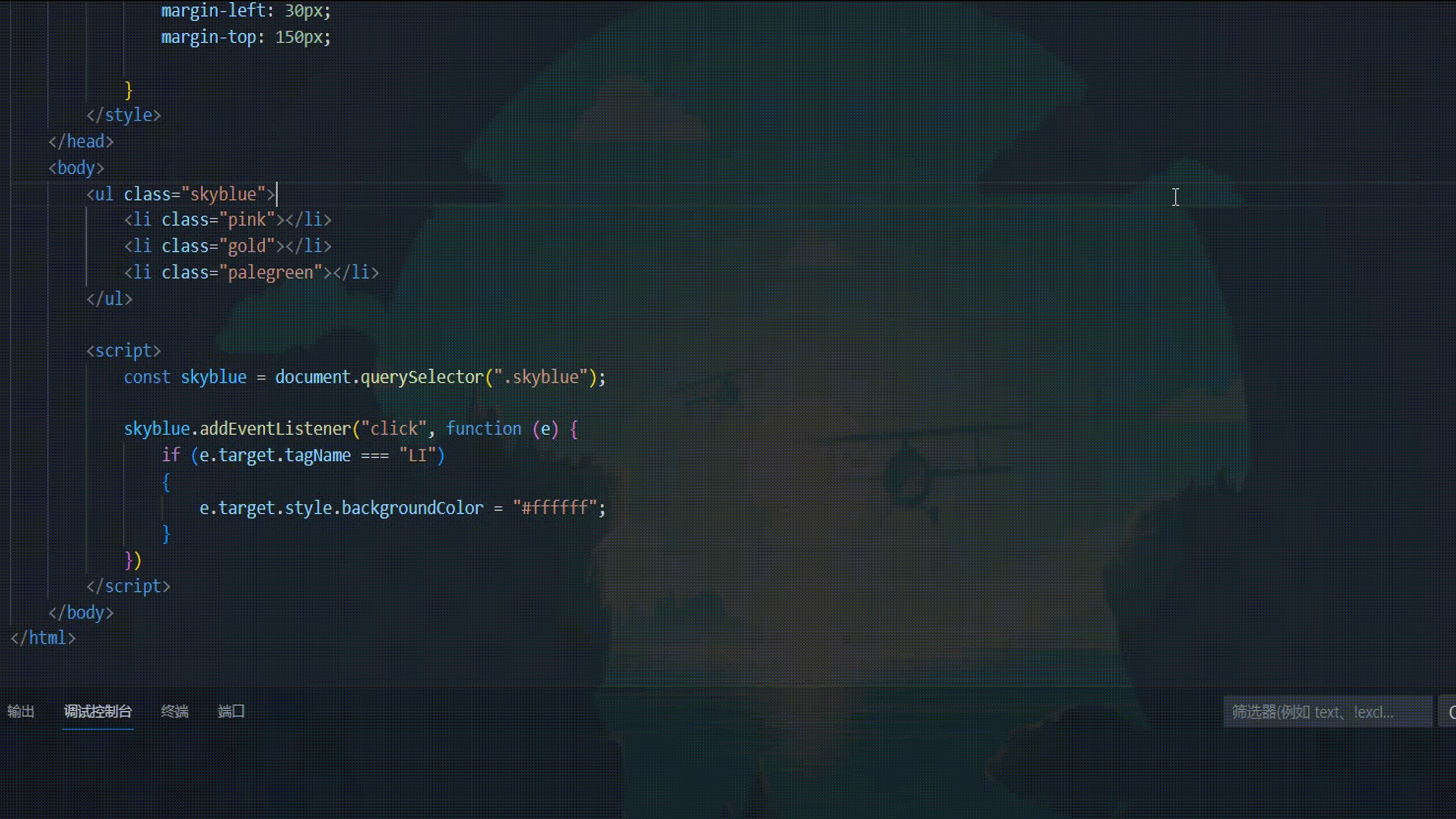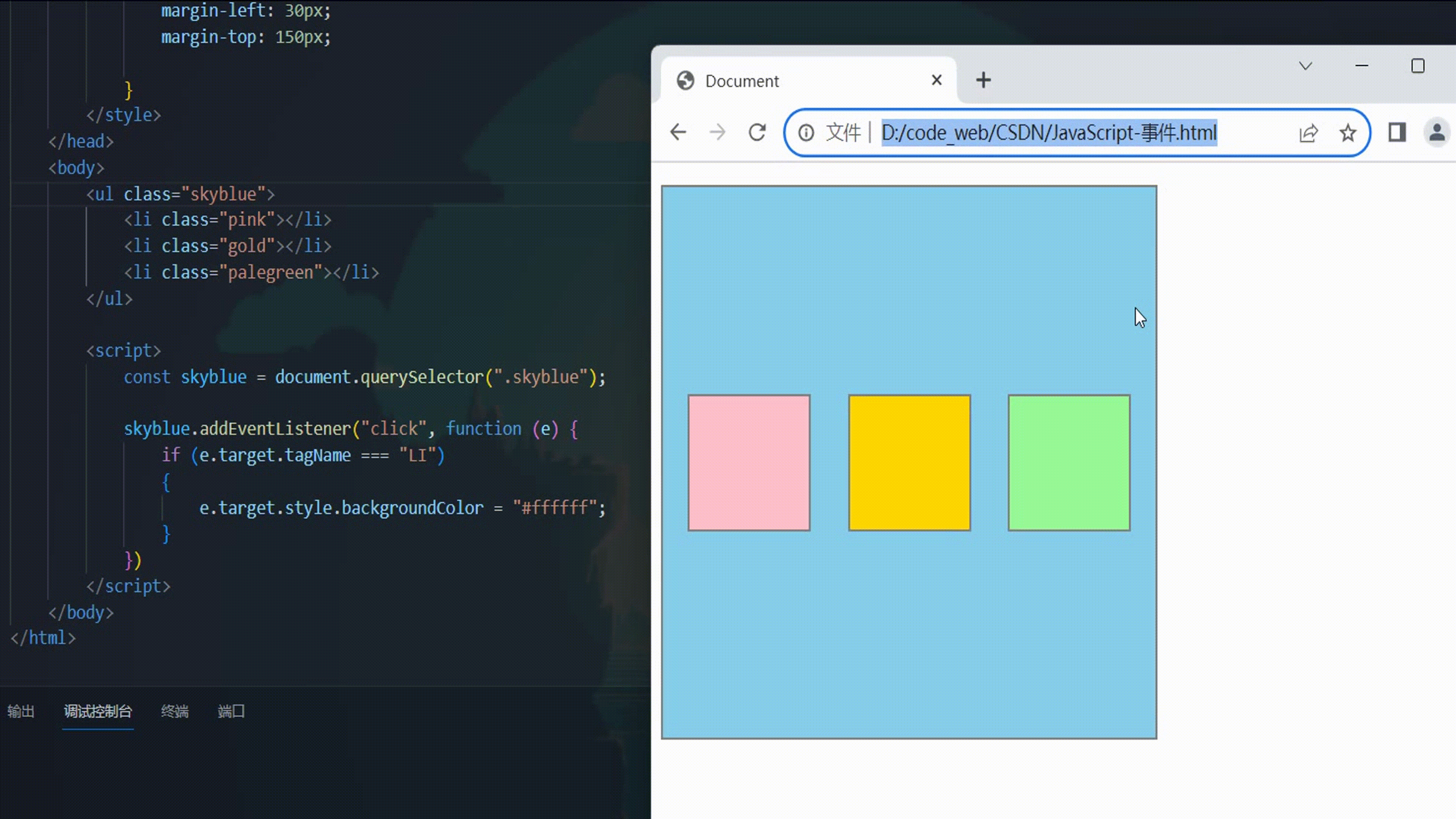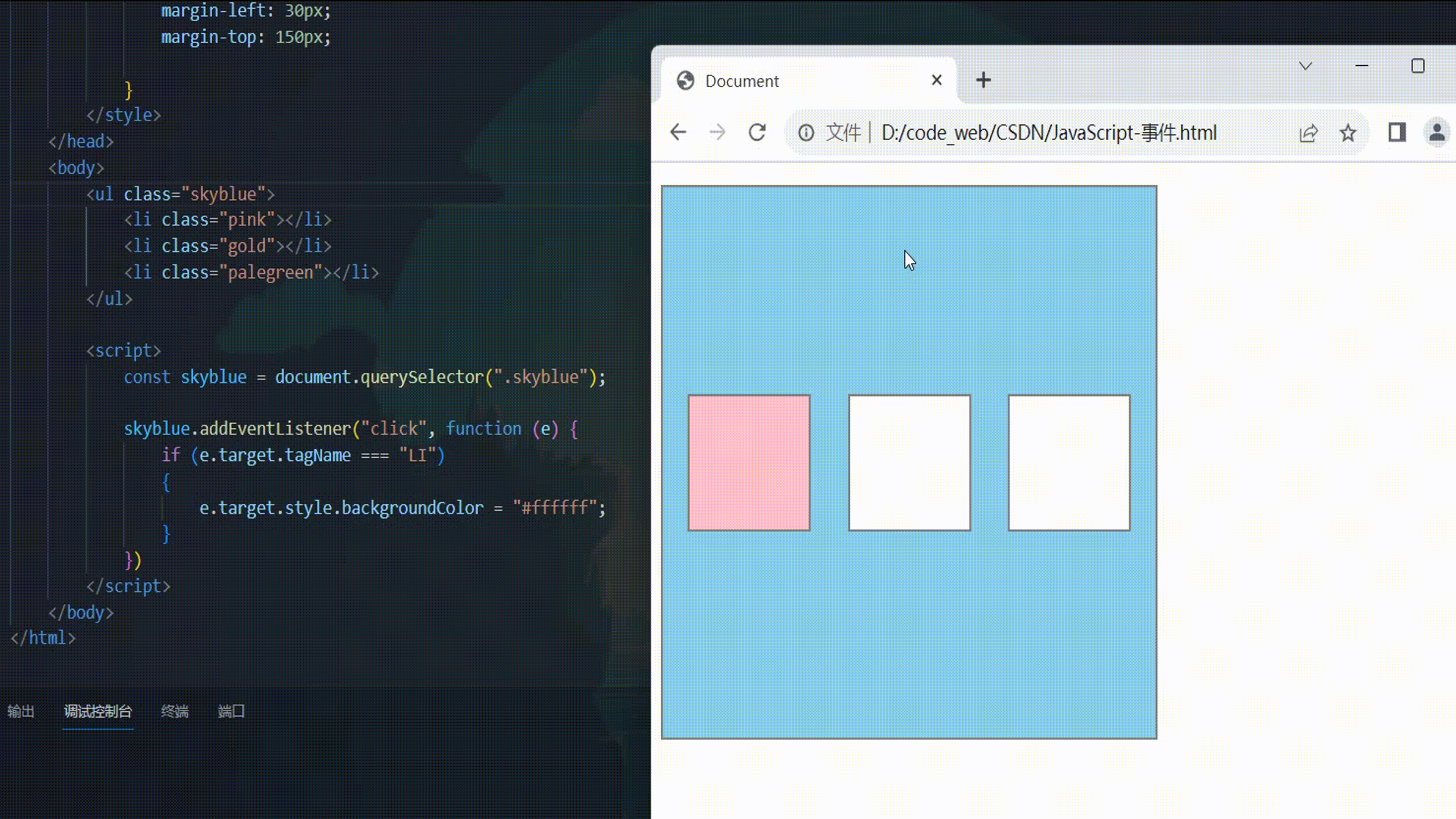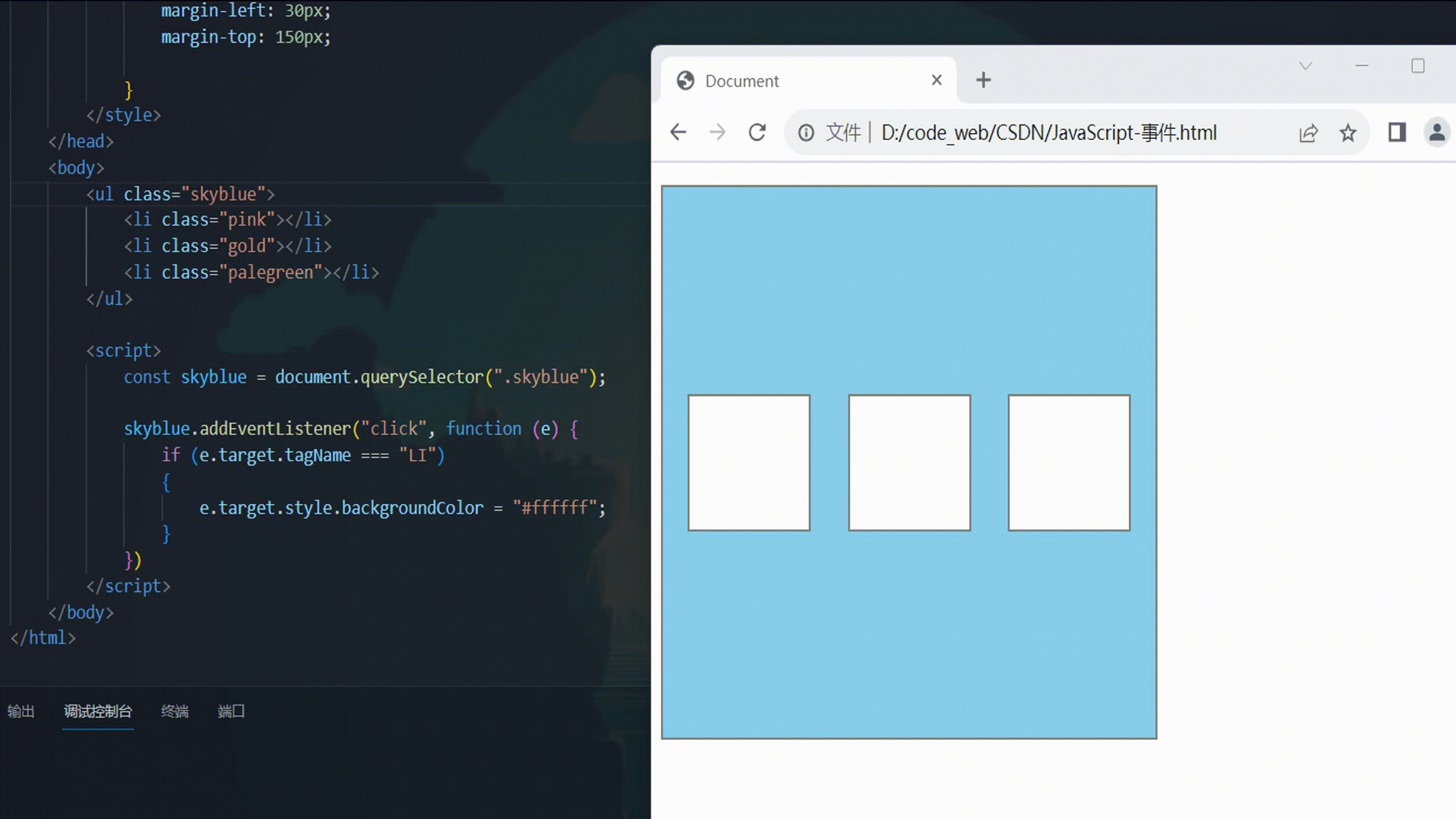
回调函数
tf.keras 的回调函数实际上是一个类,一般是在 model.fit 时作为参数指定,用于控制在训练过程开始或者在训练过程结束,在每个 epoch 训练开始或者训练结束,在每个 batch 训练开始或者训练结束时执行一些操作,例如收集一些日志信息,改变学习率等超参数,提前终止训练过程等等。同样地,针对 model.evaluate 或者 model.predict 也可以指定 callbacks 参数,用于控制在评估或预测开始或者结束时,在每个 batch 开始或者结束时执行一些操作,但这种用法相对少见。
