目录
一、树的基本概念
二、二叉树
2.1二叉树的性质
2.2二叉树的存储结构
2.3遍历二叉树
先序遍历
中序遍历
后序遍历
层次遍历
2.4二叉树的应用
计算叶子数
前序遍历建树
根据序列恢复二叉树
计算树的深度
判断完全二叉树
三、线索二叉树
3.1线索化
四、树和森林
4.1树转为二叉树
4.2二叉树还原为树
4.3森林变为二叉树
4.4树的遍历
五、哈夫曼树
编程重点为2.4二叉树应用、3线索二叉树
一、树的基本概念
定义:由一个或多个结点(n≥0)组成的有限集合T,有且仅有一个结点称为根(root),当n>1时,其余的结点分为m(m≥0)个互不相交的有限集合T1,T2,…,Tm。每个集合本身又是棵树,被称作这个根的子树 。
特点:非线性结构,一个直接前驱可以有多个直接后继 (1:n)
术语:
根——根节点,没有前驱
叶子——叶节点,没有后继
森林——m棵不相交的树的集合
有序树——节点的各子树有序,不能互换
无序树——节点各子树可互换位置
双亲——直接前驱
孩子——直接后继
兄弟——同一双亲下的同层节点
节点的度——节点的子树数
节点的层次——从根到该节点的层数,根节点为第一层
终端节点——度为0的节点,即叶节点
分支节点——度不为0的节点,也叫内部节点
树的度——所有节点度的最大值
树的深度——所有节点最大的层次

存储方式:链式存储
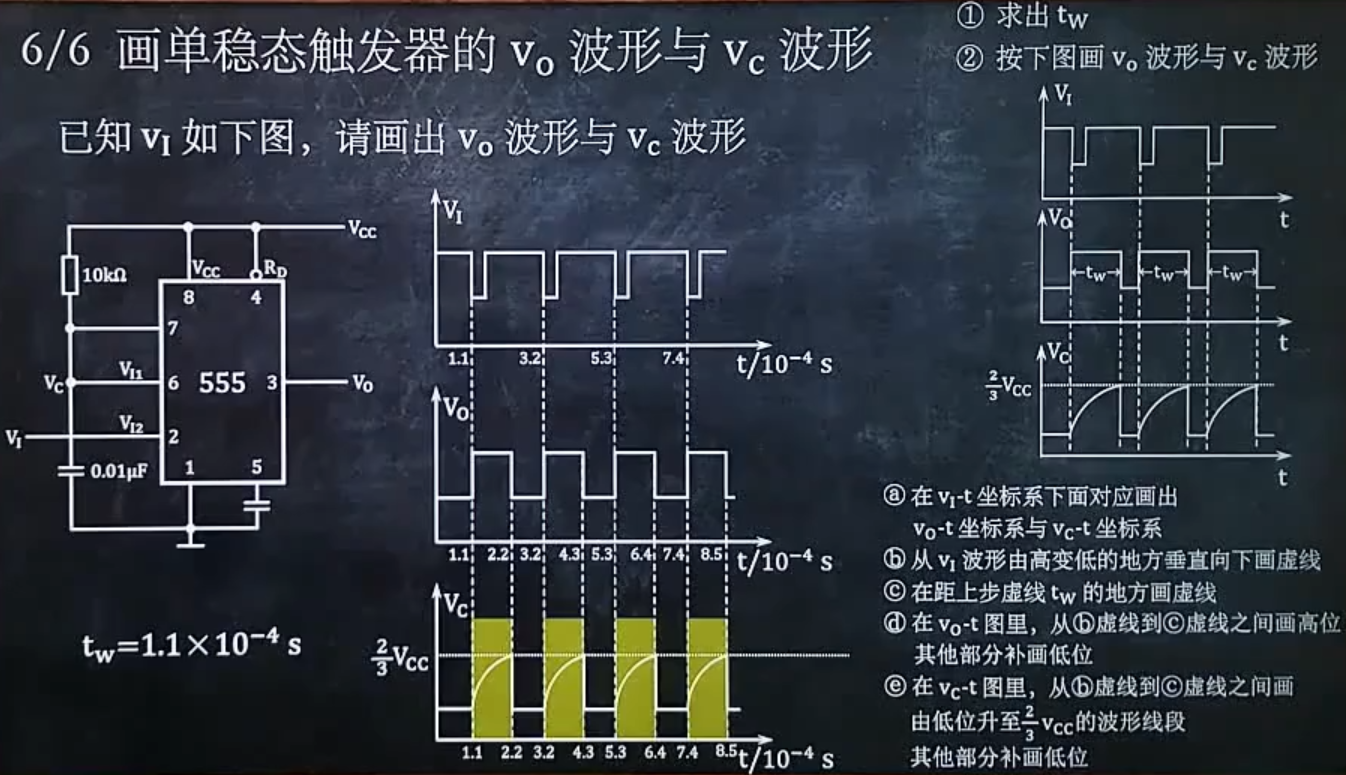
二叉树的结构最简单,规律性最强。而且所有数都能用左孩子右兄弟表示法转为唯一的二叉树
左孩子右兄弟表示法:将每个节点的最左孩子节点保留,其它孩子节点变为左孩子的右孩子
二、二叉树
定义:由一个根节点和它的左子树、右子树组成
特点:(1:2) 每个节点最多两棵子树,左右子树不能颠倒
2.1二叉树的性质
性质1.二叉树第i层上至多有个节点,至少有一个节点
性质2.深度为k的二叉树,最多有个节点,最少k个节点
性质3.叶子数=2度节点数+1 对任意二叉树成立

特殊二叉树:
满二叉树:深度为k,节点数为,即每层都填满了节点
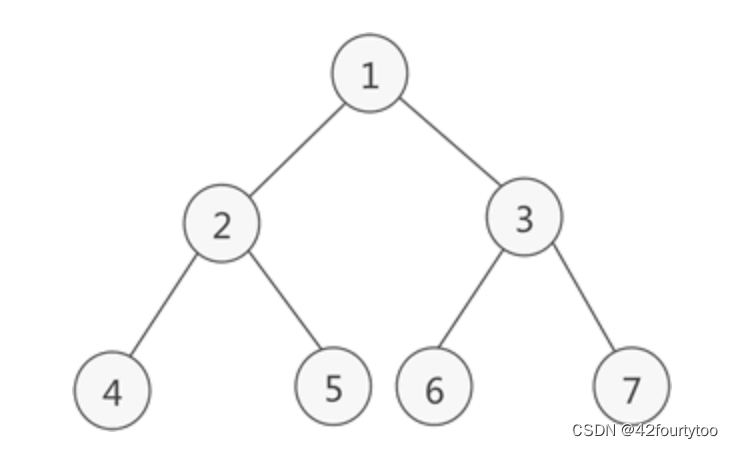
完全二叉树:只有最后一层叶子不满,并且叶子都在左侧依次排列。满二叉树是完全二叉树的特例

性质4:具有n个节点的完全二叉树的深度为
性质5:完全二叉树节点数为n,叶子数为
n0=n2-1,n1=1或0
性质6:对完全二叉树,若从上到下,从左到右编号,则编号为i的节点,左孩子编号为2i,右孩子编号为2i+1,双亲结点编号为i/2取整
练习:
在下述结论中,正确的是( )
①只有一个结点的二叉树的度为0;
②二叉树的度为2;
③二叉树的左右子树可任意交换;
④深度为K的完全二叉树的结点个数小于或等于深度相同的满二叉树。A.123
B.234
C.24
D.14
答案:D 二叉树的度小于等于2
一棵完全二叉树有1000个结点,则它必有( )个叶子结点,有( )个度为2的结点,有 ( )个结点只有非空左子树,有( )个结点只有非空右子树。
答案:500 499 1 0
由性质5求叶子数,由性质3求分支节点数。节点总数为奇数,没有n1;偶数有一个n1
设树T的度为4,其中度为1,2,3和4的结点个数分别为4,2,1,1 则T中的叶子数为( )
答案:8
设节点总数为n,n等于各种度的节点数之和,n=n0+n1+n2+n3+n4=n0+4+2+1+1
n还等于度之和加1(加上根节点)n=1*4+2*2+3*1+4*1 联立
若一棵二叉树具有10个度为2的结点,5个度为1的结点,则度为0的结点个数是( )
答案:11 性质3对任意二叉树成立
(易错)已知一棵完全二叉树的第6层(设根为第1层)有8个叶结点,则完全二叉树的结点个数最多是( )
答案:111 第六层有叶节点,但它不是最后一层。第六层的叶节点都分布在右侧。第六层为24+8,第七层为24*2,总数为2^6-1+48=111
2.2二叉树的存储结构
1.顺序存储
只有完全/满二叉树能唯一复原。下标为i的双亲,左孩子为2i,右孩子为2i+1
不是完全二叉树,把空缺处补上空节点
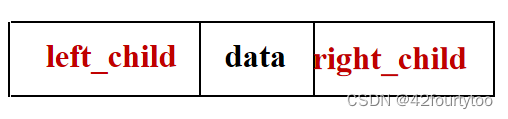
2.链式存储
2.3遍历二叉树
包括前中后序、层次遍历四种方法。每种方法包括递归和非递归两种代码。
先序遍历
按照 根-左子树-右子树 的顺序遍历
手动遍历技巧:在节点左侧画一个点,从根节点把点连起来
//前序遍历,递归
void preorder(pnode root) //根节点->左节点->右节点
{
if (root == NULL) return;
printf("%d ", root->data);
