自我介绍
- 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。微信小号【ca_cea】

实现Python隐私文本过滤器,通过删除个人身份信息(PII)来保护用户的隐私。
GDPR是欧盟制定的《通用数据保护条例》。其目的是保护所有欧洲居民的数据。保护数据也是开发人员的内在价值。通过控制对列和行的访问,保护行/列数据结构中的数据相对容易。但是免费文本呢?
为了满足我们的隐私要求,我们可以调整自由文本字段的内容,用标签取代与隐私相关的信息。文本的含义没有改变,但不能通过匿名化与个人相关。目标是翻译以下文本(日期为荷兰语):
The possibilities have increased since 2014, especially compared to2012, hè Kees? The system has different functions to manipulate data. The date is 12–01–2021 (or 12 jan 2021 or 12 januari 2021).
You can reach me at nam@provider.com and I live in Rotterdam. My address is Maasstraat 13, 1234AB. My name is Thomas de Vries and I have Acne. Oh , I use ranitidine for this.
并将其替换为
The possibilities have increased since <NUMBER>, especially compared to<NUMBER>, hè <NAME>? The system has different functions to manipulate data. The date is <DATE> (or <DATE> or <DATE>).
You can reach me at <EMAIL> and I live in <PLACE>. My address is <ADRESS> <NUMBER>, <POSTALCODE>. My name is <NAME> <NAME> and I have <DISEASE>. Oh , I use <MEDICINE> for this.
本文介绍了一个简单的隐私过滤器,它将执行以下操作:
- 用标签<DATE>替换日期
- 将URL替换为标签<URL>
- 将电子邮件地址替换为<email>
- 将邮政编码替换为<POSTALCODE>
- 将数字替换为<NUMBER>
- 用<PLACE>替换城市和地区
- 将街道名称替换为<street>
- 将名字和姓氏替换为<NAME>
- 用<疾病>替换疾病
- 将药品名称替换为<medicine>
添加后两个是因为医疗信息需要额外的护理。发生的次数会很低,但当这些信息被泄露时,影响会很大。
前四个动作将用正则表达式执行,而最后五个动作将由替换函数实现。我们的隐私过滤器类具有以下结构:
import re
from flashtext import KeywordProcessor
class PrivacyFilter:
def __init__(self):
...
def initialize(self):
...
def remove_numbers(self, text):
...
def remove_dates(self, text):
...
def remove_email(self, text):
...
def remove_postal_codes(self, text):
...
def filter(self, inputtext):
text = self.remove_dates(text)
text = self.remove_email(text)
text = self.remove_postal_codes(text)
text = self.remove_numbers(text)
...
if __name__ == "__main__":
sentence = ...
pfilter = PrivacyFilter()
pfilter.initialize()
print(pfilter.filter(sentence))
PrivacyFilter类实现了不同的过滤器。在创建和初始化后,该对象可以用于过滤文本。它与regulator表达式和FlashText WordProcesser.配合使用。
使用正则表达式筛选
前四个过滤器是用正则表达式实现的。更换数字是最简单的第一种更换方式:
def remove_numbers(self, text):
return re.sub(r'\w*\d\w*', '<NUMBER>', text).strip()
此正则表达式将所有包含一个或多个数字的单词替换为标记<NUMBER>。这将替换文本中的银行账户、电话号码、身份证号码等。此过滤器是最后执行的,因此邮政编码和日期可以由其相应的标签代替,而不是一系列数字标签。
更高级的是删除邮政编码的功能。荷兰的邮政编码格式为0000AA,数字和字母之间有一个可选的空格。要替换这些,请使用以下正则表达式:
def remove_postal_codes(self, text):
return re.sub("[0-9]{4}[ ]?[A-Z]{2}([ ,.:;])", "<POSTALCODE>\\1", text)
