接上篇《44、Scrapy的基本介绍和安装》
上一篇我们学习了Scrapy框架的基础介绍以及环境的搭建,本篇我们来学习一下Scrapy框架的核心组件的使用。
下面的核心组件的介绍,仍是基于这幅图的机制,大家可以再回顾一下:
注:图片来自[寻_觅]博主
一、Item定义与处理
1.1 Item的概述
在Scrapy框架中,Item是数据的主要载体,用于存储Spider从网页爬取的数据。Item定义了数据的结构,并通过Item Loader对爬取到的数据进行加载和清洗。
1.2 Item的定义
Item使用Python类来定义,通常继承自scrapy.item.Item基础类。通过定义Item类,我们可以明确数据的结构,如字段、类型等。例如:
import scrapy
class MyprojectItem(scrapy.Item):
link = scrapy.Field() # 字段名,数据类型默认为str
description = scrapy.Field() # 字段名,数据类型默认为str1.3 Item的处理
Item的处理主要涉及两个部分:Item Loader和Pipeline。Item Loader用于加载和清洗数据,Pipeline则负责数据的持久化存储。
Item Loader:Item Loader是用于加载和清洗数据的组件。通过使用Item Loader,我们可以对爬取到的数据进行预处理,如删除不需要的空白字符、转换数据类型等。使用Item Loader需要定义Loader类,并指定需要加载的字段。例如新建一个MySpider定义一个ItemLoader对象:
import scrapy
from scrapy.loader import ItemLoader
from ..items import MyprojectItem
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
loader = ItemLoader(item=MyprojectItem(), response=response)
# 使用XPath选择器选择<h1>标签中的内容作为标题。
loader.add_xpath('title', '//h1/text()')
# 使用CSS选择器选择class为content的元素中的内容作为内容。
loader.add_css('content', '.content')
return loader.load_item()而Pipeline负责数据的持久化存储,如将爬取到的数据存储到数据库、文件等,我们在下面的小结详细讲解。
二、Spider爬虫定义与使用
2.1 Spider的概述
Spider是Scrapy框架中用于爬取网页数据的组件。Spider通过模拟浏览器行为,自动解析网页结构,提取所需的数据,并将其封装为Item对象。
2.2 Spider的编写
编写Spider需要继承scrapy.Spider基础类,并实现以下方法:
●name:Spider的唯一标识符,用于在Scrapy项目中区分不同的Spider。
●start_urls:爬取的起始URL列表。Scrapy会从这些URL开始爬取数据。
●parse():用于解析单个网页的回调函数。该函数将接收一个Response对象作为参数,并返回一个Item对象或一个Item生成器。
例如,以下是一个简单的Spider,用于爬取网站上的所有链接:
import scrapy
from ..items import MyprojectItem
class BaiduUrlSpider(scrapy.Spider):
name = "baidu_url"
allowed_domains = ["www.baidu.com"]
start_urls = ["https://www.baidu.com"]
def parse(self, response):
