踩雷了无数次终于解决了Superset的一系列问题
现在是北京时间2023年12月27日,亲测有效。
Superset概述
Apache Superset是一个现代的数据探索和可视化平台。它功能强大且十分易用,可对接各种数据源,包括很多现代的大数据分析引擎,拥有丰富的图表展示形式,并且支持自定义仪表盘。

特别注意:
下面的教程所使用的服务器操作系统为CentOS 7,Superset对接的数据源为MySQL数据库。
Superset官网地址:Welcome | Superset
安装Python环境
Superset是由Python语言编写的Web应用,要求Python3.7以上的环境。
安装Miniconda
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。
此处,我们不需要如此多的工具包,故选择MiniConda。
下载Miniconda(Python3版本)
下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
安装Miniconda
(1)执行以下命令进行安装,并按照提示操作,直到安装完成。
[zhangxi@hadoop102 lib]$ bash Miniconda3-latest-Linux-x86_64.sh
(2)在安装过程中,出现以下提示时,可以指定安装路径 /opt/module/miniconda3

(3)出现以下字样,即为安装完成
![]()
3)加载环境变量配置文件,使之生效
[zhangxi@hadoop102 lib]$ source ~/.bashrc
4)取消激活base环境
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
[zhangxi@hadoop102 lib]$ conda config --set auto_activate_base false
创建Python3.8环境
1)配置conda国内镜像(此处可不配置,国外镜像比清华镜像更快)
(base) [zhangxi@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
(base) [zhangxi@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(base) [zhangxi@hadoop102 ~]$ conda config --set show_channel_urls yes
查看conda的镜像channel配置
[zhangxi@hadoop102 ~]$ conda config --show channels
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- defaults
删除清华镜像,继续用默认的
[zhangxi@hadoop102 ~]$ conda config --remove-key channels
[zhangxi@hadoop102 ~]$ conda config --show channels
- defaults
2)创建Python3.8环境
(base) [zhangxi@hadoop102 ~]$ conda create --name superset python=3.8.16
说明:conda环境管理常用命令
创建环境:conda create -n env_name
查看所有环境:conda info --envs
删除一个环境:conda remove -n env_name --all
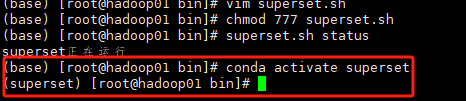
3)激活superset环境
(base) [zhangxi@hadoop102 ~]$ conda activate superset
激活后效果如下图所示
说明:退出当前环境
(superset) [zhangxi@hadoop102 ~]$ conda deactivate
4)执行python -V命令查看python版本
(superset) [zhangxi@hadoop102 ~]$ python -V
Python 3.8.16
Superset部署
安装依赖
安装Superset之前,需安装以下所需依赖。
(superset) [zhangxi@hadoop102 ~]$ sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
安装Superset
1)更新pip
(superset) [zhangxi@hadoop102 ~]$ pip install --upgrade pip -i https://pypi.douban.com/simple/
说明:pip是python的包管理工具,可以和centos中的yum类比
2)安装Supetset
vim base.txt文件至任意路径,添加以下内容
aiohttp==3.8.1
# via slackclient
aiosignal==1.2.0
# via aiohttp
alembic==1.6.5
# via flask-migrate
amqp==5.1.0
# via kombu
apispec[yaml]==3.3.2
# via flask-appbuilder
async-timeout==4.0.2
# via aiohttp
attrs==21.2.0
# via
# aiohttp
# jsonschema
babel==2.9.1
# via flask-babel
backoff==1.11.1
# via apache-superset
billiard==3.6.4.0
# via celery
bleach==3.3.1
# via apache-superset
brotli==1.0.9
# via flask-compress
cachelib==0.4.1
# via apache-superset
celery==5.2.2
# via apache-superset
cffi==1.14.6
# via cryptography
charset-normalizer==2.0.4
# via aiohttp
click==8.0.4
# via
# apache-superset
# celery
# click-didyoumean
# click-plugins
# click-repl
# flask
# flask-appbuilder
click-didyoumean==0.3.0
# via celery
click-plugins==1.1.1
# via celery
click-repl==0.2.0
# via celery
colorama==0.4.4
# via
# apache-superset
# flask-appbuilder
convertdate==2.3.2
# via holidays
cron-descriptor==1.2.24
# via apache-superset
croniter==1.0.15
# via apache-superset
cryptography==3.4.7
# via apache-superset
deprecation==2.1.0
# via apache-superset
dnspython==2.1.0
# via email-validator
email-validator==1.1.3
# via flask-appbuilder
flask==2.0.3
# via
# apache-superset
# flask-appbuilder
# flask-babel
# flask-caching
# flask-compress
# flask-jwt-extended
# flask-login
# flask-migrate
# flask-sqlalchemy
# flask-wtf
flask-appbuilder==4.1.3