添加带标点符号的可选部分是为了防止单词前两个字母的四个数字序列被替换,例如,我们不想将“4000项的顺序”替换为“<POSTCODE>ems的顺序”。
由于电子邮件地址的复杂性,删除电子邮件地址变得有点棘手:
def remove_email(text):
return re.sub("(([\w-]+(?:\.[\w-]+)*)@((?:[\w-]+\.)*\w[\w-]{0,66})\." \
"([a-z]{2,6}(?:\.[a-z]{2})?))(?![^<]*>)", "<EMAIL>", text)
正则表达式可以在网站上找到,99.99%的正则表达式有效。可以在那里找到各种语言的电子邮件检查器的实现。正则表达式的另一个好来源是Murani.nl.。
删除日期是不可能用一个正则表达式的,因为月份可以写成数字、缩写和全名。要删除日期,我们需要三个正则表达式:
def remove_dates(text):
text = re.sub("\d{2}[- /.]\d{2}[- /.]\d{,4}", "<DATUM> ", text)
text = re.sub(
"(\d{1,2}[^\w]{,2}(januari|februari|maart|april|mei|juni|juli|augustus"\
"|september|oktober|november|december)([- /.]{,2}(\d{4}|\d{2})){,1})"\
"(?P<n>\D)(?![^<]*>)", "<DATE> ", text)
text = re.sub(
"(\d{1,2}[^\w]{,2}(jan|feb|mrt|apr|mei|jun|jul|aug|sep|okt|nov|dec)"\
"([- /.]{,2}(\d{4}|\d{2})){,1})(?P<n>\D)(?![^<]*>)", "<DATE> ", text)
return text
第一个正则表达式匹配以数字形式书写的日期,格式为dd-mm-yyyy。支持日期部分之间的不同分隔符。第二个和第三个匹配日期与文本中的月份名称。
使用KeyWordProcessor进行筛选
如果像以前的替换集一样构建,过滤地点、街道、名称、药物和疾病需要数千个正则表达式。即使将一系列名称组合在一个正则表达式中也是昂贵的。
为了解决这个问题,Alfred V.Aho实现了 Aho-Corasick algorithm,该算法定位存储在类似字典结构中的字符串。从所有搜索项创建一个图,并遍历该图以解析文本。
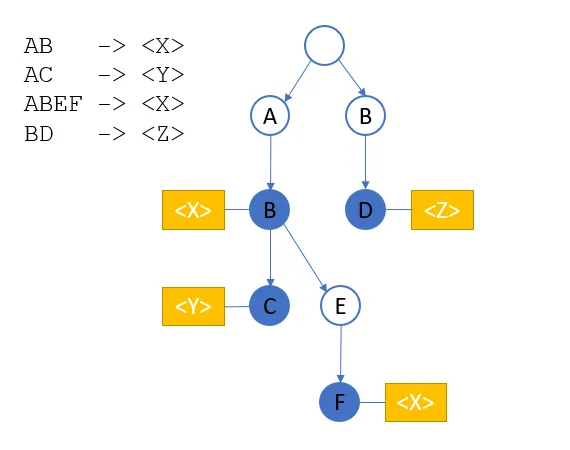
Example tree (image by author)
该图包含字符串“AB”、“ABEF”、“AC”和“BD”,因为只有蓝色节点是结束节点。当第一个字母是“AB”时,它是一个结束节点,除非后面跟着字母“C”和“E”。为了在KeywordProcessor中使用,替换标记与图中的结束节点相关联。通过这种方式,所有不同的隐私元素都可以添加到一个图中,并且仍然可以由适当的标签替换。
这个算法有几种实现,这里我们将使用Github的Flashtext实现。该算法在大规模替换和检索文档中的关键词中进行了描述。它包含一个KeywordProcessor,关键字将添加到其中并替换:KeywordProcessor.add_keyword('keyword','replacement')。端节点存储要放置的替换项。
在数据集文件夹中,有几个文件每行都有一个关键字,例如一个文件具有所有的名字,或者至少有10000个最常见的名字。我们可以使用替换标记<NAME>将该文件中的所有元素添加到图中,如下所示:
def __init__(self):
self.keyword_processor_case_sensitive = KeywordProcessor(case_sensitive=True)
def file_to_list(filename, minimum_length=0):
with open(filename, encoding='latin') as f:
lst = [line.rstrip() for line in f]
lst = list(dict.fromkeys(lst))
if minimum_length > 0:
lst = list(filter(lambda item: len(item) > minimum_length, lst))
return lst
def initialize(self):
for naam in self.file_to_list('datasets\\firstnames.csv'):
self.keyword_processor_case_sensitive.add_keyword(naam, '<NAME>')
在构造函数中,会创建一个区分大小写的KeywordProcessor。我们使用区分大小写的处理程序,因为在荷兰语中,有几个名字也是动词。这样,我们只会在它们以输入文件中的大写字母开头时替换它们。如果您想更安全,可以使用不区分大小写的处理器。
输入文件被读取到列表中(第5行和第6行),从该列表中删除重复项(第7行),并以最小长度过滤该列表。列表中的每个项目都会添加到处理器中(从而添加到图形中),并带有相应的标记“<NAME>”。
在initialize函数中,可以为街道名称、地点、姓氏、药品等添加更多的数据文件。
class PrivacyFilter:
def __init__(self):