# 抓取所有的链接
for link in response.css('a::attr(href)').getall():
if "http" in link or "https" in link:
print("link: ", link) # 打印出来抓取的链接地址
item = MyprojectItem(link=link, description='test')
yield item # 把数据交给管道 piplines.py 进行数据的下载2.3 Spider的使用
在Scrapy项目中,可以通过运行Scrapy命令来启动Spider:
●运行scrapy crawl <spider_name>命令,其中<spider_name>是Spider的名称。该命令将启动指定的Spider,并开始爬取数据。
●可以使用-o选项指定输出的文件名,例如scrapy crawl myspider -o output.csv将爬取的数据输出到output.csv文件中。
●可以使用-t选项指定输出数据的格式,例如scrapy crawl myspider -t csv将输出CSV格式的数据。
三、Pipeline数据处理管道
3.1 Pipeline的概述
Pipeline是Scrapy框架中负责处理已爬取数据的组件。它负责将爬取到的数据从Spider传递到最终的存储位置,并在传递过程中对数据进行清洗、验证和持久化。
3.2 Pipeline的工作流程
Pipeline的工作流程如下:
(1)Spider爬取数据完成后,将Item对象传递给Pipeline。
(2)Pipeline接收到Item对象后,会按照设定的顺序逐一进行处理。每个Pipeline都有一个唯一的优先级,优先级高的Pipeline会先于优先级低的Pipeline进行处理。
(3)在Pipeline中,可以对Item对象进行各种处理,如清洗数据、验证数据、持久化存储等。
(4)处理完成后,Pipeline将Item对象返回给Engine。
(5)Engine将Item对象传递给下一个Pipeline进行处理,或者将其传递给最终的存储位置。
3.3 自定义Pipeline
在Scrapy框架中,我们可以自定义Pipeline来满足特定的数据处理需求。要自定义Pipeline,需要创建一个Python类,并实现process_item()方法。process_item()方法接受一个Item对象作为参数,并返回一个Item对象。例如,我们可以创建一个将Item对象存储到CSV文件的Pipeline:
在settings.py中启用Pipeline:
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
创建Pipeline类,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
from scrapy.exporters import CsvItemExporter
import json # 需要导入的
from collections import OrderedDict # 需要导入的
class MyPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
self.file = open('news_data1.csv', 'wb')
self.exporter = CsvItemExporter(self.file, encoding='gbk')
self.exporter.start_exporting()
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
print('默认的字段数据:{}\n'.format(item))
item = OrderedDict(item)
item = json.dumps(item, ensure_ascii=False)
print('调整后的字段数据:{}\n'.format(item))
