视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 五、在虚拟机中部署Hive
- 5.1. 在node1虚拟机安装MySQL
- 5.2. 配置Hadoop
- 5.3. 下载并加压Hive
- 5.4. 下载MySQL驱动包
- 5.5. 配置Hive
- 5.6. 初始化元数据库
- 5.7. 使用hadoop用户身份启动Hive
五、在虚拟机中部署Hive
Hive是单机工具,只需要部署在一台服务器即可。
Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
本次部署服务清单:
| 服务 | 部署节点 |
|---|---|
| Hive服务 | node1 |
| 元数据服务所需的关系型数据库(本次选择MySQL) | node1 |
5.1. 在node1虚拟机安装MySQL
本次安装的是MySQL 5.7 社区版。
以root用户身份,在node1虚拟机分别执行以下命令:
# 更新rpm中MySQL相关仓库的密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装MySQL yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql社区版
yum -y install mysql-community-server
# 启动MySQL服务
systemctl start mysqld
# 启动MySQL服务设置开机启动
systemctl enable mysqld
# 检查Mysql服务状态
systemctl status mysqld
# 通过MySQL的日志查看默认生成的MySQL root用户的密码
cat /var/log/mysqld.log | grep 'password'
查看root用户的密码结果如下图所示,图中红框部分便是自动生成的密码。

使用mysql -u root -p命令,输入上面的密码登录MySQL。
在MySQL命令行中执行以下命令,实现对root命令的修改。
# 如果你想设置简单密码,需要降低Mysql的密码安全级别
# 设置密码安全级别为低
set global validate_password_policy=LOW;
# 设置密码长度最低4位即可
set global validate_password_length=4;
# 将root用户本地登录的密码修改为123456
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
# 打开root用户的远程登录权限,并将远程登录密码修改为123456
grant all privileges on *.* to root@"%" identified by '123456' with grant
# 刷新MySQL用户权限
flush privileges;
至此,MySQL安装完成。
5.2. 配置Hadoop