preorder(root->lchild); //访问左子树
preorder(root->rchild); //访问右子树
}
//前序遍历,非递归
void preorder2(pnode root)
{
printf("非递归前序遍历:");
int top = 0;
pnode stack[20];
while (top || root) //栈和指针都空时才退出
{
if (root) //输出根,找左节点,回退,找右节点
{
printf("%d ",root->data);
stack[top++] = root;
root = root->lchild;
}
else
{
root = stack[--top];
root = root->rchild;
}
}
printf("\n");
}
中序遍历
左-根-右
手动遍历技巧:把所有节点向下平移到一条线上,得到中序序列
void midorder(pnode root) { //左节点->根节点->右节点
if (root == NULL) return;
midorder(root->lchild); //访问左子树
printf("%d ", root->data);
midorder(root->rchild); //访问右子树
}
//中序遍历,非递归
void midorder2(pnode root)
{
printf("非递归中序遍历:");
int top = 0; //栈顶
pnode stack[20]; //用数组实现栈
while (top || root) //当栈和指针有一个不空时
{
while(root!=NULL) //指针不空
{
stack[top++] = root; //压栈
root = root->lchild; //找左孩子
}
if(top!=0)
{
root = stack[--top]; //此时左孩子已找完,取栈顶节点输出
printf("%d ", root->data);
root = root->rchild; //找右孩子
}
}
printf("\n");
}
后序遍历
左-右-根
手动遍历技巧:在节点右侧画一个点,从根节点把点连起来
后序遍历最复杂,因为左节点到右节点要借助根节点,所以根节点要遍历两次,第二次指向根节点的时候才输出
//后序遍历,递归
void postorder(pnode root) { //左节点->右节点->根节点
if (root == NULL) return;
postorder(root->lchild); //访问左子树
postorder(root->rchild); //访问右子树
printf("%d ", root->data);
}
//后序遍历,非递归,法一
//按照左-右-根来输出。先一直找左,找不到的时候回退一格,此时指向最左。
//如果有右节点,说明它为根,不输出,往右走。如果无右节点,说明为叶节点,输出,并标记。
void postorder2(pnode root)
{
printf("非递归后序遍历:");
int head = 0;
pnode stack[20];
pnode current = root, visited = root; //分别指向当前节点和上一个访问的节点
while (head || current) //栈和当前指针有一个不空
{
while (current) //一直找左子树
{
stack[head++] = current;
current = current->lchild;
}
current = stack[head-1]; //左子树找完,取栈顶
if (current->rchild && current->rchild != visited) //如果有右子树且未被访问,则访问
{
current = current->rchild;
}
else
{
visited = current;
printf("%d ", current->data); //输出数据,将该节点设为visited,同时current置空
current = NULL;
head--;
}
}
printf("\n");
}
//后序遍历,非递归,法二
//在后序遍历过程中,结点要入两次栈,出两次栈,而访问结点是在第二次出栈时访问。
//为了区别同一个结点指针的两次出栈,设置一标志flag,flag=1时为第一次出栈,flag=2时为第二次出栈,可以输出
//设置栈类型同时记录节点指针和flag
typedef struct {
pnode link;
int flag;
}stacktype;