self.exporter.export_item(eval(item))
return item # 返回一个Item对象,该对象将被持久化存储到CSV文件
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
pass
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
self.exporter.finish_exporting()
self.file.close()四、Scheduler调度器
4.1 Scheduler的概述
Scheduler是Scrapy框架中的调度器组件,负责管理爬取任务的队列。它根据一定的优先级和规则,将爬取请求放入队列中,并按照顺序执行。
4.2 Scheduler的工作原理
Scheduler的工作原理如下:
(1)Spider爬取完一个网页后,将生成的请求(Request)对象传递给Scheduler。
(2)Scheduler根据请求的优先级、规则等因素,将其放入内部的队列中。
(3)Engine启动后,会定期从Scheduler中获取请求,并将其传递给下载器进行下载。
(4)下载完成后,Engine将下载的响应(Response)对象传递给Scheduler。
(5)Scheduler将响应对象传递给相应的Spider进行处理。
4.3 Scheduler的配置
在Scrapy项目的settings.py文件中,可以通过设置以下参数来配置Scheduler的行为:
●SCHEDULER:用于指定使用的Scheduler类。Scrapy框架提供了多种Scheduler的实现,如DumbScheduler、SqlalchemyScheduler等。可以根据需求选择合适的Scheduler。
●SCHEDULER_QUEUE_CLASS:用于指定请求队列的实现方式。Scrapy框架提供了多种队列的实现,如PriorityQueue、FifoQueue等。可以根据需求选择合适的队列。
●SCHEDULER_QUEUE_URL:用于指定请求队列的持久化存储方式。可以使用Redis、RabbitMQ等消息队列服务作为存储后端。
●SCHEDULER_PERSIST:用于指定是否启用请求队列的持久化存储。设置为True时,请求队列将在爬虫重启后继续存在,避免重复爬取。
4.4 自定义Scheduler
如果默认的Scheduler不能满足需求,我们可以自定义Scheduler来实现特定的调度逻辑。要自定义Scheduler,需要创建一个Python类,并实现以下方法:
●enqueue_request(request):将请求加入队列中。该方法需要返回一个布尔值,表示请求是否成功加入队列。
●dequeued_request():从队列中获取请求。该方法需要返回一个请求对象。
●has_pending_requests():检查队列中是否有待处理的请求。该方法需要返回一个布尔值。
●stats:返回调度器的统计信息。该方法需要返回一个字典,包含调度器的各种统计数据。
五、Downloader下载器
5.1 Downloader的概述
Downloader是Scrapy框架中负责下载网页数据的组件。它接收Engine传递的下载请求(Request),并发送HTTP请求到目标网站,获取网页的响应(Response)数据,并将其返回给Engine。
5.2 Downloader的工作流程
Downloader的工作流程如下:
(1)Engine将下载请求(Request)对象传递给Downloader。
(2)Downloader根据请求的URL、方法、头信息等,构建HTTP请求。
(3)Downloader发送HTTP请求到目标网站,并等待响应。
(4)一旦收到响应,Downloader将响应数据封装为Response对象,并将其返回给Engine。
(5)Engine将Response对象传递给相应的Spider进行处理。
