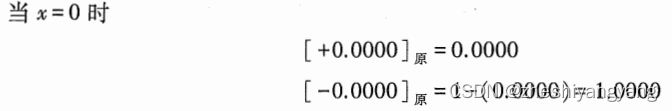本文基于Kubernetes v1.22.4版本进行源码学习
4、kubelet创建Pod流程
syncLoop()的主要逻辑是在syncLoopIteration()方法中实现,Pod创建相关代码只需要看处理configCh部分的代码
// pkg/kubelet/kubelet.go
// 该方法会监听多个channel,当发现任何一个channel有数据就交给handler去处理,在handler中通过调用dispatchWork分发任务
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// 该模块将同时watch 3个不同来源的pod信息的变化(file,http,apiServer)
// 一旦某个来源的pod信息发生了变化(创建/更新/删除),这个channel中就会出现被更新的pod信息和更新的具体操作
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.ErrorS(nil, "Update channel is closed, exiting the sync loop")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).InfoS("SyncLoop ADD", "source", u.Source, "pods", format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).InfoS("SyncLoop UPDATE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).InfoS("SyncLoop REMOVE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).InfoS("SyncLoop RECONCILE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).InfoS("SyncLoop DELETE", "source", u.Source, "pods", format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.ErrorS(nil, "Kubelet does not support snapshot update")
default:
klog.ErrorS(nil, "Invalid operation type received", "operation", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
...
}
return true
}
调用HandlePodAdditions()方法执行创建Pod,该方法代码如下:
// pkg/kubelet/kubelet.go
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
// 把所有的pod按照创建时间排序,保证最先创建的pod会最先被处理
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
// 把pod添加到podManager中,podManager负责管理这台node上的pod的信息,
// pod和mirrorPod之间的对应关系等等.所有被管理的pod都保存在podManager中,
// 如果podManager中找不到某个pod,就认为这个pod被删除了
kl.podManager.AddPod(pod)
if kubetypes.IsMirrorPod(pod) {
// 如果是mirrorPod,调用其单独的方法
kl.handleMirrorPod(pod, start)
continue
}
// Only go through the admission process if the pod is not requested
// for termination by another part of the kubelet. If the pod is already
// using resources (previously admitted), the pod worker is going to be
// shutting it down. If the pod hasn't started yet, we know that when
// the pod worker is invoked it will also avoid setting up the pod, so
// we simply avoid doing any work.
// 如果该pod没有被terminate
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
// 获取active状态的pod
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
// 校验pod是否能在该节点运行,如果不可以直接拒绝
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
// 调用dispatchWork把创建pod的工作下发给worker做异步处理
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
// TODO: move inside syncPod and make reentrant
// https://github.com/kubernetes/kubernetes/issues/105014
// 在probeManager中添加pod,如果pod中定义了readiness和liveness健康检查,启动goroutine定期进行检测
kl.probeManager.AddPod(pod)
}
}
HandlePodAdditions()方法主要逻辑如下:
- 把所有的Pod按照创建时间排序,保证最先创建的Pod会最先被处理
- 把Pod加入到podManager中,如果podManager中找不到某个Pod,就认为这个Pod被删除了
- 校验Pod是否能在该节点运行,如果不可以直接拒绝
- 调用
dispatchWork()方法把创建Pod的工作下发给worker做异步处理 - 在probeManager中添加Pod,如果Pod中定义了readiness和liveness健康检查,启动goroutine定期进行检测
// pkg/kubelet/kubelet.go
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// Run the sync in an async worker.
// 封装一个UpdatePodOptions结构体丢给podWorkers.UpdatePod去执行
kl.podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
StartTime: start,
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}
dispatchWork()方法中封装一个UpdatePodOptions结构体丢给podWorkers.UpdatePod()去执行
另外,syncLoopIteration()中对Pod进行增删改操作,最终都会调用dispatchWork()方法上
由于kubelet创建Pod路径太深,这里直接忽略下面的路径,跳到syncPod()方法中
podWorkers.UpdatePod -> podWorkers.managePodLoop -> podWorkers.syncPodFn -> Kubelet.syncPod
1)、syncPod()
// pkg/kubelet/kubelet.go
func (kl *Kubelet) syncPod(ctx context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) error {
klog.V(4).InfoS("syncPod enter", "pod", klog.KObj(pod), "podUID", pod.UID)
defer klog.V(4).InfoS("syncPod exit", "pod", klog.KObj(pod), "podUID", pod.UID)
// Latency measurements for the main workflow are relative to the
// first time the pod was seen by the API server.
var firstSeenTime time.Time
if firstSeenTimeStr, ok := pod.Annotations[kubetypes.ConfigFirstSeenAnnotationKey]; ok {
firstSeenTime = kubetypes.ConvertToTimestamp(firstSeenTimeStr).Get()
}
// Record pod worker start latency if being created
// TODO: make pod workers record their own latencies
if updateType == kubetypes.SyncPodCreate {
if !firstSeenTime.IsZero() {
// This is the first time we are syncing the pod. Record the latency
// since kubelet first saw the pod if firstSeenTime is set.
