在Linux机器上对模型进行微调前,首先需要准备环境,即安装相关的软件。因为linux是一个无界面操作系统,软件安装完成后,还需要有便捷的交互方式编写脚本,调试脚本。此篇博客将专门介绍如何快速安装所需依赖软件,以及如何用jupyter notebook进行便捷的交互式编程。
申请设备
此篇博客申请的设备是AWS上的g5系列,如果你使用的是其他云厂商服务,选择带GPU的instance即可。博客里面选用的操作系统是Ubuntu22版本,属于Debian系列,架构是x86-64的架构。在申请设备的时候,为了方便从外面通过ssh连接instance,enable了public IP的分配。对模型微调需要很多磁盘空间存储下载的模型参数文件,所以,在申请instance的时候尽量将磁盘空间设置大一些,我自己设置的是256G。如果不清楚使用的instance的架构,可通过下面的命令查看,另外,还可以通过命令查看ubuntu的版本信息。
#查看架构
dpkg --print-architecture
#查看ubuntu版本信息
lsb_release -aaws上申请好instance后,需要提前安装好gcc,安装命令:
sudo apt-get update && apt-get install gcc
检查gcc是否安装成功的命令: gcc -version
安装NVIDIA驱动
安装cuda driver的命令如下所示,非常简单。
#安装包管理,即生成相应的key,以后在安装Nvidia的相关包时,会进行安全相关的检查,保证安装的包是受到官网认证的包
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
#安装cuda-driver
sudo apt-get update
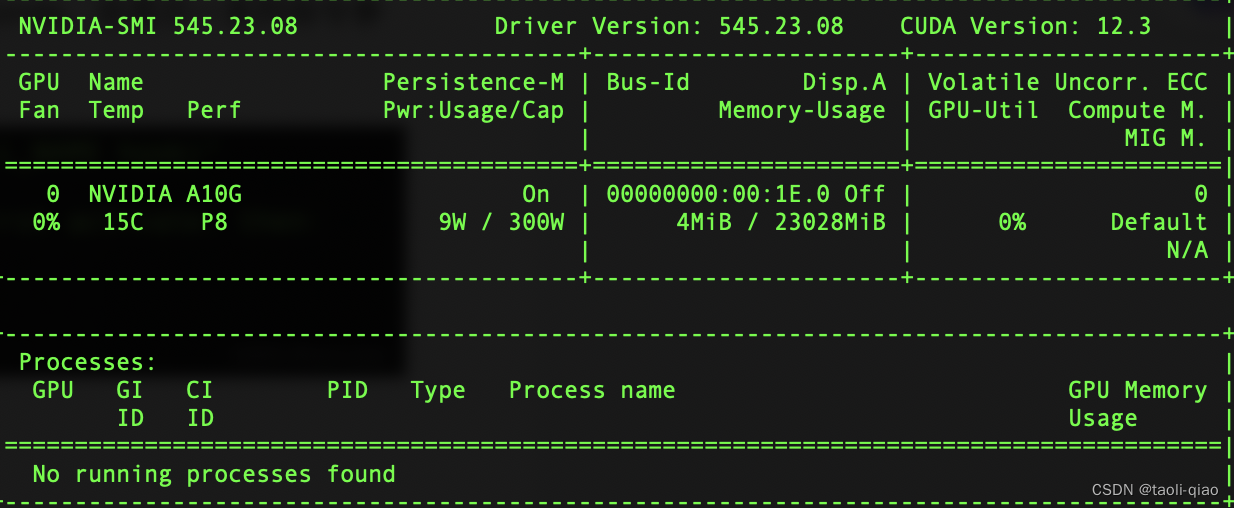
sudo apt-get -y install cuda-drivers执行命令后,用 nvidia-smi 命令进行检查,通过命令可以看到GPU相关信息,包括版本,显存大小等,具体如下图所示:
安装conda
在进行模型微调或者微调评估时,除了用到常用的pytorch包外,还可能用到NumPy,Pandas等包,所以,这里选择安装Anaconda,而不是Miniconda。安装脚本如下所示:
#安装其他的一些依赖包
apt-get install libgl1-mesa-glx libegl1-mesa libxrandr2 libxrandr2 libxss1 libxcursor1 libxcomposite1 libasound2 libxi6 libxtst6
#下载安装脚本
curl -O https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
#执行安装脚本,需要长按enter键review完协议,并输入yes,同意协议才会开始正式安装Anaconda
bash Path/Anaconda3-2020.05-Linux-x86_64.sh
#安装完成后,激活
source <PATH_TO_CONDA>/bin/activate
conda init
安装结果如下图所示,可以看到,安装成功,此时在terminal里面输入conda,会显示一系列命令参数,说明正确安装了conda。

