Havenask 是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了 Havenask 分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系统提升竞争力的一大利器。
一、Havenask 介绍
Havenask 是阿里巴巴广泛使用的自研大规模分布式检索系统,是过去十多年阿里在电商领域积累下来的核心竞争力产品,广泛应用在搜推广和大数据检索等典型场景,在 2022 年云栖大会-云计算加速开源创新论坛上完成开源首发,同时作为阿里云开放搜索 OpenSearch 底层搜索引擎,OpenSearch 自 2014 年商业化,目前已有千余家外部客户。
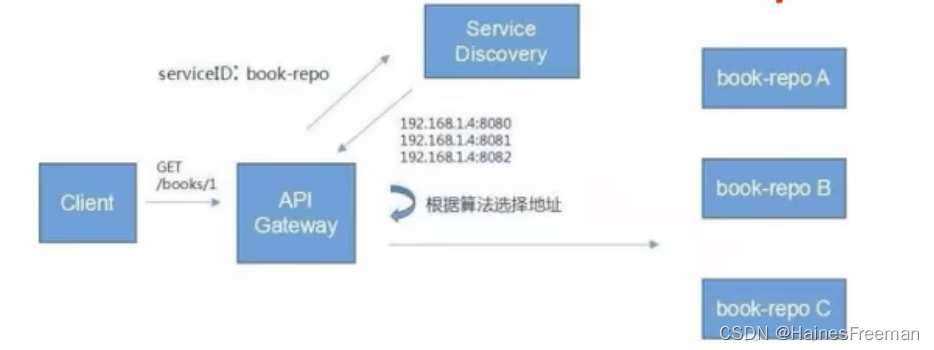
下图展示了 Havenask 中一个完整的搜索服务:在线系统、索引系统、管控系统、扩展插件,且包括了查询流、数据流、控制流。其中,索引系统负责索引数据生成的过程,还包含有文档处理与本文的主角索引构建服务 Build Service。索引构建分为三个步骤,对数据进行前置处理(例如分词、向量计算等)、产出索引、合并索引文件的处理。

Havenask 支持千亿级别数据实时检索、百万 QPS 查询,百万 TPS 高时效性写入保障,毫秒级查询延迟和数据更新,并具有良好的分布式架构、极致的性能优化,能够实现比现有技术方案更低的成本,普惠更多的开发者和企业。
二、Build Service 简介
Build Service 是一个分布式索引构建服务,用于 Havenask 中的全量表的索引构建。它可以对接本地存储、HDFS 等多种数据源,快速的将原始数据构建成全量索引,并以流式工作模式进行增量索引构建。Build Service 是 Havenask 读写分离架构的重要组成部分,独立的索引构建服务使 Havenask 具有下面优势:
在线系统更加稳定:将索引构建从在线系统分离,避免了索引构建对在线系统的影响,使在线系统更加稳定。
索引构建更快:特有的全量流程,使全量数据导入更快;独立的资源控制,进一步提升索引构建速度。
多版本索引管理:多版本独立的构建流程管理,使索引重建更方便,更安全。
三、Build Service 架构
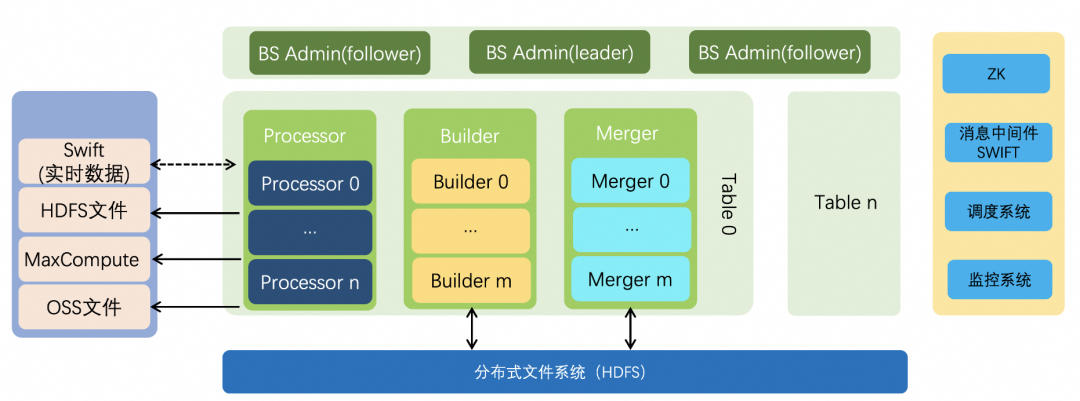
Build Service 架构图
上图是 Build Service 的架构,在 Build Service 中主要有下面几个角色:
BS Admin:BS Admin 负责整个集群的任务调度和资源管理。BS Admin 提供丰富的接口进行索引构建任务的启停,资源的调整等,BS Admin 接收到这些请求之后会进行任务的调度,并配合调度系统,调度任务的执行,并维护任务的状态。
Processor:Processor 从数据源中拉取数据进行处理,Processor 可以支持多种数据源,比如 HDFS、OSS 等分布式文件系统,也可以对接 Swift 消息中间件处理实时数据。在 Processor 中主要是对数据进行分词、简单的数据转换等处理,开发者可以通过定制数据源 reader 插件和数据处理 DocumentProcessor 插件来扩展支持不同的数据源和数据处理逻辑。