metrics.PodWorkerStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
} else {
klog.V(3).InfoS("First seen time not recorded for pod",
"podUID", pod.UID,
"pod", klog.KObj(pod))
}
}
// Generate final API pod status with pod and status manager status
apiPodStatus := kl.generateAPIPodStatus(pod, podStatus)
// The pod IP may be changed in generateAPIPodStatus if the pod is using host network. (See #24576)
// TODO(random-liu): After writing pod spec into container labels, check whether pod is using host network, and
// set pod IP to hostIP directly in runtime.GetPodStatus
podStatus.IPs = make([]string, 0, len(apiPodStatus.PodIPs))
for _, ipInfo := range apiPodStatus.PodIPs {
podStatus.IPs = append(podStatus.IPs, ipInfo.IP)
}
if len(podStatus.IPs) == 0 && len(apiPodStatus.PodIP) > 0 {
podStatus.IPs = []string{apiPodStatus.PodIP}
}
// If the pod should not be running, we request the pod's containers be stopped. This is not the same
// as termination (we want to stop the pod, but potentially restart it later if soft admission allows
// it later). Set the status and phase appropriately
// 校验该pod能否运行
runnable := kl.canRunPod(pod)
if !runnable.Admit {
// Pod is not runnable; and update the Pod and Container statuses to why.
// 如果不能运行,回写container的等待原因
if apiPodStatus.Phase != v1.PodFailed && apiPodStatus.Phase != v1.PodSucceeded {
apiPodStatus.Phase = v1.PodPending
}
apiPodStatus.Reason = runnable.Reason
apiPodStatus.Message = runnable.Message
// Waiting containers are not creating.
const waitingReason = "Blocked"
for _, cs := range apiPodStatus.InitContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
for _, cs := range apiPodStatus.ContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
}
// Record the time it takes for the pod to become running.
existingStatus, ok := kl.statusManager.GetPodStatus(pod.UID)
if !ok || existingStatus.Phase == v1.PodPending && apiPodStatus.Phase == v1.PodRunning &&
!firstSeenTime.IsZero() {
metrics.PodStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
}
// 更新状态管理器中的状态
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// Pods that are not runnable must be stopped - return a typed error to the pod worker
// 如果校验没通过,那么kill掉pod
if !runnable.Admit {
klog.V(2).InfoS("Pod is not runnable and must have running containers stopped", "pod", klog.KObj(pod), "podUID", pod.UID, "message", runnable.Message)
var syncErr error
p := kubecontainer.ConvertPodStatusToRunningPod(kl.getRuntime().Type(), podStatus)
if err := kl.killPod(pod, p, nil); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
// There was no error killing the pod, but the pod cannot be run.
// Return an error to signal that the sync loop should back off.
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
return syncErr
}
// If the network plugin is not ready, only start the pod if it uses the host network
// 校验网络插件是否已准备好
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
// Create Cgroups for the pod and apply resource parameters
// to them if cgroups-per-qos flag is enabled.
pcm := kl.containerManager.NewPodContainerManager()
// If pod has already been terminated then we need not create
// or update the pod's cgroup
// TODO: once context cancellation is added this check can be removed
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
// When the kubelet is restarted with the cgroups-per-qos
// flag enabled, all the pod's running containers
// should be killed intermittently and brought back up
// under the qos cgroup hierarchy.
// Check if this is the pod's first sync
// 校验该pod是否首次创建
firstSync := true
for _, containerStatus := range apiPodStatus.ContainerStatuses {
if containerStatus.State.Running != nil {
firstSync = false
break
}
}
// Don't kill containers in pod if pod's cgroups already
// exists or the pod is running for the first time
// 如果该pod的cgroups不存在,并且不是首次启动,那么kill掉
podKilled := false
if !pcm.Exists(pod) && !firstSync {
p := kubecontainer.ConvertPodStatusToRunningPod(kl.getRuntime().Type(), podStatus)
if err := kl.killPod(pod, p, nil); err == nil {
podKilled = true
} else {
klog.ErrorS(err, "KillPod failed", "pod", klog.KObj(pod), "podStatus", podStatus)
}
}
// Create and Update pod's Cgroups
// Don't create cgroups for run once pod if it was killed above
// The current policy is not to restart the run once pods when
// the kubelet is restarted with the new flag as run once pods are
// expected to run only once and if the kubelet is restarted then
// they are not expected to run again.
// We don't create and apply updates to cgroup if its a run once pod and was killed above
// 如果该pod在上面没有被kill掉,或重启策略不是永不重启
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
// 如果该pod的cgroups不存在,那么就创建cgroups
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).InfoS("Failed to update QoS cgroups while syncing pod", "pod", klog.KObj(pod), "err", err)
}
if err := pcm.EnsureExists(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToCreatePodContainer, "unable to ensure pod container exists: %v", err)
return fmt.Errorf("failed to ensure that the pod: %v cgroups exist and are correctly applied: %v", pod.UID, err)
}
}
}
}
// Create Mirror Pod for Static Pod if it doesn't already exist
// 为静态pod创建mirror pod
if kubetypes.IsStaticPod(pod) {
deleted := false
if mirrorPod != nil {
if mirrorPod.DeletionTimestamp != nil || !kl.podManager.IsMirrorPodOf(mirrorPod, pod) {
// The mirror pod is semantically different from the static pod. Remove
// it. The mirror pod will get recreated later.
