UNIRE: A Unified Label Space for Entity Relation Extraction
- 1 任务介绍
- 2 UniRE模型
- 3 实验
- 4 总结
1 任务介绍
过构建标签空间来对实体和关系进行联合抽取的方法。
实体关系抽取旨在提取文本中的实体并检测它们的实体类型,以及对每个实体对检测它们的关系。作者提出了一种统一标签空间的联合抽取方法——填表法,主要是将实体检测和关系抽取两个子任务放在同一个标签空间中进行处理。针对该方法,提出了一种对应的联合解码算法(Joint Decoding Algorithm),解码出表中的实体和关系。
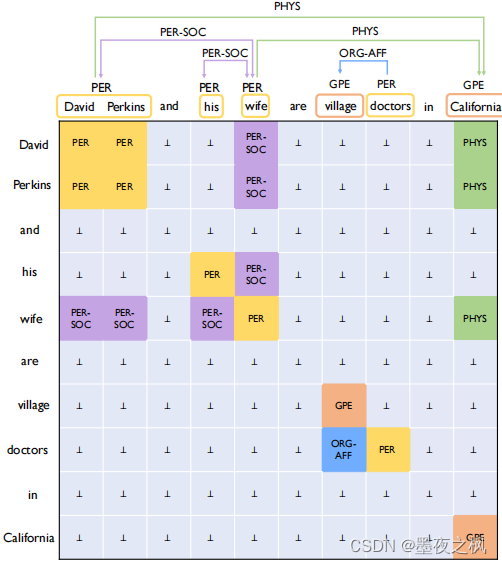
图中词对关系表。将文本表示为二维表结构,它具有更强的表示能力,能将所有的实体和关系都在这张表中完整得表示出来。其中,实体类型:(PER, 人名实体),(GPE, 地理位置实体);关系类型:(PER-SOC, 社会关系),(ORG-AFF, 机构附属关系),(PHYS, 位置临近关系)
在这个表中每个单元格对应于一个单词对,使用不同颜色表示不同的实体或关系类型。对角线上的正方形表示实体类型,而关系是对角线外的矩形。
表可以识别对称性和重叠关系:
- 对称性:对称的关系类型在表中关于对角线对称的,表中紫色单元格表示了两对儿对称的关系类型PER-SOC,而绿色单元格表示的PHYS和蓝色单元格表示的ORG-AFF则分别表示了两种不同的不对称关系类型。
- 重叠关系:表前两行中,黄色单元格表示了David Perkins(大卫·帕金斯)属于PERson类别的实体,而紫色和绿色单元格分别表示David Perkins(大卫·帕金斯)关于wife和California(加利福尼亚)的关系,其中紫色单元格表示的是一种对称关系,另一种绿色单元格表示的是不对称的关系。
2 UniRE模型
UniRE模型采用了一个基于预训练模型的双仿射模型来建模单词对之间关系。
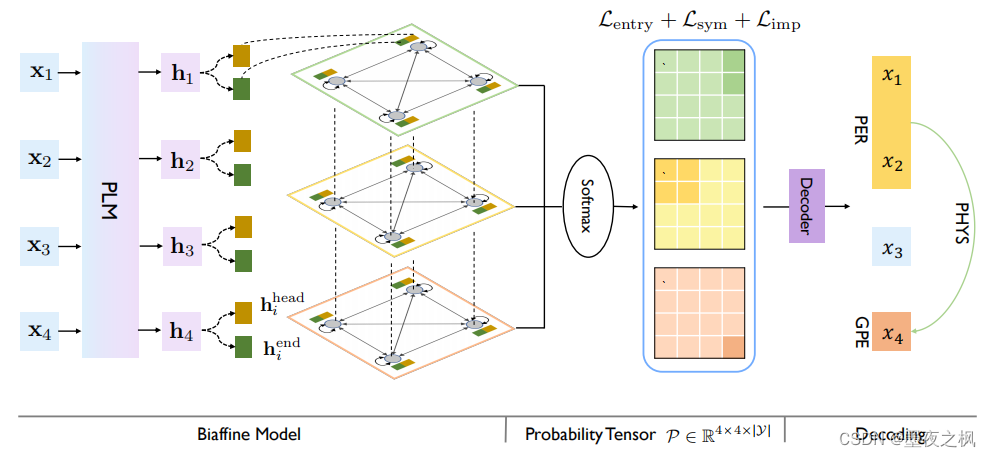
输入序列通过预训练语言模型(PLM) 学习上下文表示

为了更好地编码表中的单词的方向信息,使用两个多层感知器(MLP) 分别学习每个单词的头部和尾部投影表示,使得模型能够识别每一个单词的头部或尾部角色信息