void postorder(pnode T)
/*非递归后序遍历二叉树T*/
{
stacktype stack[20];
pnode p = T;
int top = 0, sign;
if (T == NULL) return;
while (!(p == NULL && top == 0))
{
while (p != NULL)
/*结点第一次进栈*/
{
stack[top].link = p;
stack[top].flag = 1;
top++;
p = p->lchild;
/*找该结点的左孩子*/
}
if (top > 0)
//p为空,弹出堆栈
{
top--;
p = stack[top].link;
sign = stack[top].flag;
if (sign == 1) //右子树未访问
/*结点第二次进栈,准备访问右子树*/
{
stack[top].link = p;
stack[top].flag = 2;
top++;
/*标记第二次入栈*/
p = p->rchild;
}
else //sign为2表示右子树访问完毕,可访问根
{
printf("%d", p->data);
/*访问该结点数据域值*/
p = NULL; //置空,防止重复入栈
}
}
}
}总结:
前面的三种遍历算法如果将print语句抹去,从递归的角度看,这三种算法是完全相同的,或者说这三种遍历算法的访问路径是相同的,只是访问结点的时机不同。
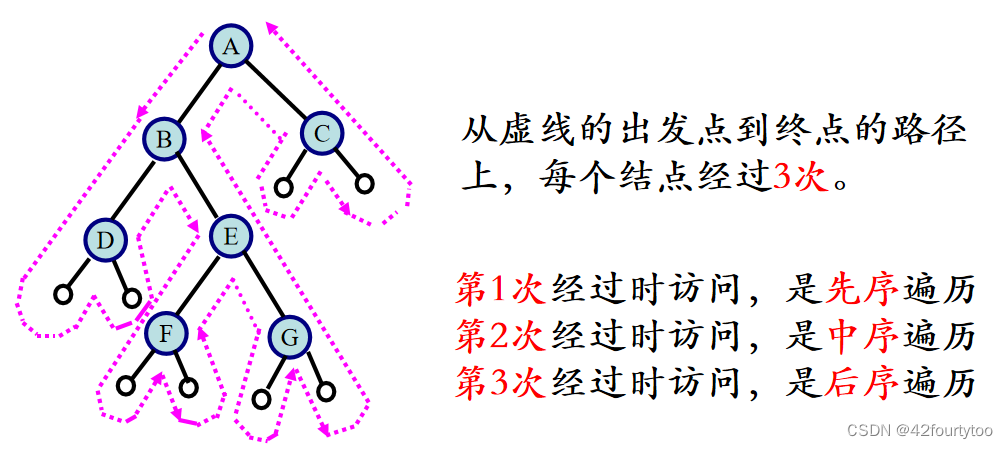
时间效率:O(n) 每个结点只访问一次
空间效率:O(n) 栈占用的最大辅助空间

层次遍历
从上到下,从左到右输出节点
void levelorder(pnode root) //层序遍历,用数组实现队列 按照每一层进行遍历 父节点出队时,其左右节点入队,从而实现从上到下从左到右的出队
{
int head = 0, tail = 0;
pnode queue[20]; //指针数组
pnode p;
queue[tail++] = root; //根节点入队
while (head < tail) //当队空时遍历完成
{
p = queue[head++]; //出队并输出值
printf("%d ", p->data);
if (p->lchild) //将该节点左右节点入队
queue[tail++] = p->lchild;
if (p->rchild)
queue[tail++] = p->rchild;
}
}2.4二叉树的应用
计算叶子数
前序遍历,无孩子的为叶子
void leavenum(pnode root)
{
static int sum = 0;
if (!root) return;
if (!root->lchild && !root->rchild)
{
sum++;
printf("叶子:%d,叶子数:%d\n", root->data, sum);
}
leavenum(root->lchild);
leavenum(root->rchild);
}前序遍历建树
将二叉树写成前序遍历的序列,NULL节点用空格代替,输入序列,将树存入计算机
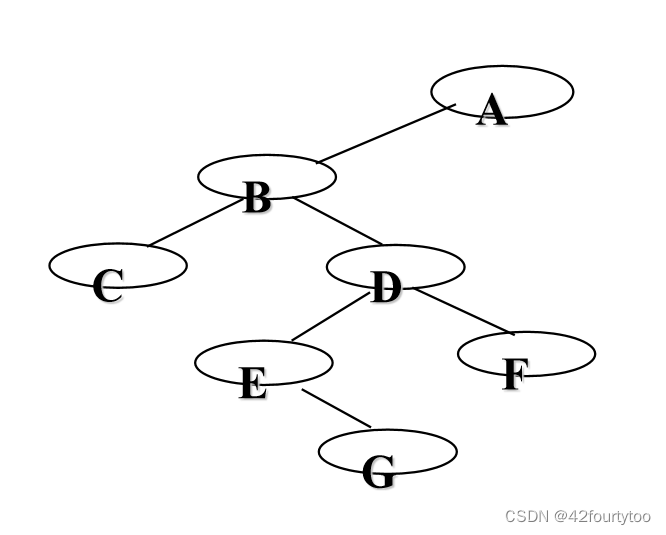
这棵树转成序列为:ABC--DE-G--F--- (-表示空格)
void createtree(pnode& root) //一定要引用,否则无法改变root的值
{
char elem = getchar(); //获取字符
if (elem == ' ') //空格则创建空节点
root = NULL;
else
{
if (!(root = (pnode)malloc(sizeof(pnode)))) //生成根节点
return;
root->data = elem; //赋值
createtree(root->lchild); //构造左子树
createtree(root->rchild); //构造右子树
}
}根据序列恢复二叉树
已知一棵二叉树的中序序列和后序序列分别是BDCEAFHG 和 DECBHGFA,请画出这棵二叉树。
解:①由后序遍历特征,根结点必在后序序列尾部(即A为根节点);
②由中序遍历特征,根结点必在其中间,而且其左边必全部是左子树(即BDCE为A左子树),其右边必全部是右子树(即FHG为A右子树);
③回到后序序列,BDCE中B在最后,所以B是这四个节点中的根,B为A的左孩子;同理F为A的右孩子;重复2,3
后序中找最后一个作为根--对应到中序,划分左右子树--左右子树对应到后序中找最后一个作为根......