klog.InfoS("Trying to delete pod", "pod", klog.KObj(pod), "podUID", mirrorPod.ObjectMeta.UID)
podFullName := kubecontainer.GetPodFullName(pod)
var err error
deleted, err = kl.podManager.DeleteMirrorPod(podFullName, &mirrorPod.ObjectMeta.UID)
if deleted {
klog.InfoS("Deleted mirror pod because it is outdated", "pod", klog.KObj(mirrorPod))
} else if err != nil {
klog.ErrorS(err, "Failed deleting mirror pod", "pod", klog.KObj(mirrorPod))
}
}
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).InfoS("No need to create a mirror pod, since node has been removed from the cluster", "node", klog.KRef("", string(kl.nodeName)))
} else {
klog.V(4).InfoS("Creating a mirror pod for static pod", "pod", klog.KObj(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.ErrorS(err, "Failed creating a mirror pod for", "pod", klog.KObj(pod))
}
}
}
}
// Make data directories for the pod
// 创建pod数据目录
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.ErrorS(err, "Unable to make pod data directories for pod", "pod", klog.KObj(pod))
return err
}
// Volume manager will not mount volumes for terminating pods
// TODO: once context cancellation is added this check can be removed
// 如果该pod没有被终止,那么需要等待attach/mount volumes
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.ErrorS(err, "Unable to attach or mount volumes for pod; skipping pod", "pod", klog.KObj(pod))
return err
}
}
// Fetch the pull secrets for the pod
// 为pod拉取secrets配置
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
// 真正的容器创建逻辑
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}
syncPod()方法为创建Pod做一些准备工作,主要准备工作如下:
- 校验该Pod能否运行,如果不能运行,那么回写container的等待原因,然后更新状态管理器中的状态
- 如果校验没通过,那么kill掉Pod,然后返回
- 校验网络插件是否已准备好,如果没有,直接返回
- 如果该Pod的cgroups不存在,那么就创建cgroups
- 创建Pod数据目录,等待attach/mount volumes
- 拉取这个Pod的secrets配置
- 调用
kl.containerRuntime.SyncPod()真正创建Pod
2)、SyncPod()
// pkg/kubelet/kuberuntime/kuberuntime_manager.go
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
// 计算一下pod中哪些container有变化,哪些container需要创建,哪些container需要kill掉
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).InfoS("computePodActions got for pod", "podActions", podContainerChanges, "pod", klog.KObj(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.ErrorS(err, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf(ref, v1.EventTypeNormal, events.SandboxChanged, "Pod sandbox changed, it will be killed and re-created.")
} else {
klog.V(4).InfoS("SyncPod received new pod, will create a sandbox for it", "pod", klog.KObj(pod))
}
}
// Step 2: Kill the pod if the sandbox has changed.
// kill掉sandbox已经改变的pod
if podContainerChanges.KillPod {
if podContainerChanges.CreateSandbox {
klog.V(4).InfoS("Stopping PodSandbox for pod, will start new one", "pod", klog.KObj(pod))
} else {
klog.V(4).InfoS("Stopping PodSandbox for pod, because all other containers are dead", "pod", klog.KObj(pod))
}
// kill容器操作
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if killResult.Error() != nil {
klog.ErrorS(killResult.Error(), "killPodWithSyncResult failed")
return
}
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
// Step 3: kill any running containers in this pod which are not to keep.
// kill掉containersToKill列表中的container
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
klog.V(3).InfoS("Killing unwanted container for pod", "containerName", containerInfo.name, "containerID", containerID, "pod", klog.KObj(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, containerInfo.reason, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.ErrorS(err, "killContainer for pod failed", "containerName", containerInfo.name, "containerID", containerID, "pod", klog.KObj(pod))
return
}
}
}
// Keep terminated init containers fairly aggressively controlled
// This is an optimization because container removals are typically handled
// by container garbage collector.
// 清理同名的init container
m.pruneInitContainersBeforeStart(pod, podStatus)
// We pass the value of the PRIMARY podIP and list of podIPs down to
// generatePodSandboxConfig and generateContainerConfig, which in turn
// passes it to various other functions, in order to facilitate functionality
// that requires this value (hosts file and downward API) and avoid races determining
// the pod IP in cases where a container requires restart but the
// podIP isn't in the status manager yet. The list of podIPs is used to
// generate the hosts file.
//
// We default to the IPs in the passed-in pod status, and overwrite them if the
// sandbox needs to be (re)started.
var podIPs []string
if podStatus != nil {
podIPs = podStatus.IPs
}
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
klog.V(4).InfoS("Creating PodSandbox for pod", "pod", klog.KObj(pod))
metrics.StartedPodsTotal.Inc()
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
// 为pod创建sandbox
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
// createPodSandbox can return an error from CNI, CSI,
// or CRI if the Pod has been deleted while the POD is
// being created. If the pod has been deleted then it's
// not a real error.
