参考自
- up主的b站链接:霹雳吧啦Wz的个人空间-霹雳吧啦Wz个人主页-哔哩哔哩视频
- 这位大佬的博客 Fun'_机器学习,pytorch图像分类,工具箱-CSDN博客
数据集下载
http://download.tensorflow.org/example_images/flower_photos.tgz
包含 5 中类型的花,每种类型有600~900张图像不等。

训练集与测试集划分
由于此数据集不像 CIFAR10 那样下载时就划分好了训练集和测试集,因此需要自己划分。具体操作可以看b站那个up 的视频,这里不再赘述
AlexNet详解

重点关注它和上一个模型不一样的地方
1.首次用GPU进行加速训练,上图上下两部分是完全一样的,这是因为用了两块GPU加速训练
2.使用了Relu函数
3.用了Dropout随即失活部分神经元 以减少过拟合

具体网络分析:
Conv1

输入:224*224*3
卷积:11*11*3 48个
- padding = [1, 2] (左上围加半圈0,右下围加2倍的半圈0
- stride = 4
输出:(224-11+3)/4+1 = 55 55*55*48
Maxpool1

输入:55*55*48
池化层:
- kernel_size = 3
- padding = 0
- stride = 2
输出:(55-3)/2+1 = 27 27*27*48
Conv2

输入:27*27*48
卷积:5*5*48 128个
- padding = [2, 2]
- stride = 1
输出:(27-5+4)/1+1 = 27 27*27*128
Maxpool2

输入:27*27*128
- 池化层:(只改变尺寸,不改变深度channel)
- kernel_size = 3
- padding = 0
- stride = 2
输出:13*13*128
Conv3

输入:13*13*128
- 卷积层:
- 3*3 192个
- padding = [1, 1]
- stride = 1
输出:13*13*192
Conv4

输入:13*13*192
- 卷积层:
- 3*3 192个
- padding = [1, 1]
- stride = 1
输出: 13*13**192
Conv5

输入:13*13*192
- 卷积层:
- 3*3*128
- padding = [1, 1]
- stride = 1
输出:13*13*128
Maxpool3

输入:13*13*128
- 池化层:
- kernel_size = 3
- padding = 0
- stride = 2
输出:6*6*128
FC1、FC2、FC3
Maxpool3 → (6*6*256) → FC1 → 2048 → FC2 → 2048 → FC3 → 1000
总结

分析可以发现,除 Conv1 外,AlexNet 的其余卷积层都是在改变特征矩阵的深度,而池化层则只改变(减小)其尺寸。
构建模型;
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
# 用nn.Sequential()将网络打包成一个模块,精简代码
self.features = nn.Sequential( # 卷积层提取图像特征
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # 直接修改覆盖原值,节省运算内存
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential( # 全连接层对图像分类
nn.Dropout(p=0.5), # Dropout 随机失活神经元,默认比例为0.5
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
# 前向传播过程
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 展平后再传入全连接层
x = self.classifier(x)
return x
# 网络权重初始化,实际上 pytorch 在构建网络时会自动初始化权重
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d): # 若是卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', # 用(何)kaiming_normal_法初始化权重
nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 初始化偏重为0
elif isinstance(m, nn.Linear): # 若是全连接层
nn.init.normal_(m.weight, 0, 0.01) # 正态分布初始化
nn.init.constant_(m.bias, 0) # 初始化偏重为0

Dropout : 发现都有具体的api 想具体研究的可以去看看它的函数是怎么写的
数据预处理 - 图像增强
需要注意的是,对训练集的预处理,多了随机裁剪和水平翻转这两个步骤。可以起到扩充数据集的作用,增强模型泛化能力
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}

训练:
import torch
from model import AlexNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# 预处理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("蒲公英.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = AlexNet(num_classes=5)
# load model weights
model_weight_path = "./AlexNet.pth"
model.load_state_dict(torch.load(model_weight_path))
# 关闭 Dropout
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 将输出压缩,即压缩掉 batch 这个维度
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].item())
plt.show()
预测:
import torch
from model import AlexNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# 预处理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("蒲公英.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = AlexNet(num_classes=5)
# load model weights
model_weight_path = "./AlexNet.pth"
model.load_state_dict(torch.load(model_weight_path))
# 关闭 Dropout
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 将输出压缩,即压缩掉 batch 这个维度
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)], predict[predict_cla].item())
plt.show()
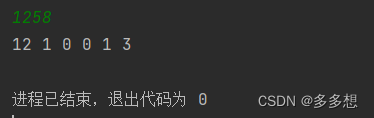
打印出预测的标签以及概率值:
dandelion 0.7221569418907166