU函数激活,输出层的输出张量长度为10,与类别数一致。代码如下
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,6,5) #初始化第一个卷积层
self.conv2=nn.Conv2d(6,16,5) #初始化第二个卷积层
self.liner_1=nn.Linear(16*4*4,256) #初始化全连接层16*4*4为输入的特征,256为输出的特征
#就是将一个大小为16×4×4的输入特征映射到一个大小为256的输出特征空间中
self.liner_2=nn.Linear(256,10) #初始化输出层
def forward(self,input):
#调用第一个卷积层和池化层
x=torch.max_pool2d(torch.relu(self.conv1(input)),2)
#调用第二个卷积层和池化层
x=torch.max_pool2d(torch.relu(self.conv2(x)),2)
# view()方法将数据展平为二维形式
# torch.Size([64,16,4,4])->torch.Size([64,16*4*4])
x=x.view(-1,16*4*4)
x=torch.relu(self.liner_1(x)) # 全连接层
x=self.liner_2(x) #输出层
return x
#判断当前可用的device,如果显卡可用,就设置为cuda,否则设置为cpu
device="cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
#初始化模型,并使用.to()方法将其上传到device
#如果GPU可以用,会上传到显存,如果device是CPU,依保留在内存
model=Model().to(device) # 初始化模型并设置设备
print(model)
loss_fn=nn.CrossEntropyLoss() # 初始化交叉熵损失函数
optimizer=torch.optim.SGD(model.parameters(),lr=0.001) # 初始化优化器
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset) # 获取当前数据集样本总数量
num_batches=len(dataloader) #获得当前dataloader总批次数
# train_loss用于累计所有批次的损失之和,correct用于累计预测正确的样本总数
train_loss,correct=0,0
for X,y in dataloader: #对dataloader进行迭代
X,y=X.to(device),y.to(device) #每一批次的数据设置为使用当前device进行预测,并计算一个批次的损失
pred=model(X)
loss=loss_fn(pred,y) # 返回的是平均损失
#使用反向传播算法,根据损失优化模型参数
optimizer.zero_grad() #将模型参数的梯度全部归零
loss.backward() # 损失反向传播,计算模型参数梯度
optimizer.step() # 根据梯度优化参数
with torch.no_grad():
# correct 用于累计预测正确的样本总数
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()
#train_loss用于累计所有批次的损失之和
train_loss+=loss.item()
#train_loss是所有批次的损失之和,所以计算全部样本的平均损失时需要处于总批次数
train_loss/=num_batches
#correct是预测正确的样本总是,若计算整个epoch总体正确率,需除以样本总数量
correct/=size
return train_loss,correct
def test(dataloader,model):
size=len(dataloader.dataset)
num_batches=len(dataloader)
test_loss,correct=0,0
with torch.no_grad():
for X,y in dataloader:
X,y=X.to(device),y.to(device)
pred=model(X)
test_loss+=loss_fn(pred,y).item()
correct+=(pred.argmax(1)==y).type(torch.float).sum().item()
test_loss/=num_batches
correct/=size
return test_loss,correct
epochs=50 #一个epoch代表对全部数据训练一遍
train_loss=[] #每个epoch训练中训练数据集的平均损失被添加到此列表
train_acc=[] #每个epoch训练中训练数据集的平均正确率被添加到此列表
test_loss=[] #每个epoch训练中测试数据集的平均损失被添加到此列表
test_acc=[] #每个epoch训练中测试数据集的平均正确率被添加到此列表
for epoch in range(epochs):
#调用train()函数训练
epoch_loss,epoch_acc=train(train_dl,model,loss_fn,optimizer)
#调用test()函数测试
epoch_test_loss,epoch_test_acc=test(test_dl,model)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
#定义一个打印模版
template=("epoch:{:2d},train_loss:{:.5f},train_acc:{:.1f}%,test_loss:{:.5f},test_acc:{:.1f}%")
#输出当前的epoch的训练集损失、训练集正确率、测试集损失、测试集正确率
print(template.format(epoch,epoch_loss,epoch_acc*100,epoch_test_loss,epoch_test_acc*100))
print("Done!")