//
// SyncPod can still be running when we get here, which
// means the PodWorker has not acked the deletion.
if m.podStateProvider.IsPodTerminationRequested(pod.UID) {
klog.V(4).InfoS("Pod was deleted and sandbox failed to be created", "pod", klog.KObj(pod), "podUID", pod.UID)
return
}
metrics.StartedPodsErrorsTotal.Inc()
createSandboxResult.Fail(kubecontainer.ErrCreatePodSandbox, msg)
klog.ErrorS(err, "CreatePodSandbox for pod failed", "pod", klog.KObj(pod))
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.ErrorS(referr, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedCreatePodSandBox, "Failed to create pod sandbox: %v", err)
return
}
klog.V(4).InfoS("Created PodSandbox for pod", "podSandboxID", podSandboxID, "pod", klog.KObj(pod))
podSandboxStatus, err := m.runtimeService.PodSandboxStatus(podSandboxID)
if err != nil {
ref, referr := ref.GetReference(legacyscheme.Scheme, pod)
if referr != nil {
klog.ErrorS(referr, "Couldn't make a ref to pod", "pod", klog.KObj(pod))
}
m.recorder.Eventf(ref, v1.EventTypeWarning, events.FailedStatusPodSandBox, "Unable to get pod sandbox status: %v", err)
klog.ErrorS(err, "Failed to get pod sandbox status; Skipping pod", "pod", klog.KObj(pod))
result.Fail(err)
return
}
// If we ever allow updating a pod from non-host-network to
// host-network, we may use a stale IP.
if !kubecontainer.IsHostNetworkPod(pod) {
// Overwrite the podIPs passed in the pod status, since we just started the pod sandbox.
podIPs = m.determinePodSandboxIPs(pod.Namespace, pod.Name, podSandboxStatus)
klog.V(4).InfoS("Determined the ip for pod after sandbox changed", "IPs", podIPs, "pod", klog.KObj(pod))
}
}
// the start containers routines depend on pod ip(as in primary pod ip)
// instead of trying to figure out if we have 0 < len(podIPs)
// everytime, we short circuit it here
podIP := ""
if len(podIPs) != 0 {
podIP = podIPs[0]
}
// Get podSandboxConfig for containers to start.
configPodSandboxResult := kubecontainer.NewSyncResult(kubecontainer.ConfigPodSandbox, podSandboxID)
result.AddSyncResult(configPodSandboxResult)
// 生成sandbox的config配置,如pod的dns、hostName、端口映射
podSandboxConfig, err := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
if err != nil {
message := fmt.Sprintf("GeneratePodSandboxConfig for pod %q failed: %v", format.Pod(pod), err)
klog.ErrorS(err, "GeneratePodSandboxConfig for pod failed", "pod", klog.KObj(pod))
configPodSandboxResult.Fail(kubecontainer.ErrConfigPodSandbox, message)
return
}
// Helper containing boilerplate common to starting all types of containers.
// typeName is a description used to describe this type of container in log messages,
// currently: "container", "init container" or "ephemeral container"
// metricLabel is the label used to describe this type of container in monitoring metrics.
// currently: "container", "init_container" or "ephemeral_container"
start := func(typeName, metricLabel string, spec *startSpec) error {
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, spec.container.Name)
result.AddSyncResult(startContainerResult)
isInBackOff, msg, err := m.doBackOff(pod, spec.container, podStatus, backOff)
if isInBackOff {
startContainerResult.Fail(err, msg)
klog.V(4).InfoS("Backing Off restarting container in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod))
return err
}
metrics.StartedContainersTotal.WithLabelValues(metricLabel).Inc()
klog.V(4).InfoS("Creating container in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod))
// NOTE (aramase) podIPs are populated for single stack and dual stack clusters. Send only podIPs.
// 启动容器
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, spec, pod, podStatus, pullSecrets, podIP, podIPs); err != nil {
// startContainer() returns well-defined error codes that have reasonable cardinality for metrics and are
// useful to cluster administrators to distinguish "server errors" from "user errors".
metrics.StartedContainersErrorsTotal.WithLabelValues(metricLabel, err.Error()).Inc()
startContainerResult.Fail(err, msg)
// known errors that are logged in other places are logged at higher levels here to avoid
// repetitive log spam
switch {
case err == images.ErrImagePullBackOff:
klog.V(3).InfoS("Container start failed in pod", "containerType", typeName, "container", spec.container, "pod", klog.KObj(pod), "containerMessage", msg, "err", err)
default:
utilruntime.HandleError(fmt.Errorf("%v %+v start failed in pod %v: %v: %s", typeName, spec.container, format.Pod(pod), err, msg))
}
return err
}
return nil
}
// Step 5: start ephemeral containers
// These are started "prior" to init containers to allow running ephemeral containers even when there
// are errors starting an init container. In practice init containers will start first since ephemeral
// containers cannot be specified on pod creation.
// 临时容器相关
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", metrics.EphemeralContainer, ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
}
// Step 6: start the init container.
