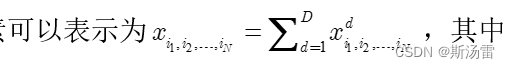摘要
文章涉及了两个时间序列的任务:forecasting,imputation.
对于预测任务:通过将时间序列编码为一系列数字,可以将时间序列预测任务转化为文本里面的next-token预测任务。在大规模预训练语言模型的基础上,文章提出了一些方法用于有效编码时间序列数据,并将离散分布的编码转换成灵活的连续分布(分布转换部分涉及到诸多统计学知识)。
在数值补全任务中,文章展示了语言模型(LLMs)如何通过非数值文本自然处理缺失数据,无需插补,如何适应文本侧面信息,并回答问题以帮助解释预测。
方法
文章提出了LLMTime模型

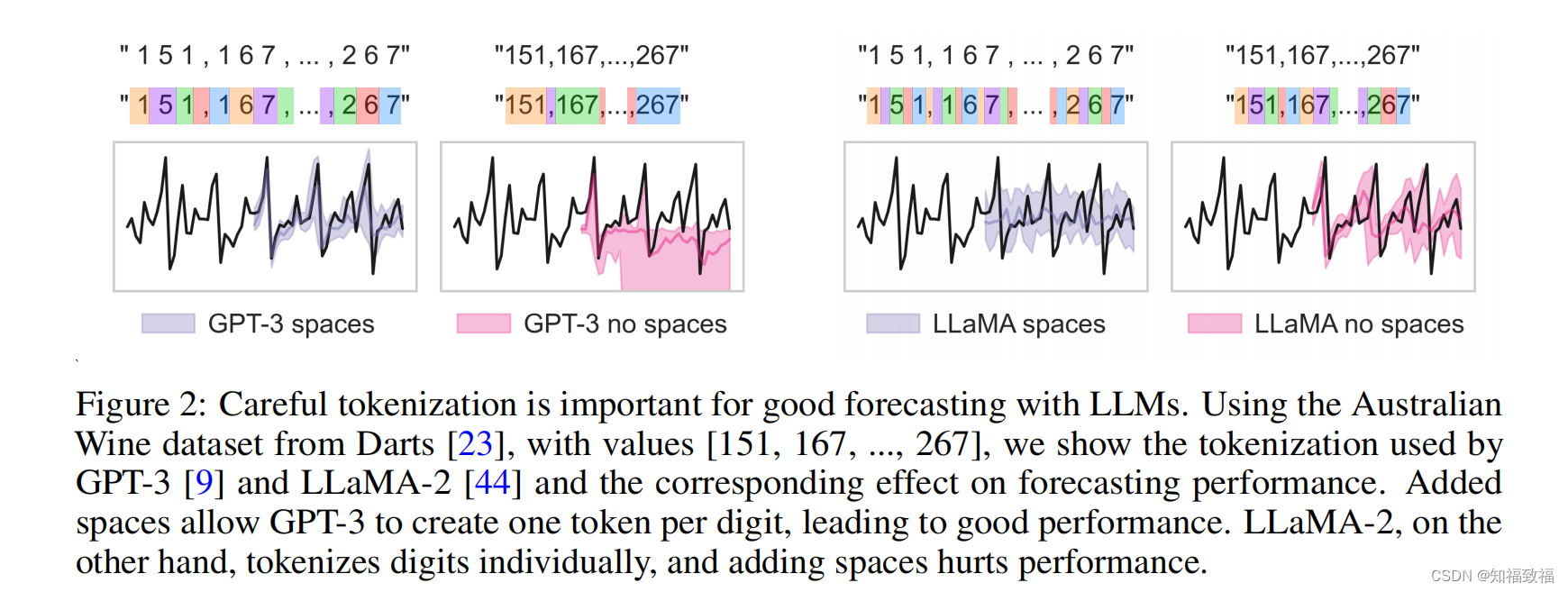
https://unit8co.github.io/darts/generated_api/darts.datasets.html
源码
需要用到openai 密钥,所以没有完全跑通openai.api_key = os.environ[‘OPENAI_API_KEY’]
1.利用darts加载数据集(需要挂梯子)
train:val:test=3:1:1
还有其他的一些数据集:
2.模型预测,llm完全不需要训练,直接将时间序列输入llm进行预测
感觉完全不需要重新训练和微调就有点离谱
serialize:处理输入数据
(1)scaler 放缩
(2)数字到字符串映射
vec_num2repr(val, base, prec, max_val)#将数字转化为指定进制和精度的表示
def vec_num2repr(val, base, prec, max_val):
"""
将数字转换为指定进制和精度的表示
Convert numbers to a representation in a specified base with precision.
Parameters:
- val (np.array): The numbers to represent.
- base (int): The base of the representation.
- prec (int): The precision after the 'decimal' point in the base representation.
- max_val (float): The maximum absolute value of the number.
Returns:
- tuple: Sign and digits in the specified base representation.