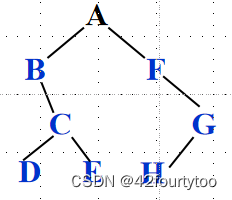
注:用前序和后序不能得到唯一的二叉树
已知一棵二叉树的前序遍历结果为ABCDEF,中序遍历结果为CBAEDF,则后序遍历的结果为
答案:CBEFDA
计算树的深度
递归:指针空返回0,否则返回左右子树求深度的最大值加一
非递归:层序遍历,走完一层深度加一
//采用递归和非递归算法求树的深度
#include<stdio.h>
#include<stdlib.h>
typedef struct node {
int data;
int left;
int right;
struct node* lchild;
struct node* rchild;
}node, * pnode;
pnode createnode(int value) {
pnode newnode = (pnode)malloc(sizeof(node));
if (!newnode) return NULL;
newnode->lchild = NULL;
newnode->rchild = NULL;
newnode->left = 0;
newnode->right = 0;
newnode->data = value;
return newnode;
}
void insert(pnode& root, int value) {
if (root == NULL) {
root = createnode(value);
return;
}
if (root->data > value)
insert(root->lchild, value);
else
insert(root->rchild, value);
}
int redeeptree(pnode root) //递归求深度:空则返回0,不空则返回左右子树深度最大值加一。递归时从上往下展开,返回时从下往上累加
{
return root == NULL ? 0 : (redeeptree(root->lchild) > redeeptree(root->rchild) ? redeeptree(root->lchild) : redeeptree(root->rchild)) + 1;
}
int nonredeeptree(pnode root) //非递归求二叉树深度。用层序遍历
{
pnode queue[20] = {};
int front = -1, tail = 0, level = 0, last = 0; //因为根节点就一个,可控,所以第一轮做初始化
queue[tail] = root; //根节点入队,tail指向最后入队元素
while (front < tail)
{
front++; //front指向出队的元素
if (queue[front]->lchild) queue[++tail] = queue[front]->lchild; //将出队元素左右节点入队
if (queue[front]->rchild) queue[++tail] = queue[front]->rchild;
if (front == last) { //last标记着该层最后一个节点。最后节点出队则层数加一,rear指向的更新为最后节点
level++;
last = tail;
}
}
return level;
}
int main() {
pnode tree = NULL;
insert(tree, 5);
insert(tree, 3);
insert(tree, 8);
insert(tree, 1);
insert(tree, 6);
insert(tree, 2);
insert(tree, 4);
insert(tree, 9);
printf("建立二叉树:5,3,8,1,6,2,4,9\n");
int level;
level = redeeptree(tree);
printf("递归算法,树的深度为%d\n", level);
level = nonredeeptree(tree);
printf("非递归算法,树的深度为%d", level);
}判断完全二叉树
层序遍历,全部元素入队列,如果空节点出现在数值序列中间则不是完全二叉树
//判断是否为完全二叉树
#include<stdio.h>
#include<stdlib.h>
typedef struct node {
int data;
struct node* lchild;
struct node* rchild;
}node, * pnode;
pnode createnode(int value) {
pnode p = (pnode)malloc(sizeof(node));
if (!p) return NULL;
p->data = value;