// 启动init container
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
if err := start("init container", metrics.InitContainer, containerStartSpec(container)); err != nil {
return
}
// Successfully started the container; clear the entry in the failure
klog.V(4).InfoS("Completed init container for pod", "containerName", container.Name, "pod", klog.KObj(pod))
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
// 启动container列表
for _, idx := range podContainerChanges.ContainersToStart {
start("container", metrics.Container, containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
SyncPod()方法主要逻辑如下:
- 首先调用
computePodActions()方法计算一下Pod中哪些container有变化,哪些container需要创建,哪些container需要kill掉 - kill掉sandbox已经改变的Pod
- 调用
killContainer()方法kill掉containersToKill列表中的container - 调用
pruneInitContainersBeforeStart()方法清理同名的init container - 调用
createPodSandbox()方法,创建需要被创建的Sandbox - 获取NextInitContainerToStart中的container,调用
startContainer()方法启动init container - 获取ContainersToStart中的container,调用
startContainer()方法container
4)、computePodActions()
// pkg/kubelet/kuberuntime/kuberuntime_manager.go
func (m *kubeGenericRuntimeManager) computePodActions(pod *v1.Pod, podStatus *kubecontainer.PodStatus) podActions {
klog.V(5).InfoS("Syncing Pod", "pod", klog.KObj(pod))
// 获取到pod sandbox的变化
createPodSandbox, attempt, sandboxID := m.podSandboxChanged(pod, podStatus)
changes := podActions{
KillPod: createPodSandbox,
CreateSandbox: createPodSandbox,
SandboxID: sandboxID,
Attempt: attempt,
ContainersToStart: []int{},
ContainersToKill: make(map[kubecontainer.ContainerID]containerToKillInfo),
}
// If we need to (re-)create the pod sandbox, everything will need to be
// killed and recreated, and init containers should be purged.
// 如果需要创建sandbox,那init container和其他container需要kill掉重新创建
if createPodSandbox {
if !shouldRestartOnFailure(pod) && attempt != 0 && len(podStatus.ContainerStatuses) != 0 {
// Should not restart the pod, just return.
// we should not create a sandbox for a pod if it is already done.
// if all containers are done and should not be started, there is no need to create a new sandbox.
// this stops confusing logs on pods whose containers all have exit codes, but we recreate a sandbox before terminating it.
//
// If ContainerStatuses is empty, we assume that we've never
// successfully created any containers. In this case, we should
// retry creating the sandbox.
// 如果所有的container都已完成且设置的不重启,那么不应该创建一个新的sandbox
// 如果containerStatuses是空的,那么可以认定从没有成功创建过container,所以应该创建sandbox
changes.CreateSandbox = false
return changes
}
// Get the containers to start, excluding the ones that succeeded if RestartPolicy is OnFailure.
var containersToStart []int
// 将所有container加入到需要启动的队列中,除了已启动成功且重启策略为OnFailure的pod
for idx, c := range pod.Spec.Containers {
if pod.Spec.RestartPolicy == v1.RestartPolicyOnFailure && containerSucceeded(&c, podStatus) {
continue
}
containersToStart = append(containersToStart, idx)
}
// We should not create a sandbox for a Pod if initialization is done and there is no container to start.
// 如果没有需要启动的container,且init container执行完成,那也不需要新建sandbox
if len(containersToStart) == 0 {
_, _, done := findNextInitContainerToRun(pod, podStatus)
if done {
changes.CreateSandbox = false
return changes
}
}
// 如果init container不为空,那么将init container中的第一个设置成下一个启动的init container
if len(pod.Spec.InitContainers) != 0 {
// Pod has init containers, return the first one.
changes.NextInitContainerToStart = &pod.Spec.InitContainers[0]
return changes
}
// 如果没有init container,则启动普通的容器
changes.ContainersToStart = containersToStart
return changes
}
// Ephemeral containers may be started even if initialization is not yet complete.
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for i := range pod.Spec.EphemeralContainers {
c := (*v1.Container)(&pod.Spec.EphemeralContainers[i].EphemeralContainerCommon)
// Ephemeral Containers are never restarted
if podStatus.FindContainerStatusByName(c.Name) == nil {
changes.EphemeralContainersToStart = append(changes.EphemeralContainersToStart, i)
}
}
}
// Check initialization progress.
// 获取下一个要运行的init container
initLastStatus, next, done := findNextInitContainerToRun(pod, podStatus)
// 如果init container没有执行完,则先启动init container
if !done {
// 如果有下一个init container要启动
if next != nil {
// 如果initLastStatus不为空且isInitContainerFailed返回true代表init container启动失败
initFailed := initLastStatus != nil && isInitContainerFailed(initLastStatus)
// 如果init container启动失败并且重启策略不是用不重启,则KillPod=true,也就是init container启动失败了删除整个pod的容器(sandbox容器也会被删除)
if initFailed && !shouldRestartOnFailure(pod) {
changes.KillPod = true
} else {
// Always try to stop containers in unknown state first.
if initLastStatus != nil && initLastStatus.State == kubecontainer.ContainerStateUnknown {
changes.ContainersToKill[initLastStatus.ID] = containerToKillInfo{
name: next.Name,
container: next,
message: fmt.Sprintf("Init container is in %q state, try killing it before restart",
initLastStatus.State),
reason: reasonUnknown,
}
}
// 设置下一个要启动的init container为next
changes.NextInitContainerToStart = next
}
}
// Initialization failed or still in progress. Skip inspecting non-init
// containers.
// 如果init container没全部执行完成,但是没有下一个init要执行,则代表当前init container正在running,没有运行完成,返回
return changes
}
// init container已完成,计算需要kill&start的工作container
// Number of running containers to keep.
keepCount := 0
// check the status of containers.
for idx, container := range pod.Spec.Containers {
containerStatus := podStatus.FindContainerStatusByName(container.Name)
// Call internal container post-stop lifecycle hook for any non-running container so that any
// allocated cpus are released immediately. If the container is restarted, cpus will be re-allocated
// to it.