Examples:
With base=10, prec=2:
0.5 -> 50
3.52 -> 352
12.5 -> 1250
"""
base = float(base)
bs = val.shape[0]
sign = 1 * (val >= 0) - 1 * (val < 0)#if val[i]>0,sign[i]=1 else sign[i]=-1
val = np.abs(val)
max_bit_pos = int(np.ceil(np.log(max_val) / np.log(base)).item()) #计算最大位数
#使用循环迭代计算整数部分的每一位数字,存储在before_decimals中。每次迭代将相应的位数从val中减去。
before_decimals = []
for i in range(max_bit_pos):
digit = (val / base**(max_bit_pos - i - 1)).astype(int)
before_decimals.append(digit)
val -= digit * base**(max_bit_pos - i - 1)
before_decimals = np.stack(before_decimals, axis=-1)
if prec > 0:
after_decimals = []
for i in range(prec):
digit = (val / base**(-i - 1)).astype(int)
after_decimals.append(digit)
val -= digit * base**(-i - 1)
after_decimals = np.stack(after_decimals, axis=-1)
digits = np.concatenate([before_decimals, after_decimals], axis=-1)
else:
digits = before_decimals
#包含符号和数字的元组,其中符号是一个数组(sign),数字是一个二维数组(digits),表示了数字在指定进制下的表示。
return sign, digits
(3)添加分隔符:
def tokenize(arr):
return ‘’.join([settings.bit_sep+str(b) for b in arr])
(4)长度对齐
truncate_input(input_arr, input_str, settings, model, steps)
#截断输入以适应给定模型的最大上下文长度
预测:将序列输入到GPT模型
模型:可以看到处理过的输入input_str和提前预设好的chatgpt_sys_messsage信息、extra_input 信息拼接成为发送给GPT的messages。
model
if model in ['gpt-3.5-turbo','gpt-4']:
chatgpt_sys_message = "You are a helpful assistant that performs time series predictions. The user will provide a sequence and you will predict the remaining sequence. The sequence is represented by decimal strings separated by commas."
extra_input = "Please continue the following sequence without producing any additional text. Do not say anything like 'the next terms in the sequence are', just return the numbers. Sequence:\n"
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": chatgpt_sys_message},
{"role": "user", "content": extra_input+input_str+settings.time_sep}
],
max_tokens=int(avg_tokens_per_step*steps),
temperature=temp,
logit_bias=logit_bias,
n=num_samples,
)
return [choice.message.content for choice in response.choices]
对于GPT返回的Response
deserialize:处理GPT返回的信息
pred = handle_prediction(deserialize_str(completion, settings, ignore_last=False, steps=steps), expected_length=steps, strict=strict_handling)
从上面代码看出,先是deserialize
def deserialize_str(bit_str, settings: SerializerSettings, ignore_last=False, steps=None):
"""
Deserialize a string into an array of numbers (a time series) based on the provided settings.
Parameters:
- bit_str (str): String representation of an array of numbers.
- settings (SerializerSettings): Settings for deserialization.
- ignore_last (bool): If True, ignores the last time step in the string (which may be incomplete due to token limit etc.). Default is False.
- steps (int, optional): Number of steps or entries to deserialize.
Returns:
- None if deserialization failed for the very first number, otherwise
- np.array: Array of numbers corresponding to the string.
"""
# ignore_last is for ignoring the last time step in the prediction, which is often a partially generated due to token limit
orig_bitstring = bit_str
bit_strs = bit_str.split(settings.time_sep)
# remove empty strings
bit_strs = [a for a in bit_strs if len(a) > 0]
if ignore_last:
bit_strs = bit_strs[:-1]
if steps is not None:
bit_strs = bit_strs[:steps]
vrepr2num = partial(vec_repr2num,base=settings.base,prec=settings.prec,half_bin_correction=settings.half_bin_correction)
max_bit_pos = int(np.ceil(np.log(settings.max_val)/np.log(settings.base)).item())
sign_arr = []
digits_arr = []
try:
for i, bit_str in enumerate(bit_strs):
if bit_str.startswith(settings.minus_sign):
sign = -1
elif bit_str.startswith(settings.plus_sign):
sign = 1
else:
assert settings.signed == False, f"signed bit_str must start with {settings.minus_sign} or {settings.plus_sign}"
bit_str = bit_str[len(settings.plus_sign):] if sign==1 else bit_str[len(settings.minus_sign):]
if settings.bit_sep=='':
bits = [b for b in bit_str.lstrip()]
else:
bits = [b[:1] for b in bit_str.lstrip().split(settings.bit_sep)]
if settings.fixed_length:
assert len(bits) == max_bit_pos+settings.prec, f"fixed length bit_str must have {max_bit_pos+settings.prec} bits, but has {len(bits)}: '{bit_str}'"
digits = []
for b in bits:
if b==settings.decimal_point:
continue
# check if is a digit
if b.isdigit():
digits.append(int(b))
else:
break
#digits = [int(b) for b in bits]
sign_arr.append(sign)
digits_arr.append(digits)
except Exception as e:
print(f"Error deserializing {settings.time_sep.join(bit_strs[i-2:i+5])}{settings.time_sep}\n\t{e}")
print(f'Got {orig_bitstring}')
print(f"Bitstr {bit_str}, separator {settings.bit_sep}")
# At this point, we have already deserialized some of the bit_strs, so we return those below
if digits_arr:
# add leading zeros to get to equal lengths
max_len = max([len(d) for d in digits_arr])
for i in range(len(digits_arr)):
digits_arr[i] = [0]*(max_len-len(digits_arr[i])) + digits_arr[i]
return vrepr2num(np.array(sign_arr), np.array(digits_arr))
else:
# errored at first step
return None
计算损失函数
# Compute NLL/D on the true test series conditioned on the (truncated) input series
if nll_fn is not None:
BPDs = [nll_fn(input_arr=input_arrs[i], target_arr=test[i].values, settings=settings, transform=scalers[i].transform, count_seps=True, temp=temp) for i in range(len(train))]
out_dict['NLL/D'] = np.mean(BPDs)


![[C/C++]排序算法 快速排序 (递归与非递归)](https://img-blog.csdnimg.cn/direct/5c52cdda0ab24fad9918cf051f1adb32.png)