大部分时候,keras.callbacks 子模块中定义的回调函数类已经足够使用了,如果有特定的需要,我们也可以通过对 keras.callbacks.Callbacks 实施子类化构造自定义的回调函数。所有回调函数都继承至 keras.callbacks.Callbacks 基类,拥有 params 和 model 这两个属性。
其中 params 是一个 dict,记录了训练相关参数 (例如 verbosity, batch size, number of epochs 等等)。model 即当前关联的模型的引用。此外,对于回调类中的一些方法如 on_epoch_begin,on_batch_end,还会有一个输入参数 logs, 提供有关当前 epoch 或者 batch 的一些信息,并能够记录计算结果,如果 model.fit 指定了多个回调函数类,这些 logs 变量将在这些回调函数类的同名函数间依顺序传递。
内置回调函数
- BaseLogger:收集每个 epoch 上 metrics 在各个 batch 上的平均值,对 stateful_metrics 参数中的带中间状态的指标直接拿最终值无需对各个 batch 平均,指标均值结果将添加到 logs 变量中。该回调函数被所有模型默认添加,且是第一个被添加的。
- History:将 BaseLogger 计算的各个 epoch 的 metrics 结果记录到 history 这个 dict 变量中,并作为 model.fit 的返回值。该回调函数被所有模型默认添加,在 BaseLogger 之后被添加。
- EarlyStopping:当被监控指标在设定的若干个 epoch 后没有提升,则提前终止训练。
- TensorBoard:为 Tensorboard 可视化保存日志信息。支持评估指标,计算图,模型参数等的可视化。
- ModelCheckpoint:在每个 epoch 后保存模型。
- ReduceLROnPlateau:如果监控指标在设定的若干个 epoch 后没有提升,则以一定的因子减少学习率。
- TerminateOnNaN:如果遇到 loss 为 NaN,提前终止训练。
- LearningRateScheduler:学习率控制器。给定学习率 lr 和 epoch 的函数关系,根据该函数关系在每个 epoch 前调整学习率。