// 如果运行状态不为空,并且不是running,代表启动失败的,准备删掉.先把生命周期性相关的执行掉
if containerStatus != nil && containerStatus.State != kubecontainer.ContainerStateRunning {
if err := m.internalLifecycle.PostStopContainer(containerStatus.ID.ID); err != nil {
klog.ErrorS(err, "Internal container post-stop lifecycle hook failed for container in pod with error",
"containerName", container.Name, "pod", klog.KObj(pod))
}
}
// If container does not exist, or is not running, check whether we
// need to restart it.
// 如果container不存在或没有在运行,那么根据重启策略决定是否需要重启
if containerStatus == nil || containerStatus.State != kubecontainer.ContainerStateRunning {
if kubecontainer.ShouldContainerBeRestarted(&container, pod, podStatus) {
klog.V(3).InfoS("Container of pod is not in the desired state and shall be started", "containerName", container.Name, "pod", klog.KObj(pod))
// 加入到需要重启的列表里
changes.ContainersToStart = append(changes.ContainersToStart, idx)
if containerStatus != nil && containerStatus.State == kubecontainer.ContainerStateUnknown {
// If container is in unknown state, we don't know whether it
// is actually running or not, always try killing it before
// restart to avoid having 2 running instances of the same container.
changes.ContainersToKill[containerStatus.ID] = containerToKillInfo{
name: containerStatus.Name,
container: &pod.Spec.Containers[idx],
message: fmt.Sprintf("Container is in %q state, try killing it before restart",
containerStatus.State),
reason: reasonUnknown,
}
}
}
continue
}
// The container is running, but kill the container if any of the following condition is met.
var message string
var reason containerKillReason
// 到这里,说明container处于running状态,那么当满足下面条件时需要kill掉重启
// 获取pod重启策略,如果不是Never就需要重启
restart := shouldRestartOnFailure(pod)
if _, _, changed := containerChanged(&container, containerStatus); changed {
// 如果container的spec已经改变了,那么直接重启
message = fmt.Sprintf("Container %s definition changed", container.Name)
// Restart regardless of the restart policy because the container
// spec changed.
restart = true
} else if liveness, found := m.livenessManager.Get(containerStatus.ID); found && liveness == proberesults.Failure {
// If the container failed the liveness probe, we should kill it.
// 如果liveness探针检测失败,需要kill掉container,根据重启策略决定是否要重启
message = fmt.Sprintf("Container %s failed liveness probe", container.Name)
reason = reasonLivenessProbe
} else if startup, found := m.startupManager.Get(containerStatus.ID); found && startup == proberesults.Failure {
// If the container failed the startup probe, we should kill it.
// 如果startup探针检测失败,需要kill掉container,根据重启策略决定是否要重启
message = fmt.Sprintf("Container %s failed startup probe", container.Name)
reason = reasonStartupProbe
} else {
// 到这里,如果探针检测又没问题,container又没改变,那么不需要重启
// Keep the container.
keepCount++
continue
}
// We need to kill the container, but if we also want to restart the
// container afterwards, make the intent clear in the message. Also do
// not kill the entire pod since we expect container to be running eventually.
// 如果需要重启,那么把这些container加入队列
if restart {
message = fmt.Sprintf("%s, will be restarted", message)
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
// 设置需要kill掉的container的列表
changes.ContainersToKill[containerStatus.ID] = containerToKillInfo{
name: containerStatus.Name,
container: &pod.Spec.Containers[idx],
message: message,
reason: reason,
}
klog.V(2).InfoS("Message for Container of pod", "containerName", container.Name, "containerStatusID", containerStatus.ID, "pod", klog.KObj(pod), "containerMessage", message)
}
if keepCount == 0 && len(changes.ContainersToStart) == 0 {
changes.KillPod = true
}
return changes
}
computePodActions()方法主要逻辑如下:
- 需要创建PodSandbox时
- 如果init container不为空,将init container中的第一个设置到NextInitContainerToStart字段中,返回
- 如果init container为空,将主容器设置到ContainersToStart字段中,返回
- 如果init container没有执行完,则先启动init container,将下一个要启动的init container设置到NextInitContainerToStart字段中,返回
- 最后根据容器运行状态、Pod重启策略、探针检测失败等情况,找到需要被kill掉的container添加到ContainersToKill字段中,以及需要被启动的container添加到ContainersToStart字段中
computePodActions()方法决定了Pod启动sandbox、init container、主容器的前后关系,Pod创建时会先创建PodSandbox,创建PodSandbox后,如果有多个init container,会按照顺序依次启动init container,init container全部启动成功后再启动主容器
4)、createPodSandbox()
sandbox是一种程序的隔离运行机制,其目的是限制不可信进程的权限。Kubernetes中每个Pod共享一个sandbox定义了其cgroup及各种namespace,所以同一个Pod的所有容器才能够互通,且与外界隔离
createPodSandbox()方法代码如下:
// pkg/kubelet/kuberuntime/kuberuntime_sandbox.go
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
// 调用generatePodSandboxConfig生成pod的sandbox配置
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
if err != nil {
message := fmt.Sprintf("Failed to generate sandbox config for pod %q: %v", format.Pod(pod), err)