Hive的运行依赖于Hadoop(HDFS、MapReduce、YARN都依赖),同时涉及到HDFS文件系统的访问,所以需要配置Hadoop的代理用户,即设置hadoop用户允许代理(模拟)其它用户。
在core-site.xml配置文件中,增加以下配置信息(该配置在前面配置通过NFS挂载HDFS系统时配置过):
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
其中:
hadoop.proxyuser.hadoop.groups配置项的值为 *,表示允许hadoop用户代理任何其他用户组;
hadoop.proxyuser.hadoop.hosts配置型的值为 *,表示允许代理任意服务器的请求。
配置完成后,使用scp命令,将该配置文件分发到node2和node3服务器上。
5.3. 下载并加压Hive
下载Hive-3.1.3:http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
将下载下来的文件传至node1虚拟机/home/hadoop目录下,在node1虚拟机中,切换到hadoop用户,进行解压:
# 切换到hadoop用户
su hadoop
# 切换到hadoop用户的home目录(即/home/hadoop)
cd ~
# 解压压缩包
tar -zxvf apache-hive-3.1.3-bin.tar.gz
# 将解压得到的文件夹移动到/export/server/目录下
mv apache-hive-3.1.3-bin /export/server/
# 切换工作目录
cd /export/server/
# 创建软链接
ln -s /export/server/apache-hive-3.1.3-bin/ /export/server/hive
5.4. 下载MySQL驱动包
下载MySQL驱动包:https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
将下载下来的文件传至node1虚拟机/home/hadoop目录下,在node1虚拟机中,以hadoop用户将其移动至hive安装文件夹的lib目录内:
# 切换到hadoop用户的home目录(即/home/hadoop)
cd ~
# 将MySQL驱动程序复制到hive安装目录的lib文件夹下
mv mysql-connector-java-5.1.34.jar /export/server/apache-hive-3.1.3-bin/lib/
# 切换到root用户
su root
# 修改MySQL驱动程序的所有者和所有组为hadoop
chown -R hadoop:hadoop /export/server/apache-hive-3.1.3-bin/lib/mysql-connector-java-5.1.34.jar
# 切换回hadoop用户
exit
5.5. 配置Hive
1、配置hive-env.sh文件:
# 进入hive配置文件目录
cd /export/server/apache-hive-3.1.3-bin/conf/