- CSVLogger:将每个 epoch 后的 logs 结果记录到 CSV 文件中。
- ProgbarLogger:将每个 epoch 后的 logs 结果打印到标准输出流中。
自定义回调函数
可以使用 callbacks.LambdaCallback 编写较为简单的回调函数,也可以通过对 callbacks.Callback 子类化编写更加复杂的回调函数逻辑。
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers,models,losses,metrics,callbacks
import tensorflow.keras.backend as K
# 示范使用LambdaCallback编写较为简单的回调函数
import json
json_log = open('./data/keras_log.json', mode='wt', buffering=1)
json_logging_callback = callbacks.LambdaCallback(
on_epoch_end=lambda epoch, logs: json_log.write(
json.dumps(dict(epoch = epoch,**logs)) + '\n'),
on_train_end=lambda logs: json_log.close()
)
# 示范通过Callback子类化编写回调函数(LearningRateScheduler的源代码)
class LearningRateScheduler(callbacks.Callback):
def __init__(self, schedule, verbose=0):
super(LearningRateScheduler, self).__init__()
self.schedule = schedule
self.verbose = verbose
def on_epoch_begin(self, epoch, logs=None):
if not hasattr(self.model.optimizer, 'lr'):
raise ValueError('Optimizer must have a "lr" attribute.')