klog.ErrorS(err, "Failed to generate sandbox config for pod", "pod", klog.KObj(pod))
return "", message, err
}
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
if err != nil {
message := fmt.Sprintf("Failed to create log directory for pod %q: %v", format.Pod(pod), err)
klog.ErrorS(err, "Failed to create log directory for pod", "pod", klog.KObj(pod))
return "", message, err
}
runtimeHandler := ""
if m.runtimeClassManager != nil {
runtimeHandler, err = m.runtimeClassManager.LookupRuntimeHandler(pod.Spec.RuntimeClassName)
if err != nil {
message := fmt.Sprintf("Failed to create sandbox for pod %q: %v", format.Pod(pod), err)
return "", message, err
}
if runtimeHandler != "" {
klog.V(2).InfoS("Running pod with runtime handler", "pod", klog.KObj(pod), "runtimeHandler", runtimeHandler)
}
}
// 调用CRI的RunPodSandbox接口,创建sandbox
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
if err != nil {
message := fmt.Sprintf("Failed to create sandbox for pod %q: %v", format.Pod(pod), err)
klog.ErrorS(err, "Failed to create sandbox for pod", "pod", klog.KObj(pod))
return "", message, err
}
return podSandBoxID, "", nil
}
其中调用generatePodSandboxConfig()方法生成Pod的sandbox配置,generatePodSandboxConfig()方法代码如下:
// pkg/kubelet/kuberuntime/kuberuntime_sandbox.go
func (m *kubeGenericRuntimeManager) generatePodSandboxConfig(pod *v1.Pod, attempt uint32) (*runtimeapi.PodSandboxConfig, error) {
// TODO: deprecating podsandbox resource requirements in favor of the pod level cgroup
// Refer https://github.com/kubernetes/kubernetes/issues/29871
// 初始化配置数据
podUID := string(pod.UID)
podSandboxConfig := &runtimeapi.PodSandboxConfig{
Metadata: &runtimeapi.PodSandboxMetadata{
Name: pod.Name,
Namespace: pod.Namespace,
Uid: podUID,
Attempt: attempt,
},
Labels: newPodLabels(pod),
Annotations: newPodAnnotations(pod),
}
// 设置dns
dnsConfig, err := m.runtimeHelper.GetPodDNS(pod)
if err != nil {
return nil, err
}
podSandboxConfig.DnsConfig = dnsConfig
// 如果没有使用主机网络,设置hostname
if !kubecontainer.IsHostNetworkPod(pod) {
// TODO: Add domain support in new runtime interface
podHostname, podDomain, err := m.runtimeHelper.GeneratePodHostNameAndDomain(pod)
if err != nil {
return nil, err
}
podHostname, err = util.GetNodenameForKernel(podHostname, podDomain, pod.Spec.SetHostnameAsFQDN)
if err != nil {
return nil, err
}
podSandboxConfig.Hostname = podHostname
}
// 设置pod log目录
logDir := BuildPodLogsDirectory(pod.Namespace, pod.Name, pod.UID)
podSandboxConfig.LogDirectory = logDir
// 注册所需要的port端口
portMappings := []*runtimeapi.PortMapping{}
for _, c := range pod.Spec.Containers {
containerPortMappings := kubecontainer.MakePortMappings(&c)
for idx := range containerPortMappings {
port := containerPortMappings[idx]
hostPort := int32(port.HostPort)
containerPort := int32(port.ContainerPort)
protocol := toRuntimeProtocol(port.Protocol)
portMappings = append(portMappings, &runtimeapi.PortMapping{
HostIp: port.HostIP,
HostPort: hostPort,
ContainerPort: containerPort,
Protocol: protocol,
})
}
}
if len(portMappings) > 0 {
podSandboxConfig.PortMappings = portMappings
}
// 生成Linux隔离配置:设置ParentCgroup、sysctls、各种Namespace、Linux权限
lc, err := m.generatePodSandboxLinuxConfig(pod)
if err != nil {
return nil, err
}
podSandboxConfig.Linux = lc
if runtime.GOOS == "windows" {
wc, err := m.generatePodSandboxWindowsConfig(pod)
if err != nil {
return nil, err
}
podSandboxConfig.Windows = wc
}
return podSandboxConfig, nil
}
调用createPodSandbox()方法创建sandbox的过程如下图:

5)、startContainer()
// pkg/kubelet/kuberuntime/kuberuntime_container.go
func (m *kubeGenericRuntimeManager) startContainer(podSandboxID string, podSandboxConfig *runtimeapi.PodSandboxConfig, spec *startSpec, pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, podIP string, podIPs []string) (string, error) {
container := spec.container
// Step 1: pull the image.
// 拉取镜像
imageRef, msg, err := m.imagePuller.EnsureImageExists(pod, container, pullSecrets, podSandboxConfig)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, "", v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return msg, err
}
// Step 2: create the container.
// For a new container, the RestartCount should be 0
// 计算一下container重启次数,如果是首次创建,那么应该是0
restartCount := 0
containerStatus := podStatus.FindContainerStatusByName(container.Name)
if containerStatus != nil {
restartCount = containerStatus.RestartCount + 1
} else {
// The container runtime keeps state on container statuses and
// what the container restart count is. When nodes are rebooted
// some container runtimes clear their state which causes the
// restartCount to be reset to 0. This causes the logfile to
// start at 0.log, which either overwrites or appends to the
// already existing log.