p->lchild = NULL;
p->rchild = NULL;
return p;
}
void insert(pnode& root, int value) {
if (!root) {
root = createnode(value);
return;
}
if (value < root->data)
insert(root->lchild, value);
if (value > root->data)
insert(root->rchild, value);
}
//法一
//int judge(pnode tree) {
//
// pnode queue[20] = {};
// int head = -1;
// int tail = 0;
//
// int notfull = 0; //为0,只有一个孩子的不饱和点还未出现
//
// queue[tail] = tree;
//
// while (head < tail && notfull == 0)
// {
// tree = queue[++head];
//
// if (tree->lchild)
// queue[++tail] = tree->lchild;
// else
// notfull = 1;
//
// if (tree->rchild)
// if (notfull == 1)
// return 0;
// else
// queue[++tail] = tree->rchild;
// else
// notfull = 1;
// }
//
// if (notfull == 1) {
// while (head < tail) {
// head++;
// if (queue[head]->lchild != NULL || queue[head]->rchild != NULL)
// return 0;
// }
// }
// return 1;
//}
//法二
int judge(pnode tree) {
pnode queue[20] = {};
int head = -1;
int tail = 0;
queue[tail] = tree;
while (head < tail)
{
tree = queue[++head];
if (!tree) //空节点跳过
continue;
queue[++tail] = tree->lchild; //非空节点左右都入队
queue[++tail] = tree->rchild;
}
int flag = 0; //未出现空节点
for (int i = 0; i <= tail; i++) { //如果空节点出现在非空节点之间则非完全二叉树
if (queue[i] == NULL)
flag = 1;
if (flag == 1 && queue[i])
return 0;
}
return 1;
}
int main() {
pnode tree = NULL;
insert(tree, 5);
insert(tree, 9);
insert(tree, 8);
insert(tree, 1);
insert(tree, 4);
insert(tree, 0);
printf("%s", judge(tree) == 1 ? "是" : "否");
}三、线索二叉树
用二叉链表存储n个节点的二叉树,有n+1个空指针
n个节点有2n个指针,n-1个指向节点,所以有n+1个空指针
我们可以用空指针存放当前结点的直接前驱和直接后继等线索,以加快查找速度
把节点增加两个标志域ltag,rtag

当标志为0时表示指向子节点的正常指针,为1时表示指向前驱或后继的线索指针
3.1线索化
线索化过程就是在遍历过程中修改空指针的过程: 将空的lchild改为结点的直接前驱; 将空的rchild改为结点的直接后继。
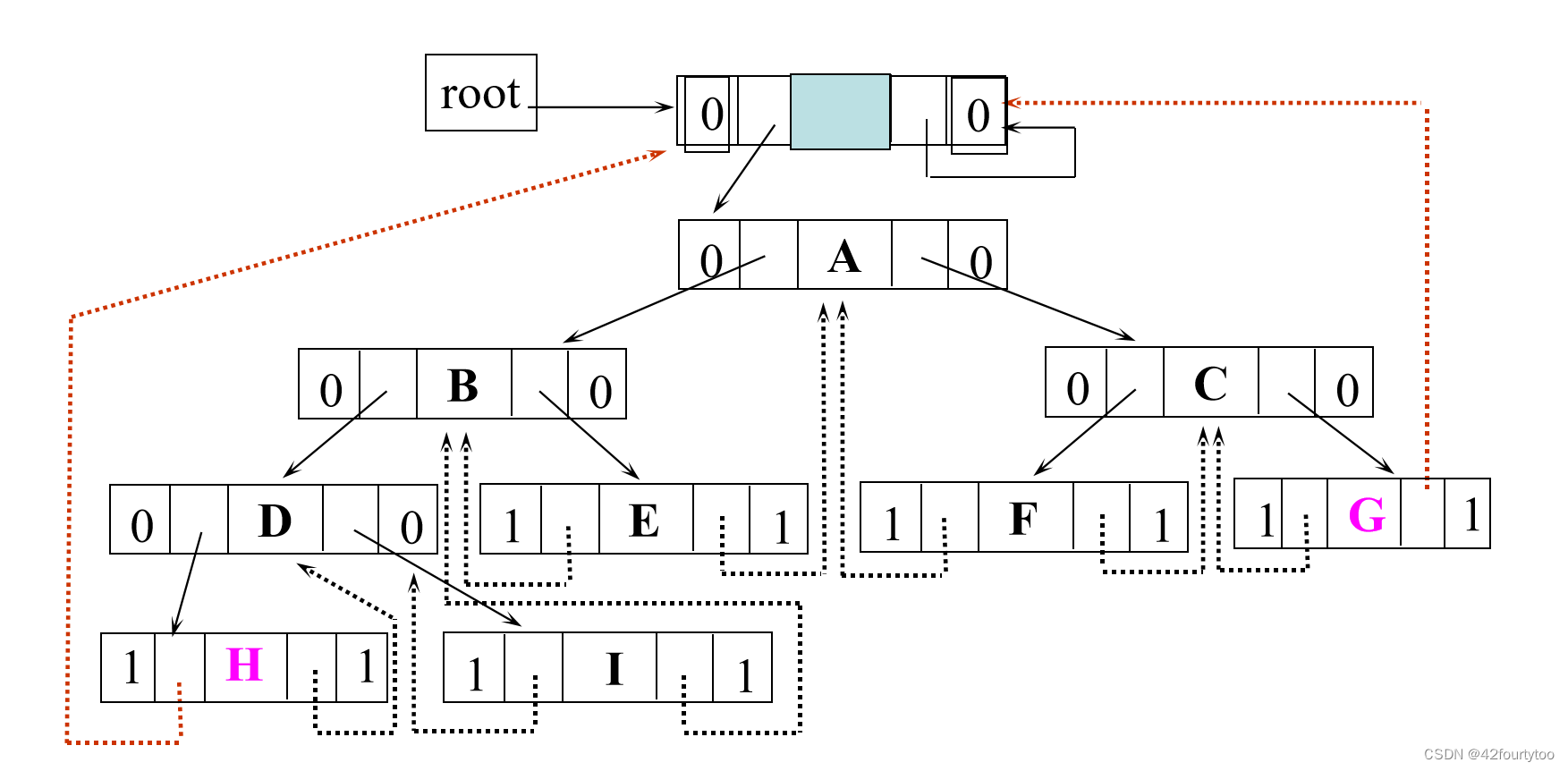
root是线索的根
非递归中序建立二叉树(代码不完整,仅参考思路)
线索有一个根节点,左右标志为0,右节点指向自己,左节点指向树的根节点;中序的始末节点线索都指向线索的根节点
//中序线索化二叉树的非递归算法
#include<stdio.h>
#include<stdlib.h>
#define MAXSIZE 50
typedef enum PointerTag { Link = 0, Thread = 1 };
typedef struct thrnode
{
int data;
struct thrnode* lchild, * rchild;
//左右孩子指针
PointerTag LTag, RTag;
}thrnode, * thrtree;