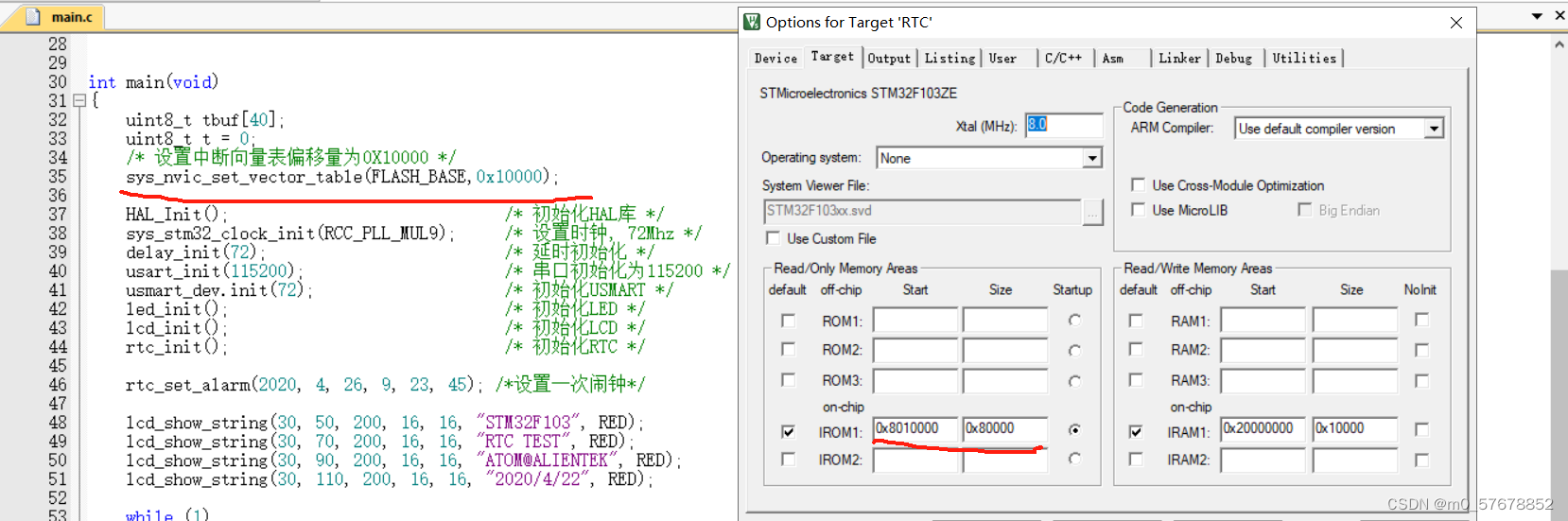
try:
lr = float(K.get_value(self.model.optimizer.lr))
lr = self.schedule(epoch, lr)
except TypeError: # Support for old API for backward compatibility
lr = self.schedule(epoch)
if not isinstance(lr, (tf.Tensor, float, np.float32, np.float64)):
raise ValueError('The output of the "schedule" function '
'should be float.')
if isinstance(lr, ops.Tensor) and not lr.dtype.is_floating:
raise ValueError('The dtype of Tensor should be float')
K.set_value(self.model.optimizer.lr, K.get_value(lr))
if self.verbose > 0:
print('\nEpoch %05d: LearningRateScheduler reducing learning '
'rate to %s.' % (epoch + 1, lr))
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
logs['lr'] = K.get_value(self.model.optimizer.lr)损失函数
一般来说,监督学习的目标函数由损失函数和正则化项组成。(Objective = Loss + Regularization),对于 keras 模型,目标函数中的正则化项一般在各层中指定,例如使用 Dense 的 kernel_regularizer 和 bias_regularizer 等参数指定权重使用 l1 或者 l2 正则化项,此外还可以用 kernel_constraint 和 bias_constraint 等参数约束权重的取值范围,这也是一种正则化手段。
损失函数在模型编译时候指定。对于回归模型,通常使用的损失函数是均方损失函数 mean_squared_error。对于二分类模型,通常使用的是二元交叉熵损失函数 binary_crossentropy。
对于多分类模型,如果 label 是 one-hot 编码的,则使用类别交叉熵损失函数 categorical_crossentropy。如果 label 是类别序号编码的,则需要使用稀疏类别交叉熵损失函数 sparse_categorical_crossentropy。如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量 y_true,y_pred 作为输入参数,并输出一个标量作为损失函数值。
损失函数和正则化项
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01),
kernel_constraint = constraints.MaxNorm(max_value=2, axis=0)))
model.add(layers.Dense(10,
kernel_regularizer=regularizers.l1_l2(0.01,0.01),activation = "sigmoid"))
model.compile(optimizer = "rmsprop",
loss = "binary_crossentropy",metrics = ["AUC"])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 4160
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 4,810
Trainable params: 4,810
Non-trainable params: 0
_________________________________________________________________内置损失函数
内置的损失函数一般有类的实现和函数的实现两种形式。如:CategoricalCrossentropy 和 categorical_crossentropy 都是类别交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。常用的一些内置损失函数说明如下。