Builder:Builder 负责索引的构建,它将经过 Processor 处理的数据按照 Schema 的配置构建成倒排、正排、摘要索引。Builder 与 Processor 的数据交互是通过 Swift 消息中间件来实现的,即 Processor 将处理之后的数据写到 Swift,Build 从 Swift 中读取这些数据进行索引构建。
Merger:Merger 负责索引的定期整理,定期索引整理使索引文件更加紧凑,可以降低在线集群索引加载的内存开销,提升检索性能。索引整理时会清理已经删除的数据,将小的索引文件合并成大的索引文件,也可以按照配置在整理时根据某个字段进行离线排序,这样可以进一步提升检索性能。
在一个 Build Service 服务中可以有一个或者多个 BS Admin,它们通过 ZK 进行 leader 选举,只有 leader 才会管理整个 Build Service 服务,其他 Admin 作为 fllower,使服务更加稳定。一个 Build Service 服务可以同时管理多个表或者同一个表的不同版本的索引构建任务,每个任务都是相互隔离的,互不影响。每个索引构建任务都有各自的 Processor、Builder、Merger 节点进行数据的处理,索引的构建。每个索引构建任务可以独立进行资源控制,比如调整 Processor 节点的个数,Builder 和 Meger 的并发度,以及这些节点的 CPU 和内存等。
对于 Processor、Builer 和 Meger 节点,它们只有分片(Shard)的概念,没有备份的概念。比如对于 Processor,每个分片处理不同的数据,一个分片只会启动一个节点,如果某些原因启动了多个节点,多个节点之间通过 ZK 进行 leader 选举,只有 leader 节点才会存活并工作,非 leader 节点的进程会自动退出。Builder 和 Merger 的情况与 Processor 类似,唯一不同的是分片数是在创建表时就确定的,它们只能基于分片数据调节并发度,因此 Builder 和 Meger 节点真实启动的个数是分片数乘以并发度。
四、索引构建流程
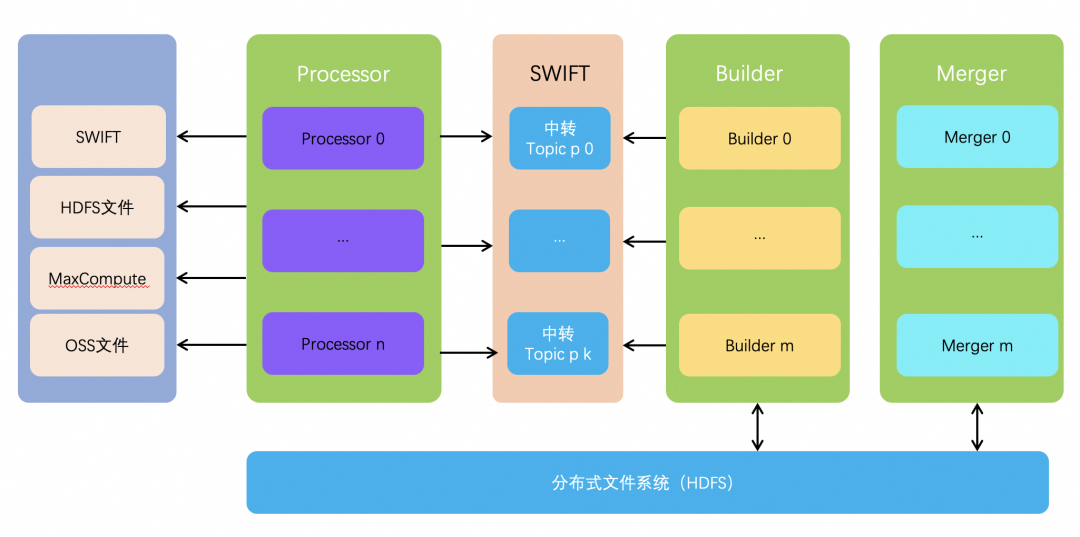
索引构建流程示意图
Build Service 的索引构建分为两个阶段:全量索引构建和增量索引构建。每个索引构建任务都会先进行全量索引构建,全量结束之后会自动切换到增量索引构建阶段,增量索引构建任务会一直执行,直至这次索引构建任务停止。全量索引构建任务会首先从分布式文件系统读取原始数据构建成索引(如果没有配置,这步会跳过),全量文件处理完成之后,会继续从 Swift 中读取数据继续构建全量索引。这样等全量流程结束之后,全量索引中的数据已经通过消费 Swift 追到距离当前比较靠近的时间了,索引切上线之后不会出现较长时间的时效性延迟。