# via apache-superset
flask-babel==1.0.0
# via flask-appbuilder
flask-caching==1.10.1
# via apache-superset
flask-compress==1.10.1
# via apache-superset
flask-jwt-extended==4.3.1
# via flask-appbuilder
flask-login==0.4.1
# via flask-appbuilder
flask-migrate==3.1.0
# via apache-superset
flask-sqlalchemy==2.5.1
# via
# flask-appbuilder
# flask-migrate
flask-talisman==0.8.1
# via apache-superset
flask-wtf==0.14.3
# via
# apache-superset
# flask-appbuilder
frozenlist==1.3.0
# via
# aiohttp
# aiosignal
func-timeout==4.3.5
# via apache-superset
geographiclib==1.52
# via geopy
geopy==2.2.0
# via apache-superset
graphlib-backport==1.0.3
# via apache-superset
gunicorn==20.1.0
# via apache-superset
hashids==1.3.1
# via apache-superset
holidays==0.10.3
# via apache-superset
humanize==3.11.0
# via apache-superset
idna==3.2
# via
# email-validator
# yarl
isodate==0.6.0
# via apache-superset
itsdangerous==2.1.1
# via
# flask
# flask-wtf
jinja2==3.0.3
# via
# flask
# flask-babel
jsonschema==3.2.0
# via flask-appbuilder
kombu==5.2.4
# via celery
korean-lunar-calendar==0.2.1
# via holidays
mako==1.1.4
# via alembic
markdown==3.3.4
# via apache-superset
markupsafe==2.0.1
# via
# jinja2
# mako
# wtforms
marshmallow==3.13.0
# via
# flask-appbuilder
# marshmallow-enum
# marshmallow-sqlalchemy
marshmallow-enum==1.5.1
# via flask-appbuilder
marshmallow-sqlalchemy==0.23.1
# via flask-appbuilder
msgpack==1.0.2
# via apache-superset
multidict==5.1.0
# via
# aiohttp
# yarl
numpy==1.22.1
# via
# apache-superset
# pandas
# pyarrow
packaging==21.3
# via
# bleach
# deprecation
pandas==1.3.4
# via apache-superset
parsedatetime==2.6
# via apache-superset
pgsanity==0.2.9
# via apache-superset
polyline==1.4.0
# via apache-superset
prison==0.2.1
# via flask-appbuilder
prompt-toolkit==3.0.28
# via click-repl
pyarrow==5.0.0
# via apache-superset
pycparser==2.20
# via cffi
pyjwt==2.4.0
# via
# apache-superset
# flask-appbuilder
# flask-jwt-extended
pymeeus==0.5.11
# via convertdate
pyparsing==3.0.6
# via
# apache-superset
# packaging
pyrsistent==0.16.1
# via jsonschema
python-dateutil==2.8.2
# via
# alembic
# apache-superset
# croniter
# flask-appbuilder
# holidays
# pandas
python-dotenv==0.19.0
# via apache-superset
python-editor==1.0.4
# via alembic
python-geohash==0.8.5
# via apache-superset
pytz==2021.3
# via
# babel
# celery
# convertdate
# flask-babel
# pandas
pyyaml==5.4.1
# via
# apache-superset
# apispec
redis==3.5.3
# via apache-superset
selenium==3.141.0
# via apache-superset
simplejson==3.17.3
# via apache-superset
six==1.16.0
# via
# bleach
# click-repl
# flask-talisman
# holidays
# isodate
# jsonschema
# polyline
# prison
# pyrsistent
# python-dateutil
# sqlalchemy-utils
# wtforms-json
slackclient==2.5.0
# via apache-superset
sqlalchemy==1.3.24
# via
# alembic
# apache-superset
# flask-appbuilder
# flask-sqlalchemy
# marshmallow-sqlalchemy
# sqlalchemy-utils
sqlalchemy-utils==0.37.8
# via
# apache-superset
# flask-appbuilder
sqlparse==0.3.0
# via apache-superset
tabulate==0.8.9
# via apache-superset
typing-extensions==3.10.0.0
# via apache-superset
urllib3==1.26.6
# via selenium
vine==5.0.0
# via
# amqp
# celery
# kombu
wcwidth==0.2.5
# via prompt-toolkit
webencodings==0.5.1
# via bleach
werkzeug==2.0.3
# via
# flask
# flask-jwt-extended
wtforms==2.3.3
# via
# flask-appbuilder
# flask-wtf
# wtforms-json
wtforms-json==0.3.3