- mean_squared_error(均方误差损失,用于回归,简写为 mse, 类与函数实现形式分别为 MeanSquaredError 和 MSE)
- mean_absolute_error (平均绝对值误差损失,用于回归,简写为 mae, 类与函数实现形式分别为 MeanAbsoluteError 和 MAE)
- mean_absolute_percentage_error (平均百分比误差损失,用于回归,简写为 mape, 类与函数实现形式分别为 MeanAbsolutePercentageError 和 MAPE)
- Huber(Huber 损失,只有类实现形式,用于回归,介于 mse 和 mae 之间,对异常值比较鲁棒,相对 mse 有一定的优势)
- binary_crossentropy(二元交叉熵,用于二分类,类实现形式为 BinaryCrossentropy)
- categorical_crossentropy(类别交叉熵,用于多分类,要求 label 为 onehot 编码,类实现形式为 CategoricalCrossentropy)
- sparse_categorical_crossentropy(稀疏类别交叉熵,用于多分类,要求 label 为序号编码形式,类实现形式为 SparseCategoricalCrossentropy)
- hinge(合页损失函数,用于二分类,最著名的应用是作为支持向量机 SVM 的损失函数,类实现形式为 Hinge)
- kld(相对熵损失,也叫 KL 散度,常用于最大期望算法 EM 的损失函数,两个概率分布差异的一种信息度量。类与函数实现形式分别为 KLDivergence 或 KLD)
- cosine_similarity(余弦相似度,可用于多分类,类实现形式为 CosineSimilarity)
自定义损失函数
自定义损失函数接收两个张量 y_true, y_pred 作为输入参数,并输出一个标量作为损失函数值。也可以对 tf.keras.loss.Loss 进行子类化,重写 call 方法实现损失的计算逻辑,从而得到损失函数的类的实现。
下面是一个 focal Loss 的自定义实现示范。focal Loss 是一种对 binary_crossentropy 的改进损失函数形式。它在样本不均衡和存在较多易分类的样本时相比 binary_crossentropy 具有明显的优势。
它有两个可调参数,alpha 参数和 gamma 参数。其中 alpha 参数主要用于衰减负样本的权重,gamma 参数主要用于衰减容易训练样本的权重。从而让模型更加聚焦在正样本和困难样本上。这就是为什么这个损失函数叫做 focal Loss。![]()
def focal_loss(gamma=2., alpha=0.75):
def focal_loss_fixed(y_true, y_pred):
bce = tf.losses.binary_crossentropy(y_true, y_pred)
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)
modulating_factor = tf.pow(1.0 - p_t, gamma)
loss = tf.reduce_sum(alpha_factor * modulating_factor * bce,axis = -1 )
return loss
return focal_loss_fixed
class FocalLoss(tf.keras.losses.Loss):
def __init__(self,gamma=2.0,alpha=0.75,name = "focal_loss"):
self.gamma = gamma
self.alpha = alpha
def call(self,y_true,y_pred):
bce = tf.losses.binary_crossentropy(y_true, y_pred)
p_t = (y_true * y_pred) + ((1 - y_true) * (1 - y_pred))
alpha_factor = y_true * self.alpha + (1 - y_true) * (1 - self.alpha)
modulating_factor = tf.pow(1.0 - p_t, self.gamma)
loss = tf.reduce_sum(alpha_factor * modulating_factor * bce,axis = -1 )
return loss