void InOrderThreading
(thrtree& Thrt, thrtree T)
/*中序遍历二叉树T,T为根节点,并将其线索化,Thrt 指向头结点*/
{
int top = 0;
thrtree p, pre, s[MAXSIZE];
if (!(Thrt = (thrtree)malloc(sizeof(thrnode))))
exit(0);
Thrt->LTag = Link;
Thrt->RTag = Link;
Thrt->rchild = Thrt;//右指针回指
//初始化头结点
if (!T)
Thrt->lchild = Thrt; //如果树空,头节点左指针也回指
else
{
Thrt->lchild = T;
pre = Thrt;
p = T;
while (p != NULL || top != 0) //p所指向树不空或栈不空
{
while (p != NULL)
{
s[top++] = p; //左子树所遇结点p进栈
p = p->lchild; //继续搜索p的左子树
}
if (top > 0)
{
p = s[--top]; //出栈,栈顶元素赋给p
if (pre->rchild == NULL)
{
pre->rchild = p;
pre->RTag = Thread;
}
if (p->lchild == NULL)
{
p->lchild = pre;
p->LTag = Thread;
}
pre = p;
p = p->rchild; //继续搜索p的右子树
}
}
pre->rchild = Thrt;
}
}递归中序线索化+遍历(完整)
//采用中序遍历实现线索二叉树,并对实现中序线索化的二叉树实现中序遍历
#include<stdio.h>
#include<stdlib.h>
typedef struct node {
int data;
int left;
int right;
struct node* lchild;
struct node* rchild;
}node, * pnode;
pnode pre = NULL; //设置全局变量pre
void inthread(pnode root) { //通过中序遍历对二叉树线索化的递归算法
if (root != NULL) {
inthread(root->lchild); //递归,线索化左子树
if (root->lchild == NULL) { //若root的左子树为空,把pre作为前驱线索
root->lchild = pre;
root->left = 1; //1表示线索指针
}
if (pre->rchild == NULL) { //若pre的右子树为空,把root作为后继
pre->rchild = root;
pre->right = 1;
}
pre = root; //标记当前结点成为刚刚访问过的结点
inthread(root->rchild); //递归,线索化右子树
}
}
void inordertraverse(pnode root) { //线索二叉树中序遍历
printf("线索二叉树中序遍历:");
pnode p = root;
while (p) { //p为空结束
while (p->left == 0) //1 找最左节点,输出
p = p->lchild;
printf("%d ", p->data);
while (p->right == 1) { //2 有后继找后继
p = p->rchild;
printf("%d ", p->data);
}
p = p->rchild; //3 无后继找右子树
}
}
pnode createnode(int value) {
pnode newnode = (pnode)malloc(sizeof(node));
if (!newnode) return NULL;
newnode->lchild = NULL;
newnode->rchild = NULL;
newnode->left = 0;
newnode->right = 0;
newnode->data = value;
return newnode;
}
void insert(pnode& root, int value) { //递归寻找,定位到值该在的位置
if (root == NULL) {
root = createnode(value);
return;
}
if (root->data > value)
insert(root->lchild, value);
else
insert(root->rchild, value);
}
int main() {
pnode tree = NULL;
insert(tree, 5);
insert(tree, 3);