# via apache-superset
yarl==1.6.3
# via aiohttp
# The following packages are considered to be unsafe in a requirements file:
# setuptools
查看文件
(superset) [zhangxi@hadoop102 ~]$ ll ~
总用量 12
-rw-r--r--. 1 zhangxi zhangxi 5795 2月 3 15:27 base.txt
drwxrwxr-x. 2 zhangxi zhangxi 4096 2月 6 11:42 bin
该文件可用于指定superset依赖组件及版本,下载地址及内容如下。
https://raw.githubusercontent.com/apache/superset/2.0.0/requirements/base.txt
在base.txt所在目录下执行如下命令,安装SuperSet
(superset) [zhangxi@hadoop102 ~]$ pip install apache-superset==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple -r base.txt
说明:
-
-i的作用是指定镜像,这里选择国内镜像
-
-r的作用是指定superset依赖组件及相应版本,指向base.txt文件即可
配置Superset元数据库
Superset的元数据支持MySQL、PostgreSQL,此处采用MySQL。
1)在MySQL中创建superset元数据库
mysql> CREATE DATABASE superset DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
2)创建superset用户
mysql> create user superset@'%' identified WITH mysql_native_password BY 'superset';
mysql> grant all privileges on *.* to superset@'%' with grant option;
mysql> flush privileges;
3)修改superset配置文件
(superset) [zhangxi@hadoop102 ~]$ vim /opt/module/miniconda3/envs/superset/lib/python3.8/site-packages/superset/config.py
修改内容如下:(184、185行)
# SQLALCHEMY_DATABASE_URI = "sqlite:///" + os.path.join(DATA_DIR, "superset.db")
SQLALCHEMY_DATABASE_URI = 'mysql://superset:superset@hadoop102:3306/superset?charset=utf8'
4)安装python msyql驱动
(superset) [zhangxi@hadoop102 ~]$ conda install mysqlclient
5)初始化superset元数据
(superset) [zhangxi@hadoop102 ~]$ export FLASK_APP=superset
(superset) [zhangxi@hadoop102 ~]$ superset db upgrade
SupersetSet初始化
1)创建管理员用户
(superset) [zhangxi@hadoop102 ~]$ superset fab create-admin
2)初始化superset
(superset) [zhangxi@hadoop102 ~]$ superset init
启动Supterset
1)安装gunicorn
(superset) [zhangxi@hadoop102 ~]$ pip install gunicorn -i https://pypi.douban.com/simple/
说明:gunicorn是一个Python Web Server,可以和java中的Tomcat类比
2)启动Superset
确保当前conda环境为superset,及下图所示
启动
(superset) [zhangxi@hadoop102 ~]$ gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 "superset.app:create_app()" --daemon
说明:
- --workers:指定进程个数
- --timeout:worker进程超时时间,超时会自动重启
- --bind:绑定本机地址,即为Superset访问地址
- --daemon:后台运行
登录Superset
访问http://hadoop102:8787
3)停止superset
(1)停掉gunicorn进程
(superset) [zhangxi@hadoop102 ~]$ ps -ef | awk '/superset/ && !/awk/{print $2}' | xargs kill -9
(2)退出superset环境
(superset) [zhangxi@hadoop102 ~]$ conda deactivate
superset启停脚本
1)创建superset.sh文件
[zhangxi@hadoop102 bin]$ vim superset.sh
内容如下
#!/bin/bash
superset_status(){
result=`ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | wc -l`
if [[ $result -eq 0 ]]; then
return 0
else
return 1
fi
}
superset_start(){
source ~/.bashrc
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
conda activate superset ; gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 --daemon 'superset.app:create_app()'
else
echo "superset正在运行"
fi
}
superset_stop(){
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
fi
}
case $1 in
start )
echo "启动Superset"
superset_start
;;
stop )
echo "停止Superset"
superset_stop
;;
restart )
echo "重启Superset"
superset_stop
superset_start
;;
status )
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
echo "superset正在运行"
fi
esac
2)加执行权限
[zhangxi@hadoop102 bin]$ chmod +x superset.sh
3)测试
启动superset
[zhangxi@hadoop102 bin]$ superset.sh start
停止superset
[zhangxi@hadoop102 bin]$ superset.sh stop
关于Apache Superset的使用后续讲解





![[C/C++]排序算法 快速排序 (递归与非递归)](https://img-blog.csdnimg.cn/direct/5c52cdda0ab24fad9918cf051f1adb32.png)