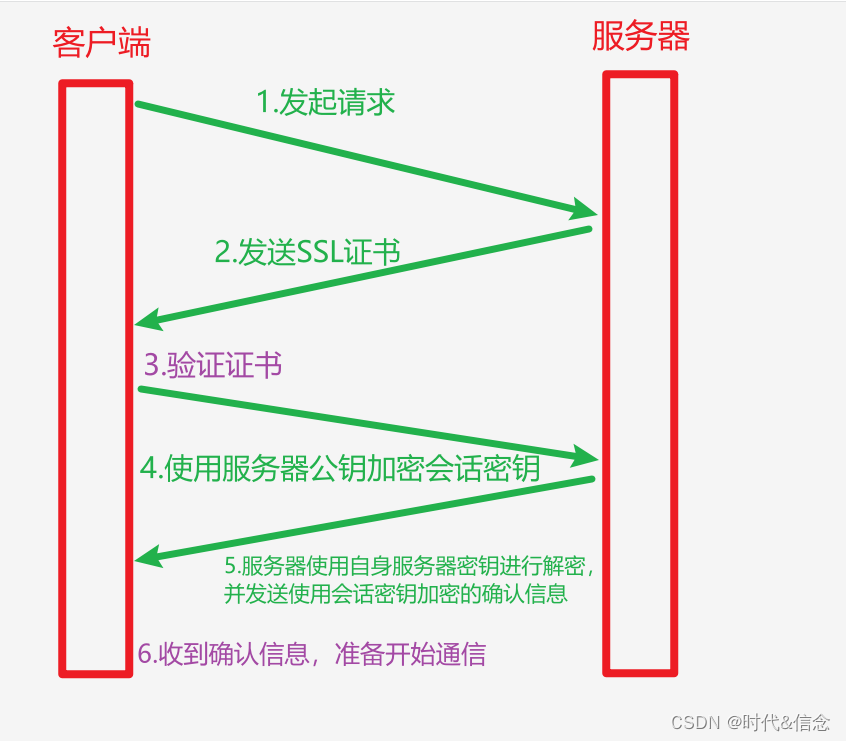
由于业务变迁,合规要求,我们需要删除大量非本公司的数据,涉及到上百张表,几个T的数据清洗。我们的做法是先从基础数据出发,将要删除的数据id收集到一张表,然后再由上往下删除子表,多线程并发处理。
我们使用的是阿里的polardb,完全兼容mysql协议,5.7版本,RC隔离级别。删除过程一直很顺利,突然有一天报了大量:“Lock wait timeout exceeded; try restarting transaction”。从日志上看是获取锁失败了,马上想到出现死锁了,但我们使用RC,这个隔离级别下会出现不可重复读和幻读,但没有间隙锁等,并发效率比较高,在我们实际应用过程中,也很少遇到加锁失败的问题。
单从日志看我们确实先入为主了,以为是死锁问题,但sql比较简单,表数据量在千万级别,其中task_id和uid均有索引,如下:
delete from t_table_1 where task_id in (select id from t_table_2 where uid = #{uid})
拿到报错的参数,查询要删除的数据也不多,联系dba同学确认没有死锁日志,但出现大量慢sql,那为什么这条sql会是慢sql呢?
问题复现
表结构简化如下:
CREATE TABLE `t_table_1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`task_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_task_id` (`task_id`)
) ENGINE=InnoDB;
CREATE TABLE `t_table_2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`uid` bigint(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`)
) ENGINE=InnoDB;
开始我们拿sql到数据库查询平台查库执行计划,无奈这个平台有bug,delete语句无法查看,所以我们改成select,“应该”是一样。这个“应该”加了双引号,导致我们走了一点弯路。
EXPLAIN SELECT * from t_table_1 where task_id in (select id from t_table_2 where uid = 1)
explain后可以看到是走了索引的

到这里可以总结:
1.没有死锁,这点比较肯定,因为没有日志,也符合我们的理解。
2.有慢sql,这点比较奇怪,通过explain select语句是走索引的,但数据库慢日志记录到,全表扫描,不会错。
那是select和delete的执行计划不同吗?正常来说应该是一样的,delete无非就是先查,加锁,再删。