insert(tree, 8);
insert(tree, 1);
insert(tree, 6);
insert(tree, 2);
insert(tree, 4);
insert(tree, 9);
printf("建立线索二叉树:5,3,8,1,6,2,4,9\n");
pre = tree;
inthread(tree);
inordertraverse(tree);
}四、树和森林
4.1树转为二叉树
1.将同一节点的兄弟相连
2.仅保留节点最左孩子连线,删除与其它孩子的连线
3.把孩子之间的连线旋转使其符合树的形状
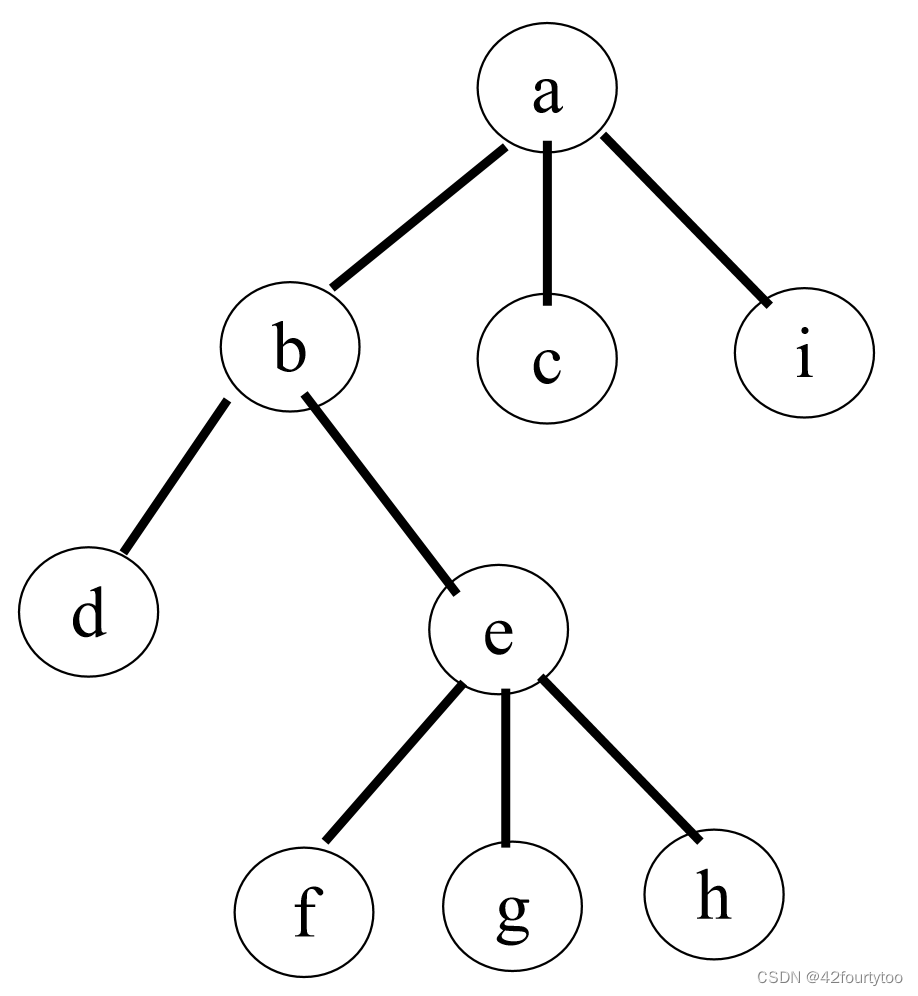
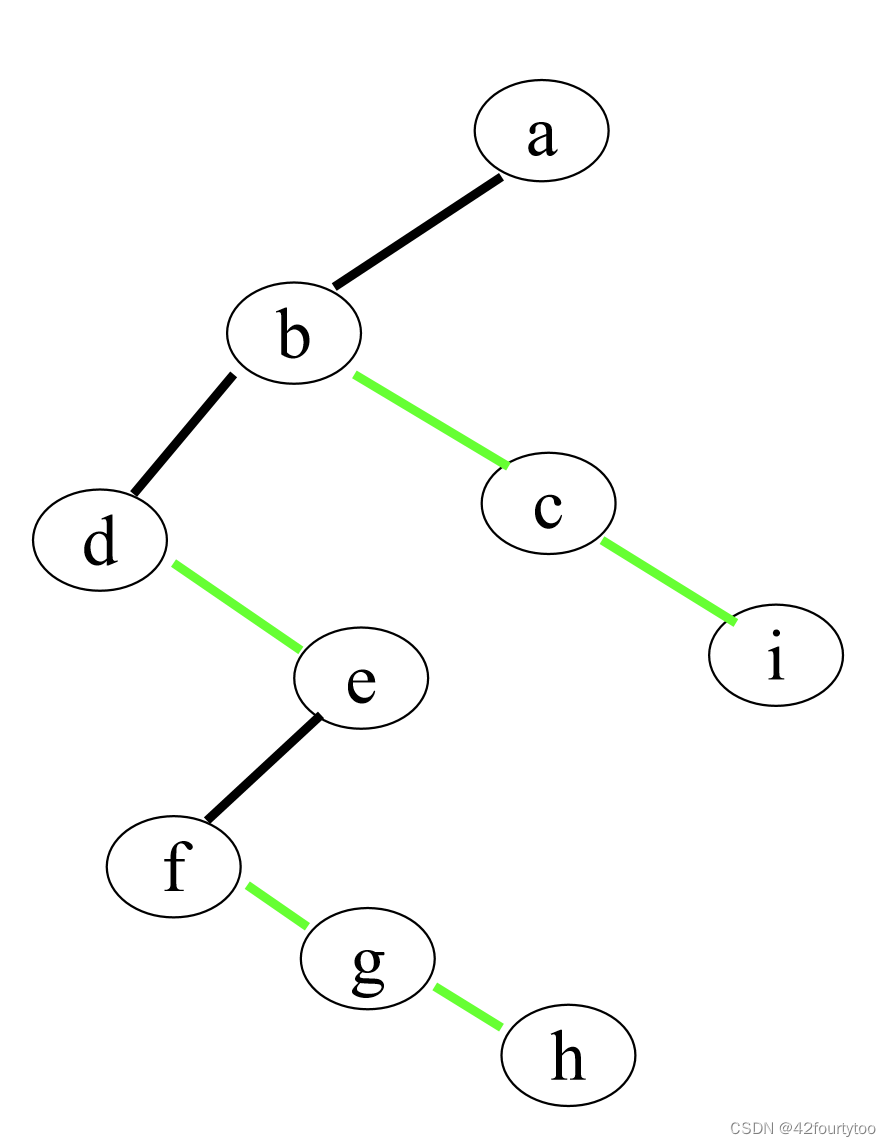
特点:根节点无右子树
4.2二叉树还原为树
把所有右孩子变为兄弟
4.3森林变为二叉树
树各自变为二叉树,把根节点依次接到右子树上
设森林F中有三棵树,第一,第二,第三棵树的结点个数分别为M1,M2和M3。与森林F对应的二叉树根结点的右子树上的结点个数是( )
答案:M2+M3
设森林F对应的二叉树为B,它有m个结点,B的根为p, p的右子树结点个数为n, 森林F中第一棵树的结点个数是( )
答案:m-n
4.4树的遍历
树:
先根遍历:访问根节点;依次先根遍历根节点的每棵子树
后根遍历:依次后根遍历根结点的每棵子树;访问根结点

先根:abcde
后根:bdcea
先根序列相当于转化为二叉树后前序遍历
后根序列相当于转化为二叉树后中序遍历
五、哈夫曼树
树的带权路径长度(WPL):树中所有叶子结点到根的经过的边的条数与叶子结点上权的乘积之和
用一些带值的节点当叶节点建立二叉树,哈夫曼树是这之中WPL最小的
哈夫曼建树+编码
建树
1.将给定的权值排成递增序列
2.取两最小值作为左右子节点,向上生成父节点,父节点值为这两个最小值的和
3.把父节点的值插入到递增序列中
4.重复2,3
比如7,5,2,4得到树:
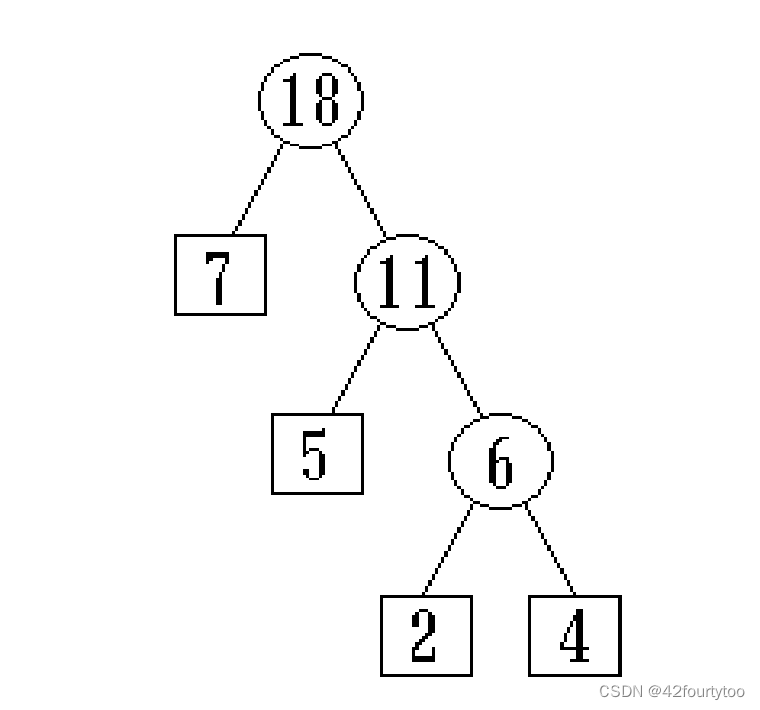
编码
1.将哈夫曼树所有左指针标0,右指针标1
2.从根走到叶节点,经过的01排成序列,即为该叶子的哈夫曼编码
比如上面的树,叶子对应的哈夫曼编码为:
“7”:0
“5”:10
“2”:110
“4”:111
WPL=1*7+2*5+3*2+3*4=35
哈夫曼平均码长:例如我们为出现频率不同的字母进行编码,哈夫曼平均码长为 编码长度*频率,再求和
特点:哈夫曼树没有度为1的节点;如果有n个叶子节点,则共有2n-1个节点;
下列选项给出的是从根分别到达两个叶节点路径上的权值序列,能属于同一棵哈夫曼树的是()
A.24,10,5 和24,10,7
B. 24,10,5和24,12,7
C. 24,10,10和24,14,11
D. 24,10,5和24,14,6
答案:D 知道根节点和一个子节点的值,做差得另一个子节点的值。把树画出来进行排除
代码:
//哈夫曼树编码解码
#include<stdio.h>
#include<stdlib.h>
typedef struct { //哈夫曼树采用顺序存储,每个元素包括名称,权重,左右子树,父节点
char data;
int weight;
int parent;
int lchild;
int rchild;
}huffnode;
typedef struct { //哈夫曼树结构体
int leafnum; //叶子个数
huffnode* mat; //内容域
}hufftree, * phufftree;
phufftree createhufftree(int n, char data[], int w[])
{
phufftree tree = (phufftree)malloc(sizeof(hufftree)); //给树分配空间
if (!tree) return NULL;
tree->leafnum = n;
tree->mat = (huffnode*)malloc(sizeof(huffnode) * (2 * n - 1)); //给节点分配空间
if (!tree->mat) return NULL;
int i, j;
for (i = 0; i < 2 * n - 1; i++)
{ //处理前n个叶子节点
if (i < n) {
tree->mat[i].data = data[i];
tree->mat[i].weight = w[i];
tree->mat[i].lchild = -1;
tree->mat[i].rchild = -1;
tree->mat[i].parent = -1;
}
else { //处理后n-1个节点
tree->mat[i].data = 0;