5.3 Downloader的配置
在Scrapy项目的settings.py文件中,可以通过设置以下参数来配置Downloader的行为:
●DOWNLOADER:用于指定使用的Downloader类。Scrapy框架默认使用scrapy.core.downloader.handlers.http.HTTPDownloader作为Downloader的实现。
●DOWNLOAD_DELAY:用于设置下载器在连续下载请求之间的延迟时间(秒)。这可以避免对目标网站造成过大的访问压力。
●DOWNLOAD_TIMEOUT:用于设置下载请求的超时时间(秒)。如果请求在超时时间内没有响应,Downloader将引发超时异常。
●DOWNLOADER_MIDDLEWARES:用于指定使用的Downloader中间件列表。Downloader中间件可以对下载请求和响应进行预处理和后处理,例如添加代理、处理重定向等。
●DOWNLOADER_MIDDLEWARES_BASE:Scrapy框架提供的默认Downloader中间件列表。可以在自定义的Downloader中间件中继承或覆盖默认的中间件。
5.4 自定义Downloader
如果默认的Downloader不能满足需求,我们可以自定义Downloader来实现特定的下载逻辑。要自定义Downloader,需要创建一个Python类,并实现以下方法:
●fetch(request, spider):用于处理下载请求。该方法需要接收一个Request对象和一个Spider对象作为参数,并返回一个包含响应数据的Response对象。在该方法中,可以使用Python标准库中的HTTP客户端库(如urllib、requests等)来发送HTTP请求,并获取响应数据。
●close():用于在Downloader关闭时进行清理操作。该方法可选,可以根据需要进行实现。
通过自定义Downloader,我们可以实现更复杂的下载逻辑,例如使用代理、处理验证码、处理动态加载等。
六、Engine引擎
6.1 Engine的概述
Engine是Scrapy框架的核心组件,负责协调和控制整个爬取过程。它管理着Spider、Scheduler、Downloader和Pipeline等组件,确保它们按照正确的顺序和逻辑进行工作。
6.2 Engine的工作流程
Engine的工作流程如下:
(1)初始化Engine,并加载Scrapy项目的配置。
(2)加载并启动Spider,将Spider的起始URL传递给Scheduler。
(3)从Scheduler中获取下一个要爬取的请求(Request)。
(3)将请求传递给Downloader进行下载。
(4)等待Downloader返回响应(Response)。
(5)将响应传递给相应的Spider进行处理。
(6)Spider解析响应数据,提取所需的信息,并生成新的请求或Item对象。
(7)将新生成的请求传递给Scheduler进行调度。
(8)将生成的Item对象传递给Pipeline进行处理。
(9)重复步骤3-9,直到Scheduler中没有更多的请求或满足停止条件。
(10)关闭Engine,释放资源。
6.3 Engine的配置
在Scrapy项目的settings.py文件中,可以通过设置以下参数来配置Engine的行为:
●CONCURRENT_REQUESTS:用于设置同时进行的下载请求数量。该参数可以控制并发度,即Downloader同时处理的请求数量。
●CONCURRENT_REQUESTS_PER_DOMAIN:用于设置每个域名同时进行的下载请求数量。该参数可以限制对同一网站的并发访问量,避免对目标网站造成过大的访问压力。
●CONCURRENT_REQUESTS_PER_IP:用于设置每个IP地址同时进行的下载请求数量。该参数可以进一步细化对并发访问量的控制,限制对同一IP地址的请求频率。
●DOWNLOAD_TIMEOUT:用于设置下载请求的超时时间(秒)。如果请求在超时时间内没有响应,Engine将引发超时异常。