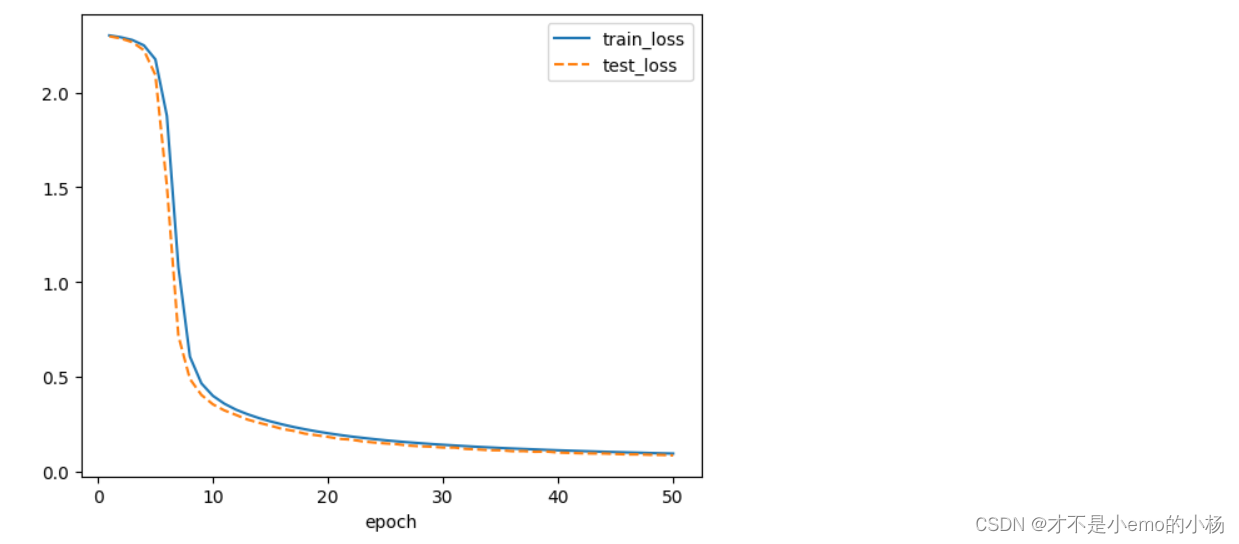
plt.plot(range(1,epochs+1),train_loss,label="train_loss")
plt.plot(range(1,epochs+1),test_loss,label='test_loss',ls="--")
plt.xlabel('epoch')
plt.legend()
plt.show()
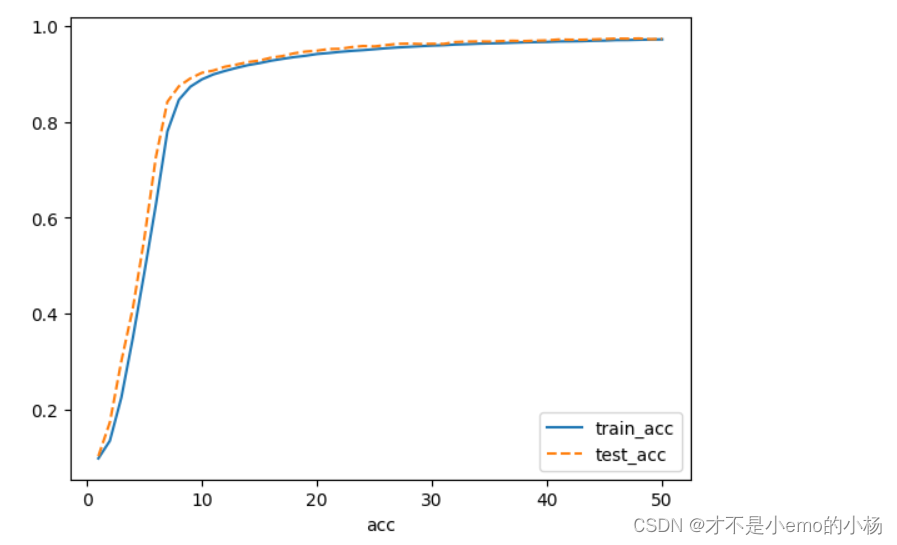
plt.plot(range(1, epochs + 1), train_acc, label="train_acc")
plt.plot(range(1, epochs + 1), test_acc, label='test_acc', ls="--")
plt.xlabel('acc')
plt.legend()
plt.show()
函数式API
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,6,5) #初始化第一个卷积层
self.conv2=nn.Conv2d(6,16,5) #初始化第二个卷积层
self.liner_1=nn.Linear(16*4*4,256) #初始化全连接层16*4*4为输入的特征,256为输出的特征
#就是将一个大小为16×4×4的输入特征映射到一个大小为256的输出特征空间中
self.liner_2=nn.Linear(256,10) #初始化输出层
def forward(self,input):
#调用第一个卷积层和池化层
x=F.max_pool2d(F.relu(self.conv1(input)),2)
#调用第二个卷积层和池化层
x=F.max_pool2d(F.relu(self.conv2(x)),2)
# view()方法将数据展平为二维形式
# torch.Size([64,16,4,4])->torch.Size([64,16*4*4])
x=x.view(-1,16*4*4)
x=F.relu(self.liner_1(x)) # 全连接层
x=self.liner_2(x) #输出层
return x