tree->mat[i].lchild = -1;
tree->mat[i].rchild = -1;
tree->mat[i].parent = -1;
tree->mat[i].weight = -1;
}
}
int min1, min2, x1, x2;
for (i = 0; i < n - 1; i++)
{ //在前n+i个数中寻找两个最小值,填充后n-1个节点
min1 = min2 = 65535;
x1 = x2 = 0;
for (j = 0; j < n + i; j++)
{
if (tree->mat[j].weight < min1 && tree->mat[j].parent == -1)
{
x2 = x1;
min2 = min1;
x1 = j;
min1 = tree->mat[j].weight;
}
else if (tree->mat[j].weight < min2 && tree->mat[j].parent == -1){
x2 = j;
min2 = tree->mat[j].weight;
}
}
tree->mat[n + i].weight = min1 + min2;
tree->mat[n + i].lchild = x1;
tree->mat[n + i].rchild = x2;
tree->mat[x1].parent = tree->mat[x2].parent = n + i;
}
printf("哈夫曼树为:\ndata\tweight\tparent\tlchild\trchild\n");
for (i = 0; i < n * 2 - 1; i++) {
printf("%d\t%d\t%d\t%d\t%d\n", tree->mat[i].data, tree->mat[i].weight, tree->mat[i].parent, tree->mat[i].lchild, tree->mat[i].rchild);
}
return tree;
}
void encode(phufftree tree) //编码
{
int i;
int code[5] = {};
int head = 0; //记录编码长度
int temp; //标记当前指向的节点
for (i = 0; i < tree->leafnum; i++)
{
temp = i;
while (tree->mat[temp].parent != -1)
{
if (tree->mat[tree->mat[temp].parent].lchild == temp) //是父节点左子树赋0,右赋1
code[head++] = 0;
else
code[head++] = 1;
temp = tree->mat[temp].parent; //从叶子往根找
}
printf("%c:", tree->mat[i].data);
for (--head; head >= 0; head--) {
printf("%d", code[head]);
}
printf("\n");
head++;
}
}
void decode(phufftree tree, int* code)
{
int p;
while (*code != -1) //遇到-1结束
{
p = 2 * tree->leafnum - 2; //根节点编号2n-2
while (p >= tree->leafnum)
{
if (*code == 0)
p = tree->mat[p].lchild;
else
p = tree->mat[p].rchild;
code++;
}
printf("%c", tree->mat[p].data);
}
}
int main()
{
int num = 13;
char data[] = { 'a','b','d','e','g','i','k','n','o','r','s','t','v'};
int weight[] = { 9,9,4,14,9,9,4,9,4,9,4,4,4 };
phufftree tree = createhufftree(num, data, weight);
encode(tree);
int code[] = { 1,1,1,1,0,0,0,1,1,1,1,1,0,0,1,1,0,0,1,0,1,0,0,1,1,0,0,1,1,1,0,0,0,1,1,0,1,0,0,0,1,0,1,1,1,0,1,1,1,1,0,1,1,0,1,1,0,0,0,0,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,1,1,-1 };
decode(tree, code);
}
//例子:a barking dog never bites.