//
// We are checking to see if the log directory exists, and find
// the latest restartCount by checking the log name -
// {restartCount}.log - and adding 1 to it.
logDir := BuildContainerLogsDirectory(pod.Namespace, pod.Name, pod.UID, container.Name)
restartCount, err = calcRestartCountByLogDir(logDir)
if err != nil {
klog.InfoS("Log directory exists but could not calculate restartCount", "logDir", logDir, "err", err)
}
}
target, err := spec.getTargetID(podStatus)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, "", v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return s.Message(), ErrCreateContainerConfig
}
// 生成containerConfig
containerConfig, cleanupAction, err := m.generateContainerConfig(container, pod, restartCount, podIP, imageRef, podIPs, target)
if cleanupAction != nil {
defer cleanupAction()
}
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, "", v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return s.Message(), ErrCreateContainerConfig
}
err = m.internalLifecycle.PreCreateContainer(pod, container, containerConfig)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, "", v1.EventTypeWarning, events.FailedToCreateContainer, "Internal PreCreateContainer hook failed: %v", s.Message())
return s.Message(), ErrPreCreateHook
}
// 调用CRI的CreateContainer接口,创建container
containerID, err := m.runtimeService.CreateContainer(podSandboxID, containerConfig, podSandboxConfig)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, containerID, v1.EventTypeWarning, events.FailedToCreateContainer, "Error: %v", s.Message())
return s.Message(), ErrCreateContainer
}
// 在启动之前调用PreStartContainer做预处理工作
err = m.internalLifecycle.PreStartContainer(pod, container, containerID)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, containerID, v1.EventTypeWarning, events.FailedToStartContainer, "Internal PreStartContainer hook failed: %v", s.Message())
return s.Message(), ErrPreStartHook
}
m.recordContainerEvent(pod, container, containerID, v1.EventTypeNormal, events.CreatedContainer, fmt.Sprintf("Created container %s", container.Name))
// Step 3: start the container.
// 调用CRI的StartContainer接口,启动container
err = m.runtimeService.StartContainer(containerID)
if err != nil {
s, _ := grpcstatus.FromError(err)
m.recordContainerEvent(pod, container, containerID, v1.EventTypeWarning, events.FailedToStartContainer, "Error: %v", s.Message())
return s.Message(), kubecontainer.ErrRunContainer
}
m.recordContainerEvent(pod, container, containerID, v1.EventTypeNormal, events.StartedContainer, fmt.Sprintf("Started container %s", container.Name))
// Symlink container logs to the legacy container log location for cluster logging
// support.
// TODO(random-liu): Remove this after cluster logging supports CRI container log path.
containerMeta := containerConfig.GetMetadata()
sandboxMeta := podSandboxConfig.GetMetadata()
legacySymlink := legacyLogSymlink(containerID, containerMeta.Name, sandboxMeta.Name,
sandboxMeta.Namespace)
containerLog := filepath.Join(podSandboxConfig.LogDirectory, containerConfig.LogPath)
// only create legacy symlink if containerLog path exists (or the error is not IsNotExist).
// Because if containerLog path does not exist, only dangling legacySymlink is created.
// This dangling legacySymlink is later removed by container gc, so it does not make sense
// to create it in the first place. it happens when journald logging driver is used with docker.
if _, err := m.osInterface.Stat(containerLog); !os.IsNotExist(err) {
if err := m.osInterface.Symlink(containerLog, legacySymlink); err != nil {
klog.ErrorS(err, "Failed to create legacy symbolic link", "path", legacySymlink,
"containerID", containerID, "containerLogPath", containerLog)
}
}
// Step 4: execute the post start hook.
// 调用生命周期的钩子,post start container
if container.Lifecycle != nil && container.Lifecycle.PostStart != nil {
kubeContainerID := kubecontainer.ContainerID{
Type: m.runtimeName,
ID: containerID,
}
msg, handlerErr := m.runner.Run(kubeContainerID, pod, container, container.Lifecycle.PostStart)
if handlerErr != nil {
klog.ErrorS(handlerErr, "Failed to execute PostStartHook", "pod", klog.KObj(pod),
"podUID", pod.UID, "containerName", container.Name, "containerID", kubeContainerID.String())
m.recordContainerEvent(pod, container, kubeContainerID.ID, v1.EventTypeWarning, events.FailedPostStartHook, msg)
if err := m.killContainer(pod, kubeContainerID, container.Name, "FailedPostStartHook", reasonFailedPostStartHook, nil); err != nil {
klog.ErrorS(err, "Failed to kill container", "pod", klog.KObj(pod),
"podUID", pod.UID, "containerName", container.Name, "containerID", kubeContainerID.String())
}
return msg, ErrPostStartHook
}
}
return "", nil
}
startContainer()方法主要逻辑如下:
- 拉取镜像
- 计算一下container重启次数,如果是首次创建,那么应该是0
- 生成containerConfig
- 调用CRI的CreateContainer接口,创建container
- 在启动之前调用PreStartContainer做预处理工作
- 调用CRI的StartContainer接口,启动container
- 调用生命周期中设置的钩子post start
6)、小结
kubelet创建Pod流程如下图:

kubelet核心流程如下图:

参考:
12.深入k8s:kubelet创建pod流程源码分析
kubelet源码分析 kuberuntime的syncpod、killpod函数(一)
kubelet源码分析 kuberuntime的syncpod、createSandbox/createContainer函数(三)