无论是全量索引构建还是增量索引构建,它们的索引构建流程是类似的。首先 Processor 节点会从数据源中(包括 Swift)读取原始数据,然后对数据进行分词或者其他处理,处理之后的数据会转发到 Swift 的中。Builder 和 Merger 的任务是交替执行的,首先 Builder 从 Swift 中读取处理之后的数据,构建成索引,索引产出在分布式文件系统中。对于全量索引构建,全量数据被全部构建为索引之后 Builder 就会结束;对于增量索引构建,Builder 接受 BS Admin 的调度,将数据处理到某个时间点就会退出。Builder 结束之后,Meger 节点就会执行,Meger 会对构建的索引按照一定的策略进行整理,整理好的索引也会写回分布式文件系统。
需要注意的是,增量索引构建时,Processor 处理之后的数据不仅仅供 Builder 消费,在线的 Searcher 节点也会直接消费,将其构建成实时索引。
五、Build Service 定制能力
为了满足不同业务的需求,Build Service 在构建索引时支持下面三种定制能力:分析器的定制、数据源插件的定制、数据处理插件的定制。开发者可以直接修改代码将定制逻辑与 Havenask 一起编译成一个 Binary 生效,也可以建立单独的目录将其编译成动态库,通过插件的方式生效。
分析器定制:分析器主要用于对文档进行分词,开发者可以通过定制分析器定制自己的分词逻辑,分析器不仅会在构建索引时生效,在查询时也会生效。
数据源插件定制:Havenask 主要支持 HDFS、OSS、MaxCompute、Swift 等数据源,如果要支持更多的数据源比如 kafka,可以定制 Processor 的 Reader 插件。
数据处理定制:数据在 Processor 中是由一个 DocumentProcessor 链进行处理的,用户可以定制自己的 DocumentProcessor 处理类来扩展数据处理逻辑。
六、Build Service 与 Indexlib(核心索引库)的关系
Indexlib 是 Havenask 的核心索引库,提供正排、倒排、摘要等索引的实现,并在此基础上抽象出了各种表模型,比如 normal 表、kv 等、kkv 表等。但是 Indexlib 无法独立提供索引构建服务,必须通过 Build Service 才能进行索引构建。可以说,Indexlib 提供了各种索引的定义,并提供了索引构建的接口,Build Service 定义了流式索引构建的框架,两者相结合才使 Havenask 具有了强大的索引构建能力。
七、总结
Build Service 是一个流式的索引构建服务,能够轻松完成海量数据的索引构建,对在线系统没有任何影响,极大提高了整个集群的稳定性。独立的索引构建任务管理,可以方便、安全的对同一张表进行多次索引构建,特别适用于智能搜索场景下需要定期索引重建的场景。当然,Build Service 的引入也使得整个系统的架构更加复杂,数据生效链路变长,资源开销变大,大家在使用时请根据业务情况认真选择。
Havenask 开源官网:
https://havenask.net/
Havenask 开源项目地址:
https://github.com/alibaba/havenask
阿里云 OpenSearch 官网:
https://www.aliyun.com/product/opensearch