安装cuda toolkit
安装cuda toolkit的方法有很多,这里因为已经安装好了conda,所以通过conda命令来安装cuda toolkit。
安装命令:conda install cuda -c nvidia
卸载命令:conda remove cuda
在conda的激活环境中,查看python,pip,可以看到,都已经默认安装好了。另外,还可以通过pip list命令查看安装的所有python包,具体如下图所示:

如果要查看某个具体的包是否被安装,可以通过pip show命令。如下图所示,可以看到transformers库已经被默认安装上去了,pytorch库还没有安装。

如果不通过conda安装cuda,还可以从官网获取安装命令进行安装,具体如下图所示。选择自己使用的instance的操作系统类型,架构,系统版本等信息就可以得到最标准的安装命令。

安装pytorch等其他库
通过conda 安装pytorch的命令: conda install pytorch torchvision -c pytorch。当然,除了安装pytorch,还可以通过conda命令安装任意其他的包,安装命令:conda install package_name。
另外,也可以通过命令批量安装requirements.txt文件中的所有依赖。
安装命令:conda install --file requirements.txt
conda默认是从default的channel上安装包,但是default channel上的包可能不全,所以,建议使用conda-forge作为下载包的渠道。不同渠道下载的包,可能会有兼容性问题。如果遇到兼容性问题,建议在激活环境后,通过下面的命令进行全量包更新。相关命令如下所示:
#添加conda-forge channel并设置为最高优先级
conda config --add channels conda-forge
#查看现在的channel状态和优先级
conda config --get channels
#更新包命令
conda update --all
在安装pytorch的时候,需要注意一点,pytorch和cuda之间是有版本映射关系的,如果版本映射关系不正确,后面运行程序可能会出错。最标准的安装办法是:在官网输入相关信息,得到安装命令进行安装。具体如下图所示,选择要安装的pytorch版本,os,package,cuda版本,即可得到正确的安装命令。

Pytorch安装成功,可以运行脚本查看安装的Pytorch是否支持GPU。

创建交互式编程方式
activate后,在激活的环境下,执行jupyter notebook命令,执行该命令后,会默认生成下面的连接,端口是8888。如下图所示:

为了能在外面电脑的浏览器上打开notebook,需要在instance的security group的inbound规则中开放8888端口。另外,执行下面的命令,这段命令是用于建立SSH隧道(SSH tunnel),通过加密的方式在本地计算机和远程服务器之间建立连接。这通常用于远程访问远程服务器上运行的服务,比如Jupyter Notebook,通过浏览器访问本地计算机上的服务。其中pem文件是申请instance时创建的权限文件。
ssh -i /Users/taoli/Downloads/taoli-tokyo.pem -N -f -L 8888:localhost:8888 ubuntu@instance public ip-L 8888:localhost:8888: 在本地端口8888上创建一个本地端口转发。这意味着本地计算机的端口8888将被转发到远程服务器的localhost:8888。
执行上面的命令后,就可以在外面的电脑浏览器上输入上图生成的连接,创建python脚本或者jupyter脚本,开始交互式编程和调试了。具体如下图所示:
以上就是对进行模型微调前环境准备的专门介绍。