●ENGINE_STOPPER:用于指定Engine的停止条件。可以自定义一个类,并实现should_stop()方法来判断是否满足停止条件。
6.4 自定义Engine
在Scrapy框架中,一般情况下不需要自定义Engine,因为Engine的核心功能已经由框架提供,并且可以通过配置参数进行调整。但是,如果需要实现特殊的爬取逻辑或集成其他功能,可以通过继承Scrapy的Engine类来自定义Engine。自定义Engine时,可以重写start()和stop()方法来实现自定义的启动和停止逻辑,也可以重写其他方法来扩展Engine的功能。需要注意的是,自定义Engine需要熟悉Scrapy框架的内部工作原理和各个组件之间的交互方式。
七、Logging日志系统
7.1 日志系统的概述
日志系统是Scrapy框架中用于记录和跟踪爬虫运行信息的组件。通过日志系统,我们可以方便地查看爬虫的运行状态、调试问题、监控异常等。
7.2 日志级别的概念
Scrapy的日志系统使用Python的标准库logging模块实现,支持多种日志级别,包括:
●DEBUG:详细信息,用于开发和调试阶段。
●INFO:一般信息,用于了解爬虫的运行情况。
●WARNING:警告信息,用于指出可能的问题或异常。
●ERROR:错误信息,用于记录发生的错误。
●CRITICAL:严重错误,用于记录严重的问题或异常。
7.3 日志配置
在Scrapy项目的settings.py文件中,可以通过设置以下参数来配置日志系统的行为:
●LOG_LEVEL:用于设置日志级别。可选值包括DEBUG、INFO、WARNING、ERROR、CRITICAL。默认级别为WARNING。
●LOG_FILE:用于指定日志文件的路径。如果设置了这个参数,日志将输出到指定的文件中。
●LOG_ENABLED:用于启用或禁用日志功能。设置为True时,启用日志功能;设置为False时,禁用日志功能。默认值为True。
●LOG_STDOUT:用于将日志输出到标准输出(stdout)。设置为True时,将日志输出到控制台;设置为False时,不输出到控制台。默认值为False。
●LOG_FORMAT:用于设置日志的格式。格式化字符串可以根据需要自行定制,支持%levelname、%message等占位符。
7.4 自定义日志处理程序
如果默认的日志处理程序不能满足需求,我们可以自定义一个处理程序来自定义日志的行为。要自定义日志处理程序,需要创建一个Python类,并实现以下方法:
●__init__(self, logger, log_level, log_format):初始化方法,接收一个logger对象、一个log_level参数和一个log_format参数。
●handle(self, record):处理日志记录的方法。该方法接收一个Record对象作为参数,并返回一个处理后的日志记录对象。可以对该方法进行重写,实现自定义的日志处理逻辑。
通过自定义日志处理程序,我们可以对日志进行更详细的处理和定制化输出,例如将日志发送到远程服务器、将日志写入数据库等。
八、测试
刚刚上面定义的item、itemloder、spiders、pipelines跑一下试试:
在控制台输入:scrapy crawl baidu_url,效果(日志LOG_LEVEL = "ERROR"):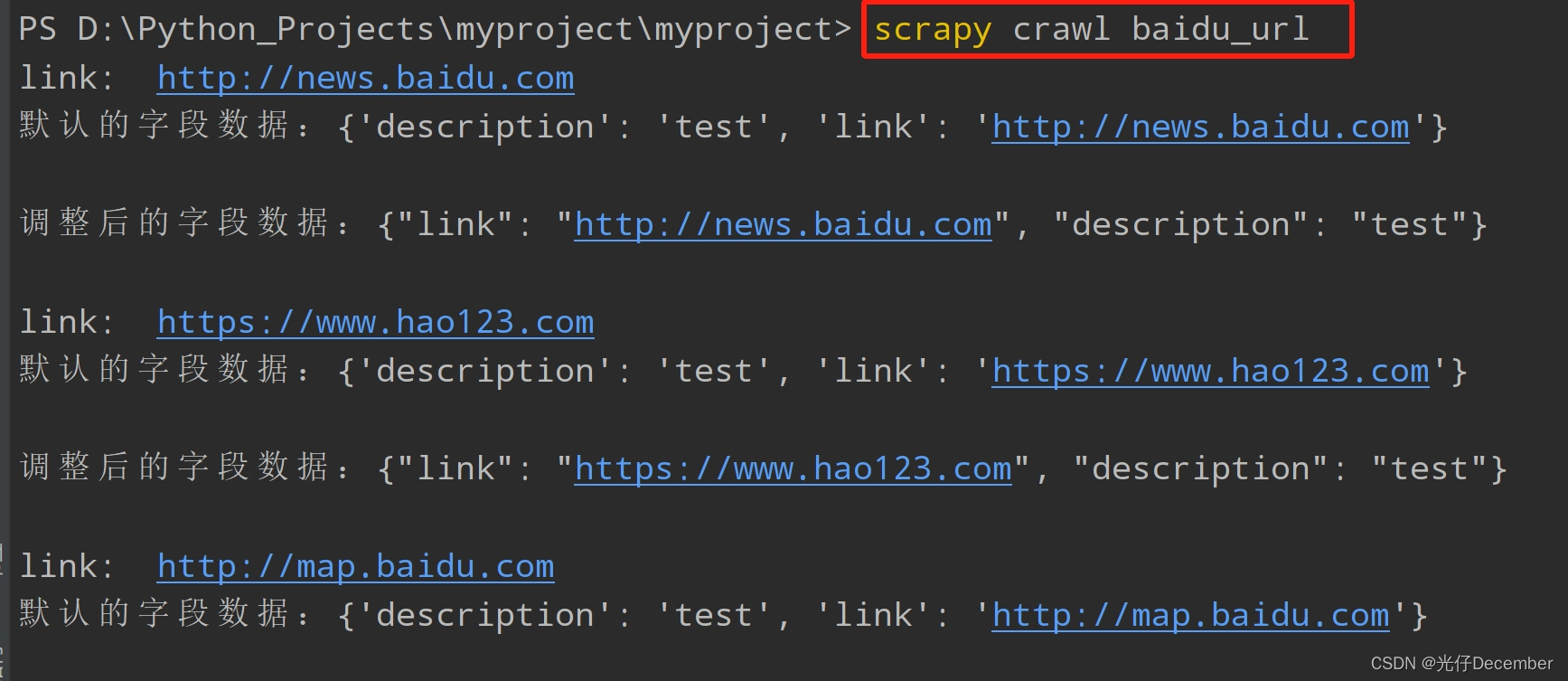
下载的csv文件内容: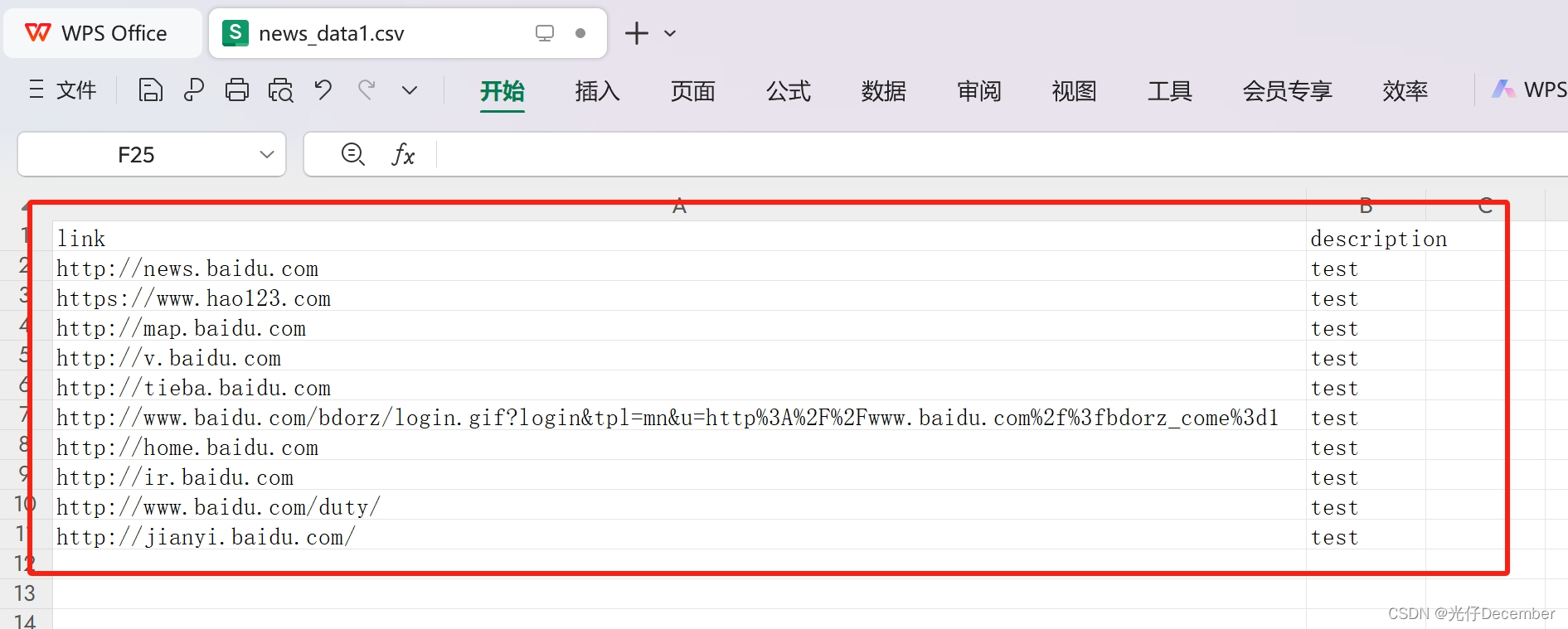
成功的获取了百度首页的所有链接信息。
至此,我们对Scrapy框架的核心组件介绍就完毕了。下一篇我们以58同城网站抓取为样例,写一个实际案例来训练Scrapy框架的使用。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/135187400