# 复制一份hive-env.sh模板
cp hive-env.sh.template hive-env.sh
# 打开hive-env.sh文件
vim hive-env.sh
在hive-env.sh文件中追加如下内容:
# 添加环境变量
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
2、创建并配置hive-site.xml文件,在其中添加如下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
其中,
javax.jdo.option.ConnectionURL 表示Hive所用到的存储元数据的关系型数据库的连接地址;
javax.jdo.option.ConnectionDriverName 表示连接数据库所使用的驱动类;
javax.jdo.option.ConnectionUserName 表示数据库用户名;
javax.jdo.option.ConnectionPassword 表示数据库密码;
hive.server2.thrift.bind.host 表示Hive的server 2绑定的主机;
hive.metastore.uris 表示Hive的metastore(元数据)服务绑定的IP和端口;
hive.metastore.event.db.notification.api.auth 表示是否开启API授权认证。
5.6. 初始化元数据库
在MySQL数据库中新建hive库(这里库的名字需要和上面的数据库连接地址里面的库名保持一致):
CREATE DATABASE hive CHARSET UTF8;
创建好数据库后,在node1虚拟机命令行执行以下命令:
# 切换工作目录
cd /export/server/hive/bin/
# 使用schematool初始化hive数据库
./schematool -initSchema -dbType mysql -verbos
其中,
-initSchema 表示初始化数据库;
-dbType mysql 表示元数据存储的数据库是MySQL数据库;
-verbos 表示开启啰嗦模式(详细日志模式)。
初始化成功后,会在MySQL的hive库中新建74张元数据管理的表。
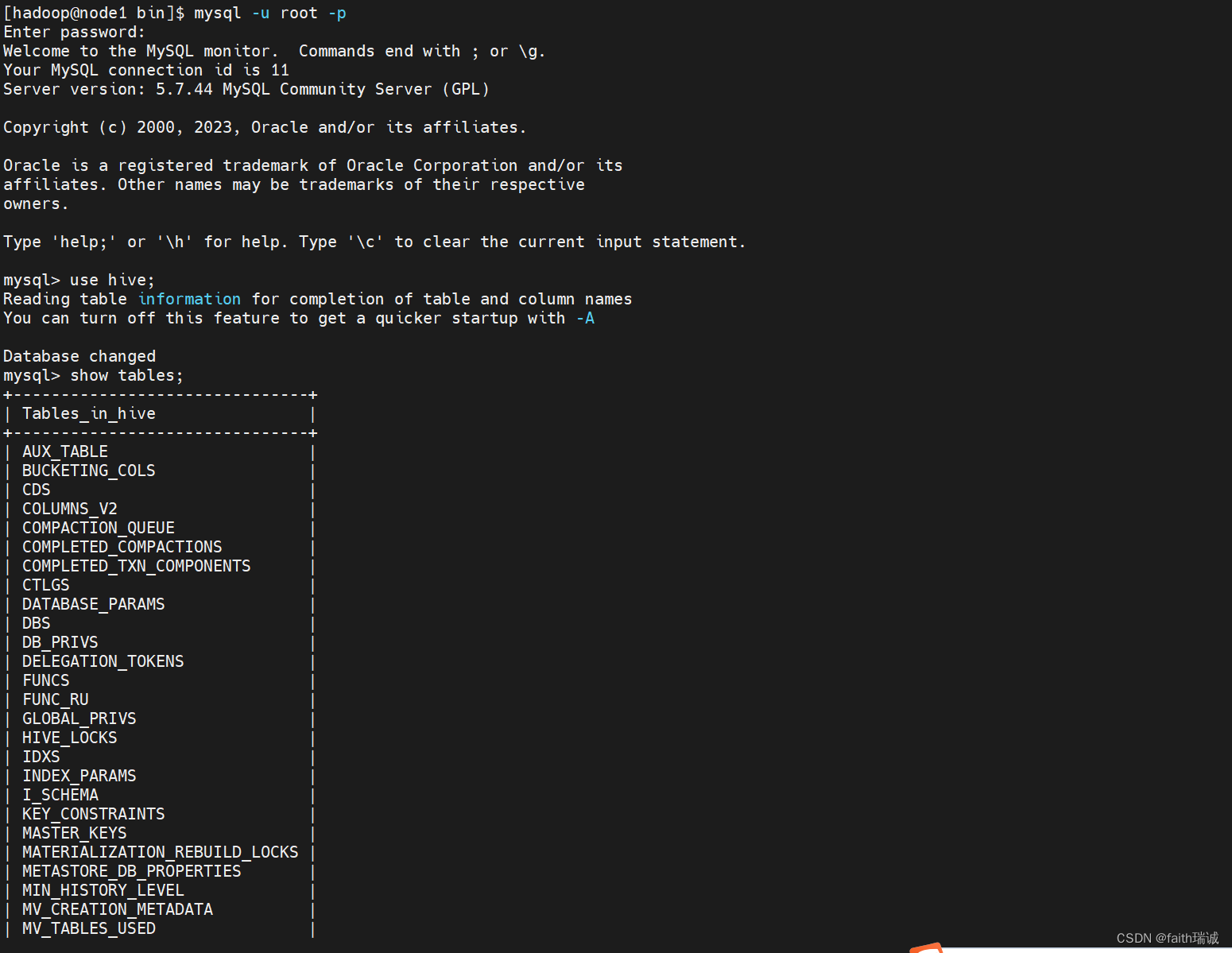
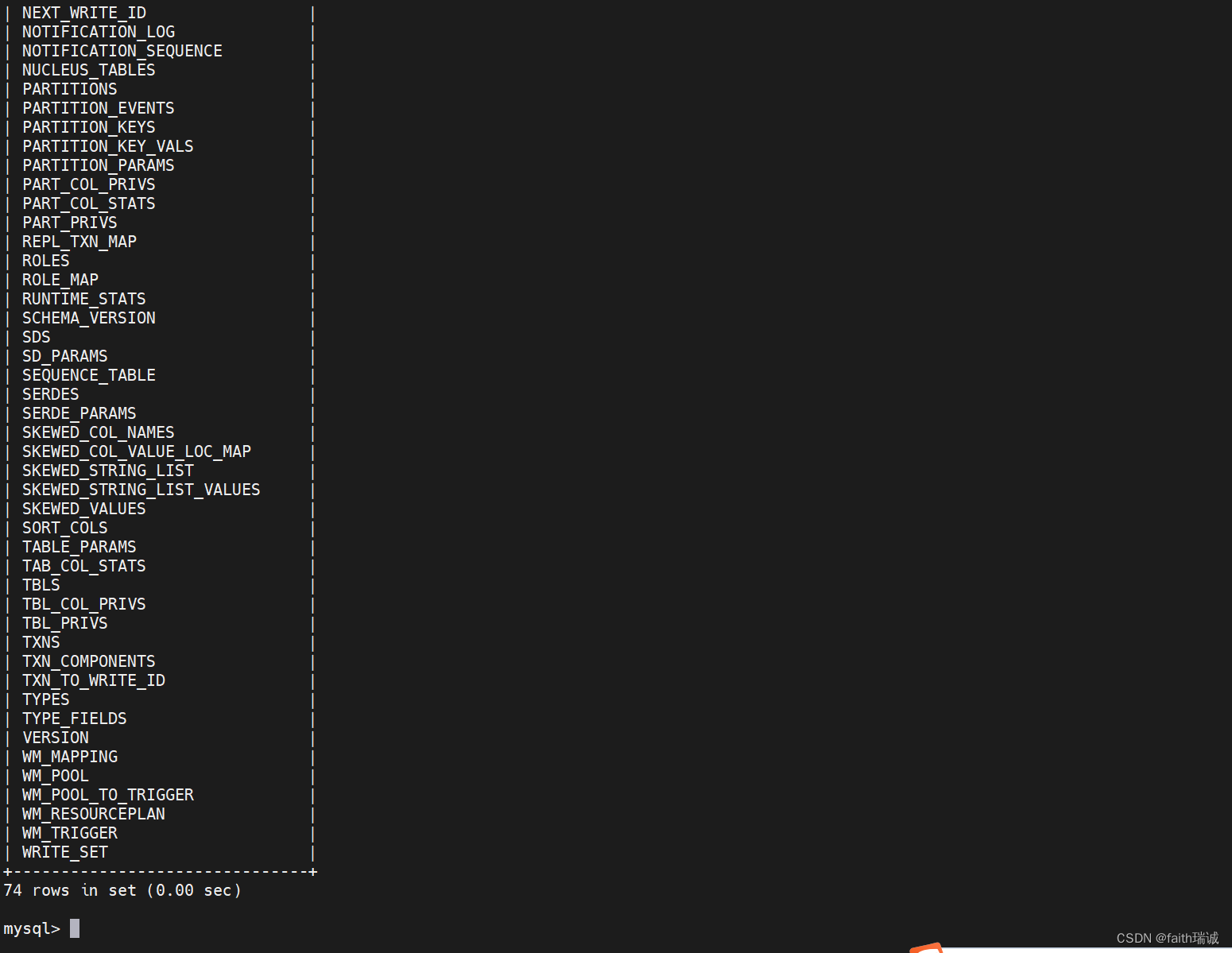
5.7. 使用hadoop用户身份启动Hive
1、在启动前,需要确保Hive安装目录及其子目录的所有用户和用户组应是hadoop用户,若不是,可以root用户身份执行chown -R hadoop:hadoop /export/server/apache-hive-3.1.3-bin/命令进行修改。

2、创建一个hive的日志文件夹
# 切换成hadoop用户
su hadoop
# 创建logs文件夹,后面用于存放hive日志
mkdir /export/server/hive/logs
3、启动元数据管理服务(必须启动,否则无法工作)
在启动Hive服务之前,一定要确保HDFS集群和YARN集群已经启动!!!