self.keyword_processor_case_sensitive = KeywordProcessor(case_sensitive=True)
self.keyword_processor_case_insensitive = KeywordProcessor(case_sensitive=False)
def file_to_list(self, filename, minimum_length=0, drop_first=1):
with open(filename, encoding='latin') as f:
lst = [line.rstrip() for line in f]
lst = list(dict.fromkeys(lst))
if minimum_length > 0:
lst = list(filter(lambda item: len(item) > minimum_length, lst))
return lst[drop_first:]
def initialize(self):
for naam in self.file_to_list('datasets\\streets_Nederland.csv', minimum_length=5):
for c in ['.', ',', ' ', ':', ';', '?', '!']:
self.keyword_processor_case_insensitive.add_keyword(naam + c, '<STREET>' + c)
for naam in self.file_to_list('datasets\\places.csv'):
for c in ['.', ',', ' ', ':', ';', '?', '!']:
self.keyword_processor_case_insensitive.add_keyword(naam + c, '<PLACE>' + c)
for naam in self.file_to_list('datasets\\firstnames.csv'):
self.keyword_processor_case_sensitive.add_keyword(naam, '<NAME>')
for naam in self.file_to_list('datasets\\lastnames.csv'):
self.keyword_processor_case_sensitive.add_keyword(naam, '<NAME>')
for naam in self.file_to_list('datasets\\aandoeningen.csv'):
self.keyword_processor_case_insensitive.add_keyword(naam, '<DISEASE>')
for naam in self.file_to_list('datasets\\medicijnen.csv'):
self.keyword_processor_case_insensitive.add_keyword(naam, '<MEDICINE>')
位置名称是按大小过滤的,因为数据是从OpenStreetMap中提取的,并且在获得的数据集中有空字段、零长度字段和短缩写。最小尺寸可根据您的安全要求进行定制。
过滤文本
有了所有的函数,我们可以编写实际的过滤器方法:
def filter(self, inputtext):
text = self.remove_dates(text)
text = self.remove_email(text)
text = self.remove_postal_codes(text)
text = self.remove_numbers(text)
text = self.keyword_processor_case_insensitive.replace_keywords(text)
text = self.keyword_processor_case_sensitive.replace_keywords(text)
return text.strip()
调用基于正则表达式的方法,然后调用区分大小写和不区分大小写的处理器。由于不同的数据集集成在KeywordProcessors中,因此只需要执行一次。这将产生所需的输出。
但是性能呢?更换文本部件可能会变得非常昂贵,尤其是包含大量禁止使用的单词,在这种情况下约为136.000(!!)。在我的电脑上,初始化课程需要3.1秒,但过滤前面介绍的文本只需要0.5毫秒。太快了!这足够快,可以在实际用例中使用。
最后的想法
本文为自由文本提供了一个简单但非常有效的隐私解析器。改进总是可能的,但这段代码是从文本中过滤隐私信息的最佳方法。
可以通过用标记化器替换算法来进行改进。这使得引入Levenshtein function来测量单词之间的距离成为可能,从而支持删除有打字错误的单词。
完整的代码可以在Github上找到:https://github.com/lmeulen/PrivacyFilter
标签和例句是荷兰语,但源代码可以很容易地被其他语言所采用。在存储库中还有一个程序,用于收集荷兰语的不同数据集。请注意,这些操作将第一行添加到具有数据名称的数据文件中。PrivacyFiler类在读取数据文件时过滤第一行。
本文:【隐私保护】使用Python从文本中删除个人信息 | 开发者开聊
欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.