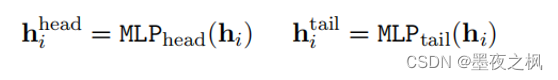
使用双仿射注意力机制得到每一个单元格对应的打分向量(scoring vector)
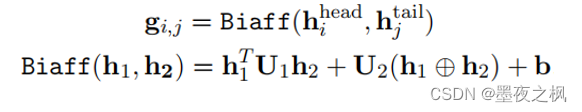
在获得打分向量后,将其送入softmax中计算每一个单元标签的概率分布:
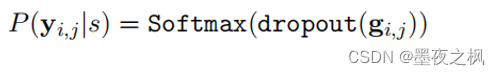
填表的目标函数(交叉熵损失):
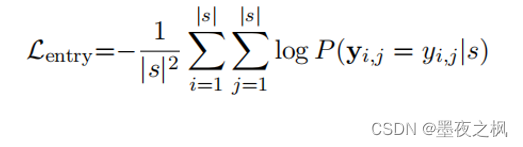
为了更好地填表,提出了对称性和蕴含性两方面的约束限制
- 对称性:对于实体和对称关系,其对应的正方形和矩形必然关于对角线对称。因此,这些标签对应的概率分数应该关于对角线对称。
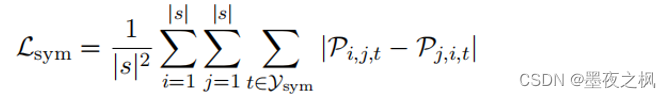
- 蕴含性:给定一个关系,参与这个关系必然是两个实体;相反给定两个实体,它们之间不一定存在关系。因此,一个关系的概率分数应该不高于其两个实体的概率分数。

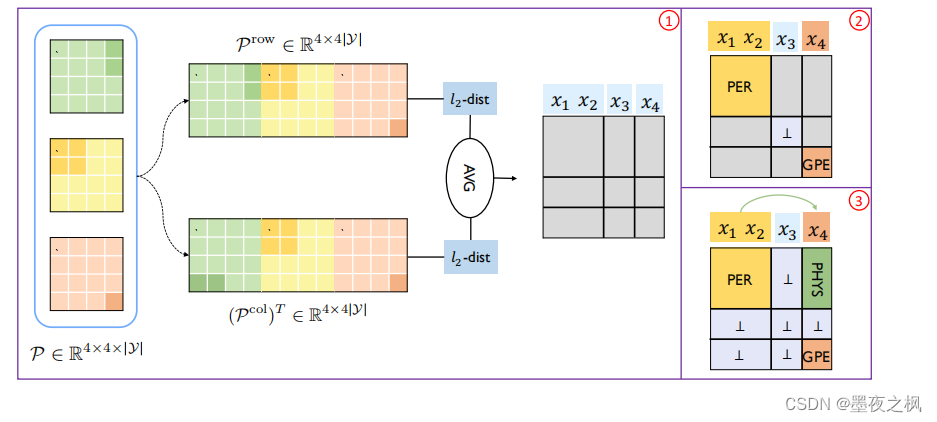
联合解码算法(joint decoding algorithm) :
- 首先是解码跨度span,就是划分实体边界,(图①,最右侧)x1和x2这两个单词表示一个实体,所以将此处两行、两列划分到一处。(图①,从左到右)这个模型是先将模型预测的三维概率张量按行列展成二维矩阵,然后计算相邻行列之间的欧式距离,将行列距离的平均值作为最终距离,来判断此处是否为切分点。
- (图②)在划分完实体边界后进行实体解码,计算对角线上的每个正方形分数,来确定最终实体类型。
- (图③)关系解码与实体解码类似,是通过计算非对角线上的矩形的分数确定关系类型的。
3 实验
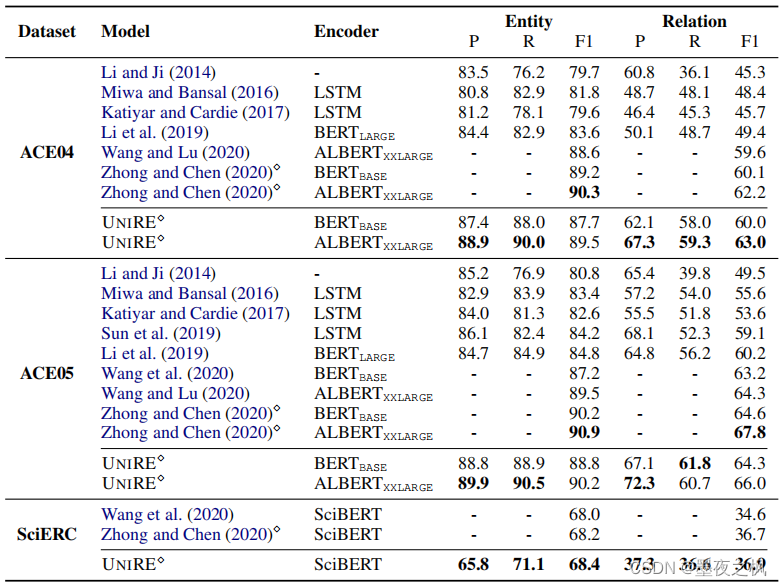
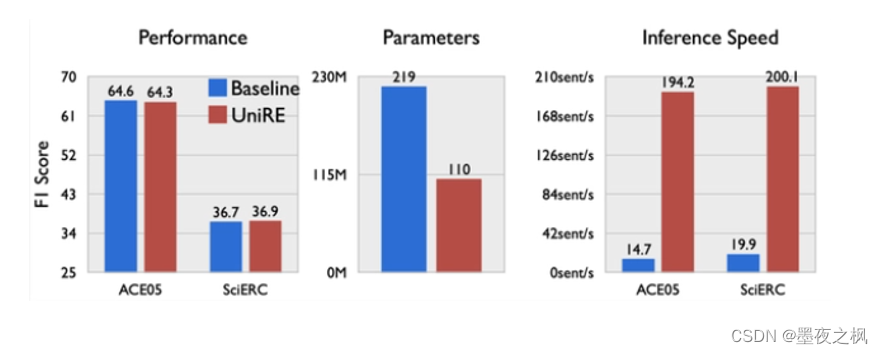
三个常用的实体关系抽取数据集(ACE04,ACE05,SciERC)上和SOTA方法做对比。结果表明,并没有太大的提升,但是它的优势主要体现在推理速度层面,与SOTA相比参数量仅为其的一半,而且推理速度加快了十几倍。
4 总结
作者提出了一种填表法的联合学习方法,在少量参数和快速推理的情况下结果有相应的提升。