前台启动方式:
# 切换工作目录
cd /export/server/hive/bin
# 前台启动metastore服务
./hive --service metastore
后台启动方式:
# 切换工作目录
cd /export/server/hive/bin
# 使用后台方式启动metastore,并将相关日志输出到metastore.log文件中
nohup ./hive --service metastore >> ../logs/metastore.log 2>&1 &
在实际工作中,一般使用后台启动方式。
启动后,可以使用tail -f ../logs/metastore.log命令查看到日志文件的内容。
4、启动Hive客户端
Hive Shell方式(可以直接写SQL):./hive
Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用): ./hive --service hiveserver2
先演示Hive Shell方式,直接在命令行输入
# 切换工作目录
cd /export/server/hive/bin/
# 打开hive客户端
./hive
打开Hive客户端后,能看到如下效果:
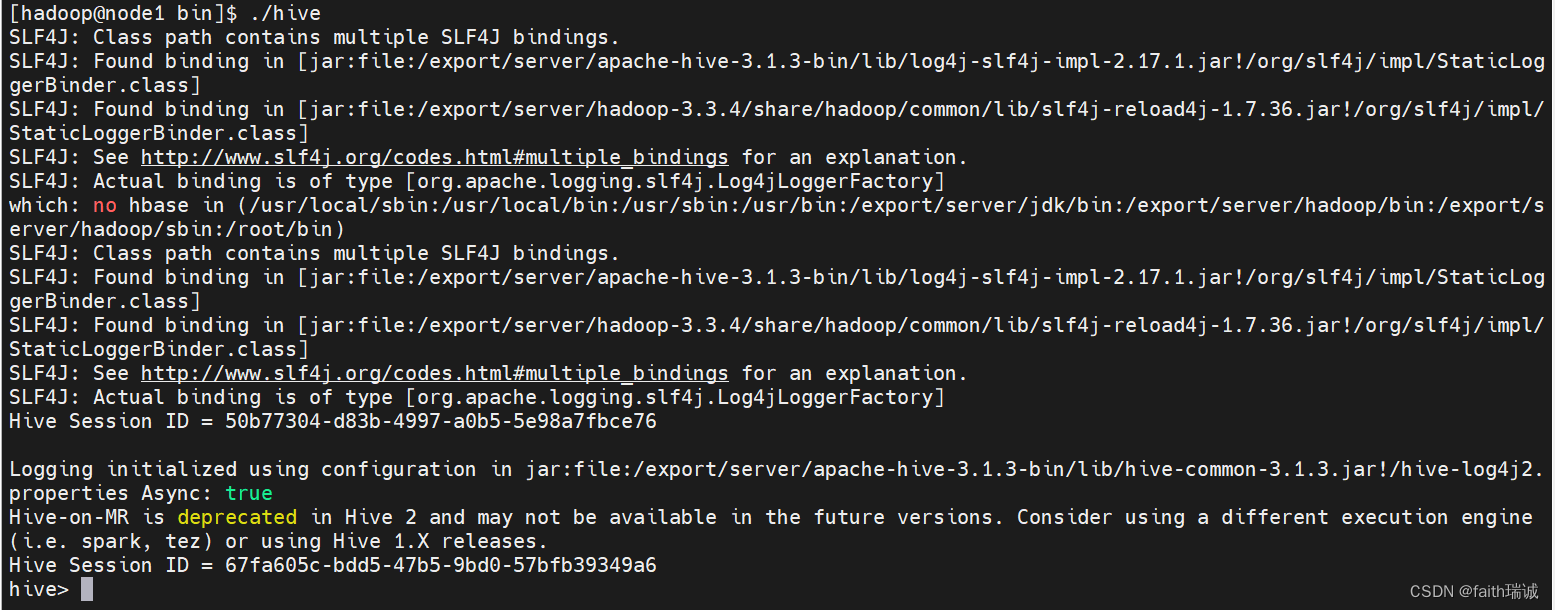
可以看到hive>标签,在这里就可以输入SQL语句:

5、停止元数据管理服务
可以通过ps -aux | grep hive来看hive的进程号,然后kill掉相关的进程即可。